Linux - 进程间通信(中)- 管道的应用场景
前言
在上篇博客当中,对Linux 当中的进程通信,做了详细阐述,主要是针对父子进程的通信来阐述的同时,也进行了模拟实现。
对于管道也有了初步了解,但是这仅仅是 进程间通信的一部分,Linux 当中关于进程间通信还有很多的内容,这篇博客将会在上篇博客的基础之上,继续阐述进程间通信。
如有疑问,请看上篇博客:
Linux - 进程间通信(上) - Linux 当中的管道-CSDN博客
管道的应用场景
我们知道,在Linux 当中,有一个命令 -- "|" ,我们也把这个命令称之为管道,那么这个命令和我们上篇博客当中,对于管道的介绍有什么关系呢?
cat text.txt | head -10 | tail-5比如上述命令,在之前来解释的话,就是把 cat text.txt 的运行结果,通过管道,传输给 head -10 ,然后 head -10 也有有一个输出结果,又把这个输出结果,通过管道,传输给 tail -5,此时得出的结果才是上述命令的最终结果。
?而上述我们所使用的 -- "|" 命令,和 Linux 当中的 pipe 管道是有关系的。
?我们拿下述 sleep 这个命令来说明上述 -- "|" 的实现:
?
sleep 6666 | sleep 7777 | sleep 8888在执行上述命令之前,我们先用 ps 命令查看一下当中 关于 sleep 的进程,发现此时只有一个 sleep 进程:?

当我们执行上述命令之后,发现系统的当中就多出了上述的??sleep 6666 ,sleep 7777 ,sleep 8888 这个三个进程:
?
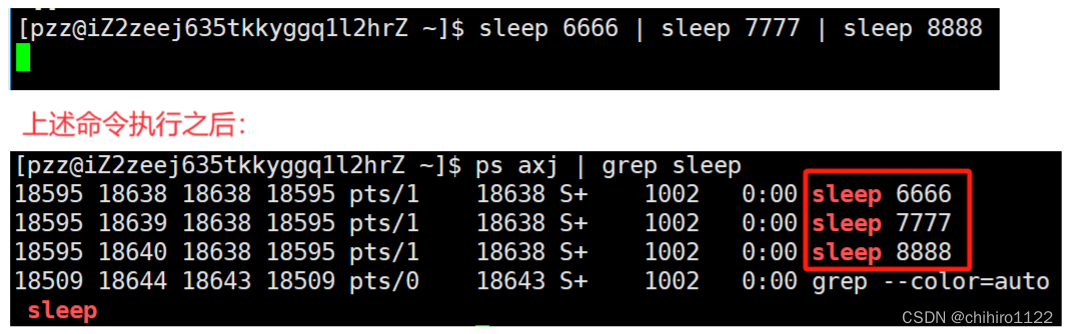
?而这??sleep 6666 ,sleep 7777 ,sleep 8888 这三个进程 的 PPID 都是 18595,也就是说,这三个进程的 PPID (父进程的PID)是一样的。
说明,这三个进程 互相直接的关系是兄弟进程。也就是具有血缘关系。
?很显然,这个18595的PID 是 BASH 的PID。
?而上述的实现也就和上篇博客当中的父子通信的原理是一样的:
首先,操作系统会先创建上述的两个管道,创建之后,在创建???sleep 6666 ,sleep 7777 ,sleep 8888 这三个进程,三个进程通过程序替换的方式,执行不同的代码块。
然后,利用上篇博客当中的对于 进程之间通信的共享文件,哪一个进程是读端,哪一个进程是写端,确定好。
也就是对每一个进程的 0,1,2 号文件,所输入或者输出重定向,使得这些文件的输出和输入不再是单纯的从 键盘文件读取数据,显示器文件输出数据。而是在指定的共享文件当中进行的数据的输入和输出,实现三个进程之间的通信。
这样就建立好了这三个进程之间的链接。
所以,这个 "|" 管道,在底层实现上就是使用 PIPE()函数,实现的 进程之间的通信。
?而这 "|" 管道,就是一种匿名管道。
?shell 当中实现?"|" 管道 原理
?Linux - 基础IO(重定向 - 重定向模拟实现 - shell 当中的 重定向)- 下篇-CSDN博客
?上述?Linux - 基础IO(重定向 - 重定向模拟实现 - shell 当中的 重定向)博客当中是对shell 加入 重定向之后的shell,其中大体流程如下所示:

显示做出与用户交互的函数,也就是打印出控制台,接受用户输入的命令,判断输入的命令是否有误等等。
然后是对接受到的命令做字符串的分割,把需要执行什么命令解析出来,也就是解析用户的输入的字符串。
然后,判断解析出来的命令,是不是内建命令,如果是,就执行内建命令;如不是,就执行普通命令。
但是,现在要想实现管道的话,管道左右两边的命令可以是内建命令,也可以是普通命令。
所以,我们在解析命令的过程当中,先要解析用户当中有没有 "|" 管道,如果有,就要以 "|" 管道为分割符,把命令一个一个的解析出来;也就是判断,命令字符串当中有多少 "|" ,从而把这个字符串打散为多个字符串。
这些字符串就是一个一个需要执行的命令,所以,需要 malloc 开辟空间来保存这个字符串(如果当中malloc 满了,好临时扩容空间)。
然后,在创建这些命令的子进程之前,需要先创建出 "|",也就是在代码当中写一个循环,在创建管道左右的子进程之时,就可以通过 pipe()函数,链接出左右两个进程之间的 共享文件的链接关系(重定向)。
之后就是循环创建出子进程,对各个子进程的 输入和输出重定向做修改,实现子进程之间的通信。(在管道的最开始就是 1->指定一个管道的写端;管道中间的进程,0标准输入重定向到上一个管道的读端,标准输出指定到下一个管道的写端;最后一个,将标准输入重定向到最后一个管道的读端)?
在让不同的子进程执行不同的命令,也就是 exec* 程序替换,程序替换不会影响到这个进程在替换之间,曾经打开的文件,也就不会影响到曾经预先设置好的重定向文件位置了
通过管道简单实现进程池?
?在 C/C++ 当中有内存池,这样可以更高效的像操作系统申请内存空间供用户使用。其实本质上也就是 像是打水一样,如果每天都需要去河边打一桶水,那么来回的路程,是相对于每一天都需要去跑的,如果,我们一天一次性打上很多桶水。比如是开车 去打上一车的水,这一车的水可以供我们一个星期来使用,那么这个一个星期都可以不同再去河边去打水了。省去了来回在路上往返的消耗了。
同样的,如果要想要操作系统为我们申请内存空间的话,是有消耗的。因为操作系统本身也是有很多事情要去做的,那么在操作系统做完当前事情之前,我们需要去等待。
而且,操作系统也是通过调用底层系统调用接口来实现的,内存属于硬件,硬件就有自己的驱动程序,操作系统在上层,只能一层一层往下去访问到内存硬件资源。这些其实都是有消耗的。
所以,在不浪费内存资源,适量的情况下,预先加载多个内存资源,就可以在一定程度上缓解,通过操作系统申请内存资源所带来的消耗。
同样的,对于申请进程而言,如果单纯的,需要一个进程就去创建一个进程的话,也是和上述一天打一桶水的结果是一样的。都是有消耗的。
创建进程需要申请内存空间,需要有进程地址空间,有进程PCB,由页表等等的内核数据结构,而且,里链接这些内核数据结构也是需要时间的。
所以,在操作系统当中,同样是有 内存池 这样的 “池”的。
我们对这种池的创建,称之为-- 池化技术。
我们预先创建好 多个 进程所需的进程资源,当我们想要用到某一个进程资源之时,只需要直接指派这个进程,帮我们去完成任务。
在父进程接受到任务之前,先预先在创建出多个 子进程的资源:
?

父进程和每一个子进程之间都建立一条管道的信道, 每一个子进程只负责从管道当中读取数据;而父进程之负责,把对应数据,输入到 对应子进程的管道当中。
如果,父进程没有向一个管道当中写入任何数据,那么这个管道对应的子进程就是阻塞在这个管道当中。等待父进程向管道当中输入数据。
一旦父进程向某一个管道当中写入数据了,那么对应子进程就会读到这些数据,就可以继续执行子进程当中的代码。
我们把父进程向管道当中写入的数据,叫做一个一个的任务码。
规定,父进程在写入数据之时,一次只能写 4字节的内容,子进程在读取数据之时,一次也只能读取4字节的内容。总之就是以等长的数据长度写入,以等长的数据长度读取(4字节只是假设,具体要看对应的操作系统的设计)
完整代码
// Task.cpp
// 任务列表,text.cc 源程序当中,用户从这个 LoadTask ()函数当中选择对应的任务
#pragma once
#include <iostream>
#include <vector>
typedef void (*task_t)();
// 下述的 tesk1-4 都是对应的任务
// LoadTask()函数是选择这些任务的函数,供text.cc 源程序当中进行选择
// <---- 这里我们使用函数指针的方式来 使得 子进程能直接跳转到 下述的 tesk1-4 都是对应的任务 函数当中进行执行 ---->
void task1()
{
std::cout << "lol 刷新日志" << std::endl;
}
void task2()
{
std::cout << "lol 更新野区,刷新出来野怪" << std::endl;
}
void task3()
{
std::cout << "lol 检测软件是否更新,如果需要,就提示用户" << std::endl;
}
void task4()
{
std::cout << "lol 用户释放技能,更新用的血量和蓝量" << std::endl;
}
// 传入一个 vector<task_t> ,这个容器当中哦弄个存储的是一个一个的任务
// 下述当中的 tasks 是一个输出型参数
void LoadTask(std::vector<task_t> *tasks)
{
tasks->push_back(task1);
tasks->push_back(task2);
tasks->push_back(task3);
tasks->push_back(task4);
}#include "Task.hpp"
#include <string>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <cassert>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/wait.h>
const int processnum = 10;
std::vector<task_t> tasks; // 任务列表,用于 LoadTask ()函数返回 任务清单
// 这个 tasks 容器当中存储的是 一个一个 task()任务执行函数的 函数指针
// 子进程通过这个函数指针,就可以直接调用到 对应的函数体当中去执行代码
// 先描述
// 父进程为了能管理各个管道
// 把各个管道用结构体对象描述起来
// 一个channel 就是一个管道结构体
class channel
{
public:
// 用于构造一个 管道类 的构造函数
channel(int cmdfd, int slaverid, const std::string &processname)
:_cmdfd(cmdfd), _slaverid(slaverid), _processname(processname)
{}
public:
int _cmdfd; // 发送任务的文件描述符
pid_t _slaverid; // 子进程的PID
std::string _processname; // 子进程的名字 -- 方便我们打印日志
// int _cmdcnt;
};
// 子进程需要做的事情
void slaver()
{
// read(0)
while(true) // 循环一直做,直到做完
{
int cmdcode = 0;
// read参数: (从0号文件当中读取数据, 保存到cmdcode变量当中, 一次只读取 4 字节的内容
int n = read(0, &cmdcode, sizeof(int)); // 如果父进程不给子进程发送数据呢??阻塞等待!
if(n == sizeof(int)) // n 是read()的返回值,返回的是 成功从文件当中读取的字节个数
{
//执行cmdcode对应的任务列表
// 先 打印子进程的PID,然后打印 当前从文件当中读取的内容
std::cout <<"slaver say@ get a command: "<< getpid() << " : cmdcode: " << cmdcode << std::endl;
// 判断当前的 执行任务是否 是在安全区间当中的
if(cmdcode >= 0 && cmdcode < tasks.size())
tasks[cmdcode](); // 执行任务
}
// 如果 read() 函数返回返回 0 ,说明读取错误,我们就跳出这个循环
if(n == 0) break;
}
}
// 先预先建立好管道共享文件,然后预先创建子进程,把各个子进程和父进程之间连接上管道
void InitProcessPool(std::vector<channel> *channels)
{
// version 2: 确保每一个子进程都只有一个写端
std::vector<int> oldfds;
for(int i = 0; i < processnum; i++)
{
// pipedf[] 数组用于pipe函数当中的 输出型参数的返回值的存储
// pipedf[0] 是共享文件的读端;pipedf[1] 是共享文件的写端
int pipefd[2]; // 临时空间
int n = pipe(pipefd); // 创建管道
assert(!n); // pipe() 创建成功返回0,否则返回 -1
(void)n;
pid_t id = fork(); // 创建子进程
if(id == 0) // child 执行的代码块
{
std::cout << "child: " << getpid() << " close history fd: ";
for(auto fd : oldfds) {
std::cout << fd << " ";
close(fd);
}
std::cout << "\n";
close(pipefd[1]); // 关闭写端文件
// 下述的 进程替换,就是把 子进程当中的 0 号文件,本来是标准输入文件,也就是键盘文件读取数据
// 现在修改为管道文件的 来读取数据
// 这样的好处是 以后 子进程就会不用再去管其他的 去哪里接收父进程传输的数据了
// 只需要“无脑”的从 子进程的 0号文件当中读取数据既可以
dup2(pipefd[0], 0); // 进程替换
close(pipefd[0]); // 因为上述已经进行了 重定向,所以 pipefd[0] 号文件就可以关闭了
slaver(); // 执行 子进程当中需要做的任务
std::cout << "process : " << getpid() << " quit" << std::endl; // 提示子场景完成任务,即将退出
// slaver(pipefd[0]);
exit(0); // 子进程退出 , 所以下述代码就可以不同执行了
}
// father 执行的代码块
close(pipefd[0]); // 关闭读端文件
// 添加channel字段了
// 往 存储 channel 对象的 vector 容器当中添加当前管道的 channel 对象
std::string name = "process-" + std::to_string(i);
channels->push_back(channel(pipefd[1], id, name));
oldfds.push_back(pipefd[1]);
sleep(1);
}
}
void Debug(const std::vector<channel> &channels)
{
// test
for(const auto &c :channels)
{
std::cout << c._cmdfd << " " << c._slaverid << " " << c._processname << std::endl;
}
}
void Menu()
{
std::cout << "################################################" << std::endl;
std::cout << "# 1. 刷新日志 2. 刷新出来野怪 #" << std::endl;
std::cout << "# 3. 检测软件是否更新 4. 更新用的血量和蓝量 #" << std::endl;
std::cout << "# 0. 退出 #" << std::endl;
std::cout << "#################################################" << std::endl;
}
void ctrlSlaver(const std::vector<channel> &channels)
{
int which = 0;
// int cnt = 5;
while(true)
{
int select = 0;
Menu(); // 打印菜单,供用户选择操作
std::cout << "Please Enter@ ";
std::cin >> select;
// 判断用户输入是否正确
if(select <= 0 || select >= 5) break;
// select > 0&& select < 5
// 1. 选择任务
// int cmdcode = rand()%tasks.size(); // tasks 是定义的全局 vector<task_t> 容器
int cmdcode = select - 1; // 由用户去选择
// 2. 选择进程
// 使用随机数来 选择 父进程当前要选择的子进程 来执行子任务
// 防止 父进程 一直选择 某一个进程来执行任务,那么其他的资源就浪费了
// 除了这种方式,还可以使用 轮询的方式,也就是递增或者是递减循环选择 子进程的方式来实现
// write(channels[processpos]._cmdfd, &cmdcode, sizeof(cmdcode)); 这样使用即可
// int processpos = rand()%channels.size(); 这种方式是使用随机数的方式来 进行 选择进程
std::cout << "father say: " << " cmdcode: " <<
cmdcode << " already sendto " << channels[which]._slaverid << " process name: "
<< channels[which]._processname << std::endl;
// 3. 发送任务
// 这种使用 which 的方式其实就是一种 轮询的方式 来选择 进程的
write(channels[which]._cmdfd, &cmdcode, sizeof(cmdcode));
which++;
which %= channels.size(); // 不哟让 which 越界了
// cnt--;
// sleep(1);
}
}
// 让所有的进程全部退出
void QuitProcess(const std::vector<channel> &channels)
{
for(const auto &c : channels){
close(c._cmdfd); // 将子进程当中的写端直接关闭,这样的话,在子进程当中的 read()函数就会返回 0
// 只要检测到 read()函数返回0 ,就可以在 父进程 控制子进程的函数当中退出 子进程
waitpid(c._slaverid, nullptr, 0); // 因为此时 QuitProcess ()函数是 父进程执行的
// 子进程退出,父进程要等待子进程退出
}
// version1
// int last = channels.size()-1;
// for(int i = last; i >= 0; i--)
// {
// close(channels[i]._cmdfd);
// waitpid(channels[i]._slaverid, nullptr, 0);
// }
// for(const auto &c : channels) close(c._cmdfd);
// // sleep(5);
// for(const auto &c : channels) waitpid(c._slaverid, nullptr, 0);
// // sleep(5);
}
int main()
{
LoadTask(&tasks); // 获取到任务 tasks 是定义的全局 vector<task_t> 容器
srand(time(nullptr)^getpid()^1023); // 种一个随机数种子
// 在组织
// 用下述的 vector 数据结构把 一个一个的管道结构体管理起来
// 从此之后,父进程管理一个一个的管道,就变成了对这个 vector 数据结构的增删查改
std::vector<channel> channels;
// 1. 初始化 --- bug?? -- 找一下这个问题在哪里?然后提出一些解决方案!
InitProcessPool(&channels);
// Debug(channels);
// 2. 开始控制子进程
ctrlSlaver(channels);
// 3. 清理收尾
QuitProcess(channels);
return 0;
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【AI视野·今日Sound 声学论文速览 第四十二期】Fri, 5 Jan 2024
- 设计模式——命令模式
- 跳转漏洞检测工具汇总(重定向漏洞)
- UnityVR入门之六 如何让3DUI层级在场景模型之上
- 谷歌Gemini模型,碾压GPT-4!
- Win11/Win10 开机蓝屏提示代码inaccebootdevice 无限重启(附带如何制作系统U盘)
- C语言入门到精通之练习实例10:打印楼梯,同时在楼梯上方打印两个笑脸(附源码)
- SvgShellExtensions 在资源管理器直接预览SVG格式图片
- 前端显示json格式化
- 程序媛的mac修炼手册--微博爬虫看江疏影如何被雪球套