ICCV2023 | MCD: Misalign, Contrast then Distill:重新思考VLP中的错位

论文标题: Misalign, Contrast then Distill: Rethinking Misalignments in Language-Image Pretraining
论文地址:ICCV 2023 Open Access Repository
代码:None
LG AI Research
一、问题提出
SLIP发现,在CLIP中引入增强(特别是调整裁剪和翻转的大小)实际上会导致性能下降。SimCLR通过在图像之间用自监督学习损失代替infoNCE,避开了在CLIP中使用增强视图,但是在充分捕捉多模式学习的本质方面存在局限性。但是对于image-text中随机图像增强过程不知道其对应的文本,经常导致增强图像视图与其描述不一致:
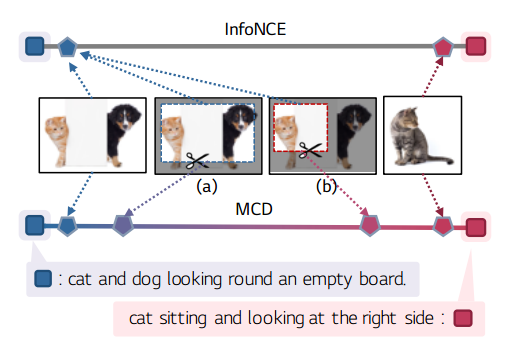
这些不一致给VLP中对比损失中加入了噪声,如果不适当处理,会导致性能下降。为了缓解这个问题,最近,使用额外的augmentation embeddings或 heavy external off-the-shelf object detectors and summary extractors 来匹配训练期间的对齐。但是他们局限性是在训练和推理中都增加了不必要的负担。
因此,是否可以将其利用起来?即是否可以将它们作为VLP的训练源。
二、Methods

1、Misalign
对图像进行随机扩增,创建图像与文本出现不同程度的错位(或根本不对齐)。存在三种情况(i)文本不可知的随机增强可能会导致正图像-文本对中的错位。(ii)随机增强可能错误地导致负对之间的正信号出现。(iii)在原始图像-文本对内可能已经天然存在错位。
(其实就是三种错位:正样本对变负样本对,负样本对变正样本对,数据集中本来的错位)
2、Contrast
将所有数据(图像、文本和增强图像)映射到一个同一多模态空间中,并通过对比目标(对比度)学习所有图像-文本对之间的距离。具体:使用这两种模态的所有正对和负对。包括N个图像样本、N个文本样本和N个随机增强图像样本,zi为batch(3N)中的i-th embedding,zp为正样本:
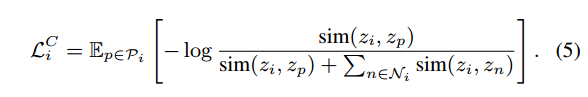
3、Distill
Log-Ratio Loss for Image–Text Distance.
给定学生的fI和动量教师的f'I,通过学习embedding空间中图像-文本不对齐的比率来近似相似距离的比率。使用Log-Ratio损失:

Misalignment in Positive pairs.
设i′表示增强图像样本的索引。在方程(5)InfoNCE上,第i′个图像样本和第i个文本样本作为正对。然而,随机扩充偶尔可以将正对转换为负对。为了解释这种转换,利用原始对和增广对之间的对数比:
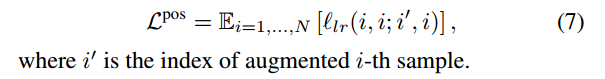
Misalignment in Negative pairs.
增强图像可以与不同的文本具有相关性,这通常被视为方程中的负对:
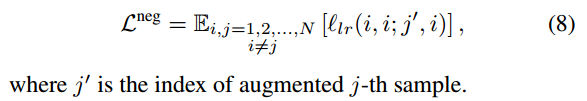
Misalignment in Noisy pairs.
提出了噪声对的损失,其中噪声标签被训练为比匹配的图像-文本对具有更大的距离:
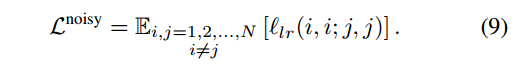
Distillation Loss.
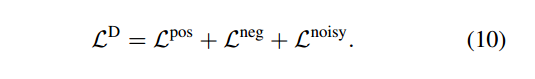
总的算法流程:

三、Training MCD
1、MLM Loss.
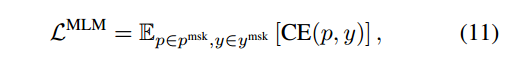
2、Momentum Teacher Update.
学生Encoder器和动量教师Encoder。学生使用损失更新,教师使用动量更新:

3、Progressive Distillation.
InfoNCE的损失与错位损失相冲突。因为InfoNCE不管其错位程度如何,它只管拉开距离。在训练的早期阶段,模型需要学习如何用硬标签区分阳性或阴性配对。然而,随着训练的进行,对数比损失精细地模拟了原始图像-文本对中增加或固有存在的各种不对齐之间的距离。因此,逐渐减少涉及增强视图的InfoNCE损失的贡献:
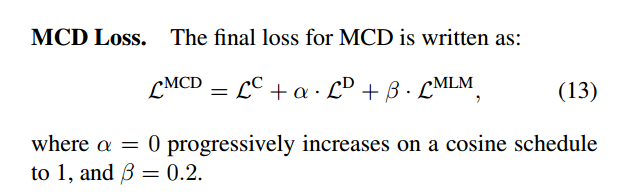
四、Experiment
MCD Pretraining on YFCC15M Dataset
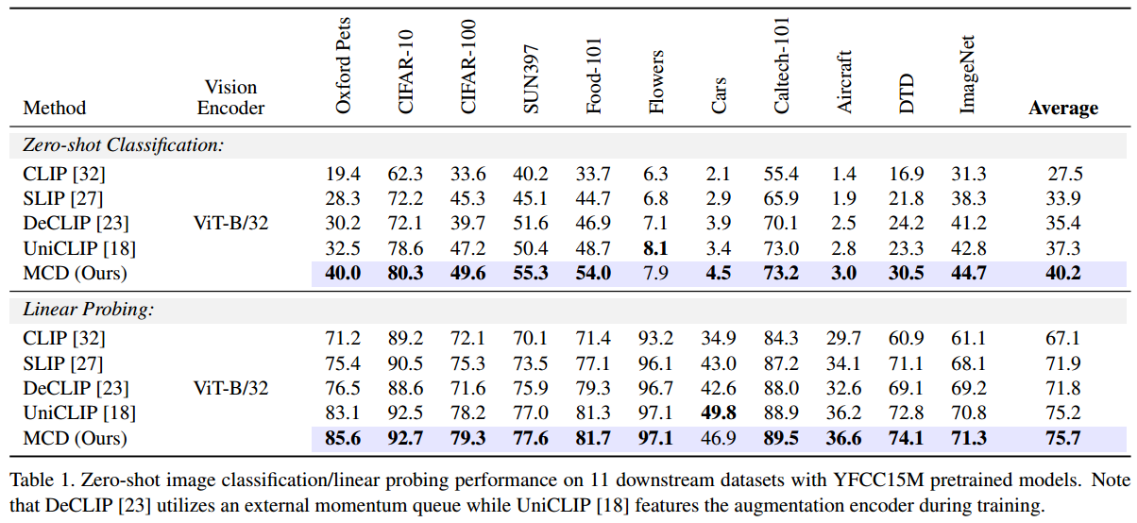
Image–Text Retrieval

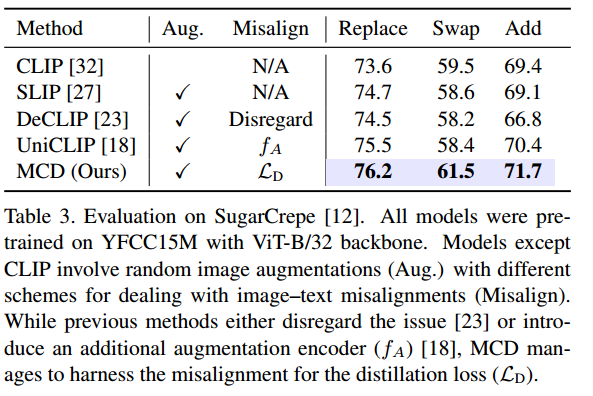
Vision–Language Compositionality
ImageNet zero-shot

Ablation Study

该工作的亮点在于将这种Misalignments当成一种训练资源在用,并引入了Log-Ratio(计算错位的相似度差),分成三类,故事很好。早前训练InfoNCE Loss为主,后期训练以Log-Ratio Loss为主。根据教师网络的参数更新方式,教师网络和学生网络就是“动量编码器”与“编码器”之间区别,只是套上了一层蒸馏的意识外壳(因为要求相似度的差值)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【管理篇 / 登录】? 07. FortiOS 7.4 初始登录提示 ? FortiGate 防火墙
- Kafka、RocketMQ、RabbitMQ消息丢失可能存在的地方,以及解决方案
- Linux 命令:cd
- ADI的DSP开发资料有哪些?(一)开发软件合辑
- AI崛起,裁员“新常态”?
- 摄像头录像软件推荐,让你看清每个细节!
- 时间是如何定义的
- 分布式事务完美解决方案:消息中间件(kafka)+ 本地事物 + 消息校对
- 数据资源工具断点续传及下载重试功能
- Linux之静态库和动态库