【NeRF】Point-NeRF:Point-NeRF: Point-based Neural Radiance Fields阅读记录
文章目录
项目地址
论文地址
源码地址
会议/期刊:CVPR 2022
个人理解
此篇文章,在传统NeRF的基础上,先利用MVSNet根据图像生成一个初始点云,再用一个2D卷积神经网络学习图片中的特征,添加到对应点云的点上,这样可以不对空间中位置进行采样,而是只对点云表面附近的点进行采样,提升了计算效率,而且模型具有一定的泛化性。
还提出了两个新方法,点修剪和点生长,迭代优化训练结果,删除置信度小于一定阈值的点,增加置信度大于一定阈值的点。
摘要
传统的NeRF神经绘制方法可以生成高质量的视图合成结果,但由于对每个场景进行了优化,导致重建时间过长。
深度多视图立体(deep multi-view stereo)方法可以通过直接的网络推理快速重建场景几何。
point-nerf结合了这两种方法的优点,使用神经三维点云,与相关的神经特征,以模拟一个辐射场。可以获得比传统NeRF更好的视觉质量,而且训练速度加快30倍。
本文还提出了一种点剪枝和生长技术,可以逐渐提高几何建模和渲染质量。
简介
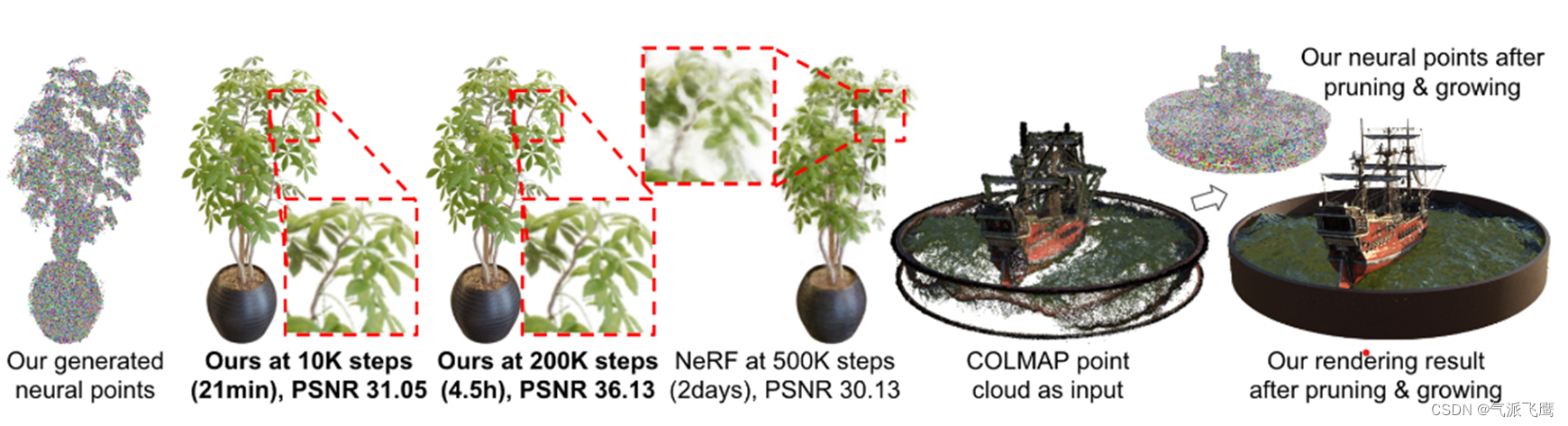
基于点的辐射场可以通过多视图图像的网络进行预测,然后针对每个场景进行优化,可以在数十分钟内实现超越 NeRF 的重建质量。
Point-NeRF 还可以利用现成的重建方法,如 COLMAP,并且能够执行点修剪和增长,自动修复这些方法中常见的孔洞和异常值。
基于点的NeRF表示
体渲染和辐射场(Volume rendering and radiance fields)
通过使光线穿过像素、沿射线在
x
j
x_j
xj?处采样 M 个着色点
x
j
∣
j
=
1
,
.
.
.
,
M
{x_j | j = 1, ..., M }
xj?∣j=1,...,M 并使用体积密度累积辐射率(我理解为颜色)来计算像素的辐射亮度,如下:

这个公式与传统NeRF中的体渲染公式基本一致,如果不容易理解可以参考这篇文章。
这里
τ
\tau
τ表示体积透过率;
σ
j
σ_j
σj? 和
r
j
r_j
rj? 是
x
j
x_j
xj? 处每个着色点 j 的体积密度和辐射亮度,
Δ
t
\Delta t
Δt 是相邻着色样本之间的距离。
辐射场表示任意 3D 位置处的体积密度 σ 和与视图相关的辐射率 r。
基于点的辐射场(Point-based radiance field)
用 P = ( p i , f i , γ i ) ∣ i = 1 , . . . , N P = {(p_i, f_i, \gamma_i)|i = 1, ..., N } P=(pi?,fi?,γi?)∣i=1,...,N 表示神经点云,其中每个点 i 是位于 p i p_i pi? 并与编码本地场景内容的神经特征向量 f i f_i fi? 相关联的点。
本文为每个点分配了一个尺度置信值 γ i ∈ [ 0 , 1 ] \gamma i \in [0, 1] γi∈[0,1],表示该点位于实际场景表面附近的可能性。然后从P点云回归辐射场。
给定任何 3D 位置 x,查询其周围一定半径 R 内的 K 个相邻神经点。本文的基于点的辐射场可以抽象为一个神经模块,对于任何位置x,该模块从与其相邻的神经点回归其体积密度
σ
\sigma
σ 和与视图相关的辐射率
r
r
r(沿着任何观看方向 d):
(
σ
,
r
)
=
P
o
i
n
t
?
N
e
R
F
(
x
,
d
,
p
1
,
f
1
,
γ
1
,
.
.
.
,
p
K
,
f
K
,
γ
K
)
(\sigma,r)=Point-NeRF(x,d,p_1,f_1,\gamma_1,...,p_K,f_K,\gamma_K)
(σ,r)=Point?NeRF(x,d,p1?,f1?,γ1?,...,pK?,fK?,γK?)
本文使用具有多个子 多层感知机(MLP) 的类似 PointNet 的神经网络来进行此回归。首先对每个神经点进行神经处理,然后聚合多点信息以获得最终的估计。
逐点处理(Per-point processing)
本文使用 MLP F来处理每个相邻神经点,通过以下方式预测着色位置 x 的新特征向量:
f
i
,
x
=
F
(
f
i
,
x
?
p
i
)
f_{i,x}=F(f_i,x-p_i)
fi,x?=F(fi?,x?pi?)
原始特征
f
i
f_i
fi?对
p
i
p_i
pi?周围的本地3D场景内容进行编码。该MLP网络表达了一个局部3D函数,该函数输出 x 处的特定神经场景描述
f
i
,
x
f_{i,x}
fi,x?,由其局部框架中的神经点建模。相对位置
x
?
p
x?p
x?p的使用使网络对于点平移具有不变性,以实现更好的泛化。
视点相关的辐射率回归(View-dependent radiance regression)
本文使用标准反距离加权来聚合从这K个相邻点回归的神经特征
f
i
,
x
f_{i,x}
fi,x?,以获得描述x处场景外观的单个特征
f
x
f_x
fx?:
f
x
=
∑
i
γ
i
w
i
∑
w
i
f
i
,
x
,
w
h
e
r
e
(
w
i
=
1
‖
p
i
?
x
‖
)
f_x = \sum_i \gamma_i \frac{w_i}{\sum w_i} f_{i,x}, where (w_i = \frac{1}{‖p_i ? x‖})
fx?=i∑?γi?∑wi?wi??fi,x?,where(wi?=‖pi??x‖1?)
然后,在给定观察方向 d 的情况下,MLP R将根据该特征回归与视图相关的辐射率:
r
=
R
(
f
x
,
d
)
r = R(f_x,d)
r=R(fx?,d)
密度回归(Density regression)
同样使用标准反距离加权聚合方法来计算 x 处的体积密度 σ。首先使用 MLP T回归每个点的密度
σ
i
\sigma_i
σi?,然后进行基于反距离的加权,如下所示:
σ
i
=
T
(
f
i
,
x
)
\sigma_i=T(f_{i,x})
σi?=T(fi,x?)
σ
=
∑
i
σ
i
γ
i
w
i
∑
w
i
,
w
h
e
r
e
(
w
i
=
1
‖
p
i
?
x
‖
)
\sigma = \sum_i \sigma_i\gamma_i \frac{w_i}{\sum w_i}, where (w_i = \frac{1}{‖p_i ? x‖})
σ=i∑?σi?γi?∑wi?wi??,where(wi?=‖pi??x‖1?)
可见,每个神经点直接对体积密度做出贡献,并且点置信度 γ i \gamma_i γi? 与该贡献明确相关。后面在点删除过程中利用了这一点(原论文第 4.2 节,优化基于点的辐射场)。
基于点的神经辐射场重建(Point-NeRF Reconstruction)
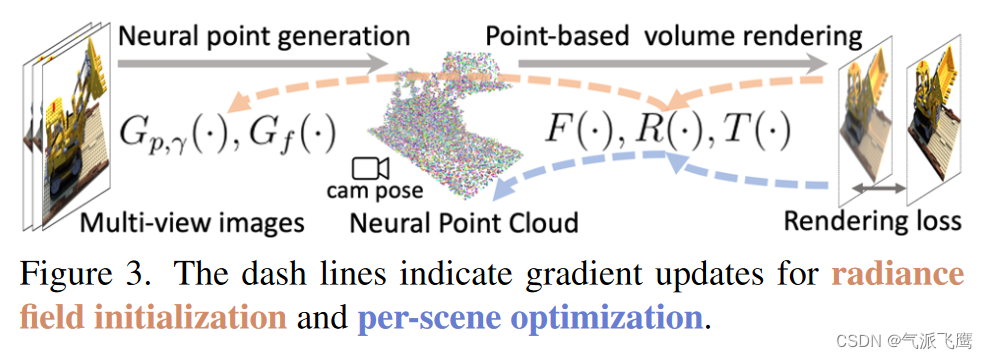
首先利用跨场景训练的深度神经网络,通过直接网络推理生成初始的基于点的场(初始点云)。通过本文的点生长和修剪技术,这个初始场在每个场景中得到进一步优化,从而实现最终的高质量辐射场重建。该图显示了该工作流程以及初始预测和场景优化的相应梯度更新。
生成初始的基于点的辐射场(Generating initial point-based radiance fields)
本文提出了一个神经生成模块来预测所有神经点属性,包括点位置
p
i
p_i
pi?、神经特征
f
i
f_i
fi? 和点置信度
γ
i
\gamma_i
γi?,通过前馈神经网络进行有效重建。网络直接推理输出良好的基于??点的初始辐射场。然后可以对初始场进行微调以实现高质量渲染。在很短的时间内,渲染质量更好或与 NeRF 相当,而 NeRF 需要更长的时间来优化。见表。

点位置和置信度(Point location and confidence)
利用深度 MVS 方法使用基于成本体积的 3D CNN 生成 3D 点位置 [10, 59]。这样的网络可以产生高质量的密集几何结构,并且可以很好地跨领域推广。
对于视点 q 处具有相机参数 ? q \phi_q ?q? 的每个输入图像 I q I_q Iq?,按照 MVSNet 首先通过扭曲相邻视点的 2D 图像特征来构建平面扫描成本体积,然后使用深度 3D CNN 回归深度概率体积。通过线性组合按概率加权的每平面深度值来计算深度图。我们将深度图投影到 3D 空间以获得每个视图 q 的点云 { p 1 , . . . , p N q } \{p_1, ..., p_{Nq} \} {p1?,...,pNq?}。(这段描述比较长,因为本人没有深入了解MVSNet,这里就理解为用MVSNet方法生成了每个视图的点云)(挖个坑,等读过MVSNet之后再来解释)
由于深度概率描述了点位于表面上的可能性,因此本文对深度概率体积进行三线性采样(挖坑,不懂三线性采样),以获得每个点 p i p_i pi? 处的点置信度 γ i \gamma_i γi?。
该过程用公式表示:
{
p
i
,
γ
i
}
=
G
p
,
γ
(
I
q
,
?
q
,
I
q
1
,
?
q
1
,
I
q
2
,
?
q
2
,
.
.
.
)
\{p_i,\gamma_i\}=G_{p,\gamma}(I_q,\phi_q,I_{q1},\phi_{q1},I_{q2},\phi_{q2},...)
{pi?,γi?}=Gp,γ?(Iq?,?q?,Iq1?,?q1?,Iq2?,?q2?,...)
其中
G
p
,
γ
G_{p,\gamma}
Gp,γ? 是基于 MVSNet 的网络。
I
q
1
、
?
q
1
、
.
.
.
I_{q1}、\phi_{q1}、...
Iq1?、?q1?、...是 MVS 重建中使用的附加相邻视图;在大多数情况下使用两个附加视图。
总结:用MVSNet网络生成每个点的位置和置信度
点特征(Point features)
使用 2D CNN
G
f
G_f
Gf? 从每个图像
I
q
I_q
Iq? 中提取神经 2D 图像特征图。这些特征图与
G
p
,
γ
G_{p,\gamma}
Gp,γ? 的点(深度)预测对齐,并用于直接预测每点特征
f
i
f_i
fi? 为:
{
f
i
}
=
G
f
(
I
q
)
\{f_i\} = G_f (I_q)
{fi?}=Gf?(Iq?)
对
G
f
G_f
Gf? 使用具有三个下采样层的 VGG 网络架构。将不同分辨率下的中间特征组合为
f
i
f_i
fi?,提供有意义的点描述来模拟多尺度场景外观。
总结:用2D CNN G f G_f Gf?提取每个点的特征
优化基于点的辐射场(Optimizing point-based radiance fields)
初始点云,尤其是来自外部重建方法(例如图 1 中的 Metashape 或 COLMAP)的点云,通常可能包含孔洞和异常值,从而降低渲染质量。在逐场景优化过程中,为了解决这个问题,本文提出了应用新颖的点修剪和生长技术来逐渐提高几何建模和渲染质量。
点修剪(Point pruning)
前面设计了点置信值
γ
i
\gamma_i
γi?来描述神经点是否靠近场景表面。利用这些置信值来修剪不必要的异常点。注意,根据前面体积密度回归中的公式可知点置信度与每点的贡献直接相关;因此,低置信度反映了点局部区域的低体积密度,表明该点是空的。本文选择每 10K 迭代修剪
γ
i
<
0.1
\gamma_i < 0.1
γi?<0.1的点。
本文还在点置信度上施加了稀疏损失:
L
s
p
a
r
s
e
=
1
∣
γ
∣
∫
γ
i
[
l
o
g
(
γ
i
)
+
l
o
g
(
1
?
γ
i
)
]
L_{sparse} = \frac{1}{|\gamma|}\int_{\gamma_i} [log(\gamma_i) + log(1 ? \gamma_i)]
Lsparse?=∣γ∣1?∫γi??[log(γi?)+log(1?γi?)] 这迫使置信值接近于零或一。

点生长(Point growing)
利用在光线行进中采样的每光线着色位置来识别新的候选点
(
体渲染部分提到的
x
j
)
(体渲染部分提到的x_j)
(体渲染部分提到的xj?)。具体来说,确定沿着光线具有最高不透明度的着色位置
x
j
g
x_{j_g}
xjg??:
α
j
=
1
?
e
x
p
(
?
σ
j
Δ
j
)
,
j
g
=
a
r
g
m
a
x
j
α
j
\alpha_j = 1 ? exp(?\sigma_j\Delta_j), j_g = argmax_j \alpha_j
αj?=1?exp(?σj?Δj?),jg?=argmaxj?αj?
用 ? j g \epsilon_{j_g} ?jg?? 表示 x j g x_{j_g} xjg?? 到其最近神经点的距离。
当 α j g 和 ? j g \alpha_{j_g}和\epsilon_{j_g} αjg??和?jg??大于一定阈值就在 x j g x_{j_g} xjg??位置添加一个点。通过重复这种增长策略,辐射场可以扩展到覆盖初始点云中缺失的区域。
实施细节(Implementation details )
网络详细信息(Network details)
略
训练和优化细节
首先使用类似于原始 MVSNet 论文 [59] 的GroundTruth深度来预训练基于 MVSNet 的深度生成网络。然后,纯粹使用 L2 渲染损失
L
r
e
n
d
e
r
\mathcal{L}_{render}
Lrender? 训练完整管道,通过GroundTruth监督光线行进(通过体渲染方程)的渲染像素,以获得最终的 Point-NeRF 重建网络。
在逐场景优化阶段,本文采用结合了渲染和稀疏损失的损失函数
L
o
p
t
=
L
r
e
n
d
e
r
+
a
L
s
p
a
r
s
e
\mathcal{L}_{opt} = \mathcal{L}_{render} + a\mathcal{L}_{sparse}
Lopt?=Lrender?+aLsparse?
参考
- 论文随记|Point-NeRF: Point-based Neural Radiance Fields
- 【论文精读】Point-NeRF:Point-based Neural Radiance Fields
- NeRF神经辐射场学习笔记(三)——Point-NeRF论文解读
- 有真实参照的图像质量的客观评估指标:SSIM、PSNR和LPIPS
如果发现文章有什么问题,欢迎指出,我会在看到后修改;对于这篇文章有疑问也尽管提出,我尽量解答。欢迎交流。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Jenkins配置代理节点时遇到的坑和解决办法
- 排序算法讲解
- 植物大战僵尸小游戏抖音快手直播搭建弹幕插件教程
- 脚本执行权限——chmod +x、chmod -x
- 逆天纪手机游戏定制开发
- Java小项目--学生信息管理系统--用户登录系统--课程设计
- 第六章 数组(二)
- go 中的 fmt 占位符
- 基于微信支付的体育场馆预订小程序开发笔记一
- 【idea】win 10 / win 11:idea 、Alibaba Dragonwell 11、maven、git 下载与安装