主动学习如何解决数据标注的难题?主动学习和弱监督学习有何区别?
机器学习的成功与否取决于数据标注的质量和数量。利用主动学习的机器学习技术能加快模型训练的进度和减少数据获取的资金投入。依靠主动学习来得到有价值的数据,以便机器模型从中学习。如果一个模型被具有价值的数据加以训练,它将以较少的人工标注和更短的训练周期达到预期的性能。本文将介绍主动学习如何解决数据标注的难题和主动学习和弱监督学习的区别。
主动学习如何解决数据标注的难题?
- 缩短标注数据流程和降低标注成本
- 有效获得模型结果反馈
- 提高模型准确率
主动学习的方法是将数据标注的步骤呈现为学习算法和用户之间的交互过程,由算法来建议哪些数据值得被标注,而人工则对这些选定的样本进行标注。应用主动学习将加快标注进程、控制成本,获得理想的训练数据。相较于传统的标注方法,主动学习能够挑选有价值的数据进行标注,排除一些冗余数据、噪声数据的干扰,摒弃传统标注中对所有数据进行标注,加上模型从中的学习发现更具有价值的数据,减少标注量提高标注效率。下图简单描述了主动学习框架下的数据标注流程:?
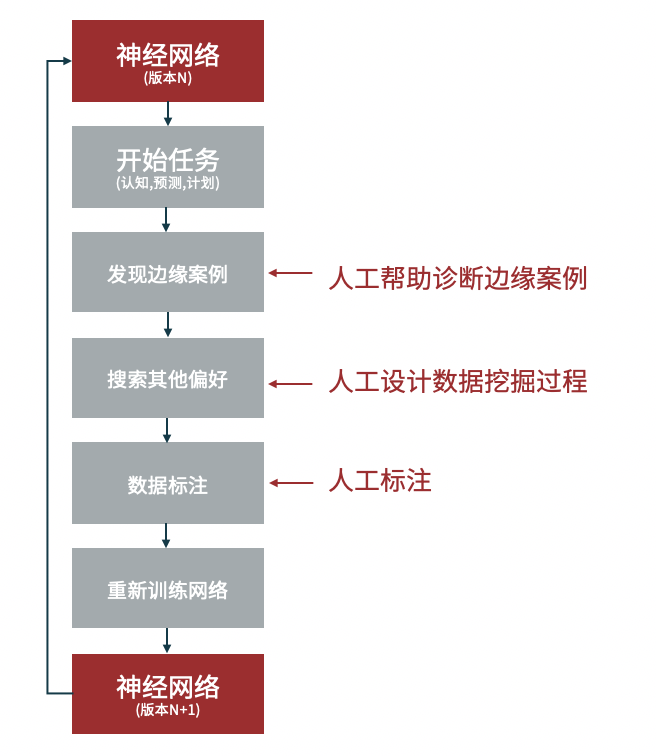
主动学习和弱监督学习有何区别?
两种学习类型均可产生高性能的模型,但它们在几个关键方面有明显的不同:
标签来源
不同学习类型所需的标签来源千差万别:?主动学习
- 人工(通常是SME)标注数据集。
- 假定这些标签准确。
- 标签来自一个来源。
弱监督学习
- 来源灵活,可来自任何地方。
- 标签不一定非常准确或完整。
- 必须使用多个数据源。
所需资源
投资用于每种学习类型的时间、金钱和人力配比不同:?主动学习
- 利用SME进行标注成本高昂且可用性也有限。
- 主动学习需要人工标注数据集中至少一部分数据。
弱监督学习
- 标注功能可以在几秒钟内应用于数百万个数据点,从而节省大量标注时间。
- 根据数据源的不同,投入在弱监督训练上的时间也会有差异,但通常都少于主动学习项目所需的时间。
过程迭代
虽然机器学习始终是个迭代过程,但弱监督学习和主动学习的迭代次数不同:?主动学习
- 使用多个循环的人机协同迭代过程。
- 标注数据后对模型进行训练。
弱监督学习
- 在开始训练模型之前,已完全标注数据集。
- 训练过程不会涉及任何人机协同。
两种方法的优点
尽管存在差异,但主动学习和弱监督学习仍与完全监督学习有所区别。它们的优势是节省了大量的标注时间,并可以通过限制SME的工作节省资金。弱监督学习所需的成本较高的数据量将远远少于监督学习所需的数据。同样,如果有一种使用主动学习的有效采样技术,则可以比传统方法使用更少的标注数据点来实现高质量的模型性能。 最重要的是,并不存在万能的机器学习方法。选择这种或那种学习方法,将取决于可用的时间、资金和人员分配;收集数据的计划和数据来源;以及特定使用场景。根据特定使用场景,不一定要选择主动学习和弱监督学习,它们并不总是相互排斥,具体取决于要使用的应用场景。在决策AI解决方案的过程中需要讲以上这些因素纳入考量标准。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- DNS重绑定攻击记录(绕过同源策略、绕过IP黑名单、SSRF绕过)
- 泛型擦除到底是怎么一回事
- java——链表实现队列
- GBASE南大通用数据库在本地的或远程的数据库中删除例程
- C++的泛型编程—模板
- 【普中开发板】基于51单片机的简易密码锁设计( proteus仿真+程序+设计报告+讲解视频)
- 小智ToDo:日程待办清单管理的智能助手
- 机器学习_线性回归原理和实战
- 【Leetcode】2171. 拿出最少数目的魔法豆
- AI数字人:定制个性化、低成本、可控性的品牌形象