Informer简单理解
发布时间:2024年01月16日
一、输入层Encoder改进:
1、ProbAttention算法计算权值:
原Transformer中的注意力机制时间复杂度N^2,而Informer作为实时性要求高的长时间序列预测算法必然需要提高效率,降低时间开销。
- 1.简化K:
- 对每个Q不再与所有K计算,而是随机选取25个K,这样减少计算量
- 2.简化Q:
- 每个Q与各自随机选取的25个K计算结果有25个值,选取最大值作为Q结果
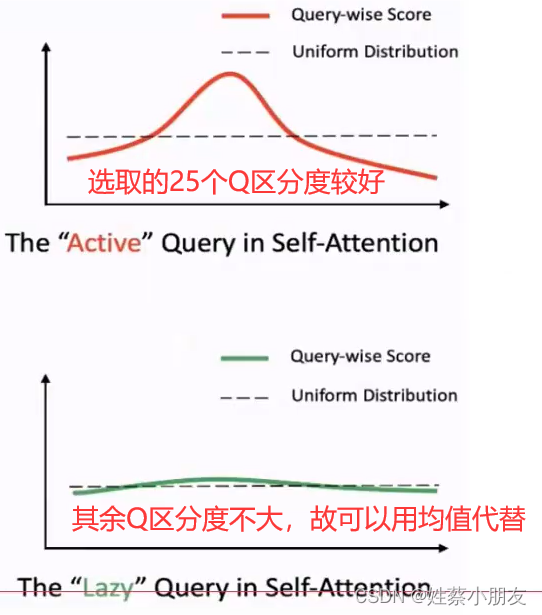
- 对所有Q,选取最大的前25个Q ,因为这25个Q具有较好的区分度
- 25个Q之外的其余Q使用96个特征V的均值作为Q结果,因为这些Q区分度不大,可以看做均匀分布
- 得到的输出结果:
- 32代表patch数量。
- 8代表8头,即每个向量都有8个不同的Q、K,即从8个角度对序列进行计算。
- 25即为25个Q。
- 96为K的总数,虽然我们在计算Q时各自只选了25个K,但是最后Q需要与所有96个K进行内积才能融合所有K的特征。

2、Self-attention Distilling算法:
同样是在Transformer中的改进,为了降低时间开销。
- Distilling算法在每层堆叠Self-attention(Transformer Encoder)时调用Distilling算法使输入序列长度减半,降低了时间开销,同样的QK的选取个数也随之减少。
二、输出层Decoder改进:
- 预测某天的值需要将该天之前的真实值作为已知输入
- 多个输出结果一口气输出,不用串行等待前一个数据的输出结果。
文章来源:https://blog.csdn.net/m0_53881899/article/details/135622210
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- FileZilla的使用
- SSM同城拼车微信小程序的开发 计算机毕设源码20625
- opencv#32 可分离滤波
- 双向循环链表实现C语言关键字中英翻译机 ?( ?? · ? ??)
- Solana 生态铭文跨链桥 Sobit 是何神圣?其场外白名单已达到1200U
- IDEA基本设置
- 一款用于生成各类免杀webshell工具
- 【数据结构1-2】P5076 普通二叉树(简化版)(c++,multiset做法)
- 计算机网络扫盲(2)——网络边缘
- 使用java内置工具jar手动创建xxx.jar文件