【无标题】
MMdetection自定义数据集训练及相关配置
一、安装mmdetection
pip install -U openmim
mim install mmengine
mim install "mmcv>=2.0.0"
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -v -e .
安装完以后,验证一下是否安装正确。
mim download mmdet --config rtmdet_tiny_8xb32-300e_coco --dest .
python demo/image_demo.py demo/demo.jpg rtmdet_tiny_8xb32-300e_coco.py --weights rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --device cuda:0
如果不报错,有正常结果,代表安装成功。
其他的包可以通过
pip install -r requirements.txt
注意:中间遇到缺少的库自己安装,比如pytorch,根据自己的硬件环境安装对应的pytorch版本。
二、数据准备
MMdetection内置的模型大多为coco数据集格式,voc格式的模型较少。建议直接使用coco模式,voc模式有很多坑,
将原始数据集转换为coco格式。首先将图像和xml文件都拷贝到同一个文件夹当中,执行以下脚本得到coco数据集。
# coding:utf-8
# pip install lxml
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
path2 = "."
START_BOUNDING_BOX_ID = 1
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + suffix
image_id = index +1
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id': image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print(
"[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
assert (xmax > xmin), "xmax <= xmin, {}".format(line)
assert (ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(os.path.join("annotations", json_file), 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),
len(pre_define_categories),
pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
# 类别
classes = ['water']
# 后缀
suffix = '.jpg'
pre_define_categories = {}
for i, cls in enumerate(classes):
pre_define_categories[cls] = i + 1
# pre_define_categories = {'a1': 1, 'a3': 2, 'a6': 3, 'a9': 4, "a10": 5}
only_care_pre_define_categories = True
# only_care_pre_define_categories = False
train_ratio = 0.9
save_json_train = 'instances_train2017.json'
save_json_val = 'instances_val2017.json'
xml_dir = "./imgAndXml"
xml_list = glob.glob(xml_dir + "/*.xml")
xml_list = np.sort(xml_list)
np.random.seed(100)
np.random.shuffle(xml_list)
train_num = int(len(xml_list) * train_ratio)
xml_list_train = xml_list[:train_num]
xml_list_val = xml_list[train_num:]
if os.path.exists(path2 + "/annotations"):
shutil.rmtree(path2 + "/annotations")
os.makedirs(path2 + "/annotations")
convert(xml_list_train, save_json_train)
convert(xml_list_val, save_json_val)
if os.path.exists(path2 + "/train2017"):
shutil.rmtree(path2 + "/train2017")
os.makedirs(path2 + "/train2017")
if os.path.exists(path2 + "/val2017"):
shutil.rmtree(path2 + "/val2017")
os.makedirs(path2 + "/val2017")
f1 = open("train.txt", "w")
for xml in xml_list_train:
img = xml[:-4] + suffix
f1.write(os.path.basename(xml)[:-4] + "\n")
shutil.copyfile(img, path2 + "/train2017/" + os.path.basename(img))
f2 = open("test.txt", "w")
for xml in xml_list_val:
img = xml[:-4] + suffix
f2.write(os.path.basename(xml)[:-4] + "\n")
shutil.copyfile(img, path2 + "/val2017/" + os.path.basename(img))
f1.close()
f2.close()
os.remove("train.txt")
os.remove("test.txt")
print("-------------------------------")
print("train number:", len(xml_list_train))
print("val number:", len(xml_list_val))
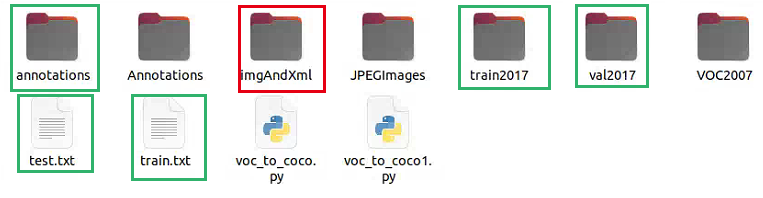
将所有的图像和xml文件放在了imgAndXml文件夹当中。其中红色为事先准备的文件信息,绿色框为后面生成的,annotations、train2017、val2017为生成的coco数据集,也就是转换之后的,目录如下图所示。
三、修改配置文件
基础修改
mmdetection/mmdet/datasets/coco.py 修改,修改classes(只有一个时需要加个逗号)和palette(标签颜色)
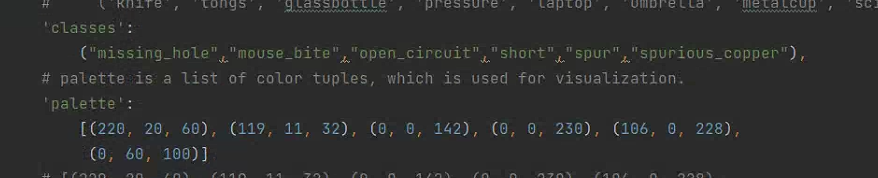
mmdetection/mmdet/evaluation/functional/class_names.py

注:上面的修改完成之后需要编译安装,才生效
python setup.py install
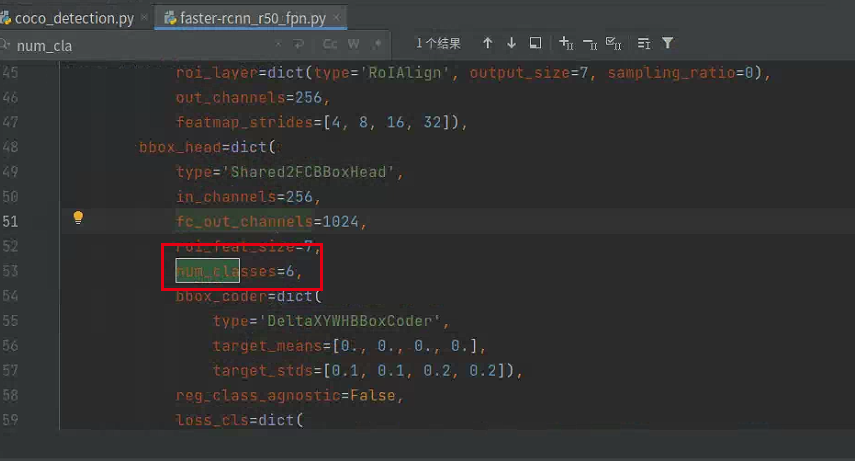
下面的网络结构文件num_classes同样需要修改,但不需要编译,对应训练的类别,和上面保持一致即可,如下图:
mmdetection/configs/_base_/datasets/faster-rcnn_r50_fpn.py
进阶修改
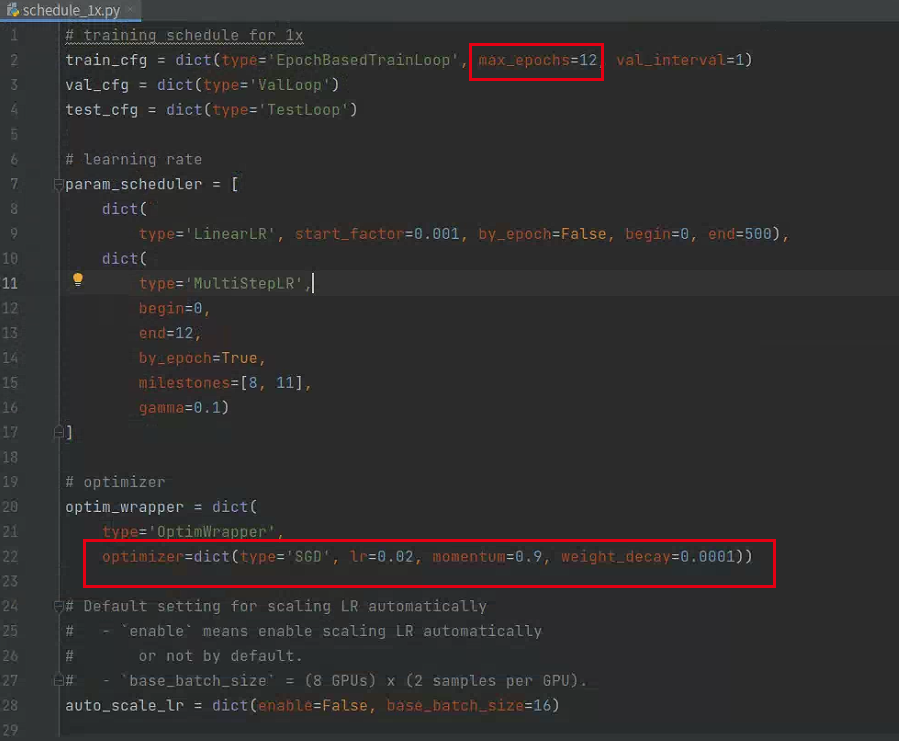
修改epoch、学习率
mmdetection/configs/_base_/schedules//schedule_1x.py
修改batch_size
mmdetection/configs/_base_/datasets/coco_detection.py

添加Tensorboard
mmdetection/configs/_base_/default_runtime.py
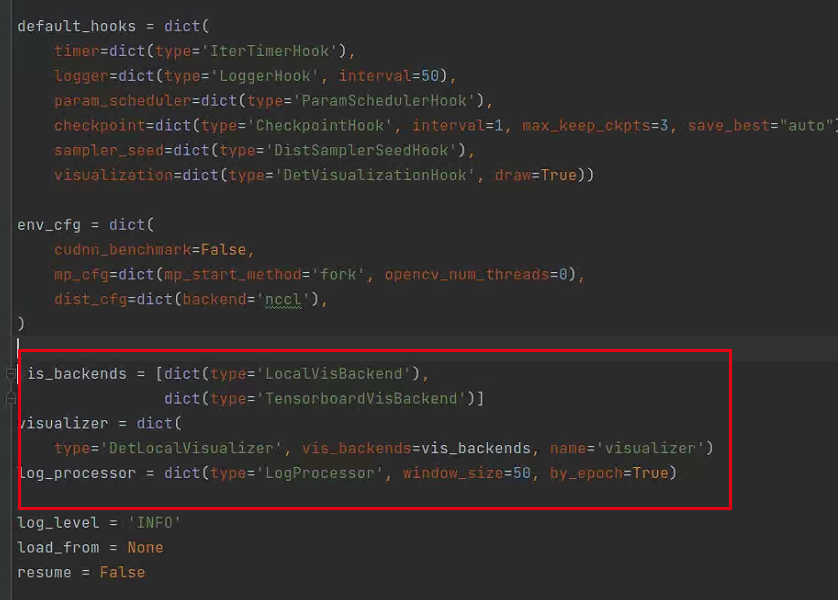
四、训练
使用Faster-RCNN训练数据
mmdetection使用配置文件的方式修改训练,直接在configs下复制faster-rcnn为my_faster-rcnn,在my_faster-rcnn进行修改,
1、修改基础配置文件
每个模型都有一个基础配置,其他规模的模型会基于该模型修改,这里只需要对基础模型配置文件修改即可,这里的基础模型是mmdetection/configs/_base_/models/fast-rcnn_r50_fpn.py,可以直接修改该文件也可以将该文件复制到my_faster-rcnn文件下,并修改对应配置文件中的 ../_base_/models/fast-rcnn_r50_fpn.py为 ./fast-rcnn_r50_fpn.py即可。
注:其他配置文件,如’coco_detection.py’, 'default_runtime.py’也可以使用复制到本地并修改的方式完成
如下图
2、训练
使用单GPU训练
python tools/train.py \
${CONFIG_FILE} \
[optional arguments]
例子:
export CUDA_VISIBLE_DEVICES=0 python tools/train.py configs/mydino/dino-4scale_r50_8xb2-12e_coco.py
在单机多GPU训练
bash ./tools/dist_train.sh \
${CONFIG_FILE} \
${GPU_NUM} \
[optional arguments]
例子:
./tools/dist_train.sh configs/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon.py 2
3、测试
为了测试训练完毕的模型,你只需要运行如下命令。
python tools/test.py configs/balloon/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon.py work_dirs/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon/epoch_12.pth
测试时输出标记后的图片
python tools/test.py configs/balloon/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon.py work_dirs/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon/epoch_12.pth --show
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- <四>Python的判断语句和循环语句
- element ui el-avatar 源码解析零基础逐行解析
- 大一C语言查缺补漏 12.28
- 【大数据学习笔记】新手学习路线图
- SSE[Server-Sent Events]实现页面流式数据输出(模拟ChatGPT流式输出)
- 李宏毅机器学习第二十三周周报 Flow-based model
- MES管理系统解决方案在汽配企业质量控制中的作用
- GO语言基础笔记(三):复合类型
- Java集合/泛型篇----第五篇
- JMM到底如何理解?JMM与MESI到底有没有关系?