INT201各种题型收集
汇总一下

FA 有穷自动机 - RL正则语言
DFA
M = (Q, Σ, δ, q, F)
-
Q 是有限状态集合(Finite Set of States): 这表示自动机中存在一个有限数量的不同状态。每个状态代表了自动机在某个特定时刻的内部状态。这些状态可以用符号或名称表示。
-
Σ 是有限符号集合(Finite Set of Symbols,即字母表): 这是自动机操作的输入符号的有穷的非空集合,通常称为自动机的字母表或输入字母表。它包含了自动机能够接受和处理的所有可能输入符号。(字符串:从某个字母表中选择的符号的有穷序列)
-
δ : Q × Σ → Q 是转移函数(Transition Function): 这个函数描述了自动机如何从一个状态通过某个输入符号转移到另一个状态。它接受一个当前状态和一个输入符号,然后返回下一个状态。这个函数是有限自动机的核心,它定义了状态转移规则。
-
q ∈ Q 是初始状态(Initial State): 这表示自动机在开始运行时处于的初始状态。初始状态是自动机的起点,从这里开始处理输入。
-
F ? Q 是接受/终止状态集合(Set of Accepting/Terminal States): 这是自动机可能达到的状态的子集。当自动机在某个状态属于 F 时,它被认为已经接受了输入字符串。这些状态通常表示自动机在识别输入时的终止状态。
NFA

Regular Expression

closure
complement, union, intersection, concatenation, and Kleene star
PDA下推自动机 - CFG 上下文无关文法
CFG

CNF
所有变量生成两个非开始变量或一个结束符号。只有start变量生成空字符串。
CNF排除了不必要的生成规则,限制了推导搜索的速度。
PDA

DPDA

封闭性
union, concatenation, and Kleene star.
Turing Machine 图灵机


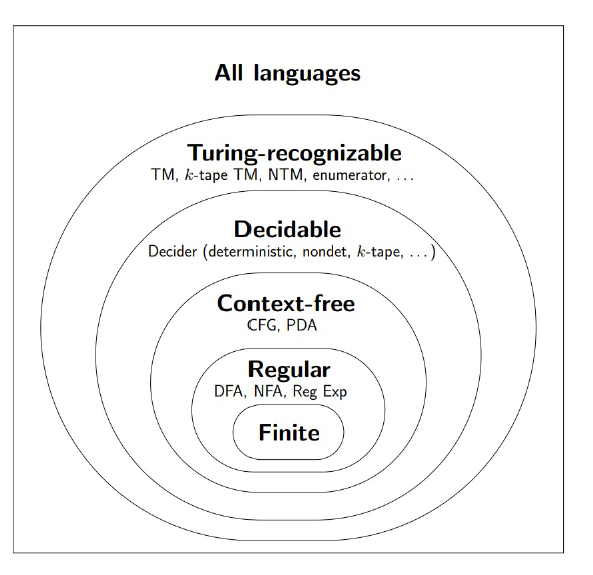
语言层次图
判断题汇总!
e.g1
?![]()
False,
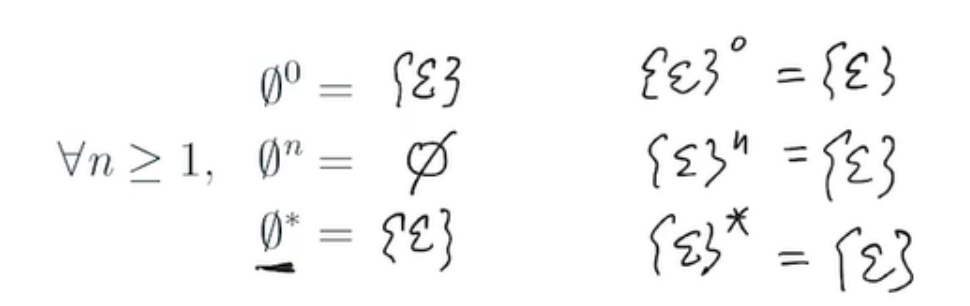
![]()
True, the string is consist of 11 and 01
![]()
False, 没空

False。context-free 交和补不行

True,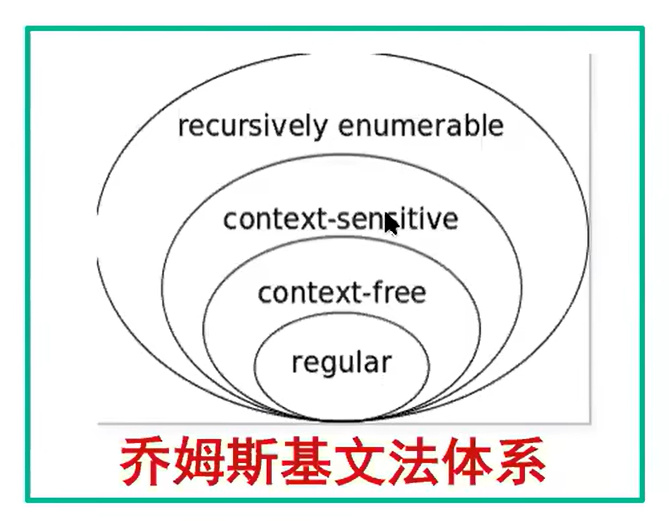

NO, the recursively enumerable is Turing recognizable, and Turing decidable??is a proper subset of? Turing recognizable, which means not all recursively enumerable language are? turing recognizable.
?e.g2
True, because a regular language could be recognized by an DFA, so the language generate by its grammar could also recognized by this DFA, so its subset is a regular language.

True , PDA is could accept context-free language, while regular language is a subset of context free language.

True , A Turing machine is a general-purpose computational model that can accept languages at various levels of the Chomsky hierarchy, including regular languages, context-free languages, and recursively enumerable languages.
![]()
False, counter example: L1 is a regular? language 0* , while L2 is not?L1 = {0^n1^n | n ≥ 0}, L1nL2 {0^n|n>=0} is a regular language.
 ?Flase, L1, L2, while string cab doesn't belong to L2
?Flase, L1, L2, while string cab doesn't belong to L2
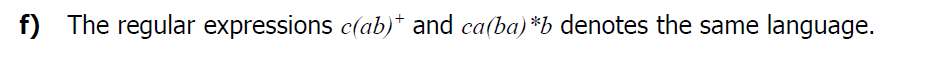
True
e.g3
(a)
?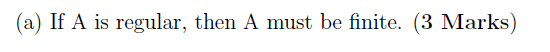 ?
?
T
e.g 状态有限,而不是字符串有限
(b)
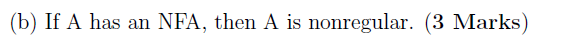
F
(c)
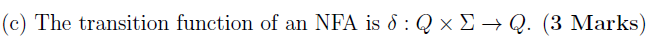
F?
![]()
(d)
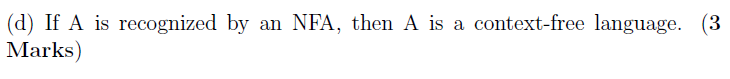
T
(e)
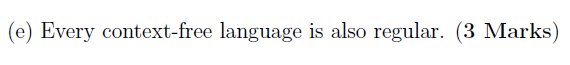
F
理由同上
(f)
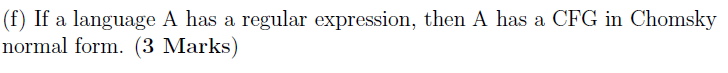
T
(g)
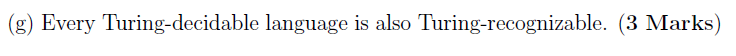
T
e.g4
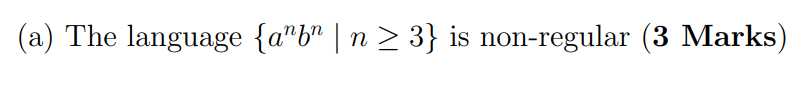
T,can't count a as the same number as b
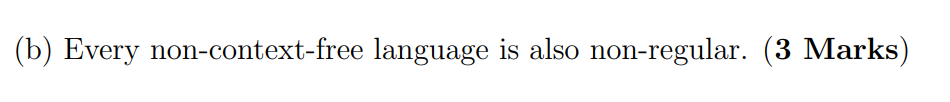
T, the hierarchy of languagr class.....(略)
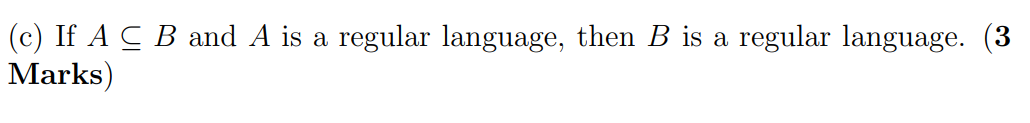
F, 如果B是A就是,但是反过来就不一定了(但是Chatgpt说是T欸)
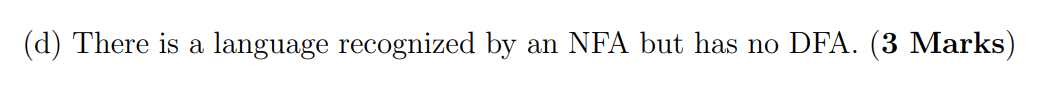
F,NFA and DFA can convert to each other
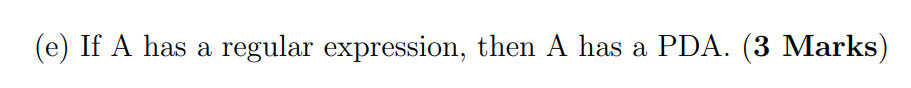
T , if a language A has a regular expression, it means there is an NFA that recognizes ?A.
Since an NFA can be simulated by a PDA, it follows that ?A can be recognized by a pushdown automaton.

F, suppose a language L can be recognized by single-tape Turing machine, it can be also recognized by multi-tape Turing machine. In this case....(略)

F, NDTM and DTM have equal caculate ability, and they can convert to each other. In this case, languages recognized by NDTM could be recognized by DTM.?
e.g5
?1.

字母表为空可能导致形式语言无法表示任何有意义的信息。形式语言的目的是通过一组规则来描述合法的字符串,而这些规则通常要求使用字母表中的符号。如果字母表为空,那么在语言中将没有符号可用,也就无法形成任何有意义的字符串。
2.
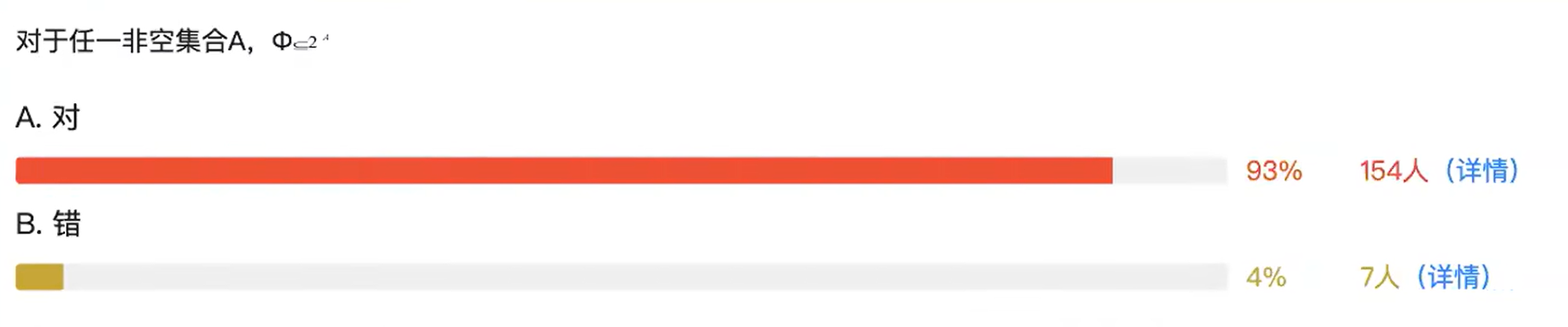
3.
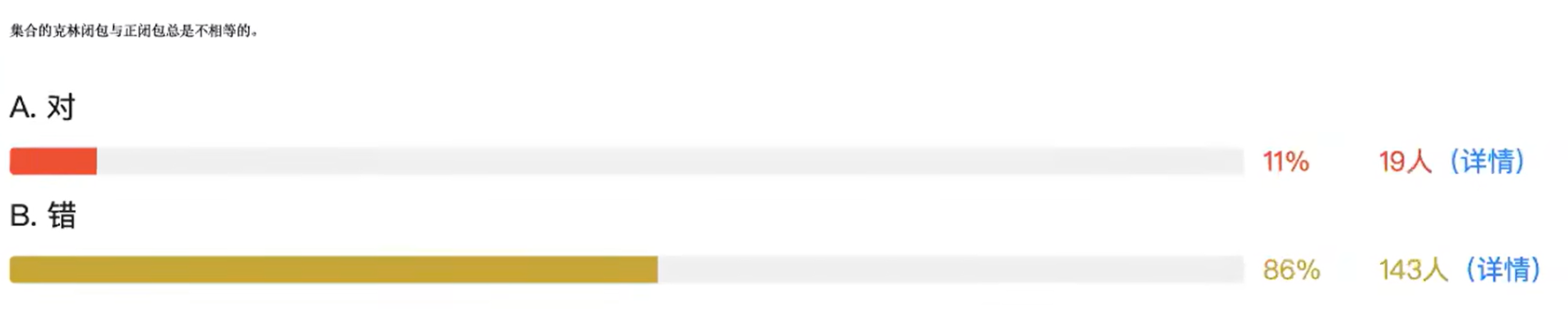
当集合A中包含空字符串时,A的克林闭包和正闭包可以相等。这是因为克林闭包包含空字符串,而正闭包不包含空字符串,但如果A中本身就包含了空字符串,那么两者就是相等的。例如,如果A = {ε, 0, 1},那么A*和A+都是{ε, 0, 1, 00, 01, 10, 11, 000, ...}。
4.
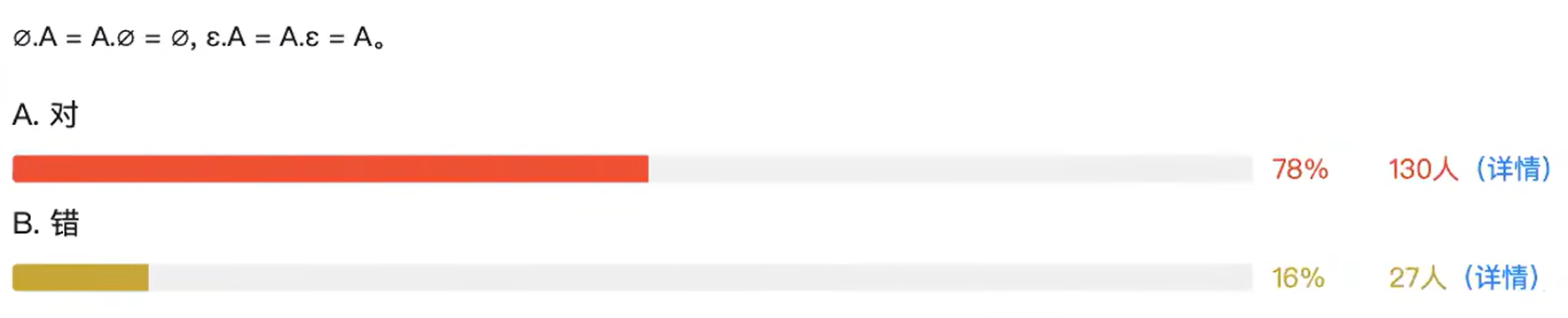
5.

6.

7. ?
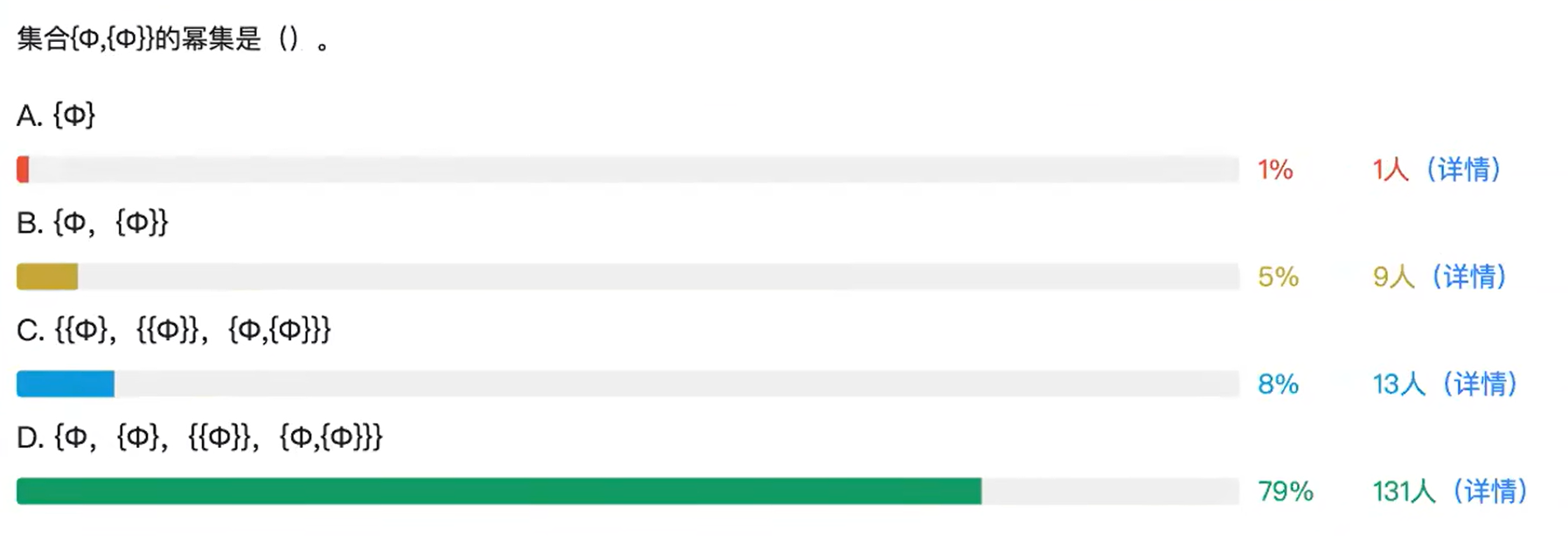
-
空集: 空集合 ? 是任何集合的子集,因此它一定包含在幂集中。
{?}
-
包含一个元素的集合: {?}是原始集合中的另一个元素,我们需要考虑它的子集。这个集合本身和空集都是它的子集。
{{?},?}
-
组合: 现在,我们将第1步和第2步中找到的子集合并,得到原始集合的所有可能子集。
{?}∪{{?},?} ={?,{?}}
-
再次组合: 最后,我们还要考虑空集和原始集合本身,得到答案按
8.
9.

10.

e.g6
?1.
字母表为空可能导致形式语言无法表示任何有意义的信息。形式语言的目的是通过一组规则来描述合法的字符串,而这些规则通常要求使用字母表中的符号。如果字母表为空,那么在语言中将没有符号可用,也就无法形成任何有意义的字符串。
2.
3.
当集合A中包含空字符串时,A的克林闭包和正闭包可以相等。这是因为克林闭包包含空字符串,而正闭包不包含空字符串,但如果A中本身就包含了空字符串,那么两者就是相等的。例如,如果A = {ε, 0, 1},那么A*和A+都是{ε, 0, 1, 00, 01, 10, 11, 000, ...}。
4.
5.
6.
7. ?
-
空集: 空集合 ? 是任何集合的子集,因此它一定包含在幂集中。
{?}
-
包含一个元素的集合: {?}是原始集合中的另一个元素,我们需要考虑它的子集。这个集合本身和空集都是它的子集。
{{?},?}
-
组合: 现在,我们将第1步和第2步中找到的子集合并,得到原始集合的所有可能子集。
{?}∪{{?},?} ={?,{?}}
-
再次组合: 最后,我们还要考虑空集和原始集合本身,得到答案按
8.
9.
10.
e.g7
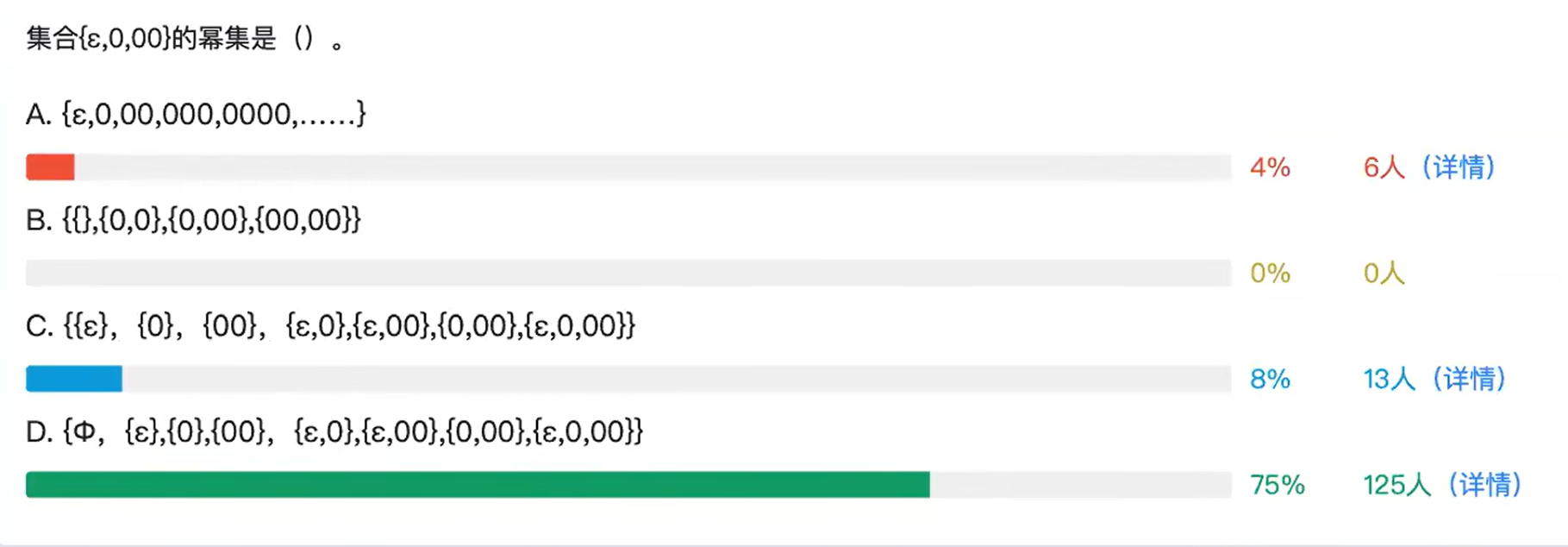
?1. B
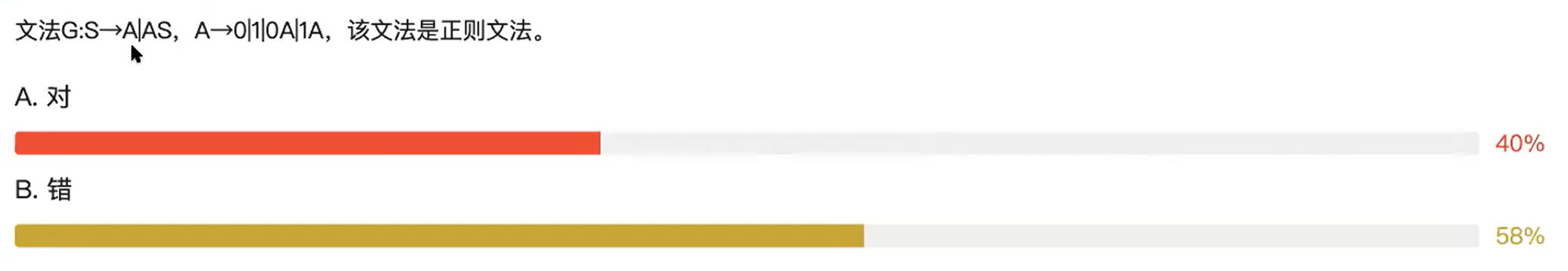
正则文法右边要么是A,AS;0,1,0A,1A,不能像上面那样产生多个变元
2.B
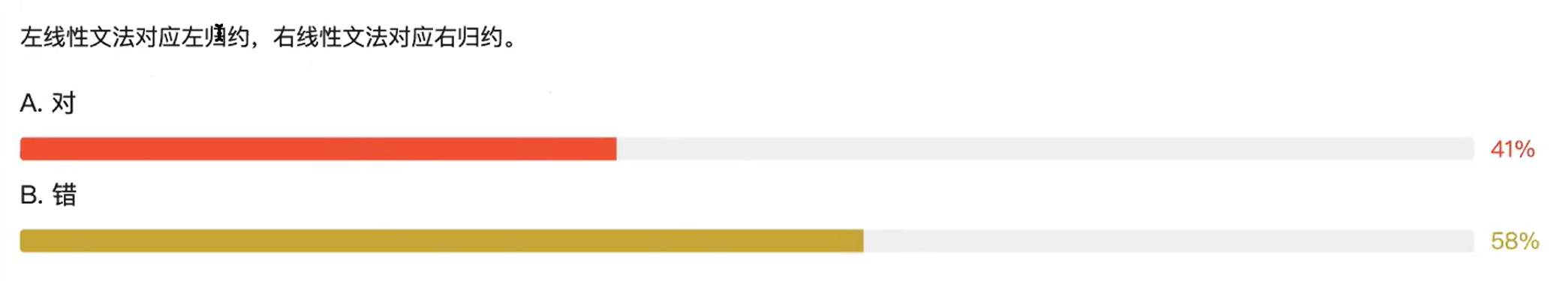
左线性文法对应左规约
3.A

4.A

5.B
严格意义上正则语言不包括ε
6.S-00|11|0S0|1S1?

这里R是反过来的意思
7.最左派生,最右规约

8. S →?ε|0S1|1S0|SS ?![]()
正则表达式
语言→正则表达式
e.g1(?)
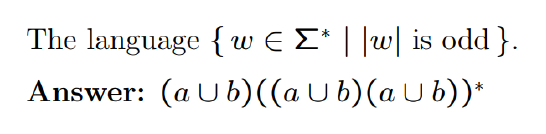
e.g2(*)
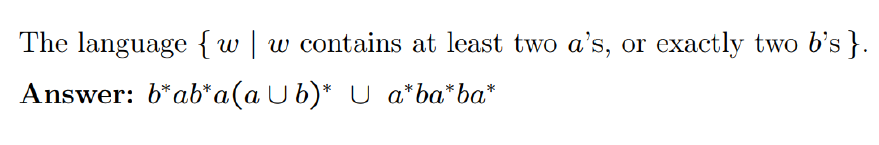
至少俩a: b*ab*a(a|b)*: 以零个或多个b开头,后跟一个a,再后跟零个或多个a或b的任意组合。
准确俩b:a*ba*ba*: 以零个或多个a开头,后跟一个b,再后跟零个或多个a。
e.g3?
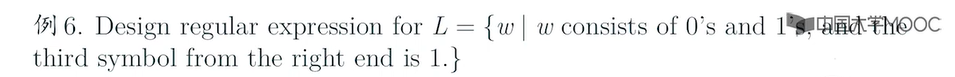
这里(0+1)表示都可以!(0+1)*是表示任意字符串都可以
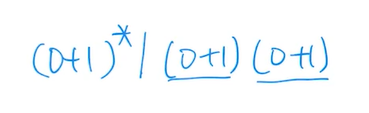
e.g4(*)

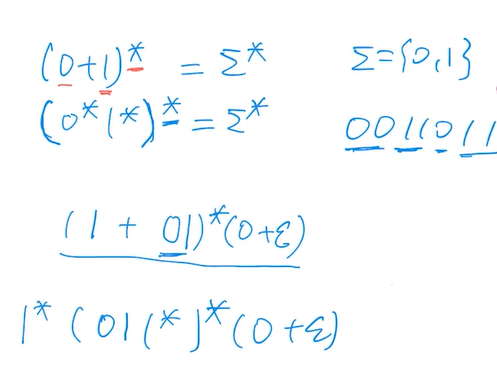
可以啥都不含的情况下记得带一个空串!
最后两行是两种解!
e.g5

e.g6

正则表达式→语言?
e.g1

e.g2

e.g3

正则表达式 →?NFA/DFA/简化DFA?
步骤
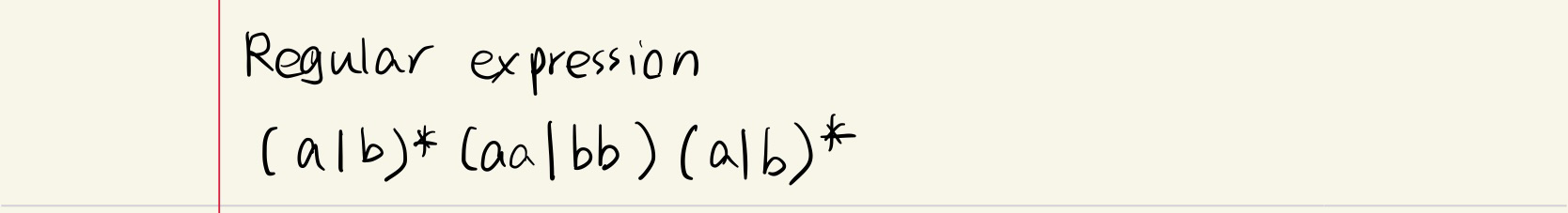
RE → NFA
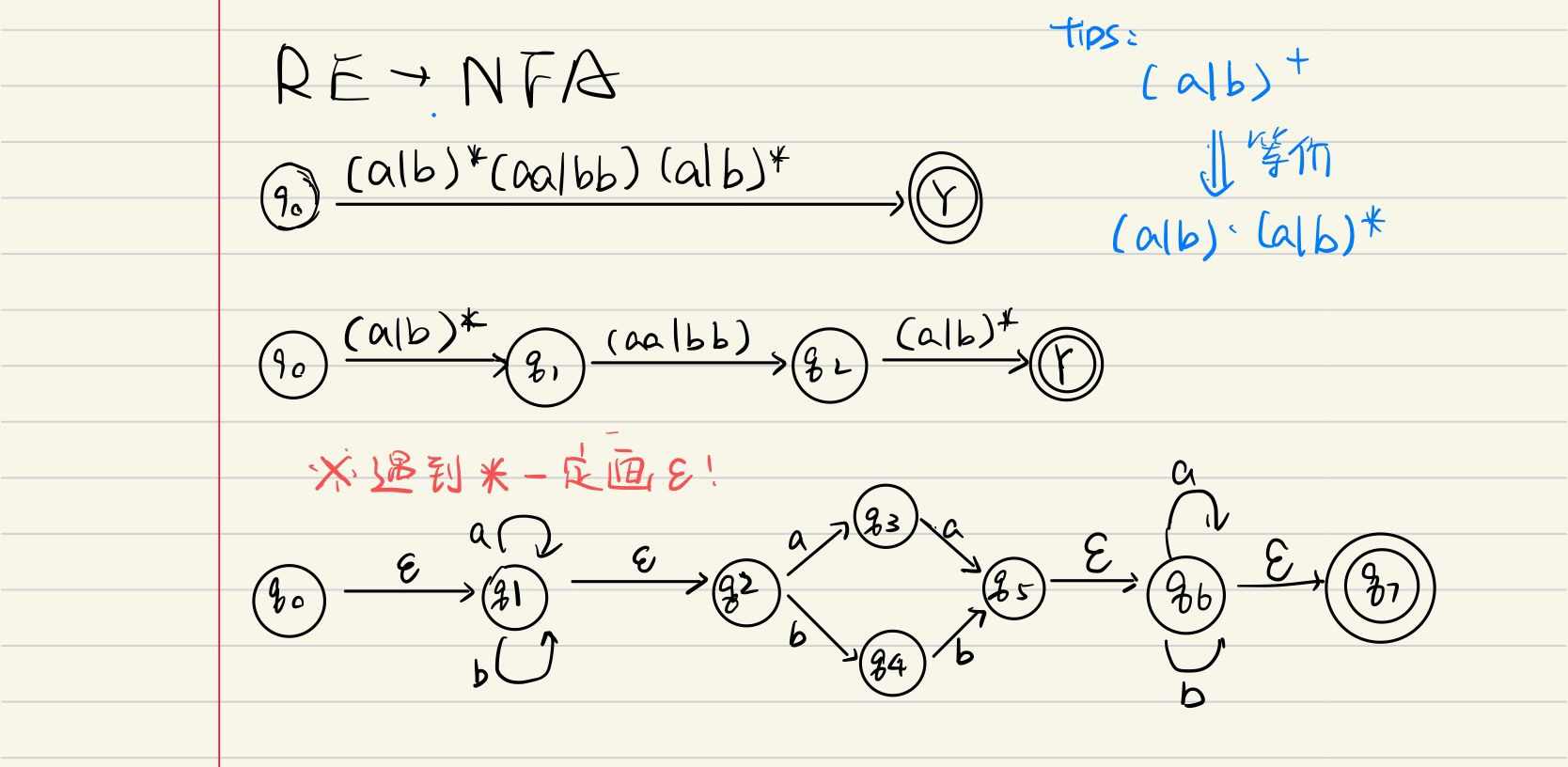
NFA → DFA

DFA化简

e.g1(√)设计DFA

sol
e.g2(√)设计DFA

sol?
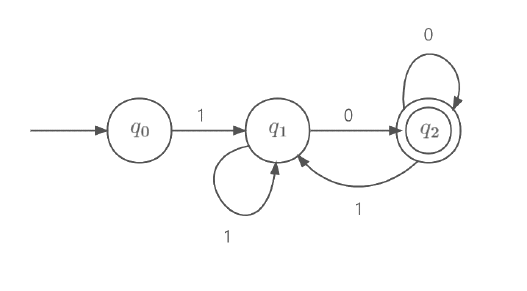
e.g3(*)?
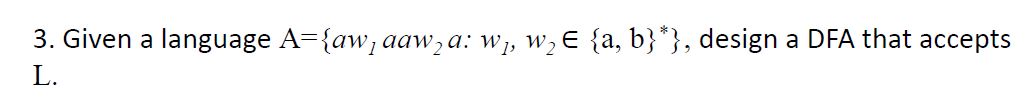
sol?
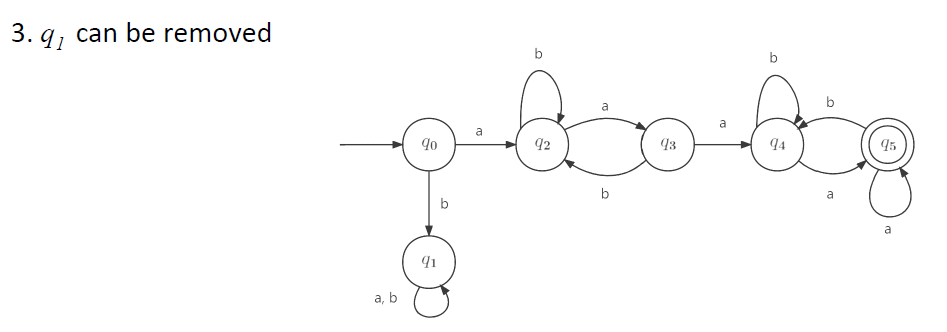
e.g4(√)
p.s? ? binary string是由二进制数字0和1组成的字符串

sol?
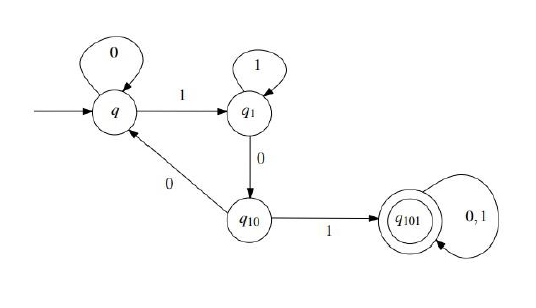
e.g 5(repeat)
本题要写初始和接受状态,并且要写能被接受的字符串
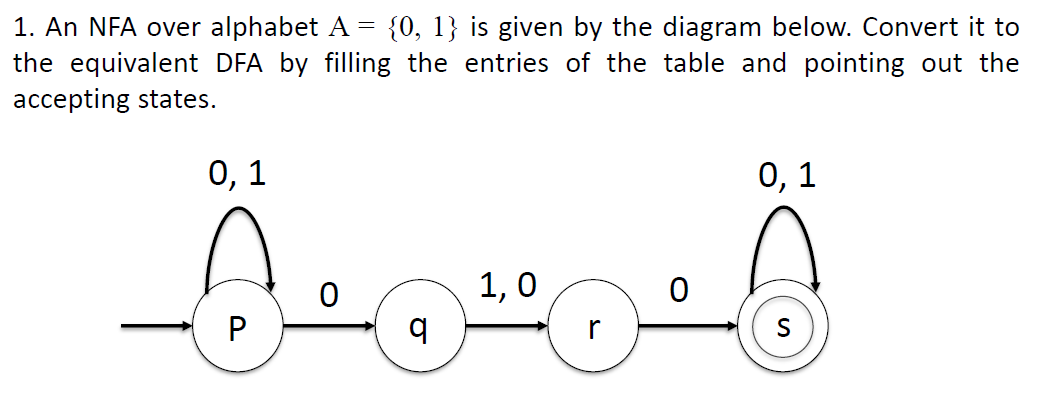
sol

e.g6(*)
给出具有指定数量的识别下列每种语言的状态的NFAs


e.g7(*)
有涉及反转字符串欸,同时second-to-last是倒数第二个的意思

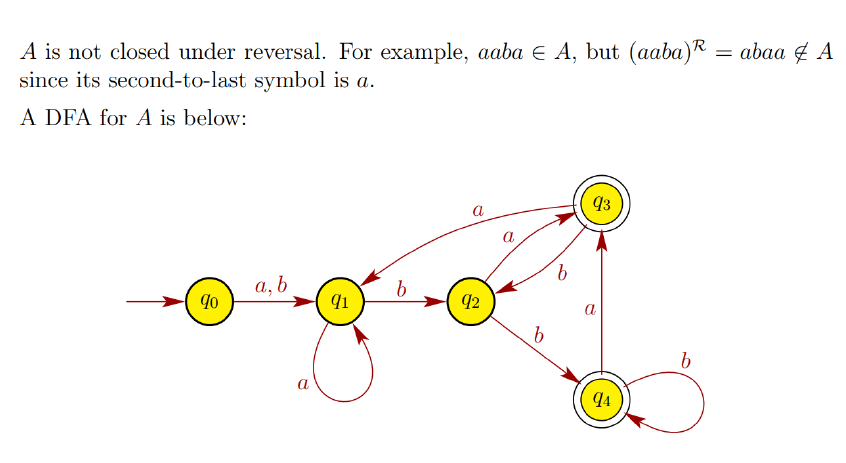
e.g8 (*)
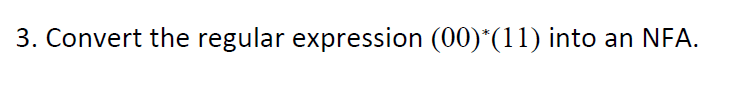
sol
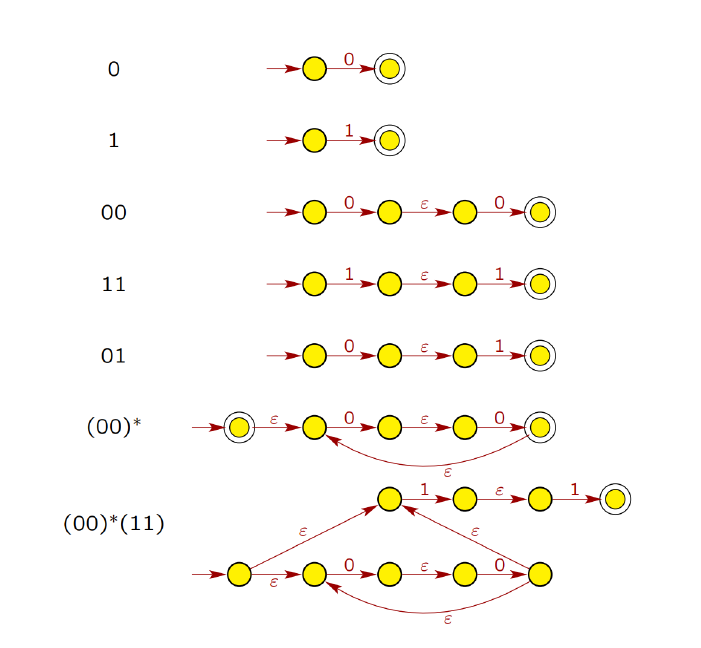
e.g10?ε -NFA会考吗?

e.g11 语言→DFA

e.g12 L→DFA/RE

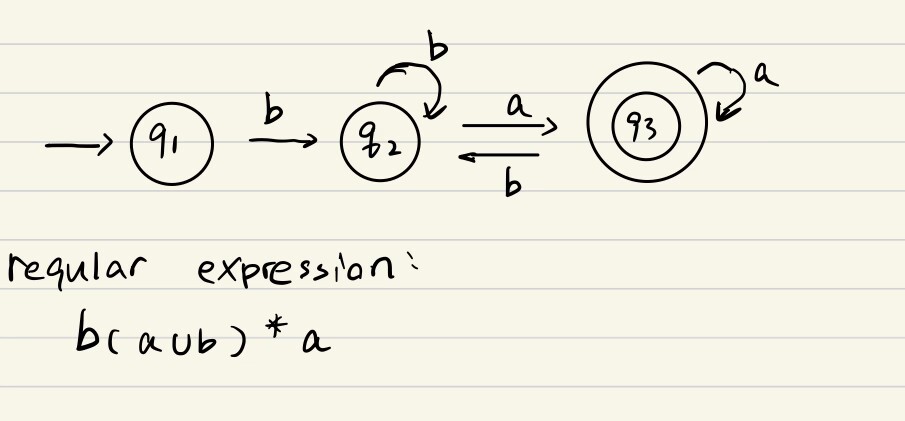 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? e.g13 L →NFA
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? e.g13 L →NFA
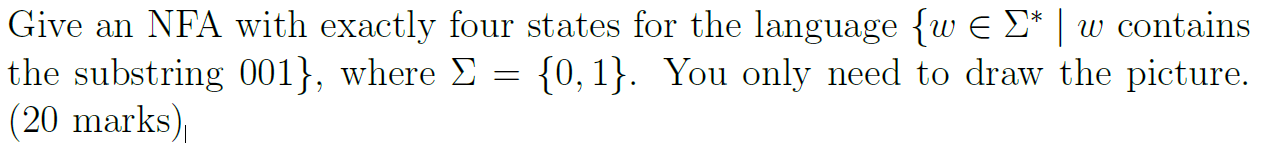
 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
e.g14?

e.g15? NFA→DFA
?

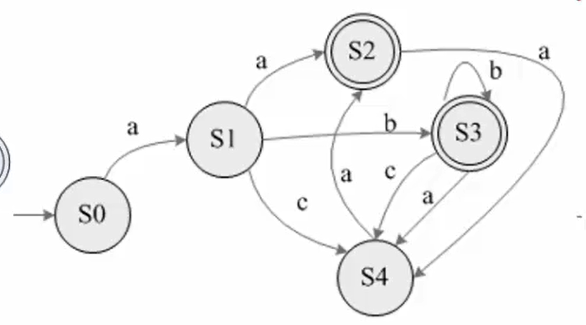
e.g16 NFA →DFA
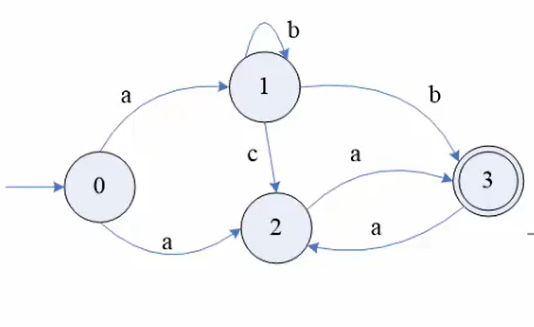
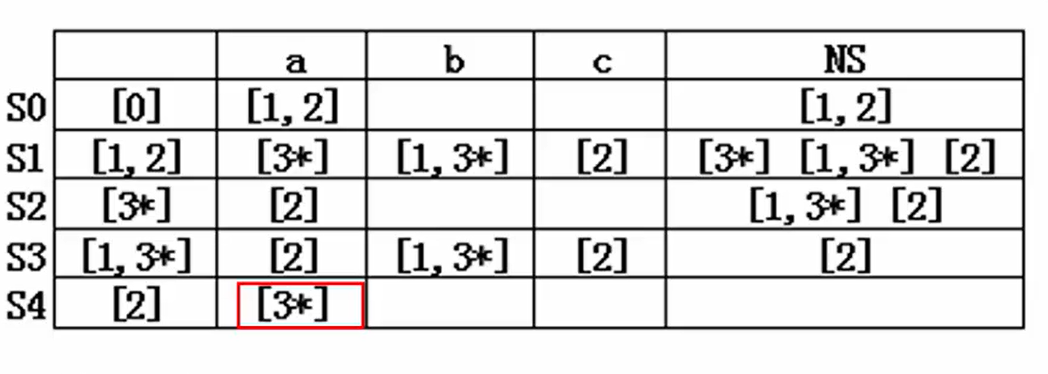
?
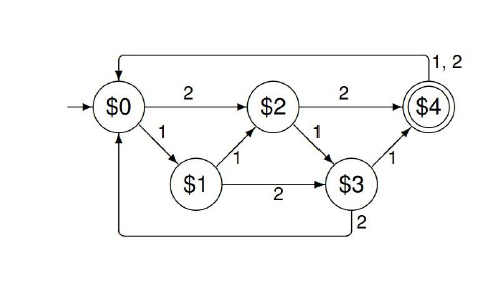
DFA →正则表达式
e.g1
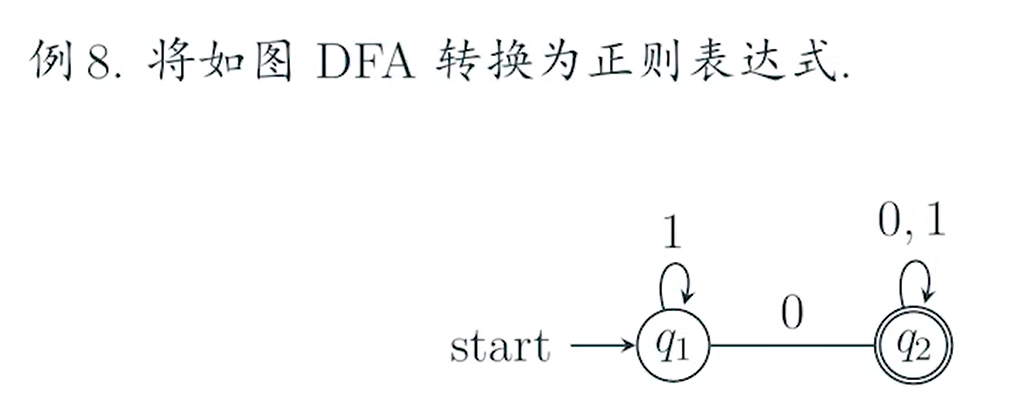
sol 1*0(0+1)*
e.g2
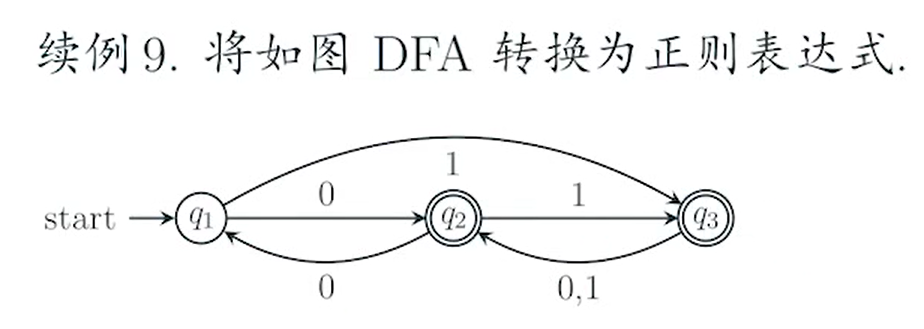
sol?
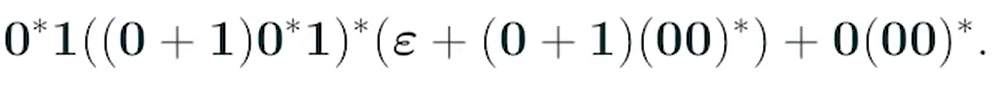
e.g 3
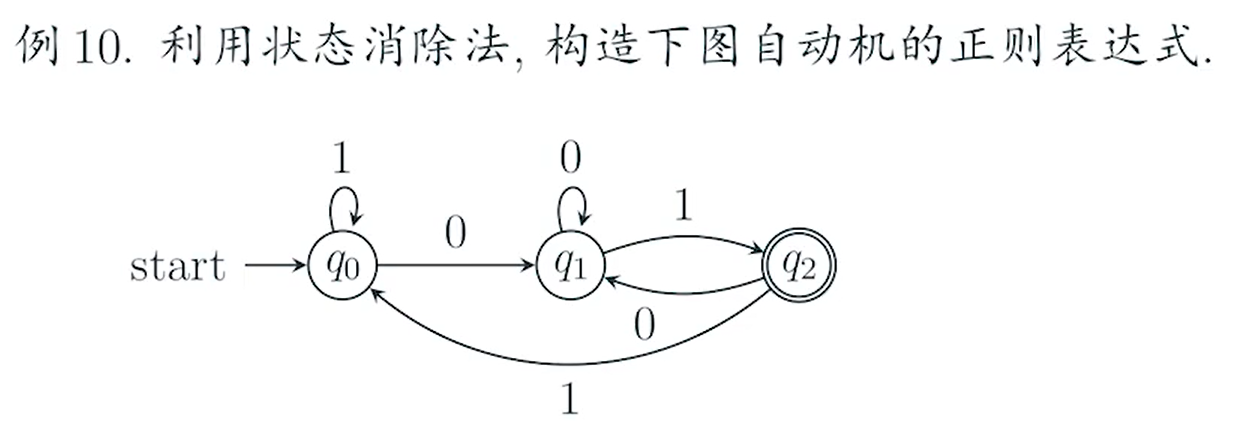
sol
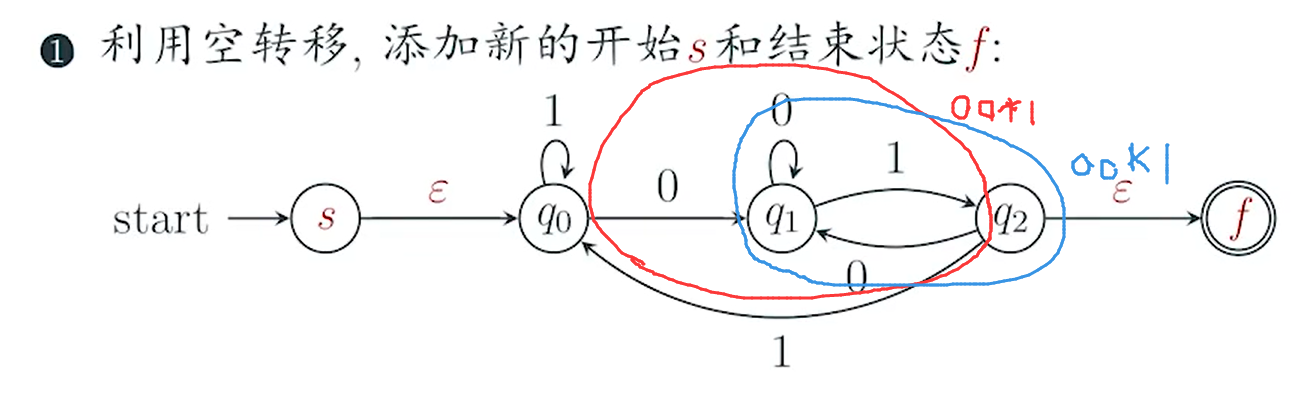
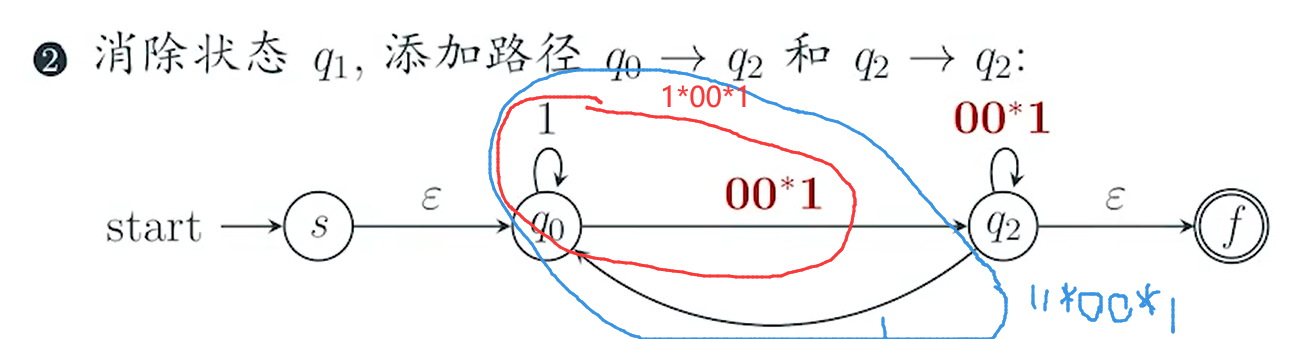

DFA定义?
e.g1
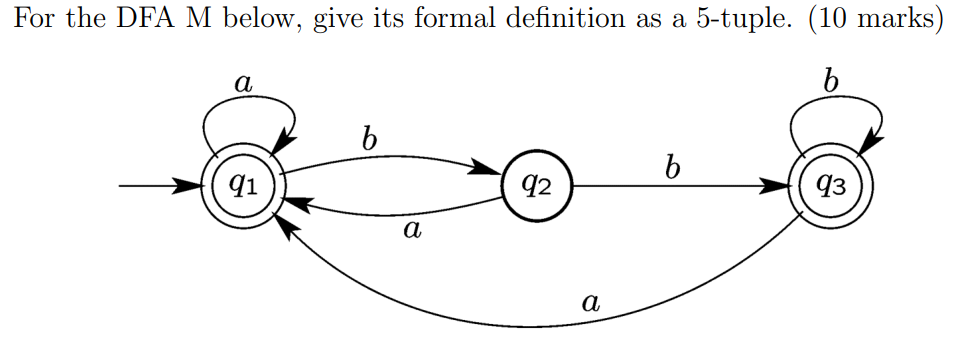
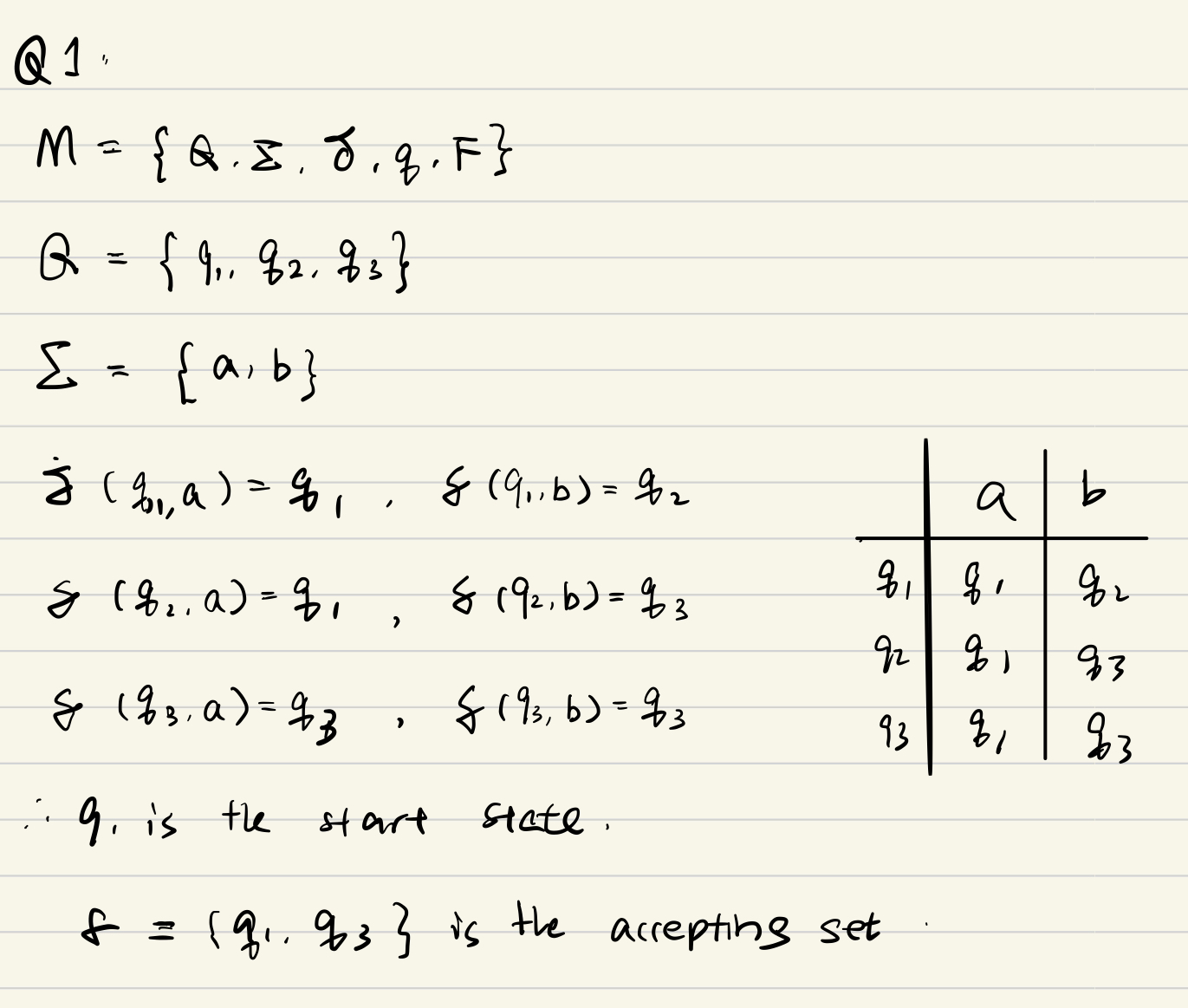
e.g2

DFA化简
e.g9()
DFA简化
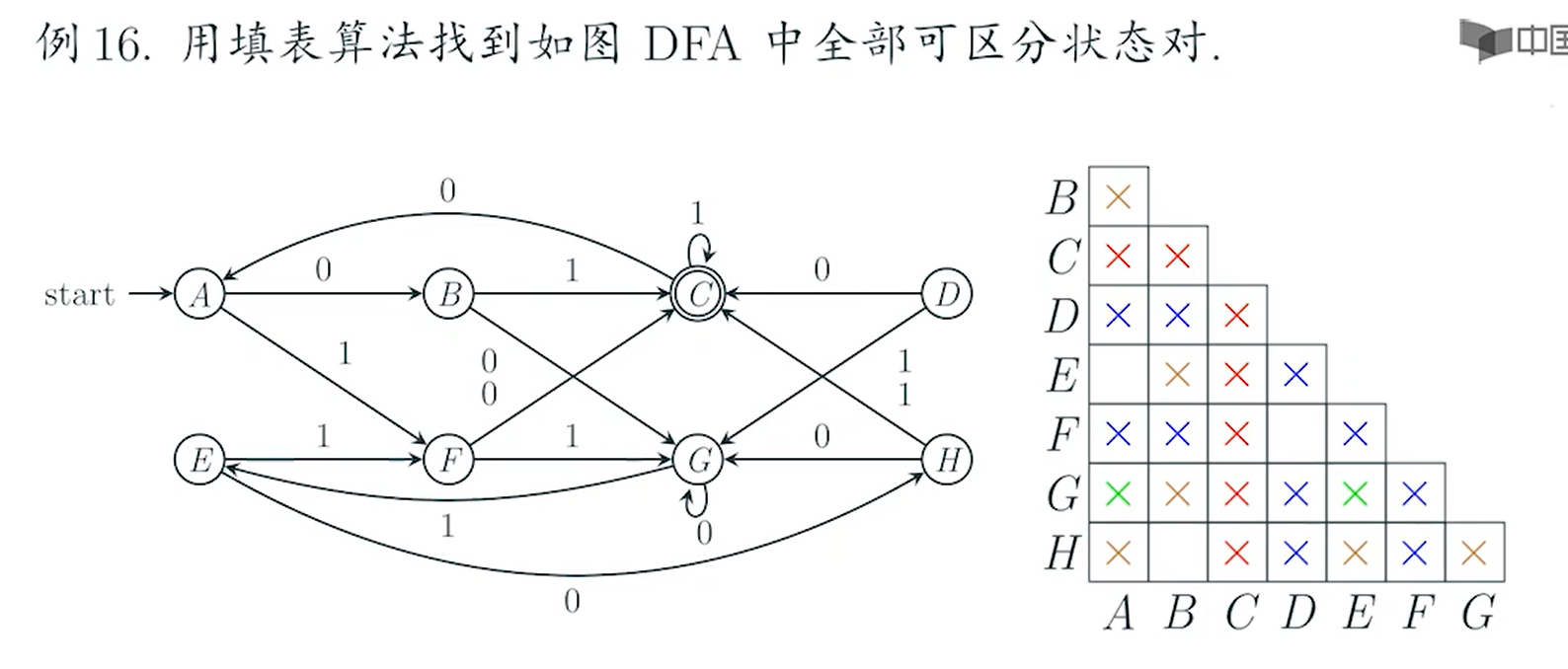




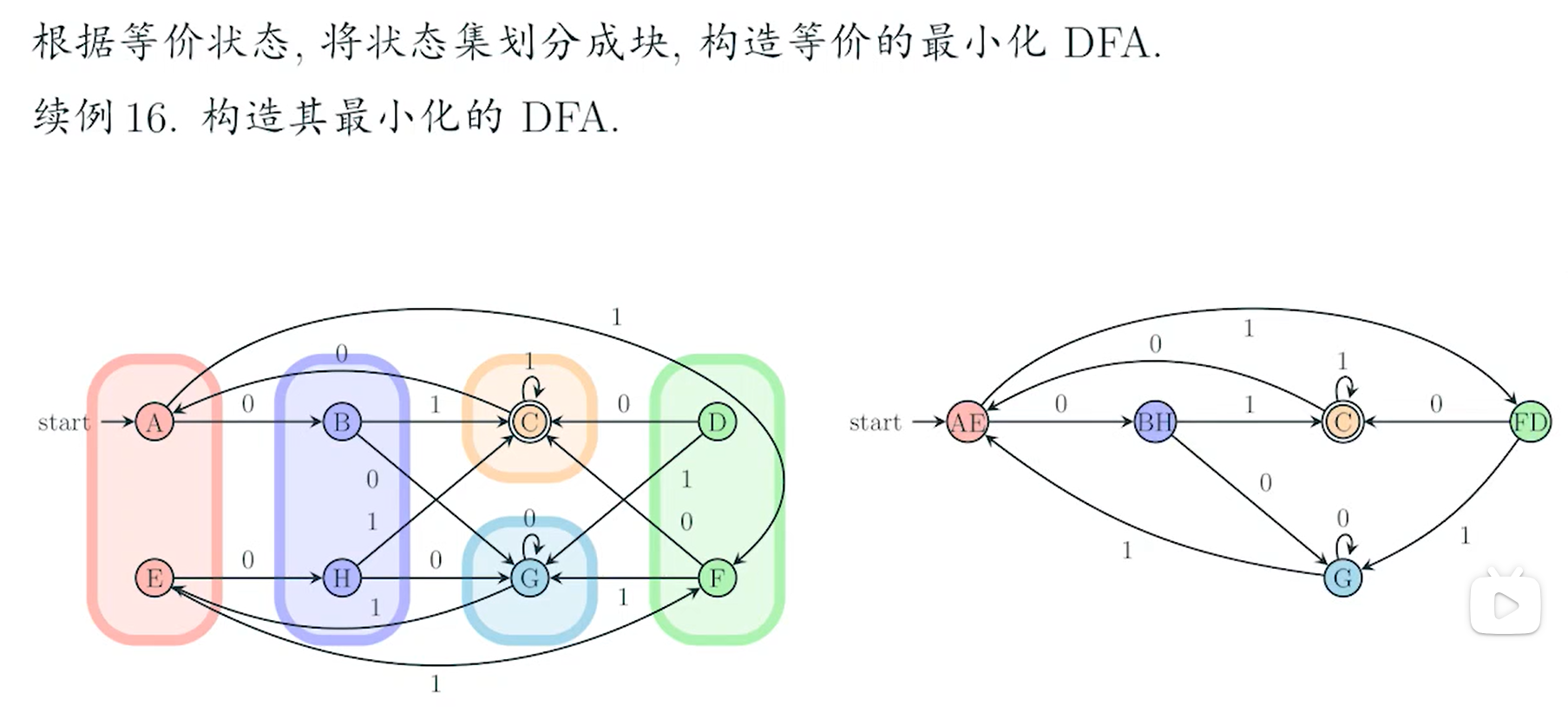
e.g10?
?



正则语言判定
观察法↓
e.g1
是
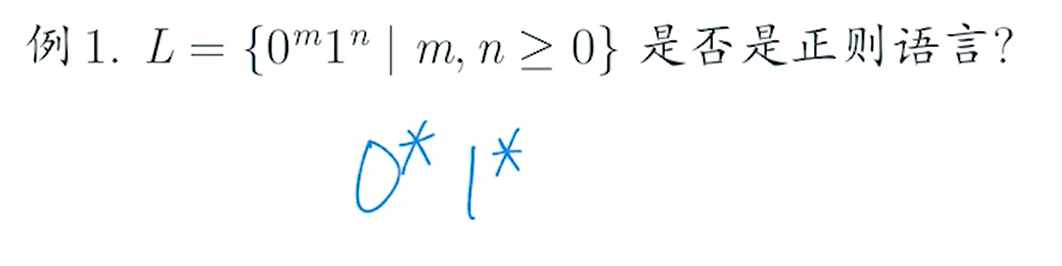
e.g2?
是
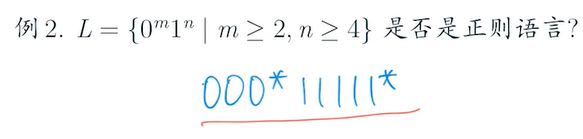
e.g3
需要有穷自动机记忆0的数量匹配1的数量然而有穷自动机无记忆力,无法识别,所以不是

注意!有限的语言是正则语言!
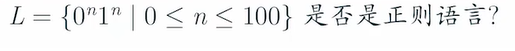
是!
e.g4
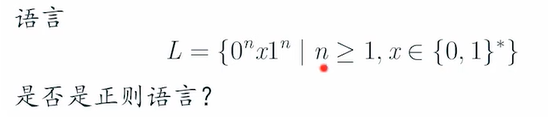
是!表达式为0(0+1)*1
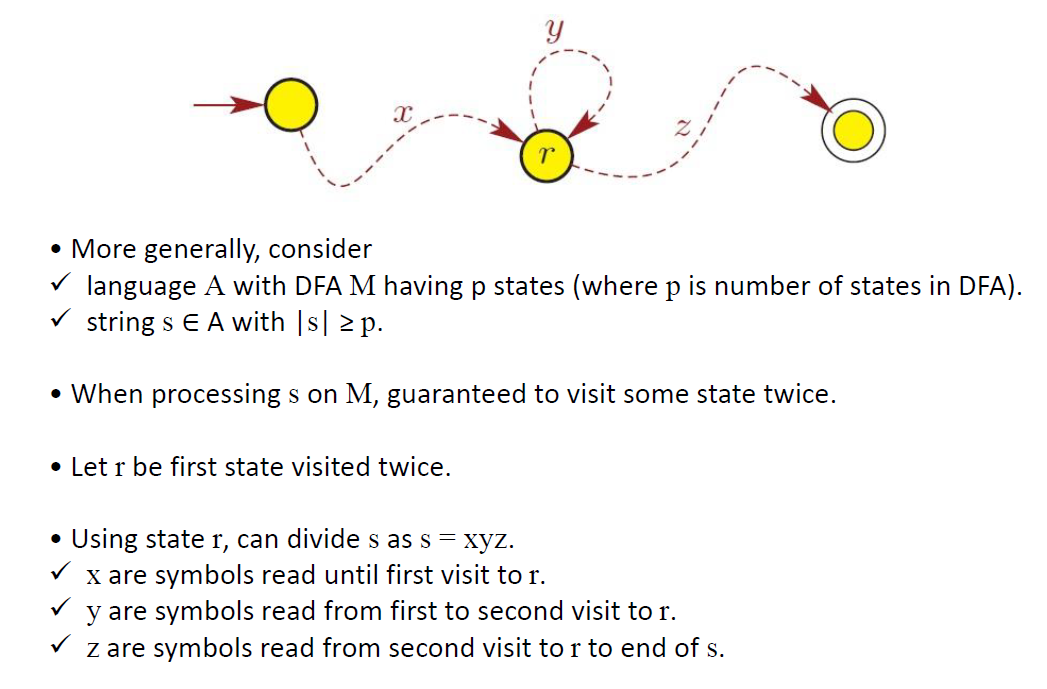
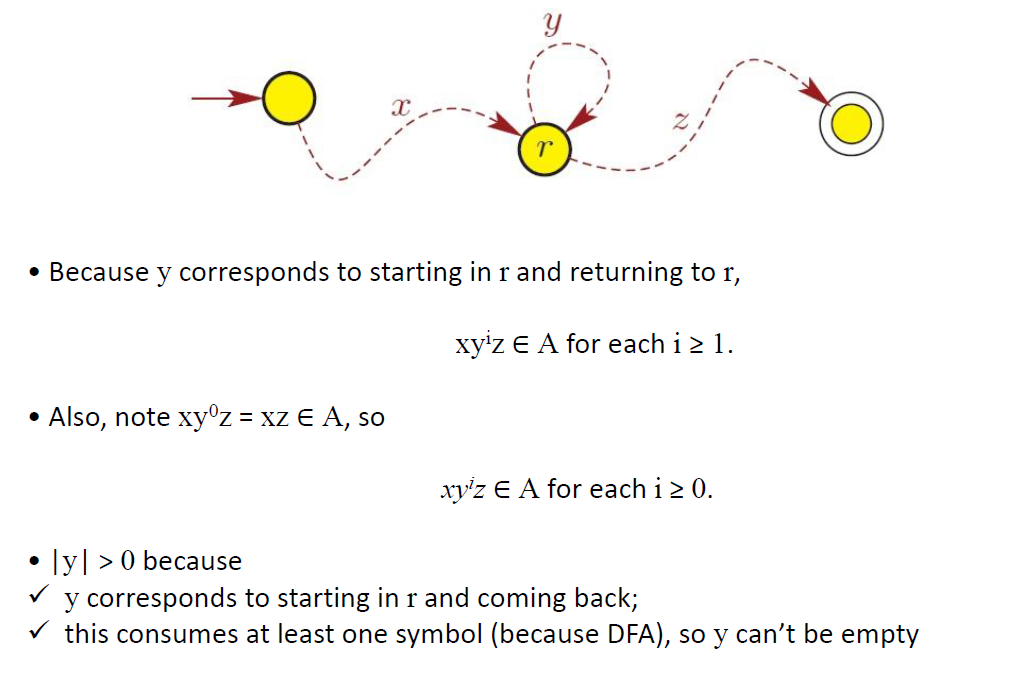
泵原理 Pumpping lemma
e.g1
证明不是正则语言需要用反证法
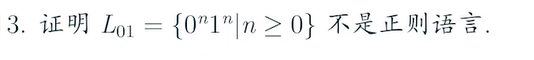
sol

w是>=n的字符串
|xy|<=n是为了让y容易证明(只能为0)
e.g2

居然和e.g1证明过程一样.....

e.g3
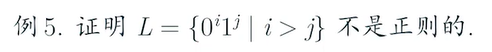

e.g4
有的时候y的情况可能会有点些复杂,只能穷举
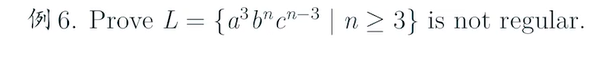

e.g5
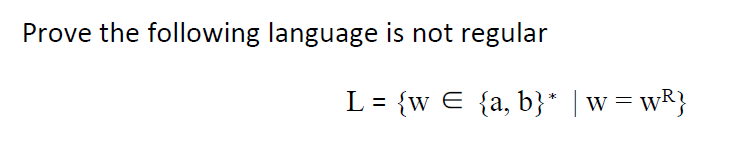
sol

e.g6
test 20-21

a) 我也不知道怎么写,这个答案是问chatgpt的
The Pumping Lemma is a useful tool for proving that certain languages are not regular. The Pumping Lemma states that for any regular language, there exists a constant p (the "pumping length") such that any string s in the language, with length at least p, can be split into three parts, s=xyz, satisfying the following conditions:
The idea behind the Pumping Lemma is that if a language is regular, then any sufficiently long string can be "pumped" to generate an infinite number of strings still in the language. If you can show that a language does not satisfy the Pumping Lemma, then it cannot be regular.
steps:
1. Assume for the sake of contradiction that the language is regular
2. Choose a specific string from the language
3. Express the string as s=xyz.
4. Consider the possible cases for y
5. Show that there exists an i for which xy^iz is not in L.
6.Conclude that the assumption is false
b)


e.g7

e.g8

e.g9

e.g 10

?e.g11
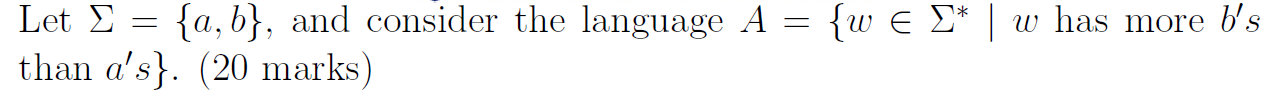
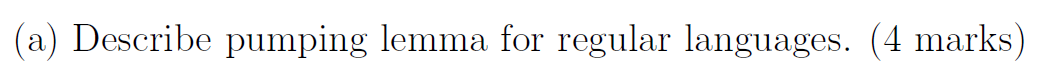

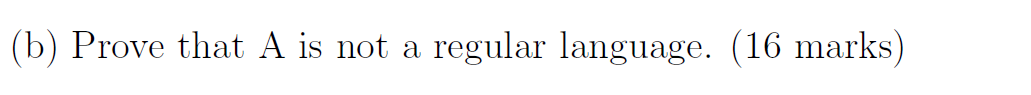

e.g12 这个是证明是正则语言




封闭性
e.g1

sol

综合题
e.g1
test20-21


CFG上下文无关语言
Context-free gramma 构造
e.g1(*)
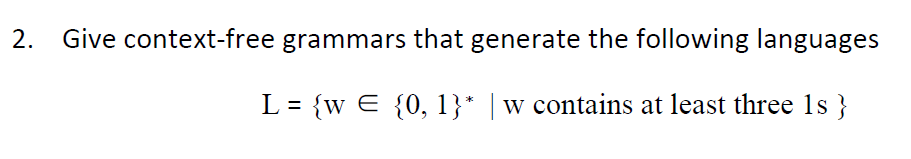
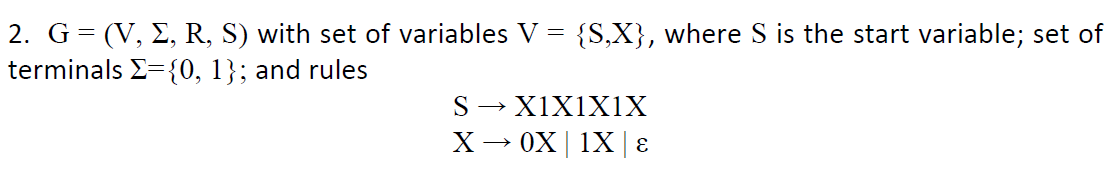
?e.g2(*)
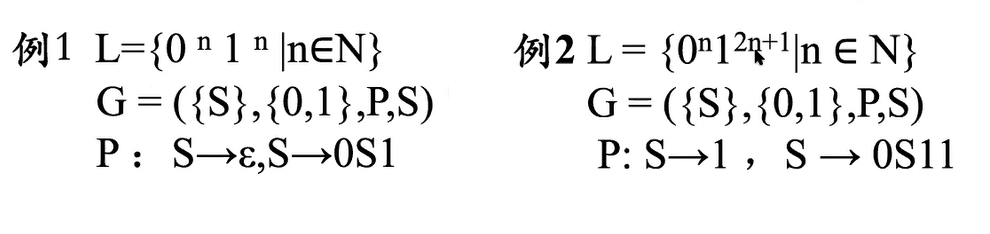
e.g3(*)
像这种至少包含的就应该引入一个新的变元

e.g4(*)

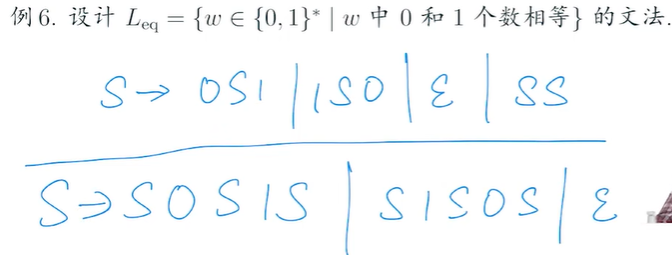
e.g5(?)

就不能直接ab吗
e.g6(?)


e.g7 G→L
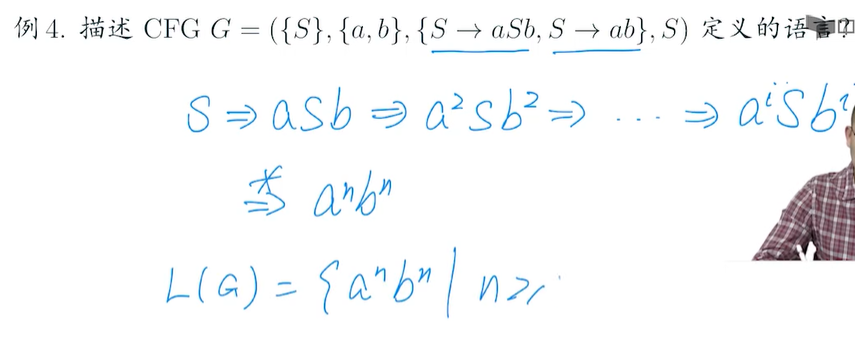
CFG 和 CNF (Chomsky Normal form) 转化
步骤
?步骤1。从规则的右侧删除start变量。

步骤2。去掉?ε-rules A→ε,其中A∈V?{S}
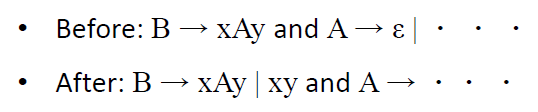
当删除A→ε-rules 时,插入所有新的替换:
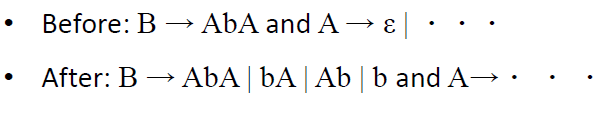
步骤3。移除单位规则A→B,其中A∈V。
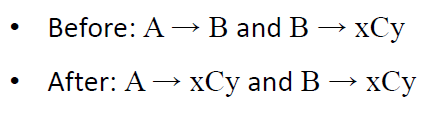
步骤4。消除所有右边有两个以上符号的规则。
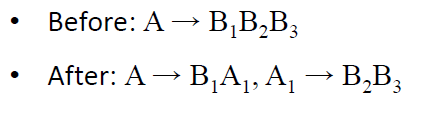
第5步。消除所有形式为A→ab的规则,其中a和b不都是变量。
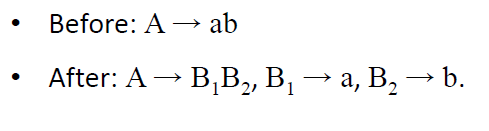
e.g1(*)
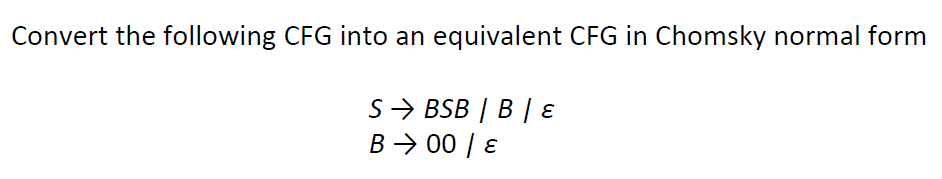
sol



e.g2

e.g3


e.g4


字符串派生(请问这个只能用眼睛看吗)
e.g1?

sol
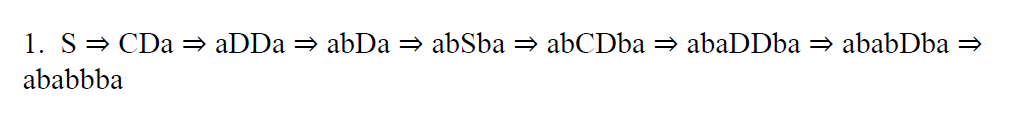
e.g2
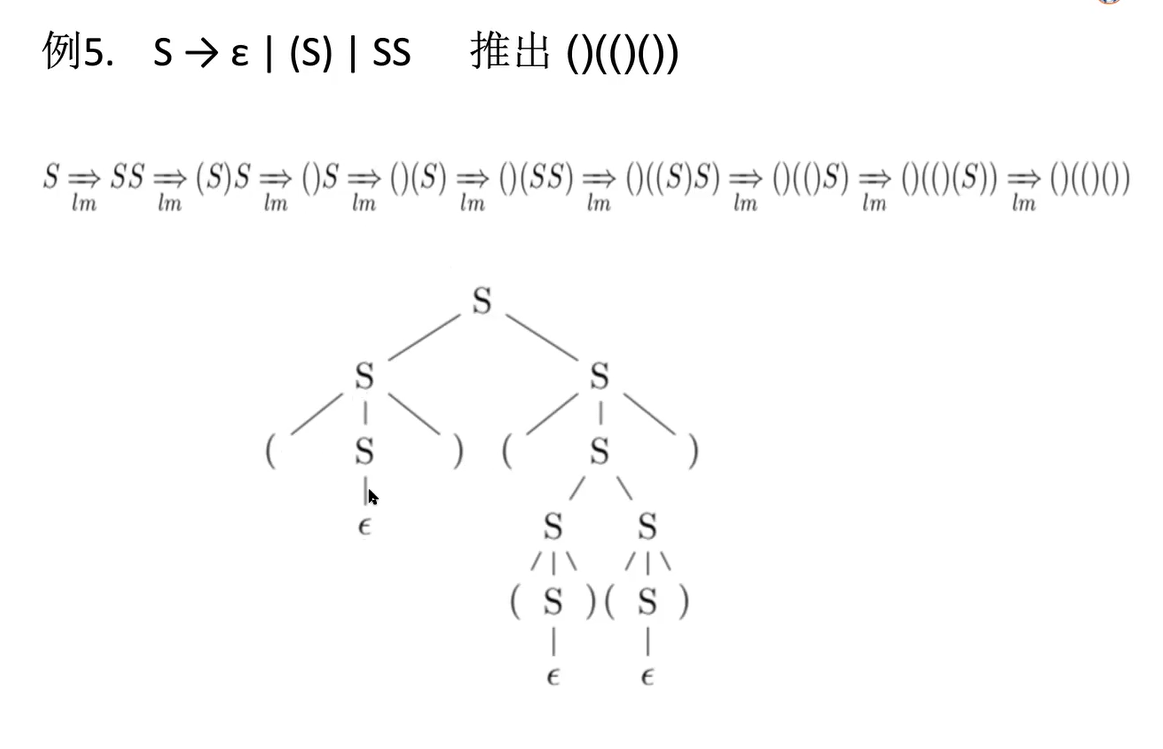
e.g3

派生树

e.g
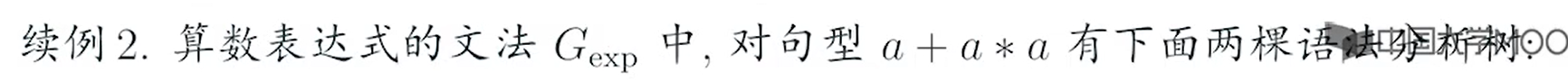
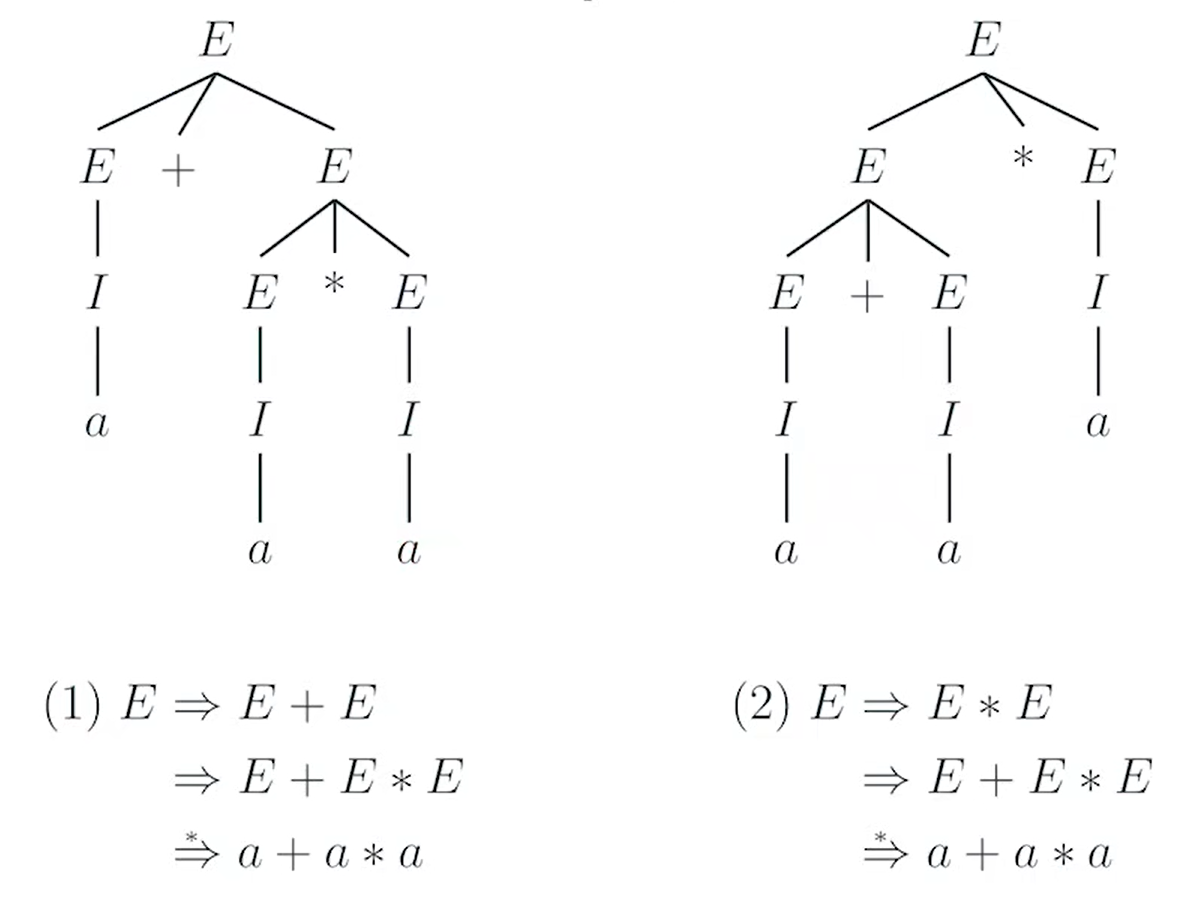
转换范式以及化简
step1消除空串
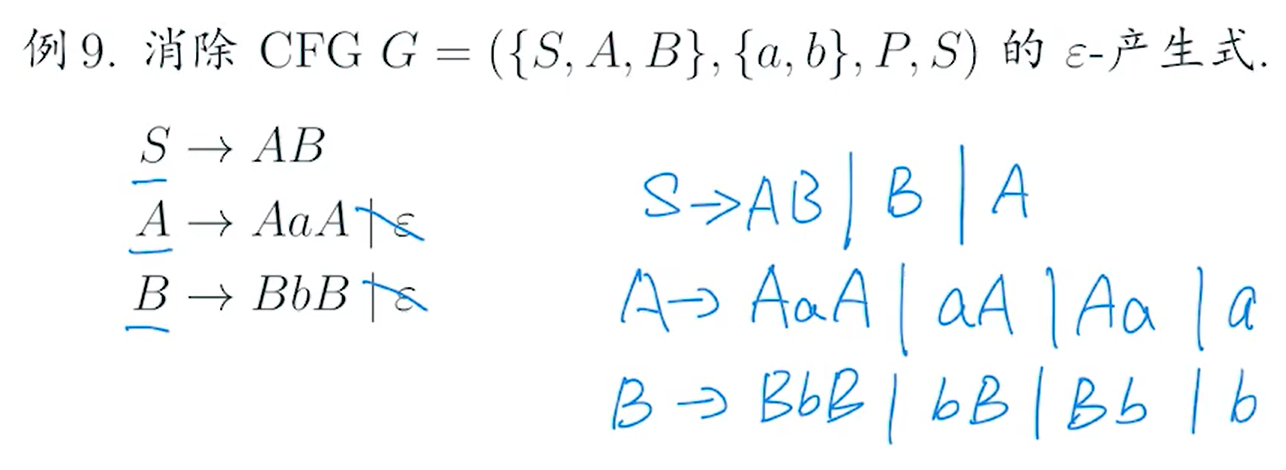
step2消除单元产生式

?step3消除非可产生的无用符号?step4 消除非可达的无用符号

e.g2
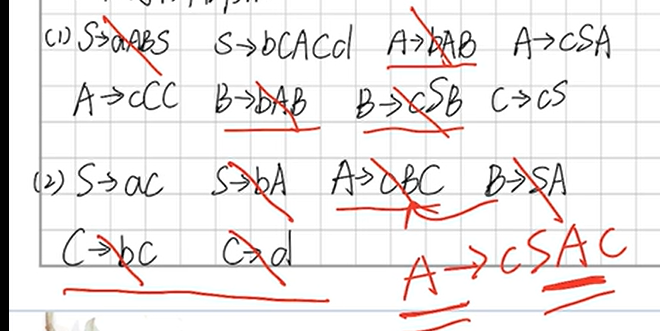
PDA 下推自动机

设计PDA
e.g1 L→PDA
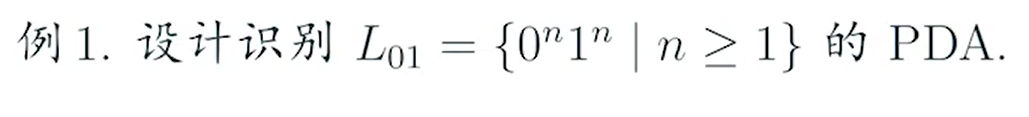
e.g2 L→PDA
注意其有非确定性的性质,所以当且仅当满足需求的时候才能跳转到最终态


e.g3 L→PDA(*)
e.g4(?)
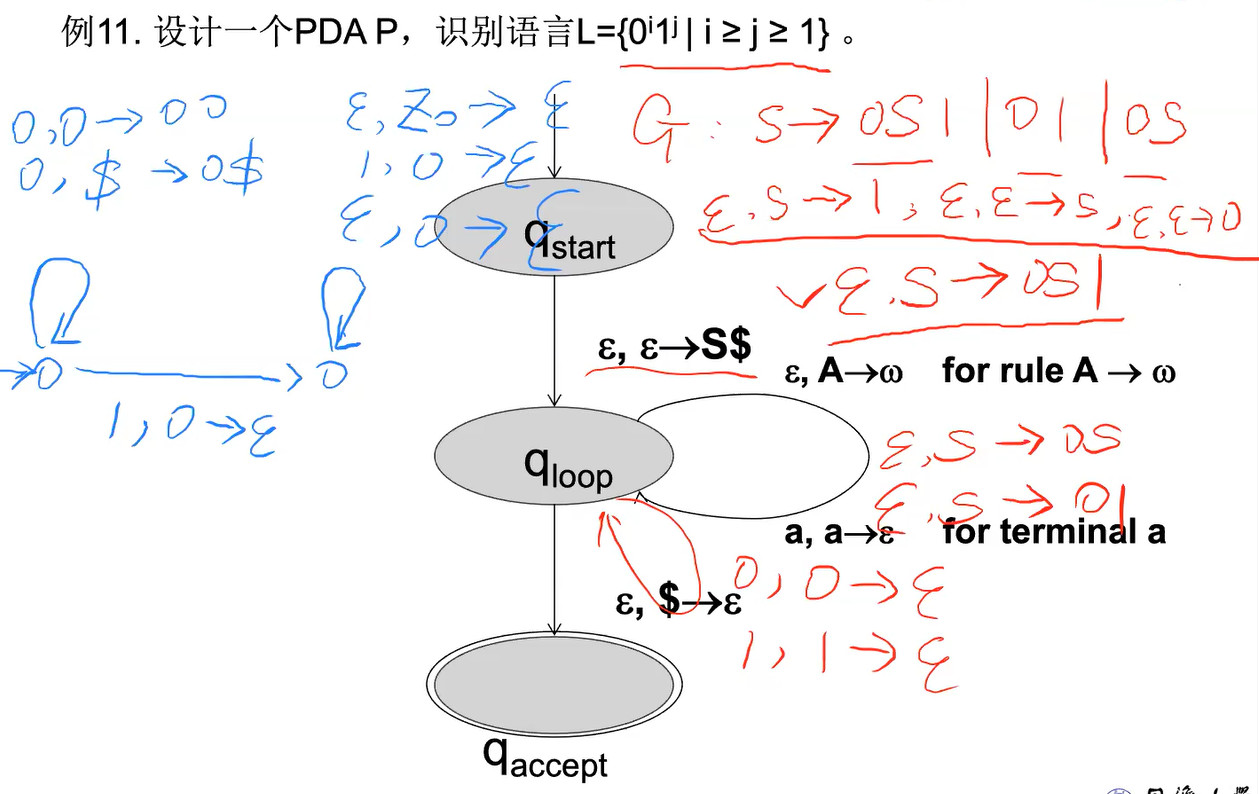
PDA状态
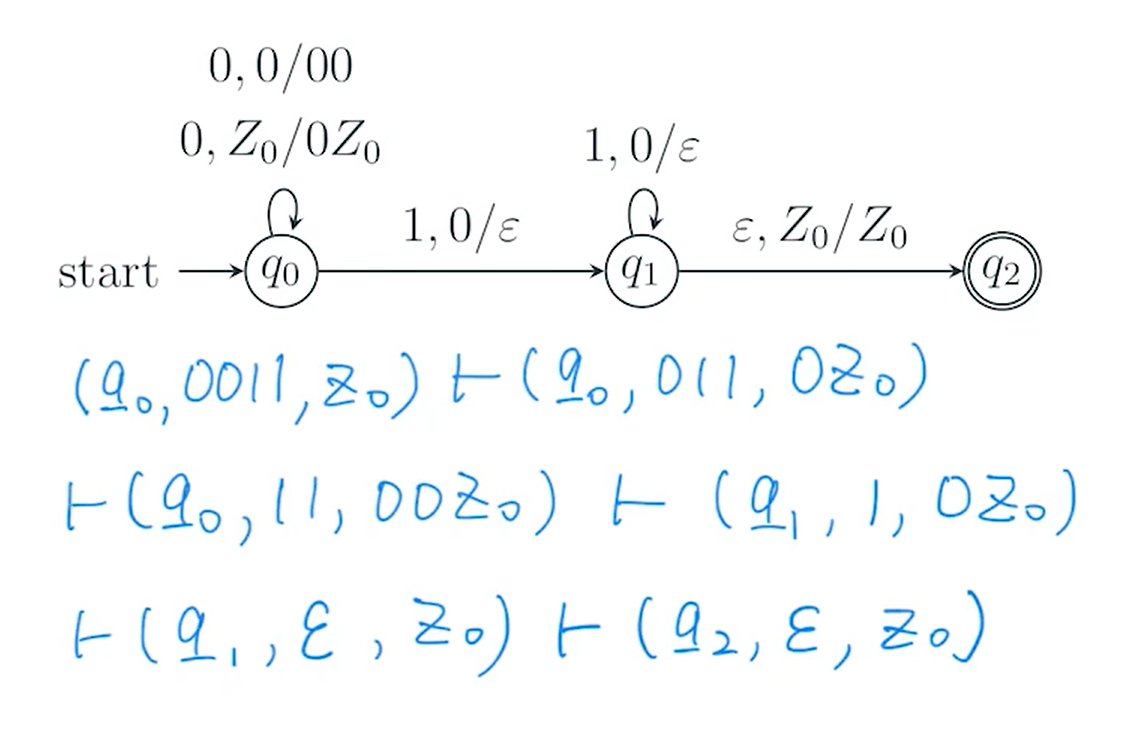
等价性 equipment***
e.g1 绘图并说明等价性
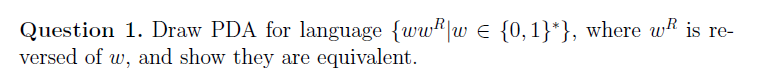
sol


首先,对于任何s = wwR,当w被处理后,非确定性PDA有一个进入q3的分支。此时,我们记为时间0,stack0[i] = w[len(w)?1?i],其中stack0[0]为栈顶,且0≤i≤len(w)?1。
在q3中,它一个一个地清理堆栈元素,当它在第k次pop时,wR[k] = stack [0] = stack0[k] = w[len(w)?1?k]总是允许转换发生。当所有东西都被消费时,我们看到$并进入接受状态。
对于被此PDA接受的字符串S,很明显,接受历史可以分解为S = ab,其中a, b是长度相等的字符串。因为要看到$,在q2处处理的符号数必须等于q3处处理的符号数。当q3弹出第k个元素时,我们得到b[k] = a[?k] 因为堆栈弹出正在被推入的内容。换句话说,我们有b = aR,所以它在{wwR|w∈{0,1}?}中。
关键在于,PDA可以接受一种语言,但也可以接受该语言之外的一些其他字符串(否则,我们可以让PDA接受所有字符串)。为了排除这种可能性,我们需要显示PDA接受的所有字符串都是该语言。
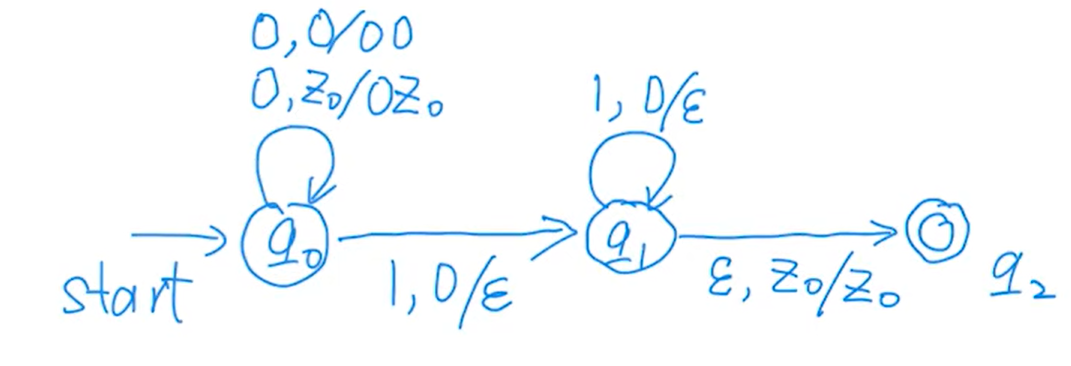
e.g2
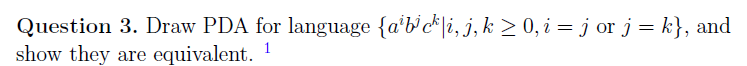
sol

对于{aibjck|i, j, k≥0,i = j或j = k}中的每个字符串,它要么在{aibjck|i, j, k≥0,i = j}中,要么在{aibjck|i, j, k≥0,j = k}中。如果是i = j的情况,它会经过q1 q2 q3 q4。从q1开始,λ过渡将其移动到q2,在那里它计算a的数量,并移动到q3,因为i = j,它以相同的频率看到b,并应用λ, $→λ移动到q4,剩下的唯一符号是c,所以它停留在q4被接受。如果是j = k的情况,机器移动到q5,在不改变堆栈的情况下处理a,然后在q6中计数b,并在q7中看到与b相同数量的c,并移动到接受状态q8。
对于这个PDA接受的每个字符串,它要么输入q4,要么输入q8。如果它进入q4,在弹出$之后,它只看到c。然后在q3,假设它调用了{b, a→λ} j次对应于b的数量,在q2, {a, λ→a}必须被调用至少j次。然而,由于q3在jbs之后看到$,{a, λ→a}必须被调用恰好j次。我们有相等数量的a和b。因此,字符串将在{aibjck|i, j, k≥0,i = j}中。
同样,如果它进入q8,它将在{aibjck|i, j, k≥0,j = k}中。
总的来说,如果它被这个PDA识别,它必须在{aibjck|i, j, k≥0,i = j或j = k}
?PDA识别问题

?e.g1 双栈PDA🤔


e.g2 概念证明


e.g3 概念证明?
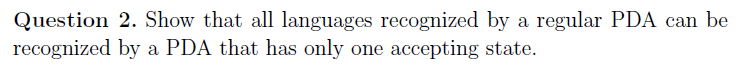

e.g4 概念证明
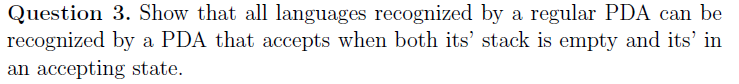

e.g5 概念证明



CFG→PDA
e.g1
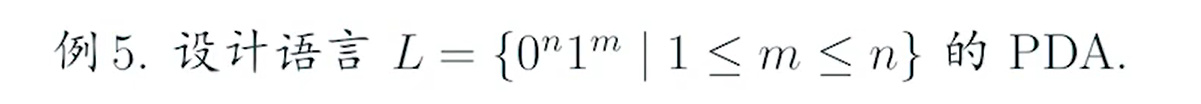
sol1
利用不确定性,所以0可以匹配空串

sol2

e.g2 模拟文法最左派生解法
(感觉其实不太好用)

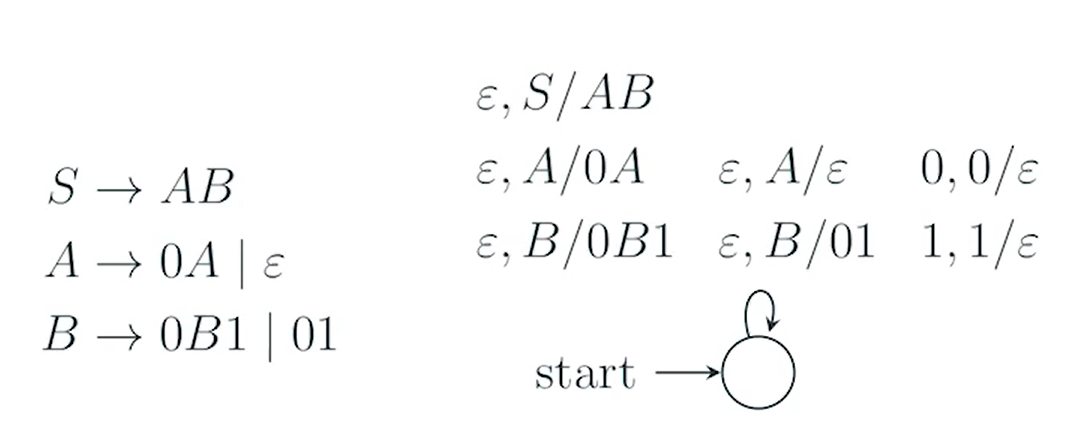
e.g3**
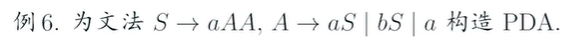
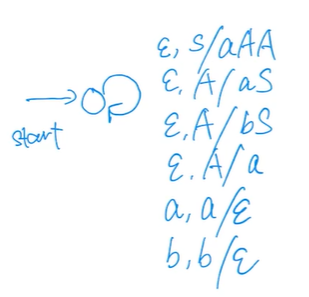
e.g4(?)


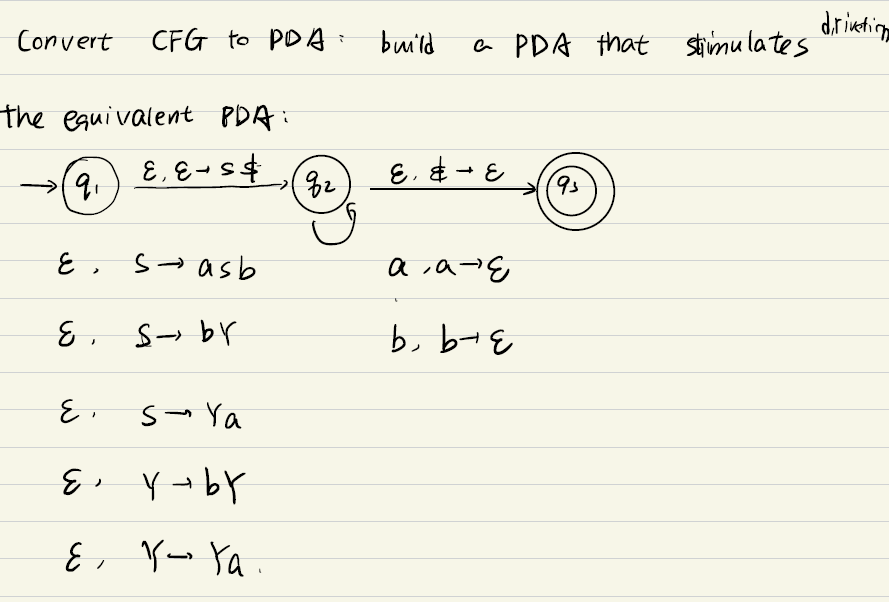

PDA→CFG
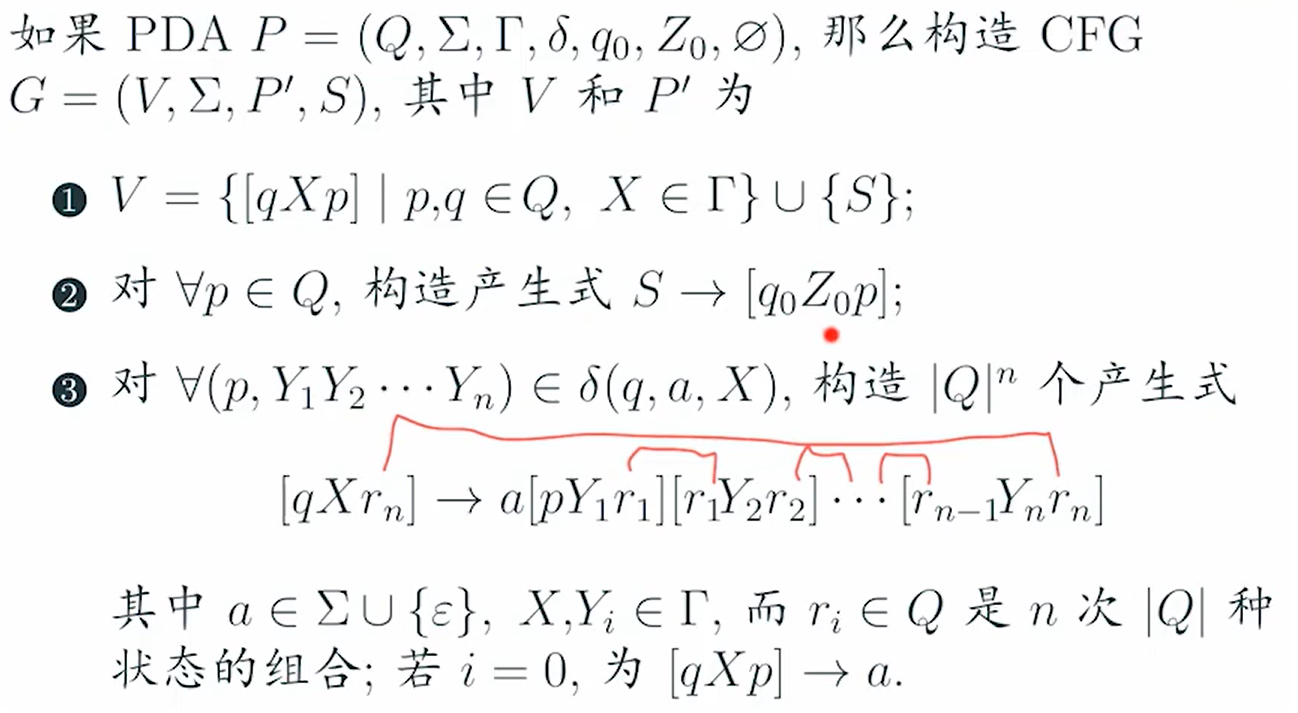
e.g 1?
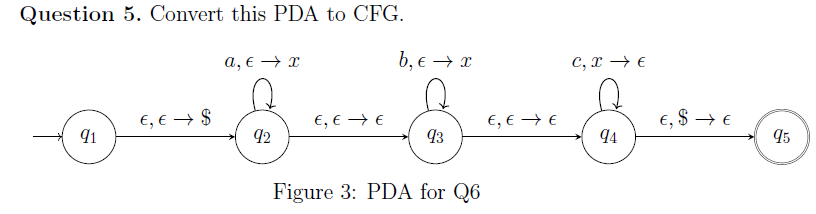
sol

e.g2
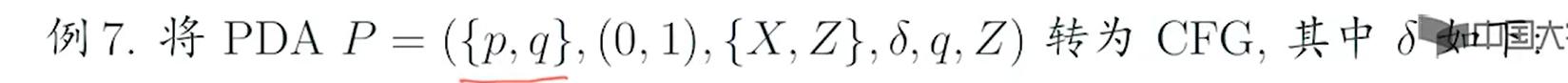
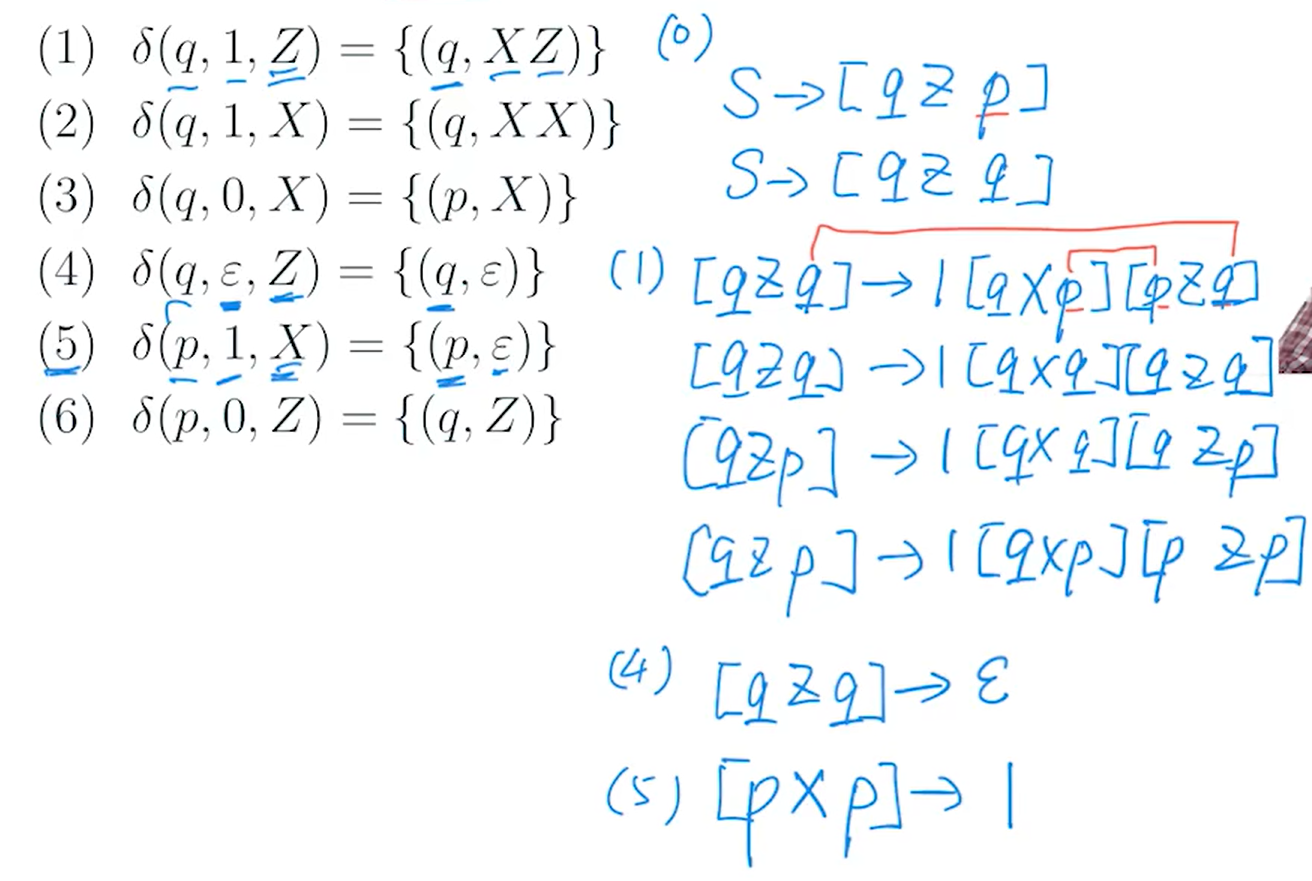
sol

概念证明
e.g1
![]()

e.g2
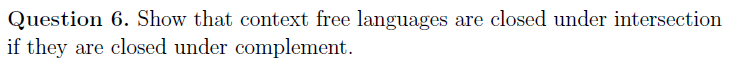

DPDA确定性自动机
e.g

c压栈到弹栈状态
泵引理

e.g1
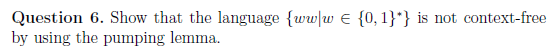
?
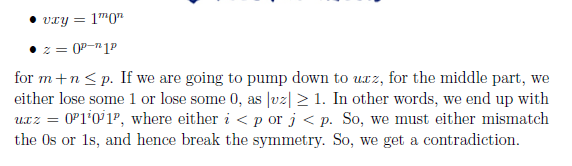
e.g2

e.g3
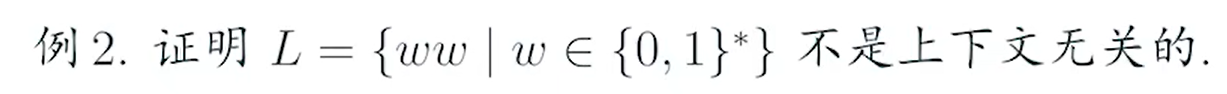
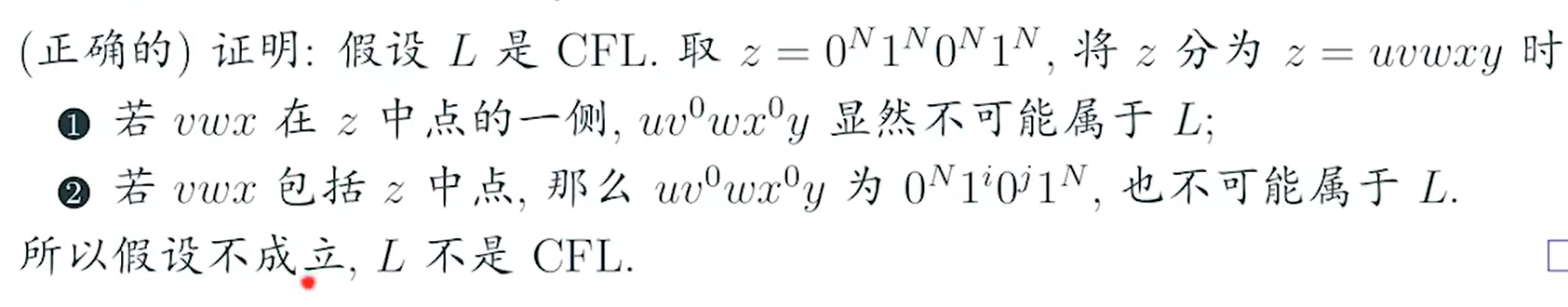
是设定n的数量的问题吗
图灵机

q状态下读的符号是X,可以跳转到p读的符号是Y,并且向左移动一格

?Language→TM
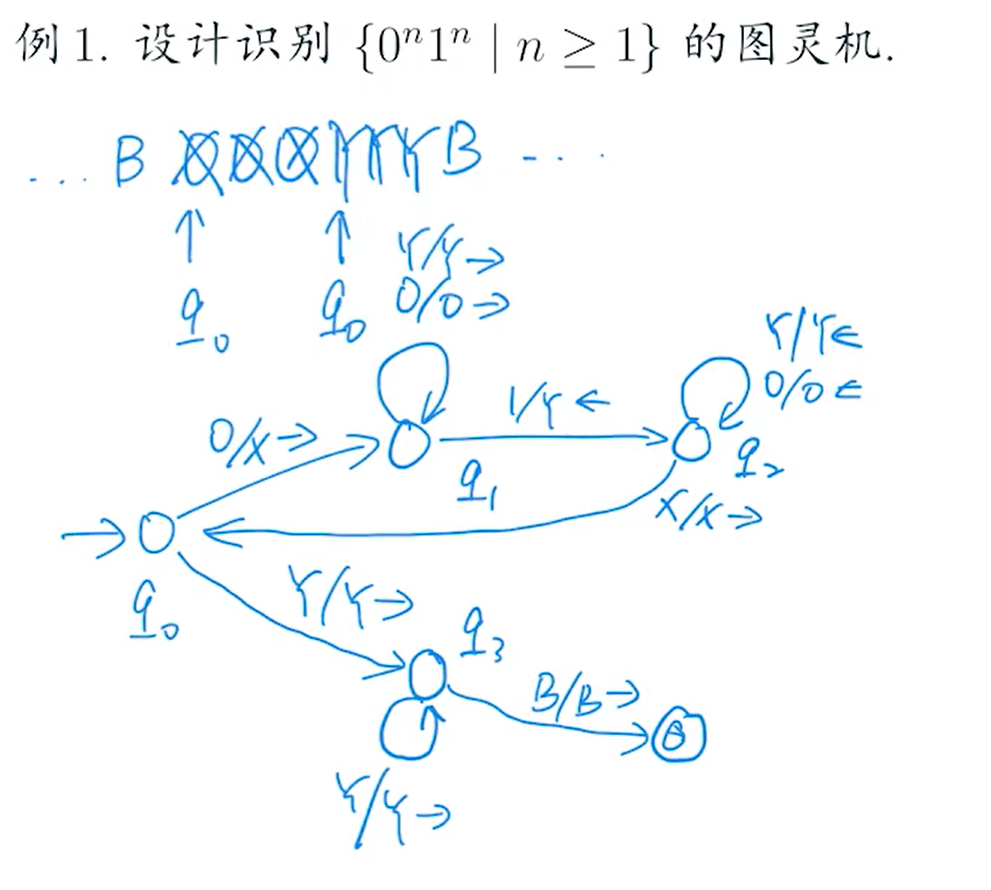
状态转移表(横线代表无定义)
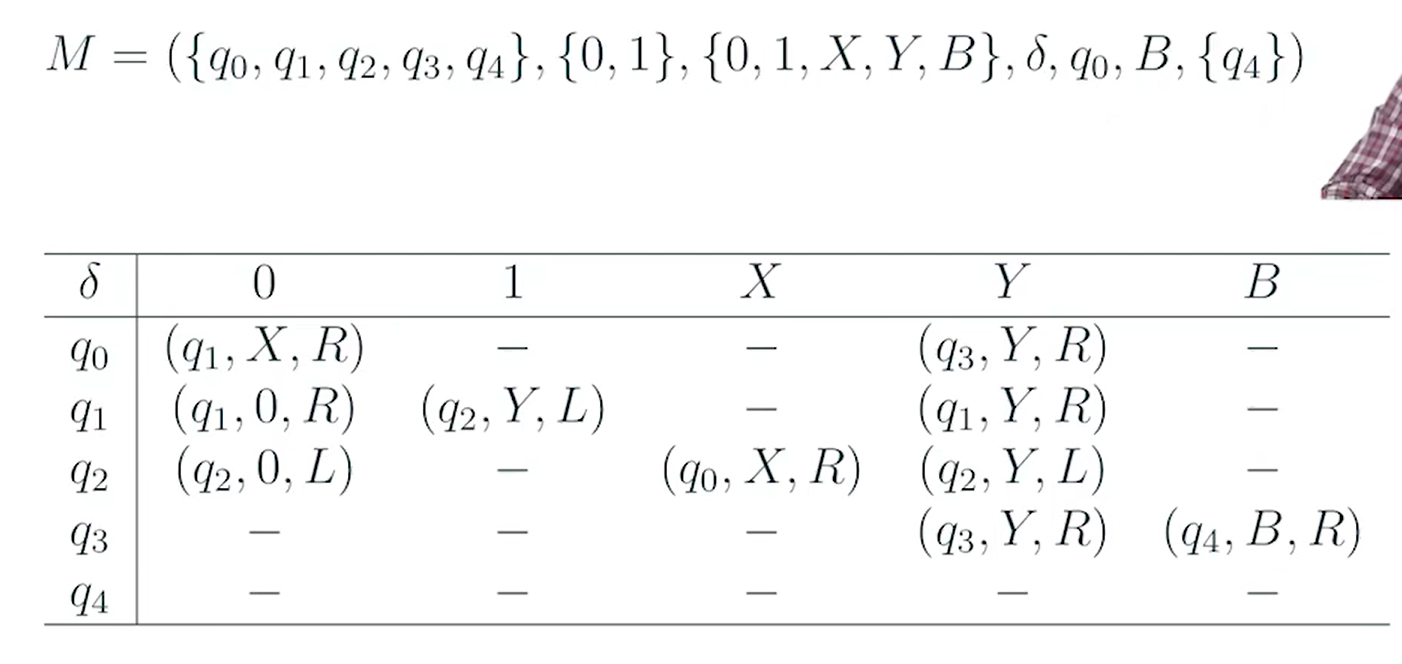
?给一种输入后看图灵机状态
e.g1(√)
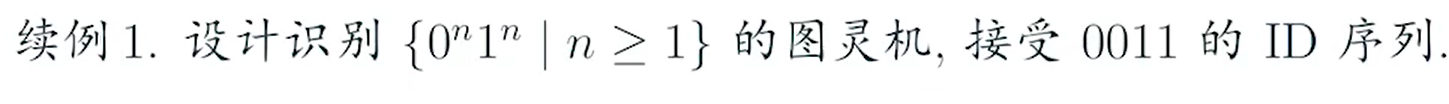
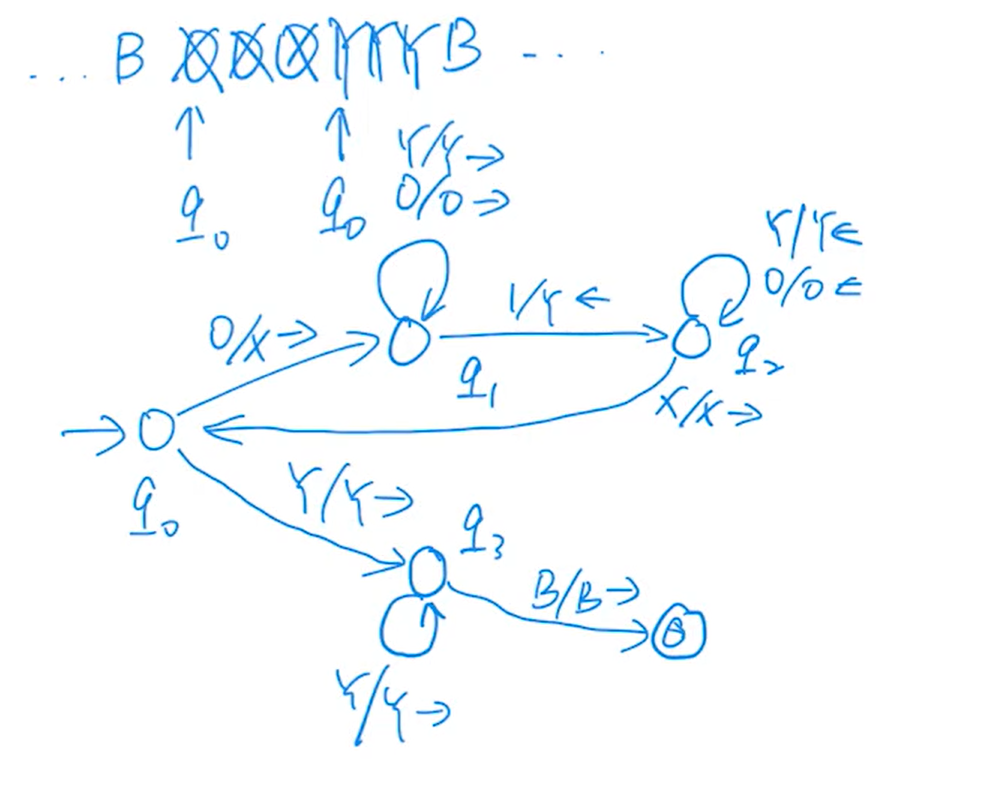
e.g2(√)
sol
![]()

e.g3
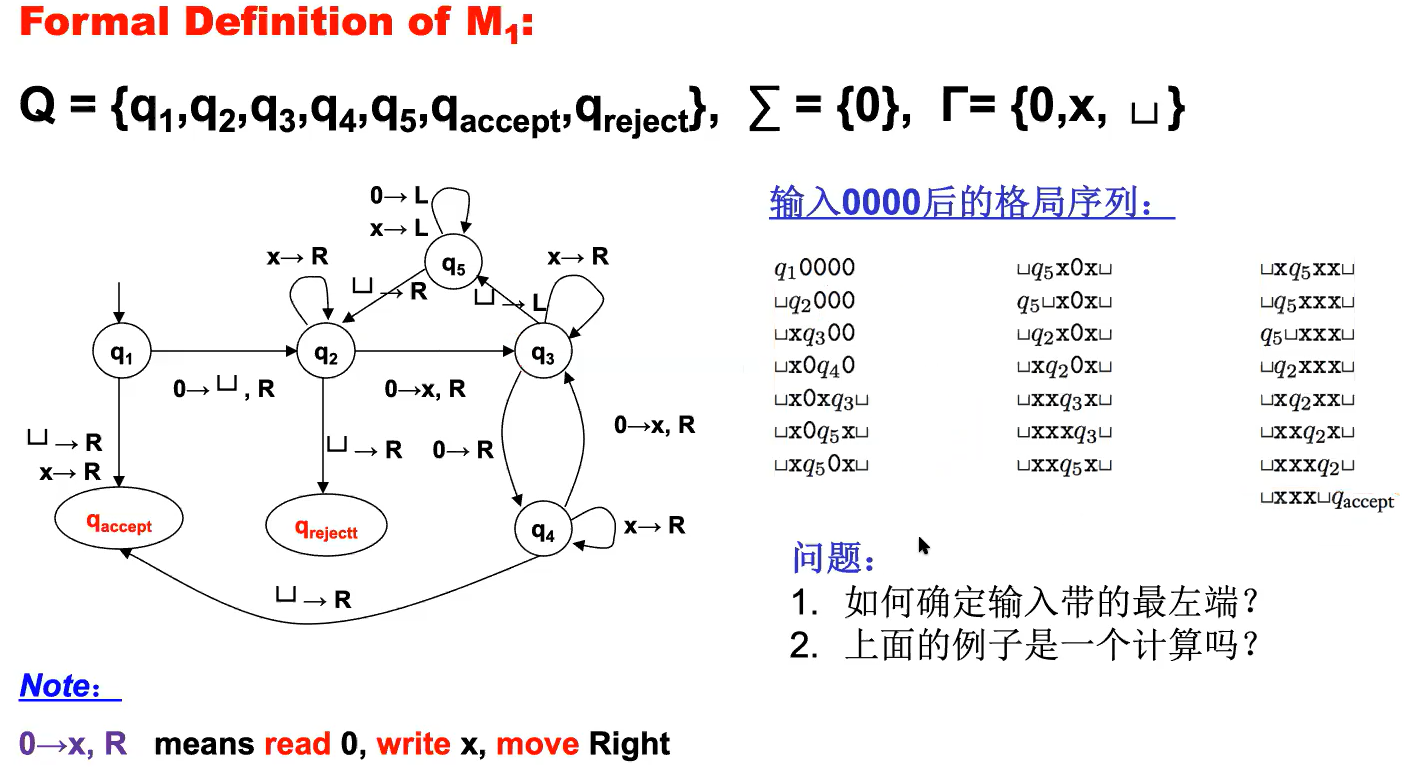
TM→language
e.g1(√)

sol
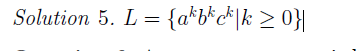
e.g2



decider判断
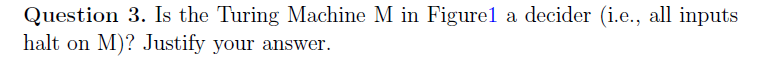

概念题
e.g
ttl9

sol

e.g ttl9


sol


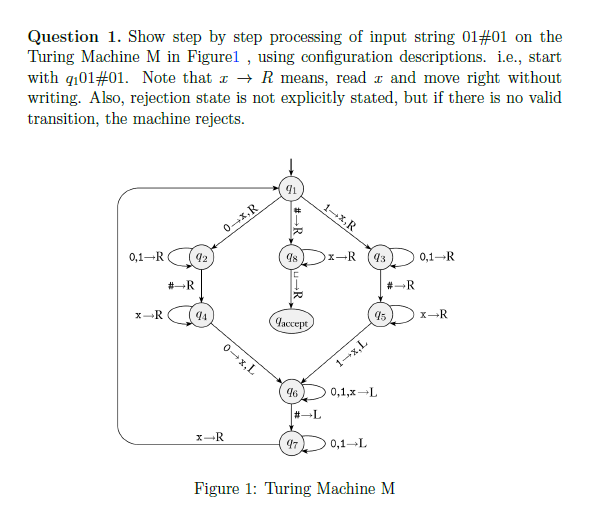
e.g cw2
![]()
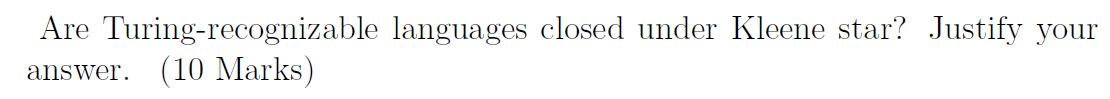




Recognizable/Decidable 语言
正向:构造图灵机
逆向:mapping,对角化,reducibility
要背
reduction?

A reduction is a technique used in computability theory and complexity theory to establish relationships between problems. Specifically, it involves transforming instances of one problem into instances of another problem in a way that preserves the answer. If we can efficiently solve the second problem, we can use this solution to solve the first problem as we
In the context of computability and undecidability, a reduction is a technique used to show that one problem is at least as hard as another. More specifically, if we can reduce problem A to problem B, it means that we can use a solution to problem B to solve problem A.

recursive/ recursive enumerate

recursive
?A language is said to be recursive if there exists a Turing machine that, when given an input string, halts and accepts the string if it belongs to the language, and halts and rejects the string otherwise.
Recursive languages have a decider – an algorithm that always halts and gives a definite answer.
recursively enumerable
A language is said to be recursively enumerable (or semi-decidable) if there exists a Turing machine that, when given an input string belonging to the language, halts and accepts the string, but it may run forever or loop (does not halt) when given a string not in the language.
Recursively enumerable languages have a recognizer – an algorithm that halts and accepts for strings in the language but may not halt or reject for strings outside the language.
halting problem

Halting Problem (H):
- Language H consists of all pairs (M, w) where M is a description of a Turing machine and w is an input string. H(M, w) is true if the Turing machine M halts on input w and false otherwise.
This language is recursively enumerable because you can design a Turing machine that enumerates all possible pairs (M, w) and simulates the execution of each Turing machine M on input w. If M halts on w, the enumeration will eventually include the pair (M, w). However, H is not recursive because there is no algorithmic procedure that, given any arbitrary Turing machine and input, can decide in a finite amount of time whether the machine halts on that input.
The proof of the undecidability of the Halting Problem is often done through a technique called diagonalization, which involves assuming the existence of a decider for H and then constructing a Turing machine that leads to a contradiction, showing that no such decider can exist. This proof establishes that the Halting Problem is recursively enumerable but not recursive.
pumping lemma
![]()
The Pumping Lemma for regular languages is a fundamental property that regular languages must satisfy. It provides a way to demonstrate that certain languages are not regular. The Pumping Lemma states the following:
For any regular language L, there exists a constant p (the "pumping length") such that any string s in L of length at least p can be split into three parts, xyz, satisfying the following conditions:
- For each i ≥ 0, the string xy^i z is in L.
- |y| > 0 (i.e., y is non-empty).
- |xy| ≤ p.
In other words, the Pumping Lemma asserts that, for any sufficiently long string in a regular language, there exists a substring y within the first p characters that can be "pumped" (duplicated any number of times) while still keeping the resulting string in the language.
The Pumping Lemma is often used in proof by contradiction to show that certain languages are not regular. If, for a given language, the conditions of the Pumping Lemma cannot be satisfied, it suggests that the language is not regular.
![]()
The Pumping Lemma for Context-Free Languages is a property that context-free languages must satisfy. It is a tool commonly used to prove that certain languages are not context-free. The Pumping Lemma for Context-Free Languages states the following:
For any context-free language L, there exists a constant p (the "pumping length") such that any string s in L of length at least p can be decomposed into five parts, uvwxy, satisfying the following conditions:
- For each i ≥ 0, the string uv^i wx^i y is in L.
- |vwx| ≤ p.
- |vx| > 0 (i.e., v and/or x is non-empty).
- For all non-negative integers i, uv^i wx^i y should also be in L.
This lemma asserts that for any sufficiently long string in a context-free language, there exists a substring vwx within the first p characters such that repeatedly "pumping" v and x (concatenating them to themselves any number of times) while keeping the u and y portions intact will result in strings that are still in the language L.
The Pumping Lemma for Context-Free Languages is often used in proof by contradiction to demonstrate that certain languages cannot be context-free. If, for a given language, the conditions of the Pumping Lemma cannot be satisfied, it suggests that the language is not context-free.
c)如何用泵原理证明语言非正则
The idea behind the Pumping Lemma is that if a language is regular, then any sufficiently long string can be "pumped" to generate an infinite number of strings still in the language. If you can show that a language does not satisfy the Pumping Lemma, then it cannot be regular.
The Pumping Lemma is a useful tool for proving that certain languages are not regular. The Pumping Lemma states that for any regular language, there exists a constant p (the "pumping length") such that any string s in the language, with length at least p, can be split into three parts, s=xyz, satisfying the following conditions:
- For each i ≥ 0, the string xy^i z is in L.
- |y| > 0 (i.e., y is non-empty).
- |xy| ≤ p.
?Lfa vs? Lpda vs Ldpda

LBAs, being equivalent to Turing Machines, can recognize context-sensitive languages.
LDPDAs, being a type of pushdown automaton, can recognize context-free languages, which are a proper subset of context-sensitive languages.
LPDAs, like LDPDAs, can recognize context-free languages, but they may not be deterministic.
LBA > LDPDA > LPDA in terms of computational power, with each level capable of recognizing languages of increasing complexity.
集合可数性
如果无限集与自然数集(N)之间不存在双射,则无限集不可数。
e.g1
![]()
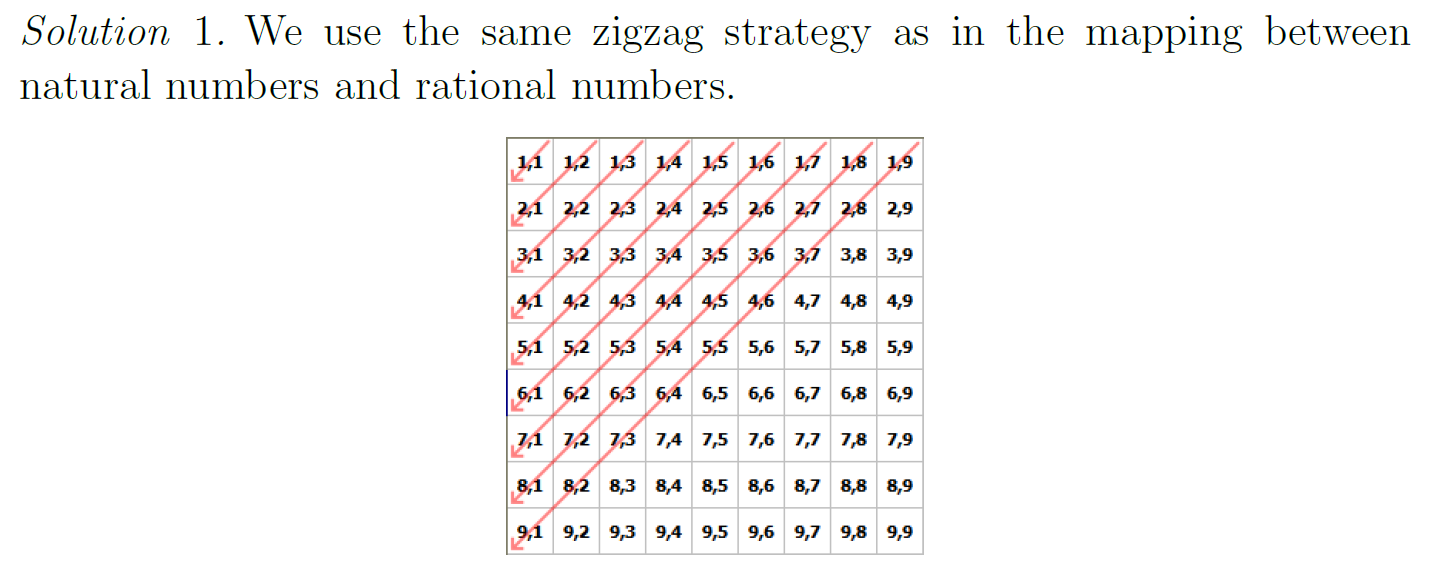
e.g2
![]()

e.g3
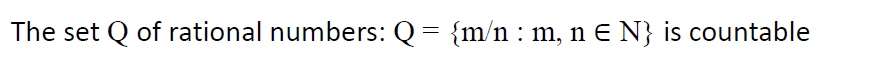
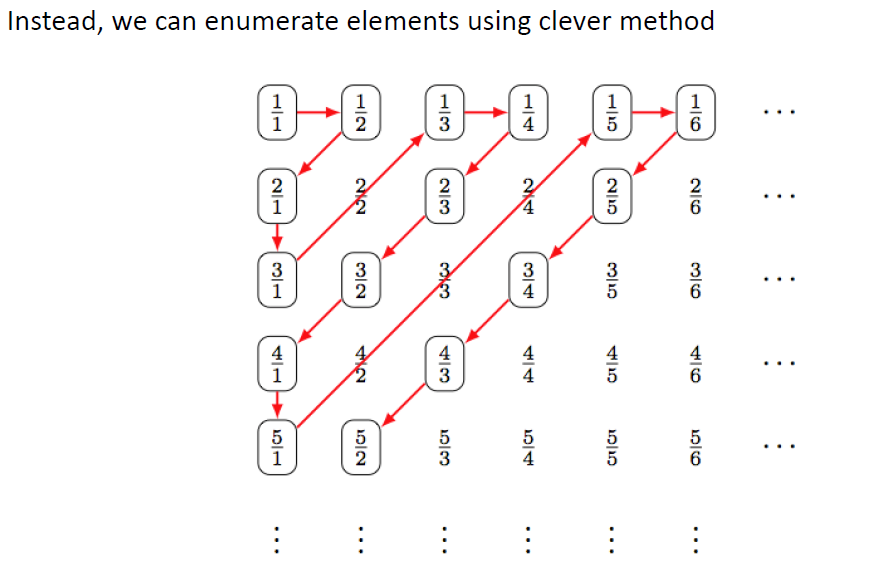
e.4证明不可数
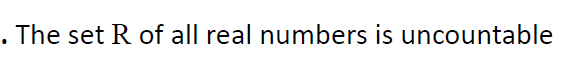


diagonalization method?对角化方法

![]()
e.g1


e.g2


e.g3

![]()
decidable
dfa

cfg

e.g1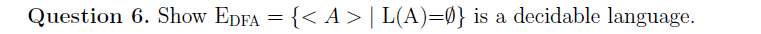
sol
 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
e.g2
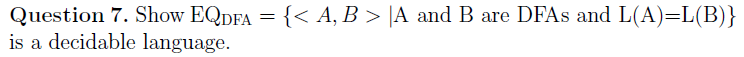
sol

e.g3
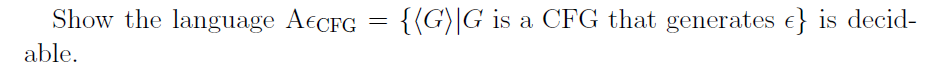
decidable- 直接构建

e.g4
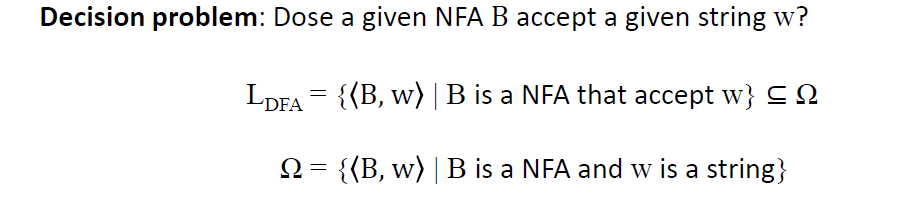
sol

e.g5
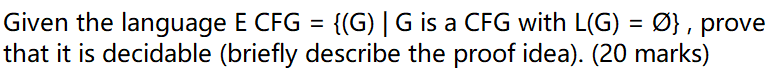

Undecidable
TM undecidable




sol2

e.g1
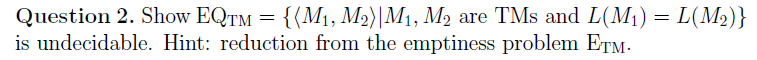

e.g2
![]()

Rice’s theorem
- 假设存在一个通用算法 A 能够判定停机问题。然后我们可以构造一个新的算法 B,该算法在输入 ?M,w? 上执行以下操作:
- 如果 A 判断 M 在输入 w 上停机,那么 B 进入无限循环;
- 如果 A 判断 M 不在输入 w 上停机,那么 B 立即停机。
- 构造出的算法 B 的性质属于 Phalt?,因为 B 的语言要么是整个集合(停机),要么是空集(不停机)。
- 这就导致了矛盾,因为根据我们的假设, A 是一个可以判定停机问题的算法。由此,我们得出结论,停机问题是不可判定的。? ? ? ? ? ??



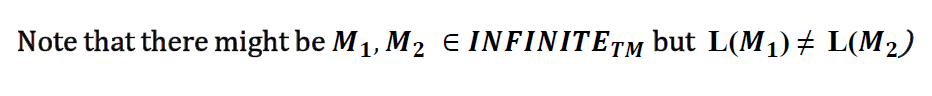

e.g1

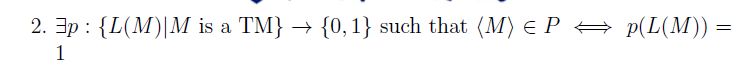

?e.g2
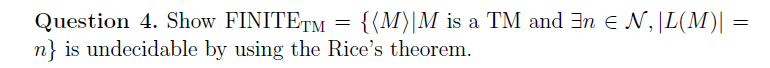

e.g3

sol




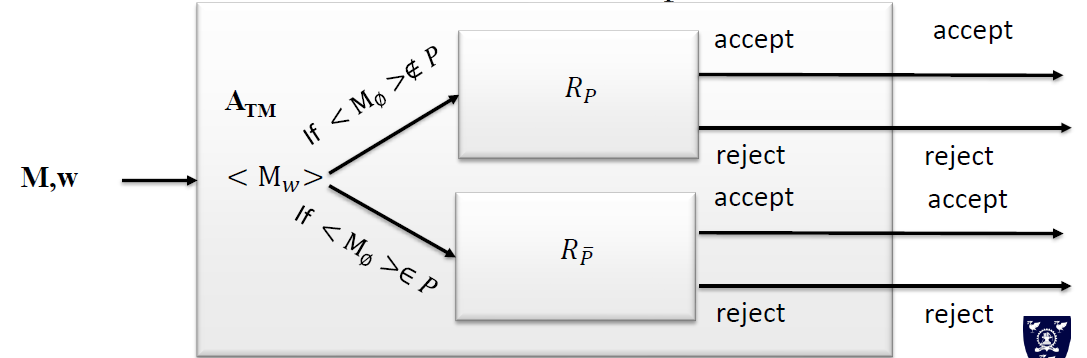
recognizable
-
Turing Decidable (可判定):
- 一个语言是Turing可判定的,意味着存在一个图灵机,对于输入的任何字符串,这个机器会在有限时间内给出答案:是或者不是(接受或者拒绝)。
- 这相当于说,对于语言中的每个字符串,图灵机会在有限的步骤内停机并输出结果。
-
Turing Recognizable (可识别):
- 一个语言是Turing可识别的,意味着存在一个图灵机,对于属于这个语言的输入,这个机器会在有限时间内接受它,但对于不属于这个语言的输入,机器可能进入无限循环或者拒绝。
- 这意味着,对于属于语言的字符串,图灵机一定能够在有限步内接受,但对于不属于语言的字符串,机器不一定会在有限时间内拒绝。
关联:
- 所有Turing可判定的语言都是Turing可识别的。如果一个语言是可判定的,那么我们可以构造一个图灵机来判定每个字符串是否在语言中,因此语言也是可识别的。
- 但并非所有Turing可识别的语言都是Turing可判定的。存在一些可识别但不可判定的语言,这意味着对于这些语言,我们可以构造一个图灵机来接受属于语言的字符串,但不能保证对于不属于语言的字符串一定能够在有限时间内拒绝。

e.g1

概念证明
e.g1


24年考题
1. 判断
2. 画NFA,大于两个0或者正好一个1
3. 根据DFA给出正则表达式
4. La{ai bj ck |i=j,i,j,k>0}?Lb{ai bj ck |i=j,i,j,k>0}
给出一个语言的CFG
5.GFL转换CNF
6.
根据PDA图给出PDA的语言
给出这个语言的CFG
判断PDAA是否属于PDAB
7.
decidable定义补全
莱斯定理
TM101是否能被证明
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解析SSH登录日志的奥秘:深入了解日志的形成过程
- YOLOv5算法进阶改进(9)— 引入ASPP | 空洞空间金字塔池化
- 不是生活有意思,是你热爱生活它才有意思
- 国产品牌GC3901与A3901/allegro的参数对比,适用于摄像机、消费类等产品中
- 文件单行读取与批量读取
- SpringBoot @RequestBody和@ResponseBody注解
- DALL-E:Zero-Shot Text-to-Image Generation
- C++程序员目前在做QT客户端,如何提升竞争力和薪资?
- 系统架构设计师教程(十一)未来信息综合技术
- 【C++】虚函数、虚基类、纯虚函数、抽象类到底怎么回事