谷歌公布一个可以让 AI 进行自我判断输出内容正确性的模型训练框架 ASPIRE
发布时间:2024年01月24日
谷歌开发了一款名为 ASPIRE 的训练框架,旨在增强人工智能(AI)模型的选择性预测能力。这款框架为模型引入了 “可信度” 机制,即模型会输出一系列答案,并为每个答案赋予一个正确概率评分。通过这种方式,ASPIRE 训练框架可以提高大语言模型的输出准确率,并使较小的模型经过微调后能够进行准确且有自信的预测。




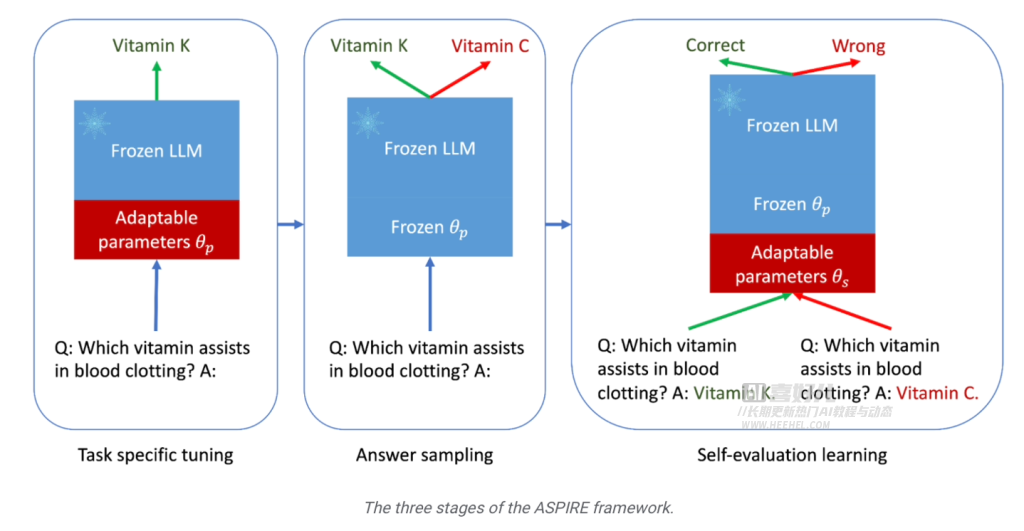
ASPIRE 训练框架主要分为三个阶段:
- 首先是“特定任务调整”阶段,该阶段对已经接受过基础训练的大型语言模型进行深入训练,重点加强模型的预测能力。研究人员通过引入一系列可调参数,在特定任务的训练数据集上微调预训练语言模型,从而提高模型的预测性能,使其能够更好地解决特定问题。
- 第二阶段是 “答案采样”,在特定微调后,模型可以利用先前学习到的可调参数,为每个训练问题生成不同的答案,并创建用于自我评估学习的数据集,生成一系列可信度较高的答案。研究人员使用集束搜索(Beam Search)方法和 Rouge-L 算法来评估答案的质量,并将生成的答案及评分重新输入给模型,开启第三阶段。
- 第三阶段是 “自我评估学习”,研究人员为模型添加一组可调参数,专门用于提升模型的自我评估能力。该阶段的目标是让模型学会自己判断输出的答案准确性,从而在生成答案时附上答案的正确概率评分。
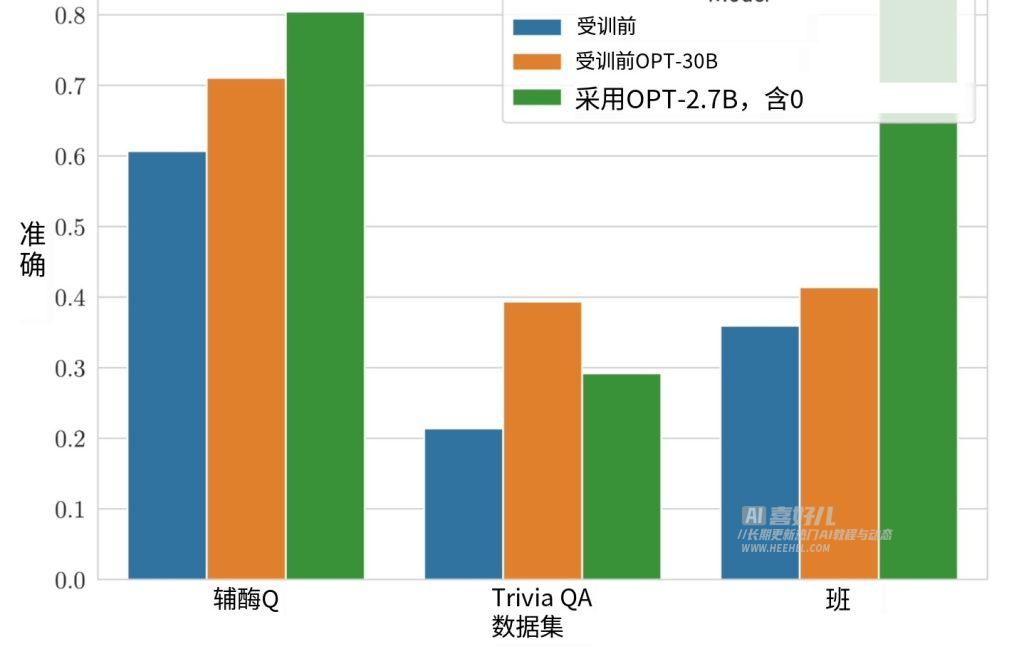
谷歌研究人员使用 CoQA、TriviaQA 和 SQuAD 三个问答数据集来验证 ASPIRE 训练框架的成果,结果显示经过 ASPIRE 调整的小模型表现远超更大的模型。这项实验结果也表明,经过适当调整,即使是较小的语言模型,在某些场景下也能超越大语言模型。
总的来说,ASPIRE?训练框架可以显著提升大语言模型的输出准确率,并使较小的模型经过微调后能够进行准确且有自信的预测。这一框架为 AI 模型引入了可信度机制,使其能够自我判断输出内容的正确性,从而在高风险决策类场合应用更加可靠。

文章来源:https://blog.csdn.net/heehelcom/article/details/135828771
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- win11修改本地hosts,自定义域名
- multipath 内核接口及框架介绍
- Leetcode—859.亲密字符串【简单】
- 什么是 DDoS ?如何识别DDoS?怎么应对DDOS攻击
- axios query传数组参数的格式
- Linux 系统中忘记了用户密码,可以通过以下步骤来重置密码
- 分库分表解决方案-ShardingSphere-JDBC
- leecode556 | 下一个更大的元素iii
- C++ STL(1)--概述
- 研讨会分享 | 非遗文化的守正创新与数字化传播