文字处理软件(字符串吃字符)#洛谷
题目描述
你需要开发一款文字处理软件。最开始时输入一个字符串作为初始文档。可以认为文档开头是第 0 0 0 个字符。需要支持以下操作:
1 str:后接插入,在文档后面插入字符串 str \texttt{str} str,并输出文档的字符串;2 a b:截取文档部分,只保留文档中从第 a a a 个字符起 b b b 个字符,并输出文档的字符串;3 a str:插入片段,在文档中第 a a a 个字符前面插入字符串 str \texttt{str} str,并输出文档的字符串;4 str:查找子串,查找字符串 str \texttt{str} str 在文档中最先的位置并输出;如果找不到输出 ? 1 -1 ?1。
为了简化问题,规定初始的文档和每次操作中的 str \texttt{str} str 都不含有空格或换行。最多会有 q q q 次操作。
输入格式
第一行输入一个正整数 q q q,表示操作次数。
第二行输入一个字符串 str \texttt{str} str,表示最开始的字符串。
第三行开始,往下 q q q 行,每行表示一个操作,操作如题目描述所示。
输出格式
一共输出 q q q 行。
对于每个操作 1 , 2 , 3 1,2,3 1,2,3,根据操作的要求输出一个字符串。
对于操作 4 4 4,根据操作的要求输出一个整数。
样例 #1
样例输入 #1
4
ILove
1 Luogu
2 5 5
3 3 guGugu
4 gu
样例输出 #1
ILoveLuogu
Luogu
LuoguGugugu
3
提示
数据保证, 1 ≤ q ≤ 100 1 \leq q\le 100 1≤q≤100,开始的字符串长度 ≤ 100 \leq 100 ≤100。
def fenge1(srt):
anss=[]
for item in range(2,len(srt)):
anss.append(srt[item])
pass
return ''.join(anss)
def fenge2(srt):
anss1 = []
anss2=[]
flag1=True
flag2=False
for item in range(2, len(srt)):
if srt[item]!=' ' and flag1:
anss1.append(srt[item])
pass
if srt[item]!=' ' and flag2:
anss2.append(srt[item])
pass
if srt[item]==' ':
flag1=False
flag2=True
return ''.join(anss1),''.join(anss2)
if __name__ == "__main__":
num = int(input())
data = input().strip('\r\n')
for item in range(num):
mapp = input().strip('\r\n')
if mapp[0] == '1':
key = fenge1(mapp)
data += key
print(data)
pass
elif mapp[0] == '2':
a, b = fenge2(mapp)
a = int(a)
b = int(b)
tran = list(data)
tran = tran[a:a + b]
data = ''.join(tran)
print(data)
pass
elif mapp[0] == '3':
n, m = fenge2(mapp)
n = int(n)
tran = list(data)
tran.insert(n, m)
data = ''.join(tran)
print(data)
pass
elif mapp[0] == '4':
key = fenge1(mapp)
anss = int(data.find(key))
print(anss)
昨晚到今天早上一直a不了,等到今天下载样例才发现根本就没有问题,可是样例过不了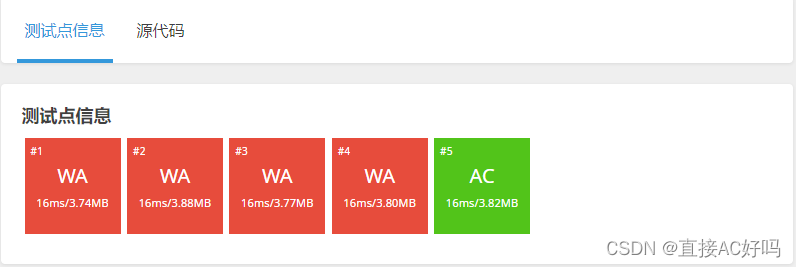
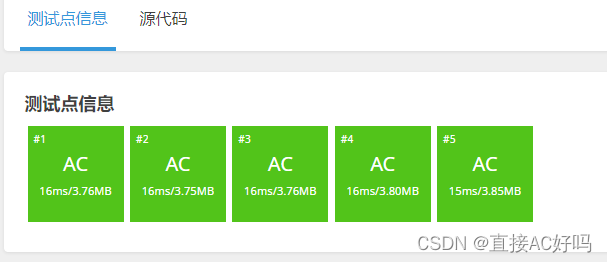
今天来了才想起,字符串输入时,很多题目要考虑最后吃掉换行的情况,因为换行也是个字符。吃掉后就会过了,/r是回车,要吃掉/r/n才可以。改了以后终于全绿了。这道题用字符串的函数以及字符串转换成列表再用列表的函数,之后转换为字符串会比较好做一些。这里的输入用的是设立函数进行字符串的分割,实际上有更方便的输入方法,下个题目会用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- three.js从入门到精通系列教程003 - three.js透视相机(PerspectiveCamera)
- SELinux介绍
- 民安智库:满意度调查在组织管理中的应用与价值
- linux中的od命令与hexdump命令
- 大语言模型参数微调过程(附完整代码)
- PPT文档怎么转换PDF?一个方法教你快速实现
- 【无标题】
- 【mysql】MySQL基础
- 生存分析survival_analysis_COXmodel_python实现
- CF1270C