Hago 的 Spark on ACK 实践
作者:华相
Hago 于 2018 年 4 月上线,是欢聚集团旗下的一款多人互动社交明星产品。Hago 融合优质的匹配能力和多样化的垂类场景,提供互动游戏、多人语音、视频直播、 3D 虚拟形象互动等多种社交玩法,致力于为用户打造高效、多样、最具沉浸式的社交娱乐体验,在东南亚、中东和南美等地区拥有广泛的用户群。
在技术层面,Hago 提供优秀的自研音视频技术,实现更加稳定、高效和优质的数字人服务。包括 3D 超写实模型、真人主播模型制作,虚拟人语音、表情驱动,自然声音的文字转语音(TTS),成熟的虚拟直播能力。
长期以来,Hago 都是在 IDC 里运行大数据任务,以支撑上面的许多产品,从 2022 年开始,Hago 开始将大数据业务迁移上云,并以?Spark on ACK?的形式来运行,本文主要针对迁移过程进行介绍。
IDC 中遇到的问题
起初,Hago 的 Spark 任务都是跑在 IDC 里的 Hadoop 集群里,当时主要面临几个问题:
- 资源限制问题:当资源不足时,导致任务堆积、排队
- 扩容的时效性:集群扩容逻辑比较复杂,特别是节假日有活动时,往往要提前一周准备扩容
- 资源利用率问题:Spark 任务有明显的波峰波谷,波谷的资源浪费明显
- 为了解决上面几个问题,Hago 决定把大数据业务用云原生的方式迁移上云
实施
Spark 项目从 3.1 开始,Spark on Kubernetes 的功能正式 GA。
所以,ACK 作为托管的 Kubernetes 发行版,提供更高的性能和更强稳定性,自然成为阿里云上 Spark 的最佳运行底座,这里为了更好的弹性效果,Hago 选择了 Serverless 版本的 ACK。
ACK Serverless

在 ACK Serverless 集群中,无需购买节点即可直接部署容器应用,无需对集群进行节点维护和容量规划,并且根据应用配置的 CPU 和内存资源量进行按需付费。ACK Serverless 集群提供完善的 Kubernetes 兼容能力,同时降低了 Kubernetes 使用门槛,用户更专注于应用程序,而不是管理底层基础设施。
同时,ACK Serverless 集群中的 Pod 基于阿里云弹性容器实例 ECI 运行在安全隔离的容器运行环境中。每个 Pod 容器实例底层通过轻量级虚拟化安全沙箱技术完全强隔离,容器实例间互不影响。
在 Spark 这种大规模业务峰值脉冲和任务调度的场景,ACK Serverless 集群的弹性优势也更加明显,可以在 30s 内交付几千个 Pod。
但在真正运行之前还有一些问题需要解决:
存算分离
上面提到,Spark 任务对算力的需求不是 7*24 小时的,但是存储是一直留存的,如果用传统的方式,在虚拟机上搭建 HDFS 集群,那就需要常驻大量的算力,也意味着产生大量的浪费。
Hago 选择存算分离的方案,将数据放在 OSS 里,通过 OSS-HDFS 服务把数据用 HDFS 接口暴露出来,方便 Spark 任务读取。
详情请参阅:OSS-HDFS 服务概述 [ 1]
shuffle service 的选型
shuffle 是 Spark 中最基本的过程之一,同时,shuffle 对于 Spark 应用程序的性能至关重要。
Spark 社区提供了默认的 shuffle service [ 2] ,但存在一些问题:
- Spark Shuffle 对本地存储有依赖,许多计算存储分离的机型、使用 ECI 的场景下没有自带本地盘,需要额外购买和挂载云盘,性价比和使用效率低
- Spark 基于 ShuffleTracking 实现了 Dynamic Allocation,但 Executor 回收效率低下
具体表现如下:
- Shuffle Write 在大数据量场景下会溢出,导致写放大
- Shuffle Read 过程中存在大量的网络小包导致的 Connection reset 问题
- Shuffle Read 过程中存在大量小数据量的 IO 请求和随机读,对磁盘和 CPU 造成高负载
- 对于 M*N 次的连接数,在 M 和 N 数千的规模下,作业基本无法完成
EMR 推出的 RSS 服务,可以优化上述 Spark Shuffle 方案的问题,完美支持 ACK 环境下的 Dynamic Allocation。
详情请参阅:EMR Remote Shuffle Service [ 3]
落地效果
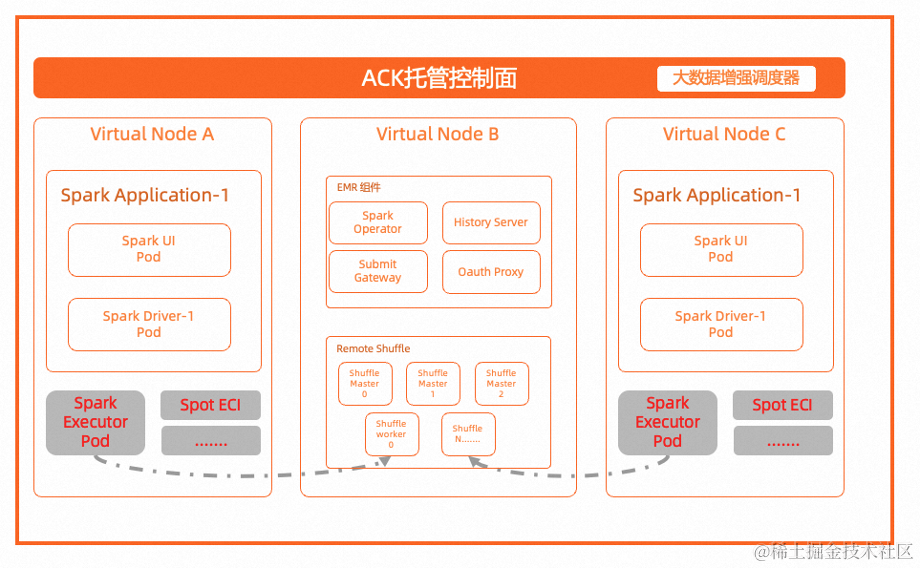
最终落地的架构图大致如上所示,取得了非常理想的效果:
- 基本不需要提前准备,扩容只需要 30s
- 任务不再需要排队
- 不需要关心 IDC 的硬件故障问题
相关链接:
[1]?OSS-HDFS 服务概述
https://help.aliyun.com/zh/oss/user-guide/overview-1
[2]?shuffle service
https://github.com/lynnyuan-arch/spark-on-k8s/blob/master/resource-managers/kubernetes/architecture-docs/external-shuffle-service.md
[3]?EMR Remote Shuffle Service
https://help.aliyun.com/zh/emr/emr-on-ecs/user-guide/celeborn#task-2184004
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!