大模型应用系列01:我们可以利用Transformer做什么?
pipeline() 是Transformers 库提供的一个工具函数,这个函数将模型和必要的预处理(preprocessing)和后处理(postprocessing)连接起来。这样我们可以直接输入文本,然后得到模型的输出。

情感分类
首先就是最老生常谈的 sentiment analysis 任务,我们只需要指定任务类型为 sentiment-analysis,device 参数表示模型运行的设备:CPU 或 GPU。默认情况下,pipeline 会选择一个在英文语料库上预训练之后的模型,这里选择的是
distilbert-base-uncased-finetuned-sst-2-english

模型会输出一个字典列表,label 表示要分类的句子是 POSITIVE 还是 NEGATIVE,score 表示 label 的得分,最大为 1.0。
当我们创建 classifier 对象时,pipeline 就会自动下载这个模型,这个模型会被缓存在本地,所以下次运行时就不会再下载了。
当然,这篇教程是为了中文用户的,所以我也会使用对应的中文模型来说明。
我将要指定使用
IDEA-CCNL/Erlangshen-Roberta-110M-Sentiment
这个模型。

效果还算不错,我们可以同时在列表中分类多条语句。

当我们将文本传到一个 pipeline 对象时,pipeline 为我们做了以下三件事:
-
预处理文本,将文本转成模型能够理解的形式。
-
将预处理结果输入到模型中。
-
后处理模型的输出,这样我们可以理解模型输出的内容。
零样本分类
上面的模型在训练时就已经指定了输出只能是 Positive 或者是 Negative 这 2 种类别。在实际工作中,人为标注数据集非常耗时且需要领域内的专业知识背景。
零样本分类(zero-shot classification)可以让我们自己指定样本的类别,而无需用这些样本组成自己的训练集预先训练模型。
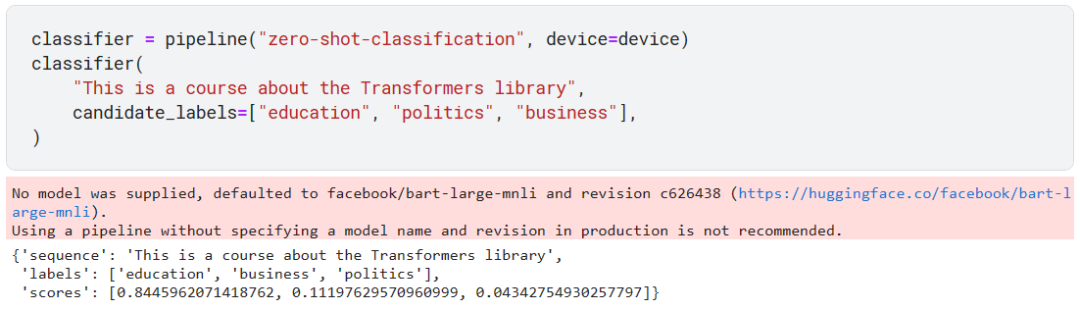
默认使用的模型是:facebook/bart-large-mnli
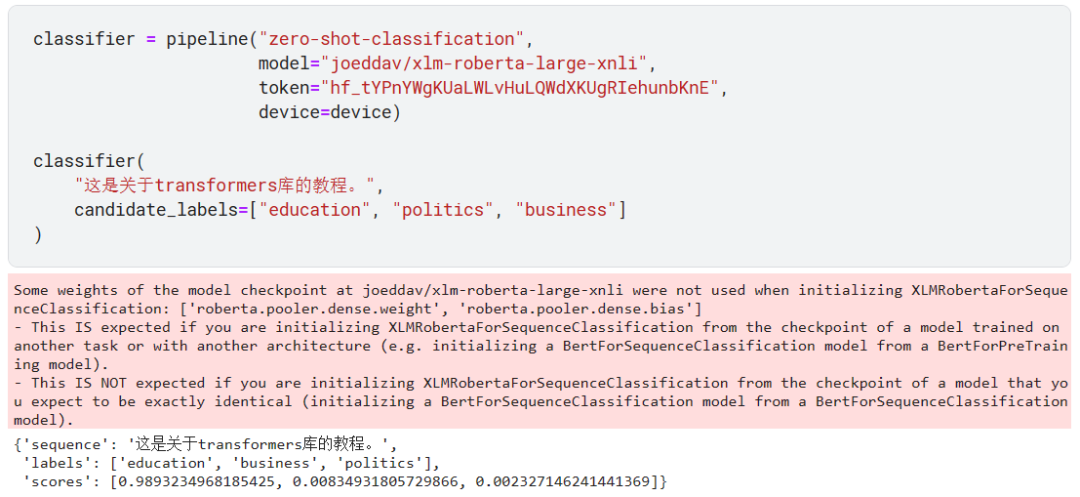
指定使用中文模型:joeddav/xlm-roberta-large-xnli
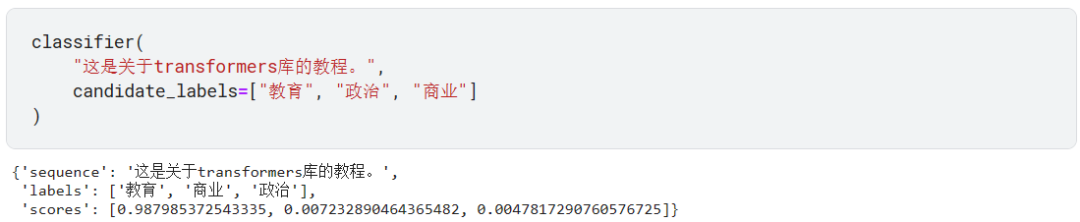
甚至连 label 都能指定成中文。
文本生成
相信大家都用过 ChatGPT 或者类似的产品:给定一段提示(prompt),模型会自动生成余下的文字。就好比你的手机输入法预判你要输入什么内容一样。
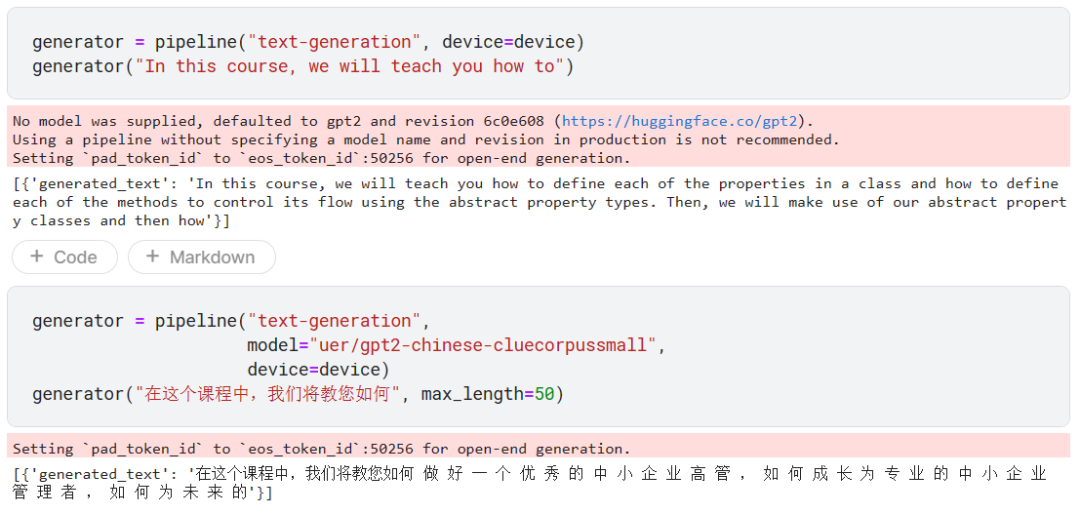
这种文本生成模型带有随机性,所以要是你得到的输出和我的不一样,那也很正常。
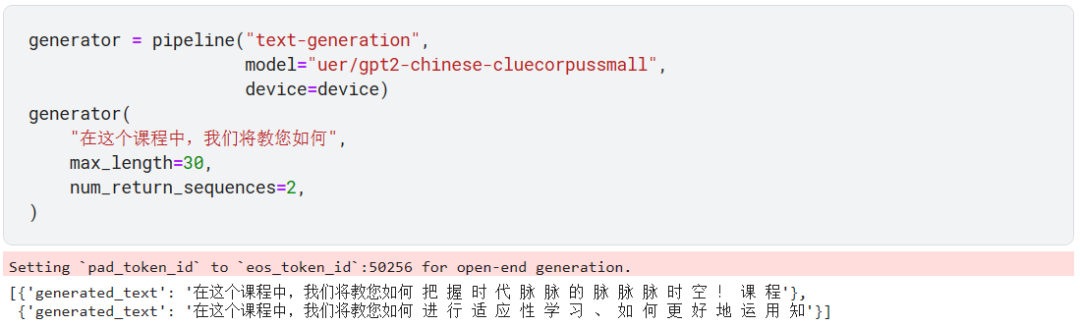
默认使用的是 gpt-2 模型,不过我们也可以指定使用中文模型,比如这里的 uer/gpt2-chinese-cluecorpussmall 模型。
我们可以控制生成的文本个数及长度。
Mask filling
如果你听说过谷歌的 BERT(Bidirectional Encoder Representations from Transformers) 模型,那么你就会知道 mask filling 指的是什么,我们先看一个例子。
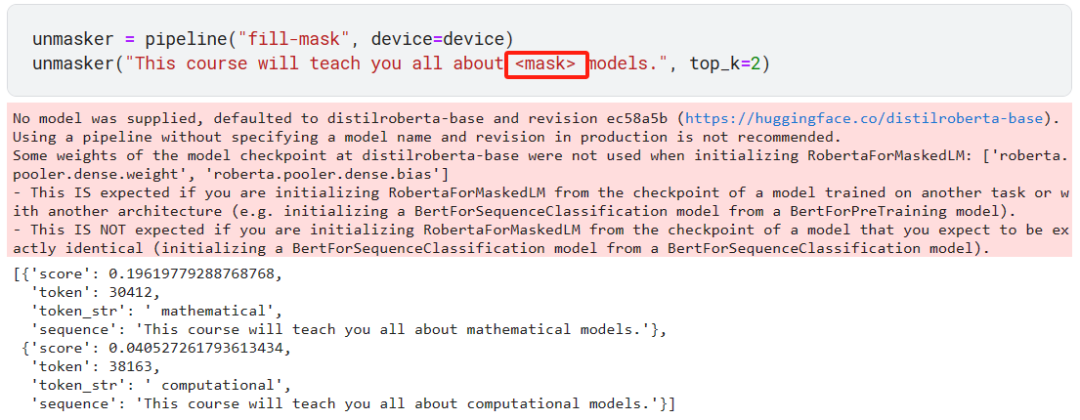
我们在一句话中插入了 <mask> 标志,让模型去预测这个?<mask> 标志最有可能是什么词。上面我们通过 top_k=2 让模型输出前 2 个概率最高的词。
值得注意的是,默认使用的是 BERT 模型的衍生版:distilroberta-base 模型。
我们可以使用在中文数据集上微调过的 bert-base-chinese 模型,看名字也知道这也是 BERT 模型。
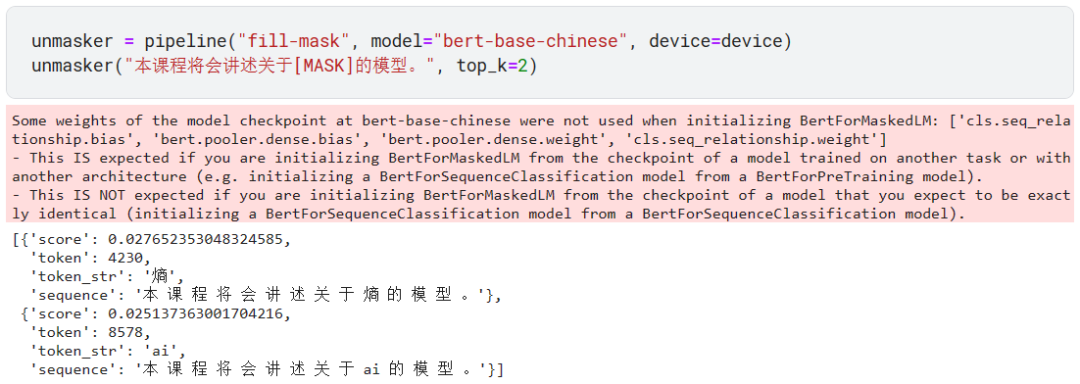
注意不同的模型用不同的标志,比如上面的?bert-base-chinese 模型用的就是 [MASK],而不是?<mask>。
命名实体识别
命名实体识别(Named entity recognition,NER)就将句子中的词打标签:人物、地点、组织等等。也可以理解为这是一种 token classification 任务。
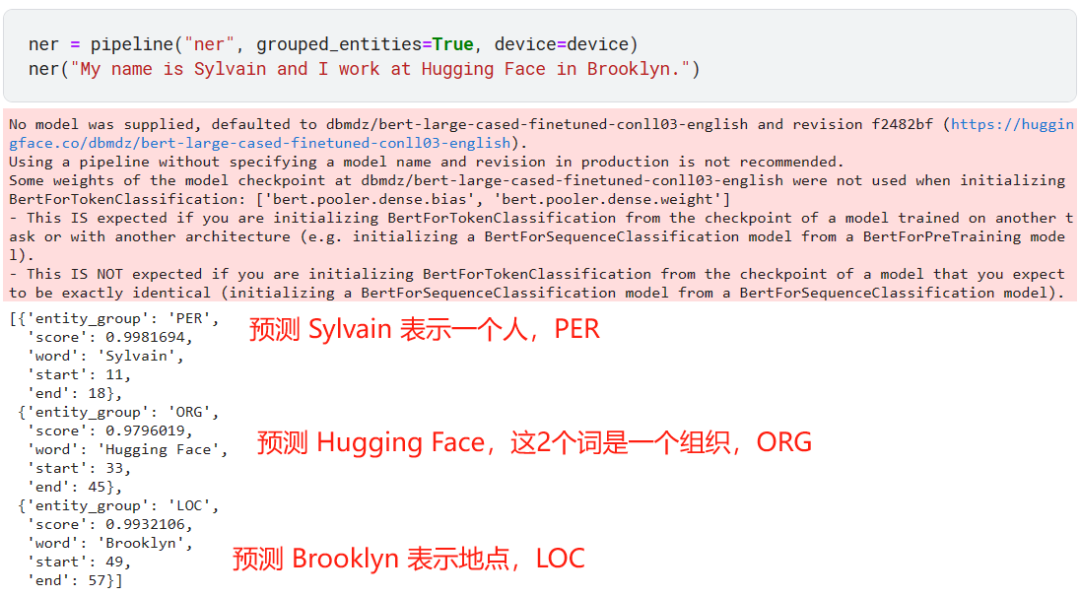
以上预测完全正确!
有的命名实体可能包含多个词,比如 Hugging Face 就是 2 个词,所以我们通过 grouped_entities=True 参数让模型可以将表示一个命名实体的多个词组合起来。
不过有点遗憾,我还没找到合适的中文模型。希望各位读者能够有朝一日贡献一个!
问答
这是我最感兴趣的任务了,我们只需要提供背景(context),然后就可以向模型提问,模型根据我们提供的背景知识回答问题。
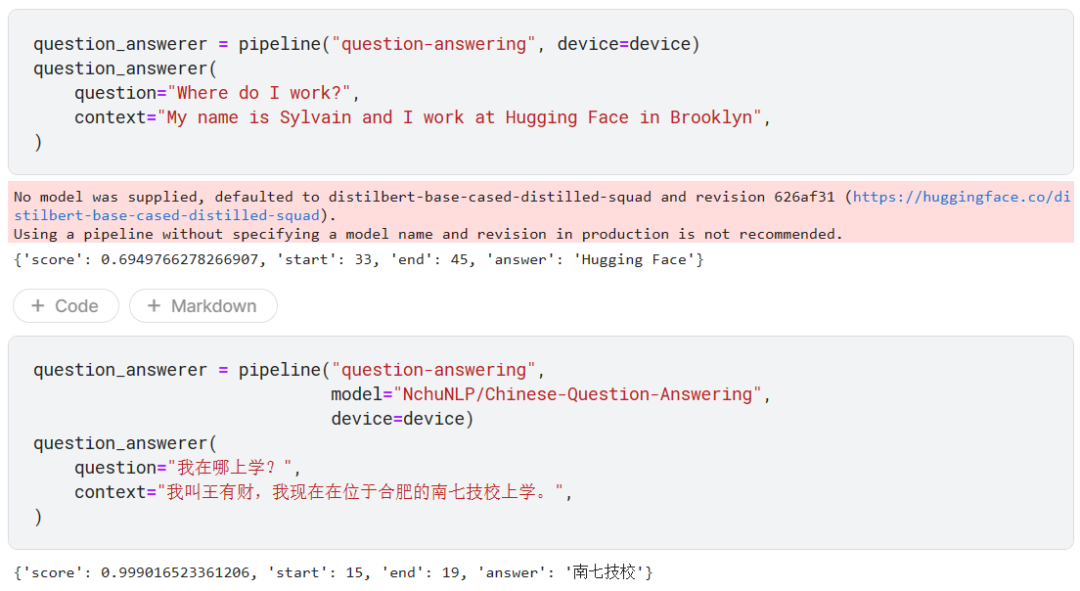
注意,上面的 2 个模型仅仅是从背景知识里面截取答案,而不是自己推理生成答案。start 和 end 指出了答案在背景知识字符串中的开始和结束索引。
当然现在很火的 RAG(Retrieval Augmented Generation),即检索增强生成,是根据用户问题,检索出相关的文档,然后根据检索的文档生成答案,非常有趣!
摘要
从一篇长文本中总结出一段话,而且保留原文的主题意思。
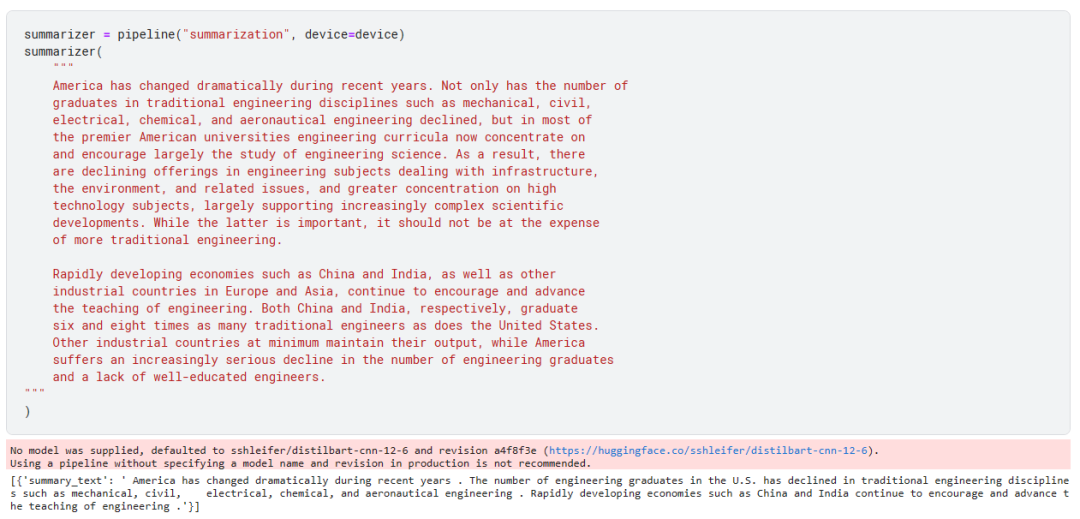

我们可以通过 max_length 或 min_length 来指定摘要的最大长度和最小长度。
翻译
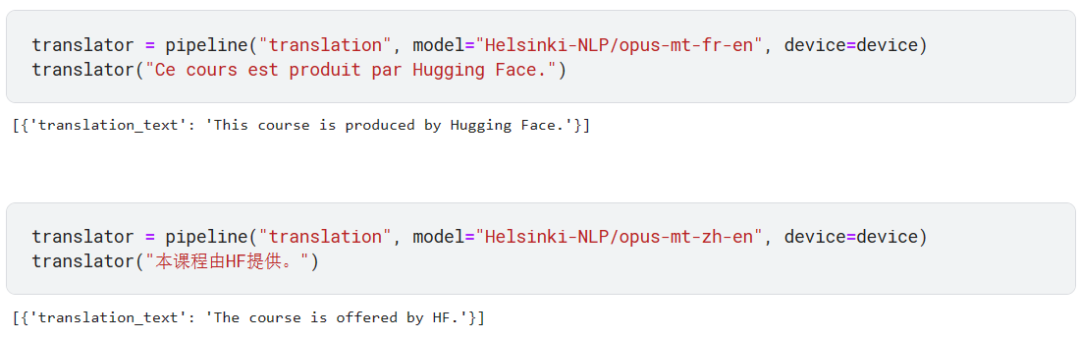
Transformers 原本就是用来解决翻译任务的,有兴趣的读者可以阅读一下《Attention is all you need》。
下面的任务一个是将法语翻译成英文,一个是将中文翻译成英文。
我们也可以通过?max_length?或?min_length 来指定摘要的最大长度和最小长度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++笔记(一)
- Spring 七种事务传播性介绍
- Qt界面篇:Qt停靠控件QDockWidget、树控件QTreeWidget及属性控件QtTreePropertyBrowser的使用
- 安卓11通过脚本修改相应板型系统属性
- SpringBoot + MyBatis-Plus 实现分页操作详解
- 假设与灵敏度分析
- 如何开始第一次测试? 测试人员和开发人员起了争执怎么办?
- Sqoop的增量数据加载策略与示例
- DC-磁盘配额
- 01.03