Redis:原理+项目实战——Redis实战3(Redis缓存最佳实践(问题解析+高级实现))
👨?🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
🌌上期文章:Redis:原理+项目实战——Redis实战2(Redis实现短信登录(原理剖析+代码优化))
📚订阅专栏:Redis速成
希望文章对你们有所帮助
Redis实现商铺查询缓存
什么是缓存
缓存:数据交换的缓冲区(Cache),是存储数据的临时地方,读写性能高。
缓存的原理学过计算机组成原理、微机、计算机系统等课程的人都会很熟悉。
我们的浏览器有浏览器缓存,在浏览器未命中数据,就会在tomcat的应用层缓层中取数据,再没有命中的话就去数据库进行查询检索。
缓存的作用:
1、降低后端负载
2、提高读写效率,降低响应时间
缓存的成本:
1、数据的一致性成本
2、代码维护成本(解决一致性问题的时候带来的代码复杂)
3、运维的成本
给商铺查询功能添加Redis缓存
基础业务逻辑

这里的网址就是根据ID查询商户信息的接口,可以看到信息还是很多的:

所以我们要做的事情就是给这个接口添加缓存,从而提高查询的性能。
我们找到查询商户的业务逻辑代码:

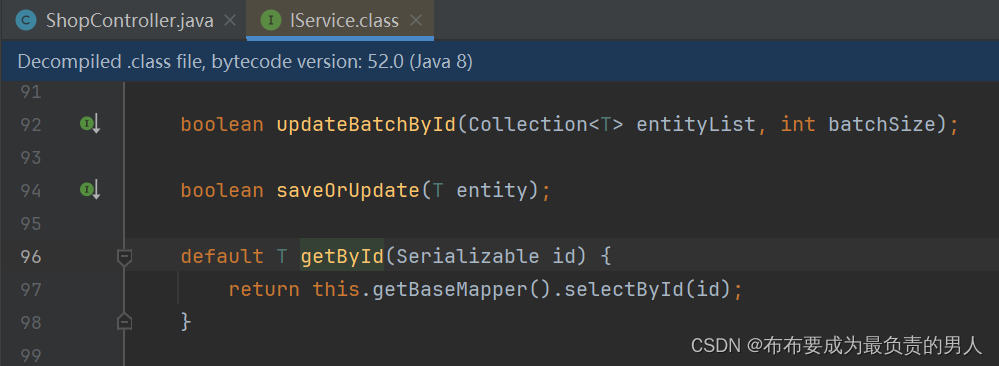
这里直接调用了mybatis-plus提供的接口,直接就能实现数据库的根据id查询的操作,我们就在这里进行Redis缓存的添加。
缓存作用模型与缓存流程
学过计算机系统结构,下面的内容还是很容易看懂的,最简单的缓存作用模型如图所示(当然这个模型实际上是有问题的,学过计算机系统结构的会明白,后续开发会优化这个模型):
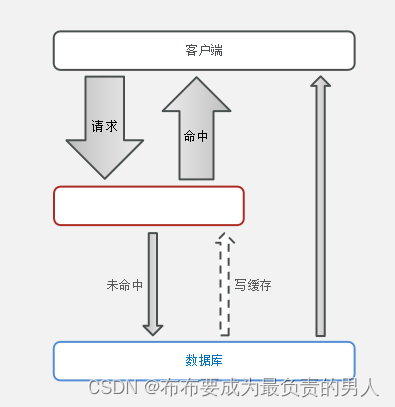
知道原理,我们也很容易知道流程该如何进行:

按照这个流程去实现代码,流程比较多我们就不在controller中去写了,直接让controller层中的方法去调用service层中的方法:

然后在service中实现相应的业务:
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY + id;
//从Redis中查询商铺缓存,存储对象可以用String或者Hash,这里用String
String shopJson = stringRedisTemplate.opsForValue().get(key);
//判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
//存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
//不存在,根据id查询数据库
Shop shop = getById(id);
//不存在,返回错误
if (shop == null){
return Result.fail("店铺不存在");
}
//存在,写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
//返回
return Result.ok(shop);
}
}
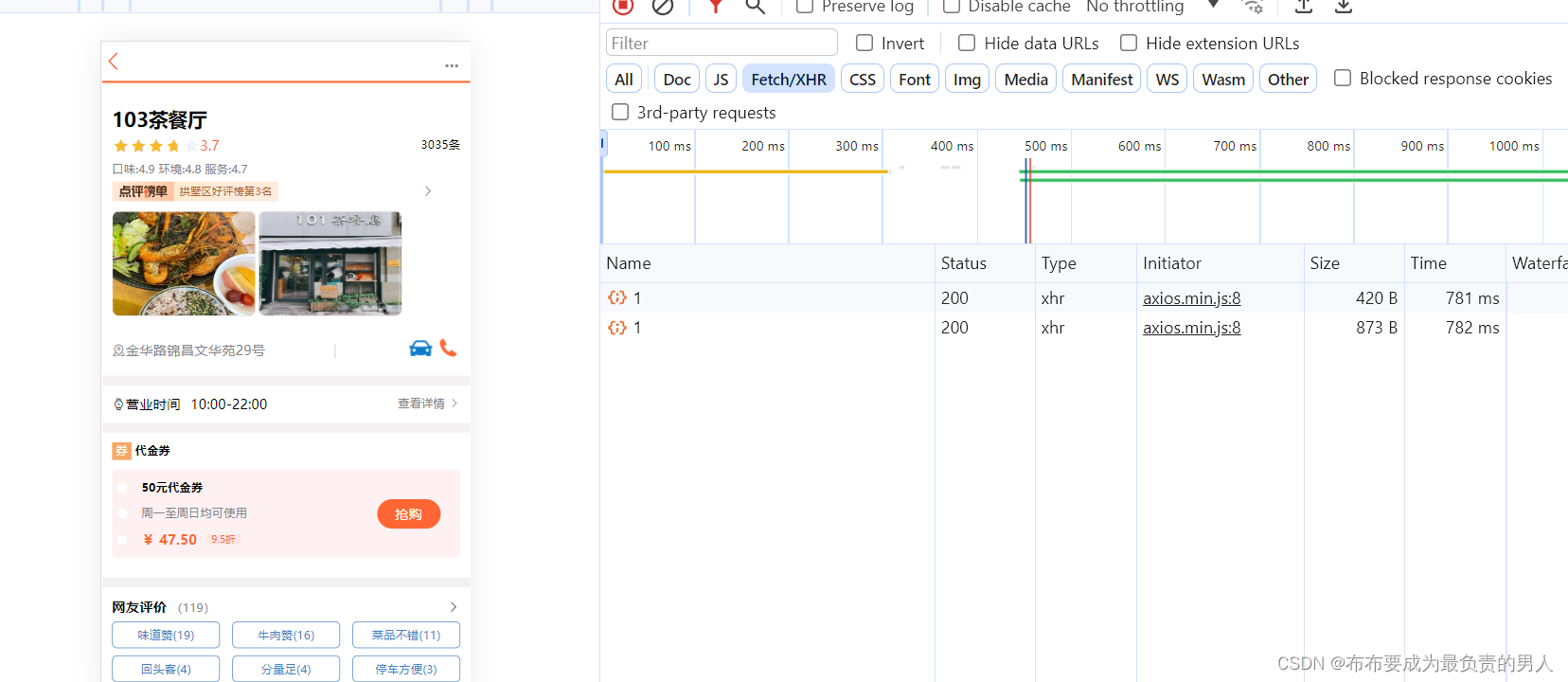
刷新页面,用了700多ms访问到该页面:
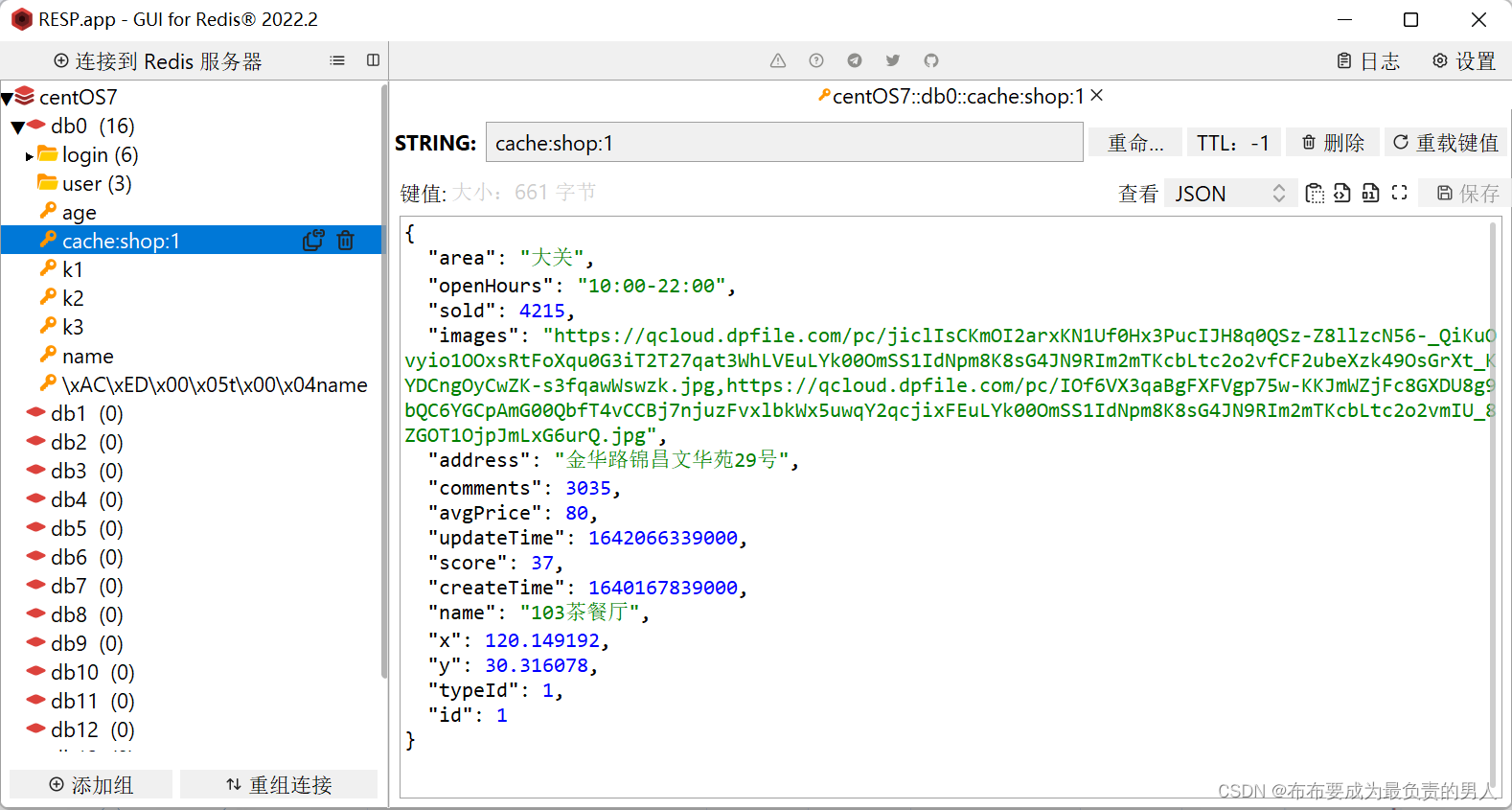
查询Redis数据库,发现成功存储:
再次刷新页面,可以发现拥有缓存后速度快了很多:
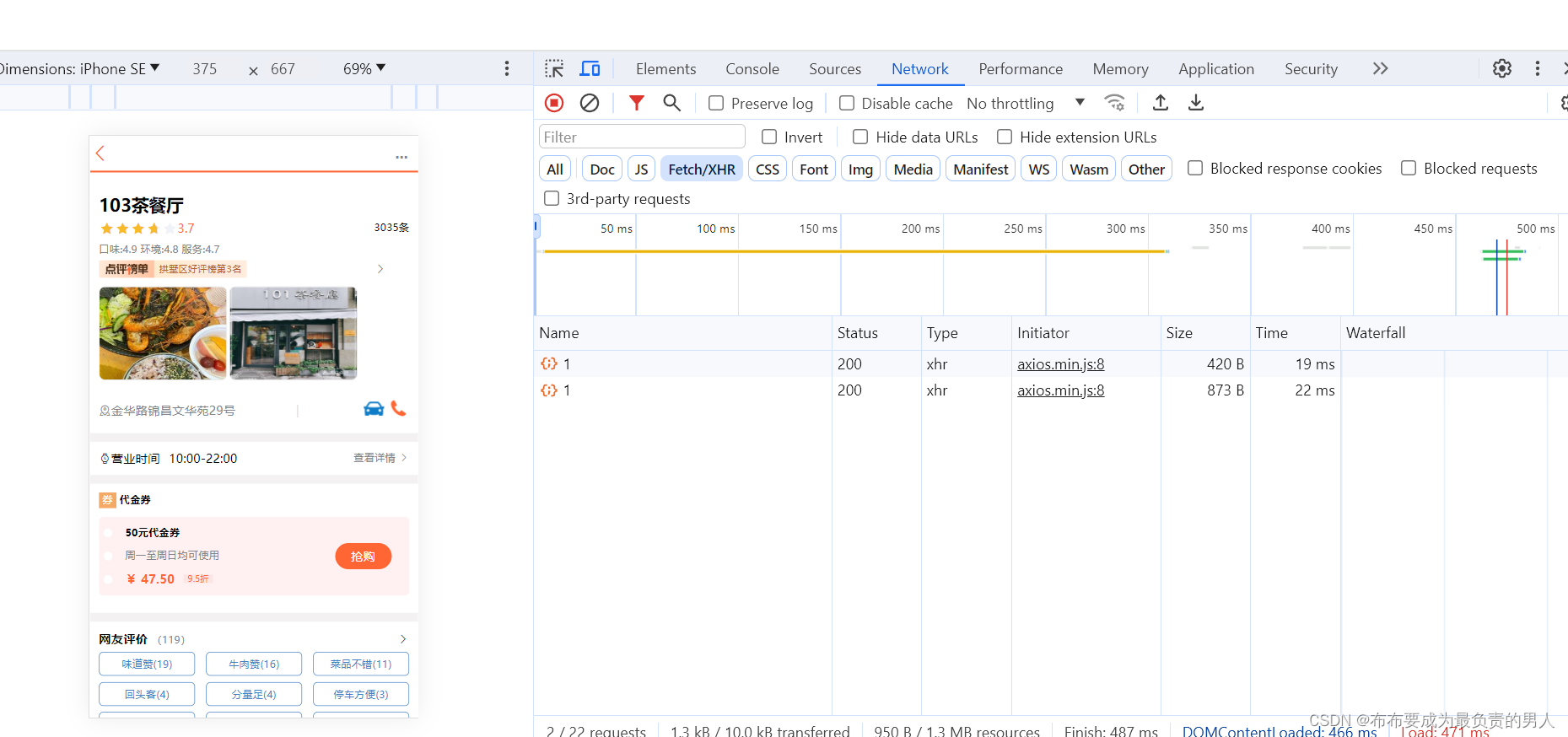
至此,我们已经成功给商户查询增添了Redis缓存。
给商品类型添加缓存
商品类型也就是Shop-List,在很多地方都会用到,比如首页:
这里的controller层代码逻辑:
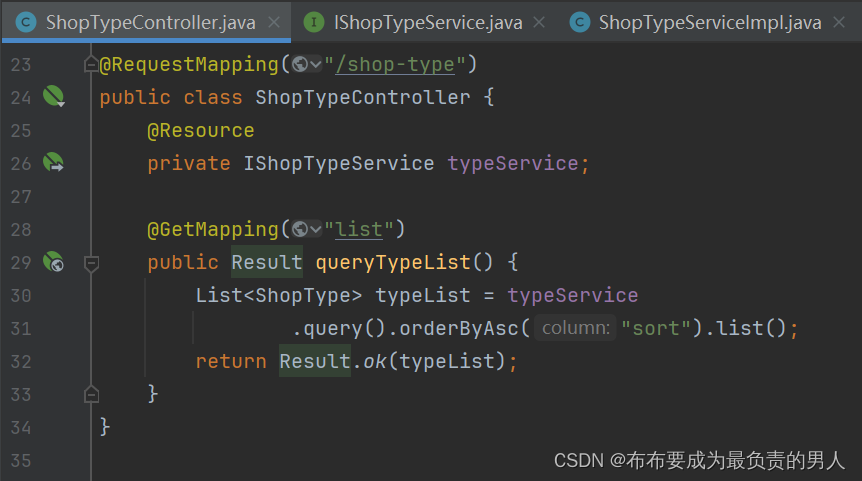
这个代码也是直接使用的mybatis-plus的查询功能,同时对“sort”这个优先级进行排序。
在这里添加Redis缓存,可以使用String也可以使用Hash,因为最终的返回值类型是List的,当然也可以使用List的数据结构。
这里最推荐使用的应该就是Hash了,因为List里面的内容都是对象,Hash是天然适配的。
但在这里我打算使用List来实现,用List实现的话,由于存储到Redis里面的List面向的是String类型的对象,所以我们从Redis取出后、在存入Redis的时候,都需要进行类型的转换。
这里的转换我用了比较高级一点的方式,先把List转换成Stream的形式,然后在map方法中进行转换。
controller层:
@GetMapping("list")
public Result queryTypeList() {
//List<ShopType> typeList = typeService
// .query().orderByAsc("sort").list();
//return Result.ok(typeList);
if (typeService.queryTypeList() == null){
return Result.fail("查询出错");
}
return Result.ok(typeService.queryTypeList());
}
service层:
@Service
public class ShopTypeServiceImpl extends ServiceImpl<ShopTypeMapper, ShopType> implements IShopTypeService {
@Resource
StringRedisTemplate stringRedisTemplate;
@Override
public List<ShopType> queryTypeList() {
//查询Redis是否有缓存
Long size = stringRedisTemplate.opsForList().size(CACHE_SHOP_TYPE_KEY);
//存储到Redis的——存储商品类型的List
List<String> typeList_String;
//返还给前端的——存储商品类型的List
List<ShopType> typeList;
//Redis里有数据,就转换成对象类型后直接返回数据
if (size != 0){
//CACHE_SHOP_TYPE_KEY="cache:shopType"
typeList_String = stringRedisTemplate.opsForList().range(CACHE_SHOP_TYPE_KEY, 0, size);
//将每个String都转换回ShopType类
typeList = typeList_String.stream().map(s->{
ShopType shopType = JSONUtil.toBean(s, ShopType.class);
return shopType;
}).collect(Collectors.toList());
return typeList;
}
//Redis里面没有数据,就查询数据库
typeList = this.query().orderByAsc("sort").list();
if (typeList == null || typeList.isEmpty()){
//数据库中不存在,返回null
return null;
}
//数据库里面有,就存入Redis缓存,并返回这个List
typeList_String = typeList.stream().map(shopType -> {
return JSONUtil.toJsonStr(shopType);
}).collect(Collectors.toList());
//存入Redis,注意插入的方式
stringRedisTemplate.opsForList().rightPushAll(CACHE_SHOP_TYPE_KEY, typeList_String);
//返回
return typeList;
}
}
刷新页面,响应时间接近600ms:
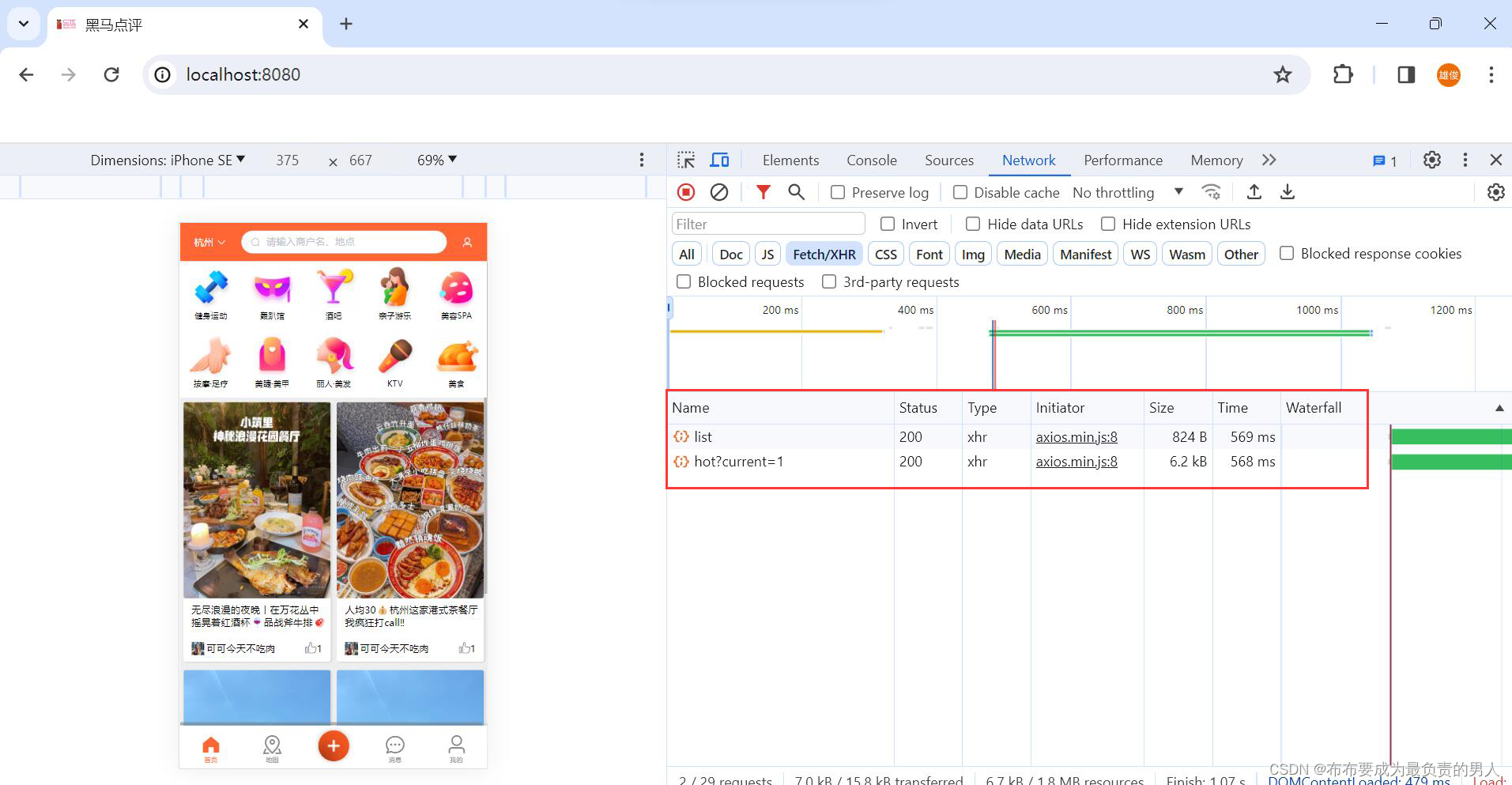
查看Redis,已经成功存储,且是按照sort来排序的:
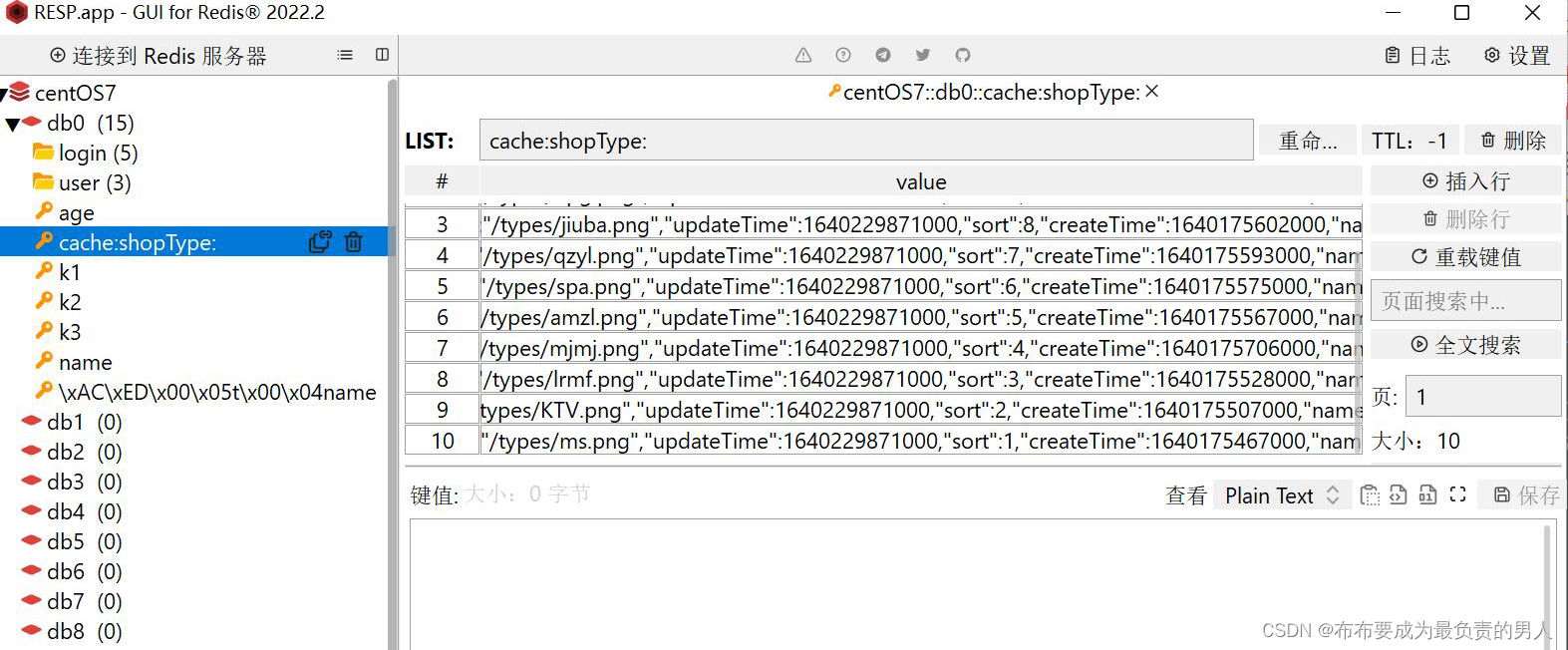
再次刷新,响应只花了20多ms:

缓存更新策略
学过计算机系统结构的同学应该知道,上面的作用模型可能会造成数据一致性问题,当我们对数据库进行修改的时候,缓存并没有同步进行修改,然后我们的页面在缓存中获取数据的时候,其实并不是最新的数据。这肯定是不允许的。
下面是缓存更新策略:
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不用自己维护,利用Redis的内存淘汰机制,内存不足时自动淘汰部分数据,下次查询时更新缓存 | 给缓存数据添加TTL时间,到期后自动删除缓存。下次查询即可实现缓存的更新 | 自己编写业务逻辑,在修改数据库的同时,更新缓存 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
上述的策略选择要根据具体的业务场景:
1、低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存。
2、高一致性需求:主动更新,以超时剔除作兜底方案。例如店铺详情查询的缓存。
主动更新策略
1、Cache Aside Pattern(最常用)
由缓存的调用者在更新数据库同时更新缓存
2、Read/Write Through Pattern
缓存与数据库整合为一个服务,由服务来维护一致性。调用者调用该服务无需关注一致性问题。但这种服务的成本肯定是很高的。
3、Write Behind Caching Pattern
调用者只操作缓存,由其它线程异步的将缓存数据持久化到数据库,保证最终一致。
比如我们一直对缓存进行更新,更新10次以后轮到这个线程工作,就维护一下数据库的数据为更新10次后的数据,中途的其他9次更新操作根本不重要,这样的性能显然是很高的。
这种方式当然也有很大问题,比如长期的数据不一致、缓存宕机造成的严重后果等。
之后的更新策略我们将会用第一种方式,操作缓存和数据库时有三个问题考虑:
更新缓存 or 删除缓存
更新缓存:每次更新数据库都更新缓存,中途无效写操作太多了
删除缓存:更新数据库时让缓存失效,查询时更新缓存
因此,我们会选择删除缓存
保证缓存与数据库操作同时成功或失败
单体系统:将缓存和数据库操作放到一个事务
分布式系统:利用TCC等分布式事务方案
总之我们要确保数据库与缓存操作的原子性
线程安全问题(重要问题)
我们到底要先删除缓存再操作数据库,还是先操作数据库再删除缓存呢?其实这两种方案都是会遇到问题的,我们可以先分析一下。
1、先删除缓存再操作数据库:
(1)正常情况
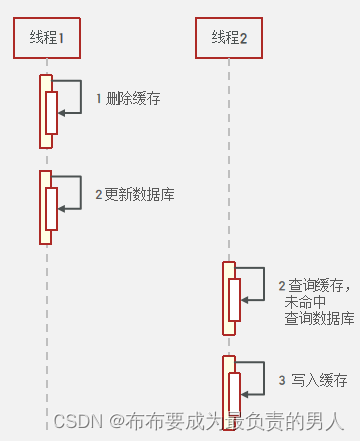
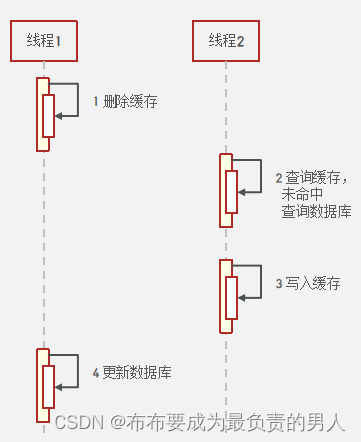
(2)异常情况
线程1工作的时候,线程2可能也要进行操作,就可能会造成数据不一致:
2、先操作数据库再删除缓存
(1)正常情况
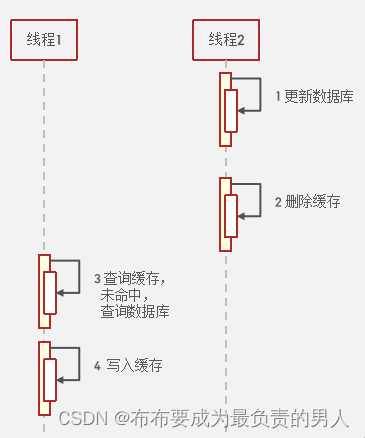
(2)异常情况
查询缓存未命中,在查询数据库的过程中,数据库更新了,这时候也会造成数据不一致:
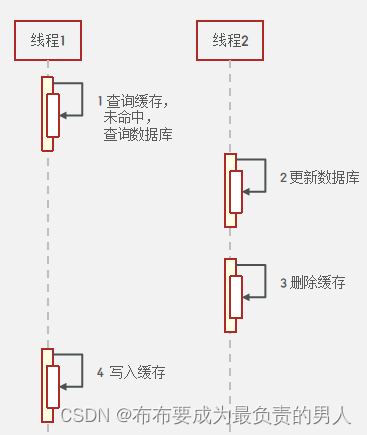
显然,第二种的异常条件是在查询数据库的过程中发生的不一致,相对是更难发生的,因此我们会选择先操作数据库,再删除缓存。
最佳实践方案
1、低一致性:使用Redis自带的内存淘汰机制
2、高一致性:主动更新,并以超时剔除作为兜底方案
(1)读操作:
①缓存命中直接返回
②缓存未命中则查询数据库,并写入缓存,设定超时时间(这是一个兜底,万一不一致,超时就剔除)
(2)写操作:
①先写数据库,再删除缓存
②确保数据库与缓存操作的原子性
实现商铺缓存与数据库的双写一致性
通过上面的讨论,现在我们要给查询商铺的缓存添加主动更新和超时剔除策略。
修改ShopController的业务逻辑满足:
(1)根据id查询店铺,没命中就查数据库,然后写入缓存,并设置超时时间
(2)根据id修改店铺,先操作数据库,再删除缓存
controller层:
@PutMapping
public Result updateShop(@RequestBody Shop shop) {
// 写入数据库
//shopService.updateById(shop);
return shopService.update(shop);
}
service层:
1、在queryById函数的写入Redis环节加上时间限定:

2、根据id更新商铺逻辑:
@Override
@Transactional //如果操作中有异常,我们用该注解实现事务回滚
public Result update(Shop shop) {
//我们要首先对id进行判断
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为空");
}
//更新数据库
updateById(shop);
//删除缓存 这里用了单事务,将删除缓存与更新数据库放在了一个事务里面
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}
我们现在可以进行验证,首先进行查询的验证,当我们打开商铺页面以后,后端会进行数据库查询操作,接着我们打开Redis可以发现:
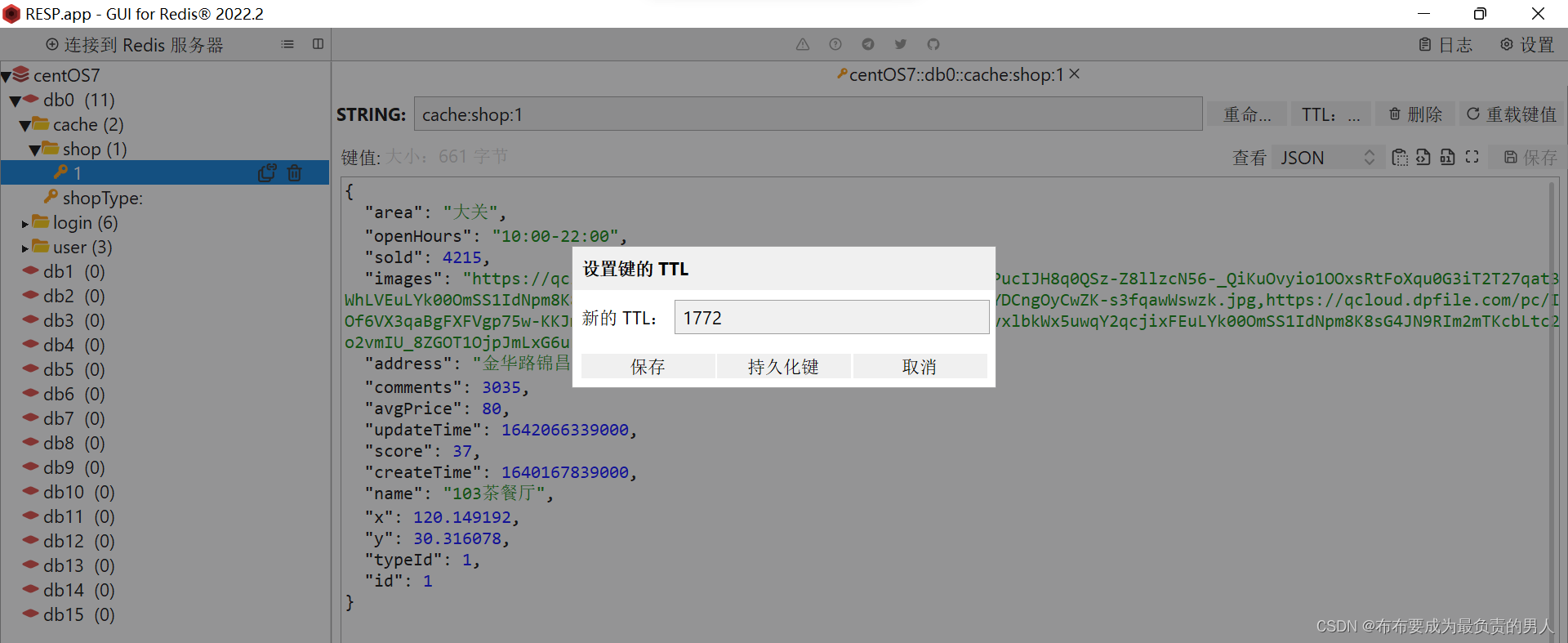
说明查询完毕了之后又写到了Redis,并且可以看到时限。
双写一致性的验证
对于修改店铺的验证,这种修改并不是使用前端的用户能进行的,因此我们需要Postman工具。
网页目前是103餐厅:
2、我们在postman中修改餐厅的名称,并点击send:

3、查询数据库是否成功修改:

4、刷新一下Redis,可以发现已经没有了,说明成功进行了缓存删除:

5、这时候去刷新浏览器,可以发现查询无误,说明确实是在缓存查询不到之后查询了数据库:
6、再次打开Redis,可以看见,查询完数据库以后,数据写回了Redis:
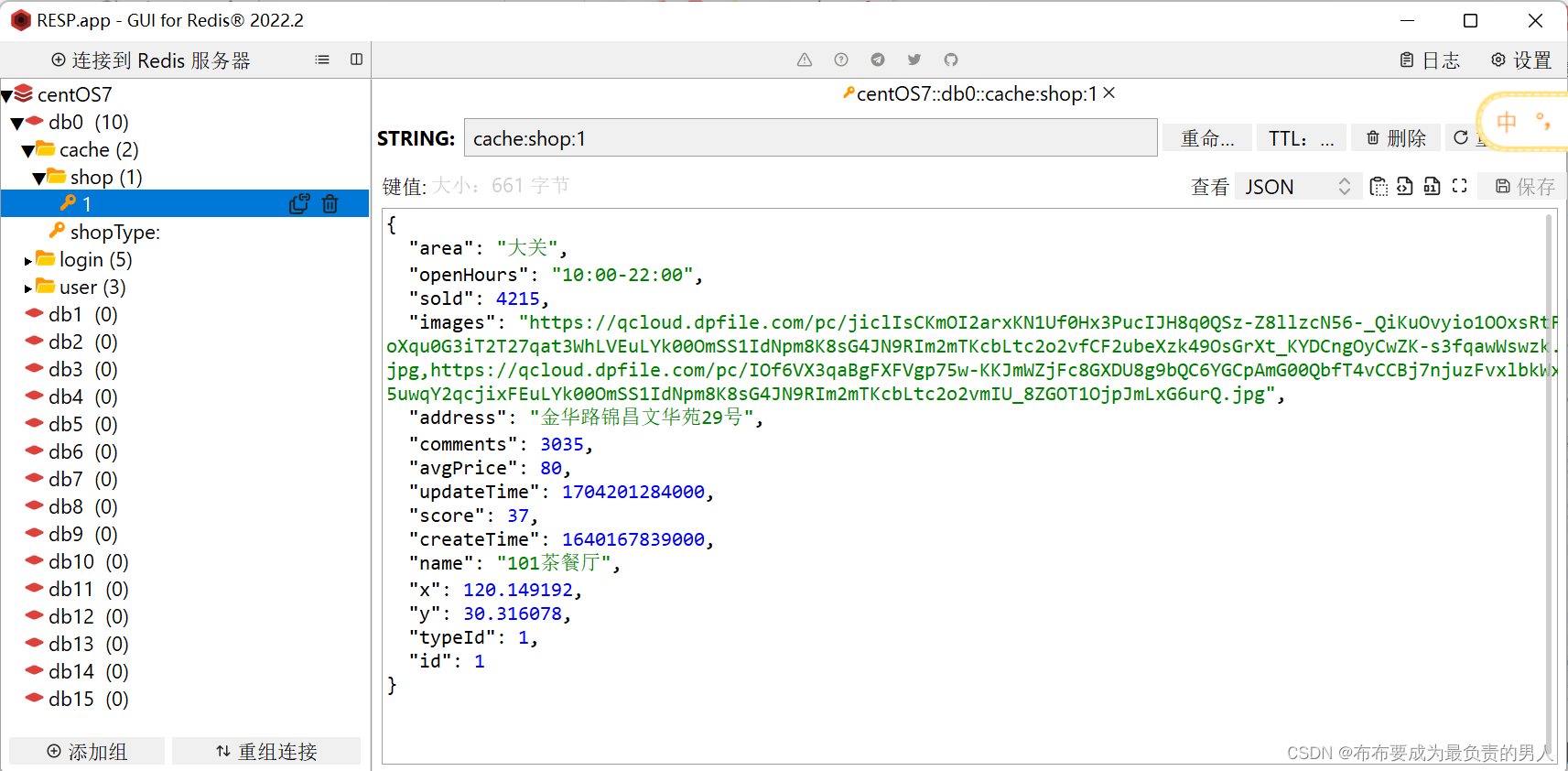
自此,流程完全调通!
上述是一些比较基础的内容和最佳实践,但是企业在使用Redis的时候,还会遇到其它难点和热点如缓存穿透、缓存雪崩、缓存击穿,在后续会慢慢解决这些问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 污水处理成套设备如何挑选
- 性能测试、分析、优化
- 2024中国管业十大品牌——皮尔特管业
- 刷题 ------ 枚举
- TikTok与环保:短视频如何引领可持续生活方式?
- vue折叠展开transition动画使用keyframes实现
- 日志审计系统Agent项目创建——获取Linux的ip并将得到的日志插入数据库中(Linux版本)
- 避免邮件进入垃圾箱的实用技巧:提高邮件接收率的策略
- 【前缀和】【分类讨论】2983:使用封装类解决回文串重新排列查询
- 【Spring Transaction afterCommit 调用不生效的原因分析】