pandas库学习以及一些常见函数
文章目录
1. pandas简介

-
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
-
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
-
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
-
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
-
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
-
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
-
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
-
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
-
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
-
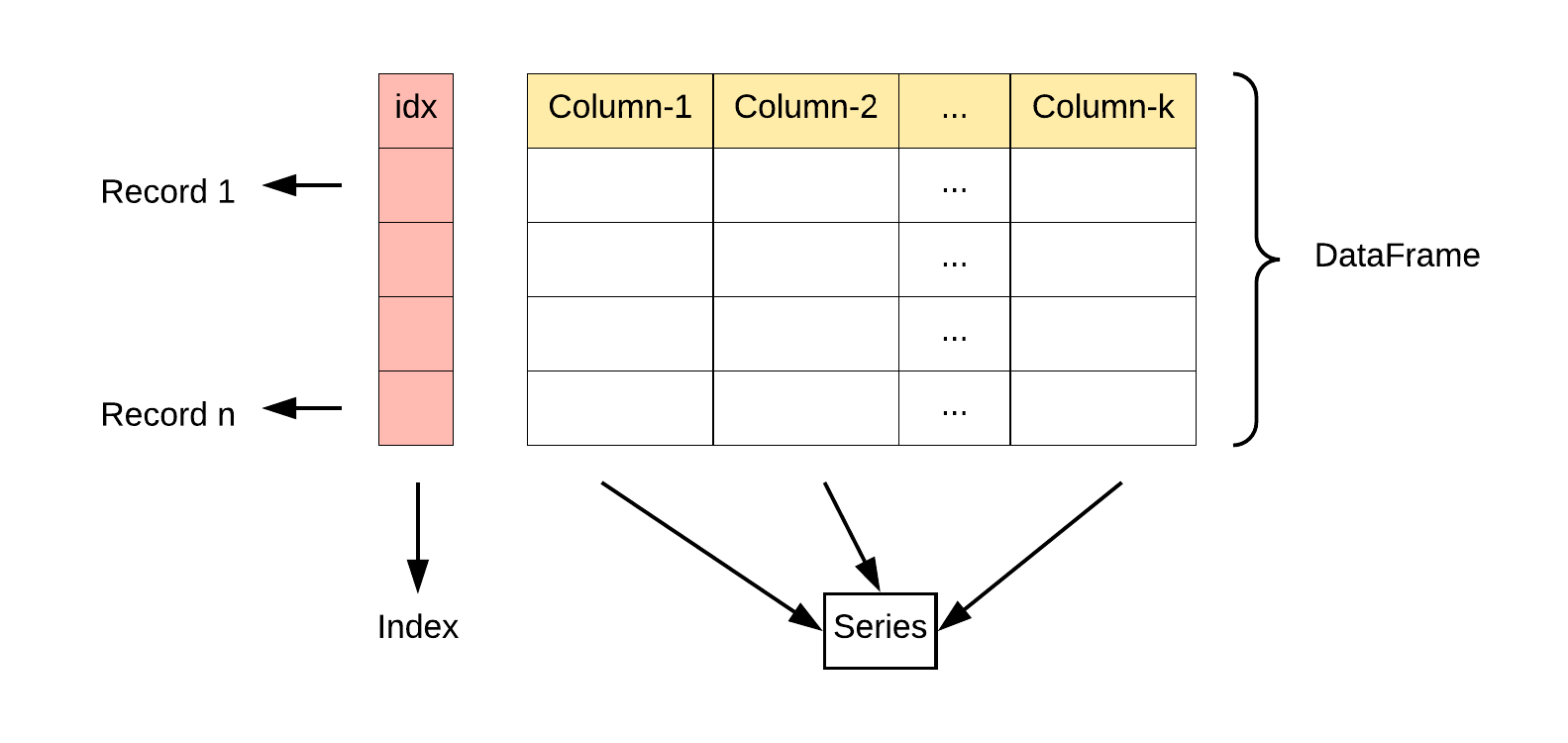
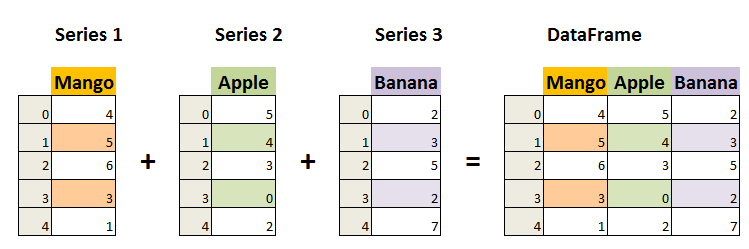
Pandas 主要引入了两种新的数据结构:DataFrame 和 Series。
-
Series: 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。

-
-
DataFrame: 类似于一个二维表格,它是 Pandas 中最重要的数据结构。DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引,因此可以方便地进行行列选择、过滤、合并等操作。

DataFrame 可视为由多个 Series 组成的数据结构:
-
Pandas 提供了丰富的功能,包括:
- 数据清洗:处理缺失数据、重复数据等。
- 数据转换:改变数据的形状、结构或格式。
- 数据分析:进行统计分析、聚合、分组等。
- 数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
1.1 Pandas应用
Pandas 在数据科学和数据分析领域中具有广泛的应用,其主要优势在于能够处理和分析结构化数据。
以下是 Pandas 的一些主要应用领域:
- 数据清洗和预处理: Pandas被广泛用于清理和预处理数据,包括处理缺失值、异常值、重复值等。它提供了各种方法来使数据更适合进行进一步的分析。
- 数据分析和统计: Pandas使数据分析变得更加简单,通过DataFrame和Series的灵活操作,用户可以轻松地进行统计分析、汇总、聚合等操作。从均值、中位数到标准差和相关性分析,Pandas都提供了丰富的功能。
- 数据可视化: 将Pandas与Matplotlib、Seaborn等数据可视化库结合使用,可以创建各种图表和图形,从而更直观地理解数据分布和趋势。这对于数据科学家、分析师和决策者来说都是关键的。
- 时间序列分析: Pandas在处理时间序列数据方面表现出色,支持对日期和时间进行高效操作。这对于金融领域、生产领域以及其他需要处理时间序列的行业尤为重要。
- 机器学习和数据建模: 在机器学习中,数据预处理是非常关键的一步,而Pandas提供了强大的功能来处理和准备数据。它可以帮助用户将数据整理成适用于机器学习算法的格式。
- 数据库操作: Pandas可以轻松地与数据库进行交互,从数据库中导入数据到DataFrame中,进行分析和处理,然后将结果导回数据库。这在数据库管理和分析中非常有用。
- 实时数据分析: 对于需要实时监控和分析数据的应用,Pandas的高效性能使其成为一个强大的工具。结合其他实时数据处理工具,可以构建实时分析系统。
Pandas 在许多领域中都是一种强大而灵活的工具,为数据科学家、分析师和工程师提供了处理和分析数据的便捷方式。
1.2 Pandas数据结构
- Series 是一种类似于一维数组的对象,它由一组数据(各种 Numpy 数据类型)以及一组与之相关的数据标签(即索引)组成。
- DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
- Pandas 官网 https://pandas.pydata.org/
- Pandas 源代码:https://github.com/pandas-dev/pandas
2. Pandas安装
- 安装 pandas 需要基础环境是 Python,Pandas 是一个基于 Python 的库,因此你需要先安装 Python,然后再通过 Python 的包管理工具 pip 安装 Pandas。使用 pip 安装 pandas:
pip install pandas
-
查看pandas版本
import pandas as pd pd.__version__ '1.4.4'
3. Pandas Series介绍
-
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
-
Series 特点:
-
索引: 每个
Series都有一个索引,它可以是整数、字符串、日期等类型。如果没有显式指定索引,Pandas 会自动创建一个默认的整数索引。 -
数据类型:
Series可以容纳不同数据类型的元素,包括整数、浮点数、字符串等。 -
Series 是 Pandas 中的一种基本数据结构,类似于一维数组或列表,但具有标签(索引),使得数据在处理和分析时更具灵活性。
-
3.1 构造方法
- 创建Series:pd.Series() 构造函数创建一个 Series 对象,传递一个数据数组(可以是列表、NumPy 数组等)和一个可选的索引数组。
pandas.Series( data, index, dtype, name, copy)
? 参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
示例:
a=[1,2,3]
mySeries=pd.Series(a)
print(mySeries)

- 从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
print(mySeries[1])
2
- 我们可以指定索引值,如下实例:
a=["numpy","pandas","matplotlib"]
mySeries=pd.Series(a,index=["x","y","z"])
print(mySeries)
x numpy
y pandas
z matplotlib
dtype: object
print(mySeries["y"])
pandas
- 我们也可以使用 key/value 对象,类似字典来创建 Series:
sites={1:"numpy",2:"pandas",3:"matplotlib"}
mySeries=pd.Series(sites)
print(mySeries)
1 numpy
2 pandas
3 matplotlib
dtype: object
- 从上图可知,字典的 key 变成了索引值。
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
sites={1:"numpy",2:"pandas",3:"matplotlib"}
mySeries=pd.Series(sites,index=[1,2])
print(mySeries)
1 numpy
2 pandas
dtype: object
- 设置 Series 名称参数:
sites={1:"numpy",2:"pandas",3:"matplotlib"}
mySeries=pd.Series(sites,index=[1,2],name="python-Series")
print(mySeries)
1 numpy
2 pandas
Name: python-Series, dtype: object
3.2 获取属性值
- Series 获取值的相关操作
sites={1:"numpy",2:"pandas",3:"matplotlib",4:"pyechart"}
mySeries=pd.Series(sites,name="python-Series")
print(mySeries)
print('---------1---------')
#获取值
value=mySeries[2]
print(value)
print('---------2---------')
#获取多个值 左开右闭
subset=mySeries[1:3]
print(subset)
print('---------3---------')
#使用自定义索引
a=["numpy","pandas","matplotlib"]
mySeries_with_index=pd.Series(a,index=["x","y","z"])
print(mySeries_with_index["x"])
print('---------4---------')
#打印索引和值的对应关系 items获取Series的键和值
for index, value in mySeries_with_index.items():
print(f"Index:{index},Value:{value}")
1 numpy
2 pandas
3 matplotlib
4 pyechart
Name: python-Series, dtype: object
---------1---------
pandas
---------2---------
2 pandas
3 matplotlib
Name: python-Series, dtype: object
---------3---------
numpy
---------4---------
Index:x,Value:numpy
Index:y,Value:pandas
Index:z,Value:matplotlib
3.3 Series的一些基本运算
#算术运算
# a=[1,2,3,4]
# mySeries=pd.Series(a)
#如果values的值非数字
print(mySeries)
print('---------1---------')
#所有元素乘以2
result=mySeries*2
print(result)
print('---------2---------')
#过滤 首字母比较小于“p”
filter_series=mySeries[mySeries<"p"]
print(filter_series)
print('---------3---------')
1 numpy
2 pandas
3 matplotlib
4 pyechart
Name: python-Series, dtype: object
---------1---------
1 numpynumpy
2 pandaspandas
3 matplotlibmatplotlib
4 pyechartpyechart
Name: python-Series, dtype: object
---------2---------
1 numpy
3 matplotlib
Name: python-Series, dtype: object
---------3---------
#算术运算 如果是数字,可以进行更多相关的运算
a=[1,2,3,4]
mySeries=pd.Series(a)
#如果values的值非数字
print(mySeries)
print('---------1---------')
#所有元素乘以2
result=mySeries*2
print(result)
print('---------2---------')
#过滤 大于2的元素
filter_series=mySeries[mySeries>2]
print(filter_series)
print('---------3---------')
mysqrt = np.sqrt(mySeries) # 对每个元素取平方根
print(mysqrt)
0 1
1 2
2 3
3 4
dtype: int64
---------1---------
0 2
1 4
2 6
3 8
dtype: int64
---------2---------
2 3
3 4
dtype: int64
---------3---------
0 1.000000
1 1.414214
2 1.732051
3 2.000000
dtype: float64
3.4 Series可以获取到相关属性和方法
a=[1,2,3,4]
mySeries=pd.Series(a)
#获取索引
index=mySeries.index
print(index)
print('---------1---------')
#获取值数组
value=mySeries.values
print(value)
print('---------2---------')
#获取描述统计信息 可以获取元素个数均值方差等相关属性值
stats=mySeries.describe()
print(stats)
print('---------3---------')
#获取最大值和最小值的索引
max_index=mySeries.idxmax()
print(f"max_index:{max_index}")
min_index=mySeries.idxmin()
print(f"max_index:{min_index}")
RangeIndex(start=0, stop=4, step=1)
---------1---------
[1 2 3 4]
---------2---------
count 4.000000
mean 2.500000
std 1.290994
min 1.000000
25% 1.750000
50% 2.500000
75% 3.250000
max 4.000000
dtype: float64
---------3---------
max_index:3
max_index:0
注意事项:
Series 中的数据是有序的。
可以将 Series 视为带有索引的一维数组。
索引可以是唯一的,但不是必须的。
数据可以是标量、列表、NumPy 数组等。
4. Pandas DataFrame介绍
-
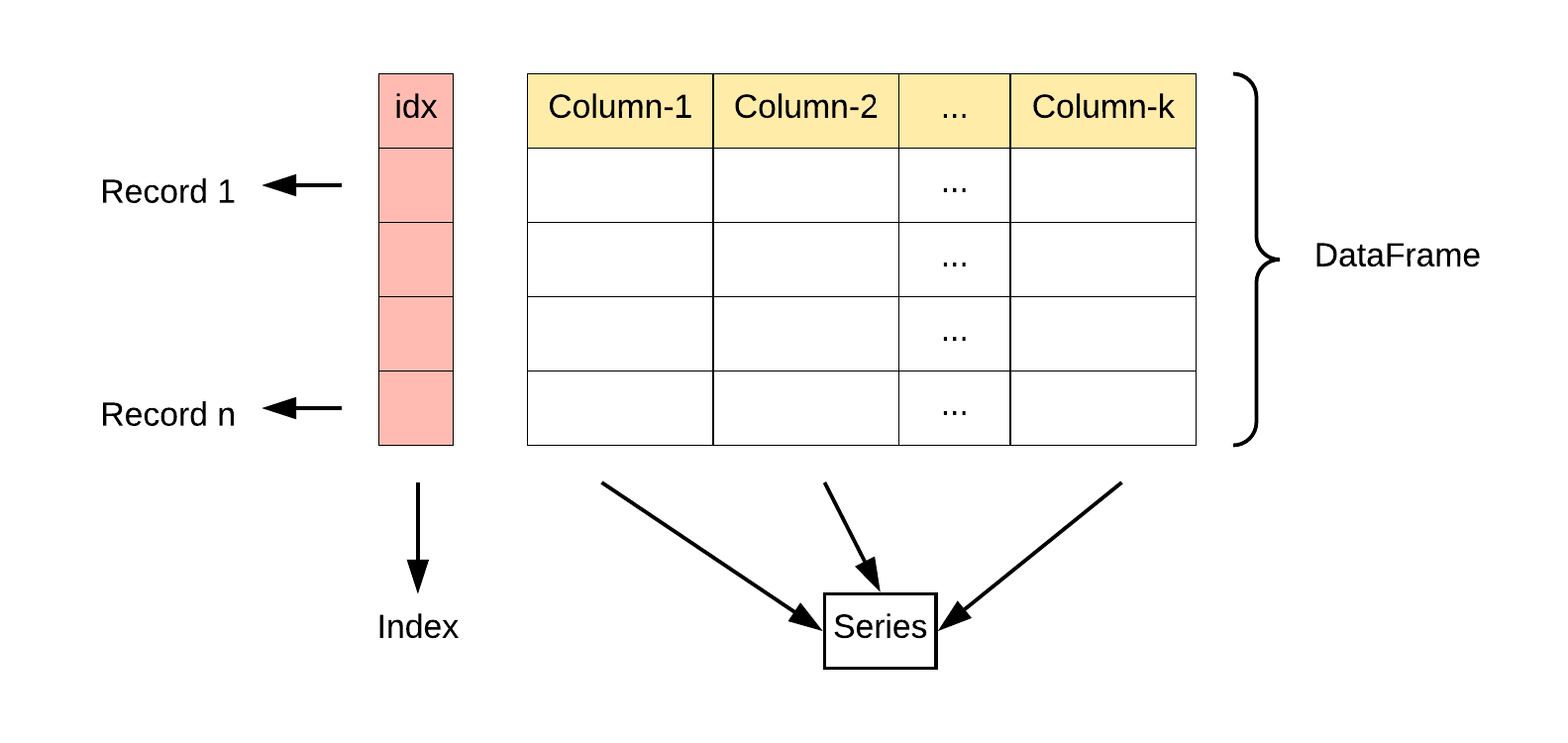
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
-
DataFrame 特点:
-
列和行:
DataFrame由多个列组成,每一列都有一个名称,可以看作是一个Series。同时,DataFrame有一个行索引,用于标识每一行。 -
二维结构:
DataFrame是一个二维表格,具有行和列。可以将其视为多个Series对象组成的字典。 -
列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串等。
-
4.1 构造方法
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
- Pandas DataFrame 是一个二维的数组结构,类似二维数组。
data=[["gcc1",10],["gcc2",12],["gcc3",13]]
myDf=pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(myDf)
Site Age
0 gcc1 10.0
1 gcc2 12.0
2 gcc3 13.0
- 使用 ndarrays 同样可以创建dataframe,ndarray的长度必须相同.
- 如果传递了 index,则索引的长度应等于数组的长度;如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
data2=np.array([4,1,3,2,5,2,4,3,6,3,5,4,7,4,6,5,8,5,7,6]).reshape(5,4)
print('利用ndarrays创建dataframe')
print(pd.DataFrame(data2, index=list('abcde'), columns=['one', 'two', 'three', 'four']))
print('---------1---------')
利用ndarrays创建dataframe
one two three four
a 4 1 3 2
b 5 2 4 3
c 6 3 5 4
d 7 4 6 5
e 8 5 7 6
---------1---------
-
从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):

-
还可以使用字典(key/value),其中字典的 key 为列名:
data3=[{'a':1,'b':2},{'a':3,'b':4,'c':5}]
df=pd.DataFrame(data3)
print(df)
a b c
0 1 2 NaN
1 3 4 5.0
- 没有对应的部分数据为 NaN。
- Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
data4={
"calories":[100,200,300],
"duration":[10,20,30]
}
df=pd.DataFrame(data4)
print(df)
print('---------1---------')
#返回第一行
print(df.loc[0])
#返回第二行
print(df.loc[1])
#返回的对象类型
print(type(df.loc[1]))
calories duration
0 100 10
1 200 20
2 300 30
---------1---------
calories 100
duration 10
Name: 0, dtype: int64
calories 200
duration 20
Name: 1, dtype: int64
<class 'pandas.core.series.Series'>
- 注意:返回结果其实就是一个 Pandas Series 数据。
- 也可以返回多行数据,使用 [[ … ]] 格式,… 为各行的索引,以逗号隔开:
#返回第一行和第二行
print(df.loc[[0,1]])
calories duration
0 100 10
1 200 20
- 注意:返回结果其实就是一个 Pandas DataFrame 数据。
- 我们可以指定索引值,如下实例:
data5={
"calories":[100,200,300],
"duration":[10,20,30]
}
df=pd.DataFrame(data5,index=["day1","day2","day3"])
print(df)
calories duration
day1 100 10
day2 200 20
day3 300 30
- Pandas 可以使用 loc 属性返回指定索引对应到某一行:
print(df.loc["day2"])
calories 200
duration 20
Name: day2, dtype: int64
4.2 DataFrame的一些基本操作
data5={
"calories":[100,200,300],
"duration":[10,20,30]
}
df=pd.DataFrame(data5,index=["day1","day2","day3"])
print(df)
print('---------1---------')
#获取列
name_column=df['calories']
print(name_column)
print('---------2---------')
#获取行
first_row=df.loc['day1']
print(first_row)
print('---------3---------')
#选择多列
subset=df[['calories','duration']]
print(subset)
print('---------4---------')
#过滤行
filter_rows=df[df['duration']>10]
print(filter_rows)
calories duration
day1 100 10
day2 200 20
day3 300 30
---------1---------
day1 100
day2 200
day3 300
Name: calories, dtype: int64
---------2---------
calories 100
duration 10
Name: day1, dtype: int64
---------3---------
calories duration
day1 100 10
day2 200 20
day3 300 30
---------4---------
calories duration
day2 200 20
day3 300 30
4.3 DataFrame获取相关的属性和方法
Pandas 获取相关的属性和方法:
- 获取列名
- 获取行列数
- 获取索引
- 获取描述统计信息
data5={
"calories":[100,200,300],
"duration":[10,20,30]
}
df=pd.DataFrame(data5,index=["day1","day2","day3"])
print(df)
print('---------1---------')
# 获取列名
columns = df.columns
print(columns)
print('---------2---------')
# 获取形状(行数和列数)
shape = df.shape
print(shape)
print('---------3---------')
# 获取索引
index = df.index
print(index)
print('---------4---------')
# 获取描述统计信息
stats = df.describe()
print(stats)
print('---------5---------')
calories duration
day1 100 10
day2 200 20
day3 300 30
---------1---------
Index(['calories', 'duration'], dtype='object')
---------2---------
(3, 2)
---------3---------
Index(['day1', 'day2', 'day3'], dtype='object')
---------4---------
calories duration
count 3.0 3.0
mean 200.0 20.0
std 100.0 10.0
min 100.0 10.0
25% 150.0 15.0
50% 200.0 20.0
75% 250.0 25.0
max 300.0 30.0
---------5---------
Pandas相关的数据操作:
DataFrame中的drop函数用于删除指定行或列。它返回一个新的DataFrame,原始DataFrame保持不变。
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise').
参数说明:
- labels: 要删除的行或列的标签。
- axis: 指定删除的是行还是列,可以是0(行)或1(列)。
- index: 要删除的行的标签,与labels参数相同,只是提供了另一种指定行的方式。
- columns: 要删除的列的标签,与labels参数相同,只是提供了另一种指定列的方式。
- level: 当DataFrame具有多层索引时,指定删除的级别。
- inplace: 如果为True,则直接在原始DataFrame上进行修改,而不返回新的DataFrame。
- errors: 如果指定的标签不存在,确定是否引发错误。默认为’raise’,表示引发错误;可以设置为’ignore’,表示忽略。 、
DataFrame中的sort_values函数用于按照指定的列或多列的值对数据进行排序。它返回一个新的DataFrame,原始DataFrame保持不变。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
参数说明:
- by: 指定用于排序的列或列的列表。
- axis: 排序的轴,可以是0(按行排序)或1(按列排序)。
- ascending: 排序顺序,为True表示升序,为False表示降序。
- inplace: 如果为True,则直接在原始DataFrame上进行排序,而不返回新的DataFrame。
- kind: 排序算法,可以是’quicksort’、‘mergesort’、‘heapsort’,默认是’quicksort’。
- na_position: 缺失值在排序时的位置,可以是’first’、‘last’,默认是’last’。
- ignore_index: 如果为True,则忽略排序后的索引,重新生成默认的整数索引。
- key: 用于排序的函数。
data6={
"Name":["gcc1","gcc2","gcc3"],
"Age":[20,30,40],
"City":["changsha","shanghai","guangzhou"]
}
df=pd.DataFrame(data6)
print(df)
print('---------1---------')
# 添加新列
df['Salary'] = [50000, 60000, 70000]
print(df)
print('---------2---------')
# 删除列
df.drop('City', axis=1, inplace=True)
print(df)
print('---------3---------')
# 排序
df.sort_values(by='Age', ascending=False, inplace=True)
print(df)
print('---------4---------')
# 重命名列
df.rename(columns={'Name': 'Full Name'}, inplace=True)
print(df)
Name Age City
0 gcc1 20 changsha
1 gcc2 30 shanghai
2 gcc3 40 guangzhou
---------1---------
Name Age City Salary
0 gcc1 20 changsha 50000
1 gcc2 30 shanghai 60000
2 gcc3 40 guangzhou 70000
---------2---------
Name Age Salary
0 gcc1 20 50000
1 gcc2 30 60000
2 gcc3 40 70000
---------3---------
Name Age Salary
2 gcc3 40 70000
1 gcc2 30 60000
0 gcc1 20 50000
---------4---------
Full Name Age Salary
2 gcc3 40 70000
1 gcc2 30 60000
0 gcc1 20 50000
4.3 外部数据源创建
从外部数据源创建 DataFrame:
# 从CSV文件创建 DataFrame
df_csv = pd.read_csv('example.csv')
print(df_csv)
print('---------1---------')
# 从Excel文件创建 DataFrame
df_excel = pd.read_excel('example2.xls')
print(df_excel)
print('---------2---------')
# 从字典列表创建 DataFrame
data_list = [{'Name': 'John', 'Age': 25,'City':'New York'}, {'Name': 'Jane', 'Age': 30,'City':'San Francisco'},{'Name': 'Bob', 'Age': 22,'City':'Chicago'}]
df_from_list = pd.DataFrame(data_list)
print(df_from_list)
print('---------3---------')
Name Age City
0 John 25 New York
1 Jane 30 San Francisco
2 Bob 22 Chicago
---------1---------
Name Age City
0 John 25 New York
1 Jane 30 San Francisco
2 Bob 22 Chicago
---------2---------
Name Age City
0 John 25 New York
1 Jane 30 San Francisco
2 Bob 22 Chicago
---------3---------
注意事项:
- DataFrame 是一种灵活的数据结构,可以容纳不同数据类型的列。
- 列名和行索引可以是字符串、整数等。
- DataFrame 可以通过多种方式进行数据选择、过滤、修改和分析。
- 通过对 DataFrame 的操作,可以进行数据清洗、转换、分析和可视化等工作。
5. Pandas 操作csv文件
- CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
- CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
- Pandas 可以很方便的处理 CSV 文件,以 nba.csv 为例,其下载地址:static.runoob.com/download/nba.csv.txt
5.1 查看csv文件内容
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 … 代替。
df=pd.read_csv('nba.csv')
print(df.to_string())
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0
5 Amir Johnson Boston Celtics 90.0 PF 29.0 6-9 240.0 NaN 12000000.0
6 Jordan Mickey Boston Celtics 55.0 PF 21.0 6-8 235.0 LSU 1170960.0
7 Kelly Olynyk Boston Celtics 41.0 C 25.0 7-0 238.0 Gonzaga 2165160.0
8 Terry Rozier Boston Celtics 12.0 PG 22.0 6-2 190.0 Louisville 1824360.0
9 Marcus Smart Boston Celtics 36.0 PG 22.0 6-4 220.0 Oklahoma State 3431040.0
10 Jared Sullinger Boston Celtics 7.0 C 24.0 6-9 260.0 Ohio State 2569260.0
11 Isaiah Thomas Boston Celtics 4.0 PG 27.0 5-9 185.0 Washington 6912869.0
12 Evan Turner Boston Celtics 11.0 SG 27.0 6-7 220.0 Ohio State 3425510.0
13 James Young Boston Celtics 13.0 SG 20.0 6-6 215.0 Kentucky 1749840.0
14 Tyler Zeller Boston Celtics 44.0 C 26.0 7-0 253.0 North Carolina 2616975.0
15 Bojan Bogdanovic Brooklyn Nets 44.0 SG 27.0 6-8 216.0 NaN 3425510.0
16 Markel Brown Brooklyn Nets 22.0 SG 24.0 6-3 190.0 Oklahoma State 845059.0
17 Wayne Ellington Brooklyn Nets 21.0 SG 28.0 6-4 200.0 North Carolina 1500000.0
18 Rondae Hollis-Jefferson Brooklyn Nets 24.0 SG 21.0 6-7 220.0 Arizona 1335480.0
19 Jarrett Jack Brooklyn Nets 2.0 PG 32.0 6-3 200.0 Georgia Tech 6300000.0
20 Sergey Karasev Brooklyn Nets 10.0 SG 22.0 6-7 208.0 NaN 1599840.0
21 Sean Kilpatrick Brooklyn Nets 6.0 SG 26.0 6-4 219.0 Cincinnati 134215.0
22 Shane Larkin Brooklyn Nets 0.0 PG 23.0 5-11 175.0 Miami (FL) 1500000.0
23 Brook Lopez Brooklyn Nets 11.0 C 28.0 7-0 275.0 Stanford 19689000.0
24 Chris McCullough Brooklyn Nets 1.0 PF 21.0 6-11 200.0 Syracuse 1140240.0
25 Willie Reed Brooklyn Nets 33.0 PF 26.0 6-10 220.0 Saint Louis 947276.0
26 Thomas Robinson Brooklyn Nets 41.0 PF 25.0 6-10 237.0 Kansas 981348.0
27 Henry Sims Brooklyn Nets 14.0 C 26.0 6-10 248.0 Georgetown 947276.0
28 Donald Sloan Brooklyn Nets 15.0 PG 28.0 6-3 205.0 Texas A&M 947276.0
29 Thaddeus Young Brooklyn Nets 30.0 PF 27.0 6-8 221.0 Georgia Tech 11235955.0
30 Arron Afflalo New York Knicks 4.0 SG 30.0 6-5 210.0 UCLA 8000000.0
31 Lou Amundson New York Knicks 17.0 PF 33.0 6-9 220.0 UNLV 1635476.0
32 Thanasis Antetokounmpo New York Knicks 43.0 SF 23.0 6-7 205.0 NaN 30888.0
33 Carmelo Anthony New York Knicks 7.0 SF 32.0 6-8 240.0 Syracuse 22875000.0
34 Jose Calderon New York Knicks 3.0 PG 34.0 6-3 200.0 NaN 7402812.0
35 Cleanthony Early New York Knicks 11.0 SF 25.0 6-8 210.0 Wichita State 845059.0
36 Langston Galloway New York Knicks 2.0 SG 24.0 6-2 200.0 Saint Joseph's 845059.0
37 Jerian Grant New York Knicks 13.0 PG 23.0 6-4 195.0 Notre Dame 1572360.0
38 Robin Lopez New York Knicks 8.0 C 28.0 7-0 255.0 Stanford 12650000.0
39 Kyle O'Quinn New York Knicks 9.0 PF 26.0 6-10 250.0 Norfolk State 3750000.0
40 Kristaps Porzingis New York Knicks 6.0 PF 20.0 7-3 240.0 NaN 4131720.0
41 Kevin Seraphin New York Knicks 1.0 C 26.0 6-10 278.0 NaN 2814000.0
42 Lance Thomas New York Knicks 42.0 SF 28.0 6-8 235.0 Duke 1636842.0
43 Sasha Vujacic New York Knicks 18.0 SG 32.0 6-7 195.0 NaN 947276.0
44 Derrick Williams New York Knicks 23.0 PF 25.0 6-8 240.0 Arizona 4000000.0
45 Tony Wroten New York Knicks 5.0 SG 23.0 6-6 205.0 Washington 167406.0
46 Elton Brand Philadelphia 76ers 42.0 PF 37.0 6-9 254.0 Duke NaN
47 Isaiah Canaan Philadelphia 76ers 0.0 PG 25.0 6-0 201.0 Murray State 947276.0
48 Robert Covington Philadelphia 76ers 33.0 SF 25.0 6-9 215.0 Tennessee State 1000000.0
49 Joel Embiid Philadelphia 76ers 21.0 C 22.0 7-0 250.0 Kansas 4626960.0
50 Jerami Grant Philadelphia 76ers 39.0 SF 22.0 6-8 210.0 Syracuse 845059.0
51 Richaun Holmes Philadelphia 76ers 22.0 PF 22.0 6-10 245.0 Bowling Green 1074169.0
52 Carl Landry Philadelphia 76ers 7.0 PF 32.0 6-9 248.0 Purdue 6500000.0
53 Kendall Marshall Philadelphia 76ers 5.0 PG 24.0 6-4 200.0 North Carolina 2144772.0
54 T.J. McConnell Philadelphia 76ers 12.0 PG 24.0 6-2 200.0 Arizona 525093.0
55 Nerlens Noel Philadelphia 76ers 4.0 PF 22.0 6-11 228.0 Kentucky 3457800.0
56 Jahlil Okafor Philadelphia 76ers 8.0 C 20.0 6-11 275.0 Duke 4582680.0
57 Ish Smith Philadelphia 76ers 1.0 PG 27.0 6-0 175.0 Wake Forest 947276.0
58 Nik Stauskas Philadelphia 76ers 11.0 SG 22.0 6-6 205.0 Michigan 2869440.0
59 Hollis Thompson Philadelphia 76ers 31.0 SG 25.0 6-8 206.0 Georgetown 947276.0
60 Christian Wood Philadelphia 76ers 35.0 PF 20.0 6-11 220.0 UNLV 525093.0
61 Bismack Biyombo Toronto Raptors 8.0 C 23.0 6-9 245.0 NaN 2814000.0
62 Bruno Caboclo Toronto Raptors 20.0 SF 20.0 6-9 205.0 NaN 1524000.0
63 DeMarre Carroll Toronto Raptors 5.0 SF 29.0 6-8 212.0 Missouri 13600000.0
64 DeMar DeRozan Toronto Raptors 10.0 SG 26.0 6-7 220.0 USC 10050000.0
65 James Johnson Toronto Raptors 3.0 PF 29.0 6-9 250.0 Wake Forest 2500000.0
66 Cory Joseph Toronto Raptors 6.0 PG 24.0 6-3 190.0 Texas
print(df)
Name Team Number Position Age Height Weight \
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0
.. ... ... ... ... ... ... ...
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0
457 NaN NaN NaN NaN NaN NaN NaN
College Salary
0 Texas 7730337.0
1 Marquette 6796117.0
2 Boston University NaN
3 Georgia State 1148640.0
4 NaN 5000000.0
.. ... ...
453 Butler 2433333.0
454 NaN 900000.0
455 NaN 2900000.0
456 Kansas 947276.0
457 NaN NaN
[458 rows x 9 columns]
- 我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
nme=['Goole','taobao','baidu']
st=["www.goole.com","www.taobao.com","www.baidu.com"]
ag=[90,80,70]
dict={'name':nme,'site':st,'age':ag}
df=pd.DataFrame(dict)
df.to_csv('site.csv')
-
执行成功后,我们打开 site.csv 文件,显示结果如下:

5.2 数据处理
- head()
- head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
df=pd.read_csv('nba.csv')
print(df.head())
print('---------1---------')
#读取前面十行
print(df.head(10))
Name Team Number Position Age Height Weight \
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0
College Salary
0 Texas 7730337.0
1 Marquette 6796117.0
2 Boston University NaN
3 Georgia State 1148640.0
4 NaN 5000000.0
---------1---------
Name Team Number Position Age Height Weight \
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0
5 Amir Johnson Boston Celtics 90.0 PF 29.0 6-9 240.0
6 Jordan Mickey Boston Celtics 55.0 PF 21.0 6-8 235.0
7 Kelly Olynyk Boston Celtics 41.0 C 25.0 7-0 238.0
8 Terry Rozier Boston Celtics 12.0 PG 22.0 6-2 190.0
9 Marcus Smart Boston Celtics 36.0 PG 22.0 6-4 220.0
College Salary
0 Texas 7730337.0
1 Marquette 6796117.0
2 Boston University NaN
3 Georgia State 1148640.0
4 NaN 5000000.0
5 NaN 12000000.0
6 LSU 1170960.0
7 Gonzaga 2165160.0
8 Louisville 1824360.0
9 Oklahoma State 3431040.0
- tail()
- tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
df = pd.read_csv('nba.csv')
print(df.tail())
print('---------1---------')
print(df.tail(10))
Name Team Number Position Age Height Weight College \
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas
457 NaN NaN NaN NaN NaN NaN NaN NaN
Salary
453 2433333.0
454 900000.0
455 2900000.0
456 947276.0
457 NaN
---------1---------
Name Team Number Position Age Height Weight \
448 Gordon Hayward Utah Jazz 20.0 SF 26.0 6-8 226.0
449 Rodney Hood Utah Jazz 5.0 SG 23.0 6-8 206.0
450 Joe Ingles Utah Jazz 2.0 SF 28.0 6-8 226.0
451 Chris Johnson Utah Jazz 23.0 SF 26.0 6-6 206.0
452 Trey Lyles Utah Jazz 41.0 PF 20.0 6-10 234.0
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0
457 NaN NaN NaN NaN NaN NaN NaN
College Salary
448 Butler 15409570.0
449 Duke 1348440.0
450 NaN 2050000.0
451 Dayton 981348.0
452 Kentucky 2239800.0
453 Butler 2433333.0
454 NaN 900000.0
455 NaN 2900000.0
456 Kansas 947276.0
457 NaN NaN
- info()
- info() 方法返回表格的一些基本信息
df = pd.read_csv('nba.csv')
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 458 entries, 0 to 457 # 行数,458 行,第一行编号为 0
Data columns (total 9 columns) # 列数,9列
# Column Non-Null Count Dtype # 各列的数据类型
--- ------ -------------- -----
0 Name 457 non-null object
1 Team 457 non-null object
2 Number 457 non-null float64
3 Position 457 non-null object
4 Age 457 non-null float64
5 Height 457 non-null object
6 Weight 457 non-null float64
7 College 373 non-null object
8 Salary 446 non-null float64 # non-null,意思为非空的数据
dtypes: float64(4), object(5) # 类型
memory usage: 32.3+ KB
None
non-null 为非空数据,我们可以看到上面的信息中,总共 458 行,College 字段的空值最多。
6. Pandas 操作JSON数据
- JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。
- JSON 比 XML 更小、更快,更易解析,更多 JSON 内容可以参考 JSON 教程。
- Pandas 可以很方便的处理 JSON 数据,本文以 sites.json 为例,下载地址:static.runoob.com/download/sites.json
- to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
6.1 查看json文件数据
df=pd.read_json('sites.json')
print(df.to_string())
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
data =[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
6.2 python字典转为DataFrame
- JSON 对象与 Python 字典具有相同的格式,所以我们可以直接将 Python 字典转化为 DataFrame 数据:
s={
"id":{"row1":"A001","row2":"A002","row3":"A003"},
"name":{"row1":"菜鸟教程","row2":"Google","row3":"淘宝"},
"url":{"row1":"www.runoob.com","row2":"www.google.com","row3":"www.taobao.com"},
"likes":{"row1":61,"row2":124,"row3":45},
}
df=pd.DataFrame(s)
print(df)
id name url likes
row1 A001 菜鸟教程 www.runoob.com 61
row2 A002 Google www.google.com 124
row3 A003 淘宝 www.taobao.com 45
6.3 内嵌JSON数据展开
-
内嵌的 JSON 数据
假设有一组内嵌的 JSON 数据文件 nested_list.json :{ "school_name": "ABC primary school", "class": "Year 1", "students": [ { "id": "A001", "name": "Tom", "math": 60, "physics": 66, "chemistry": 61 }, { "id": "A002", "name": "James", "math": 89, "physics": 76, "chemistry": 51 }, { "id": "A003", "name": "Jenny", "math": 79, "physics": 90, "chemistry": 78 }] }
import pandas as pd
df = pd.read_json('nested_list.json')
print(df)
school_name class \
0 ABC primary school Year 1
1 ABC primary school Year 1
2 ABC primary school Year 1
students
0 {'id': 'A001', 'name': 'Tom', 'math': 60, 'phy...
1 {'id': 'A002', 'name': 'James', 'math': 89, 'p...
2 {'id': 'A003', 'name': 'Jenny', 'math': 79, 'p...
-
可以看到输出的结果中Students没有被完全展开,这时候需要使用json_normalize()将内嵌的JSON展开。
pandas.json_normalize() 函数用于将嵌套的 JSON 数据规范化成扁平的表格形式(表格化)。
这是在处理具有嵌套结构的 JSON 数据时非常有用的功能,因为它允许将 JSON 数据展平到 Pandas DataFrame 中,便于进一步处理和分析。
以下是 json_normalize() 函数的基本语法:
pandas.json_normalize(data, record_path=None, meta=None, sep='_', max_level=None, errors='raise')
参数说明:
data: 包含 JSON 数据的字典或列表。
record_path: 用于提取嵌套记录的路径,指定要规范化的嵌套结构的位置。
meta: 需要包含在结果 DataFrame 中的元数据(非规范化的字段)。
sep: 用于连接嵌套路径的分隔符。
max_level: 指定规范化的最大层级深度。
errors: 如果遇到错误,确定是否引发异常。默认是 ‘raise’。
import json
with open('nested_list.json','r') as f:
data=json.load(f)
#展开数据
df_nested_list=pd.json_normalize(data,record_path=['students'])
print(df_nested_list)
id name math physics chemistry
0 A001 Tom 60 66 61
1 A002 James 89 76 51
2 A003 Jenny 79 90 78
data = json.load(f) 使用 Python JSON 模块载入数据。
json_normalize() 使用了参数 record_path 并设置为 [‘students’] 用于展开内嵌的 JSON 数据 students。
- 显示结果还没有包含 school_name 和 class 元素,如果需要展示出来可以使用 meta 参数来显示这些元数据:
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.load(f)
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path =['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
id name math physics chemistry school_name class
0 A001 Tom 60 66 61 ABC primary school Year 1
1 A002 James 89 76 51 ABC primary school Year 1
2 A003 Jenny 79 90 78 ABC primary school Year 1
-
尝试读取更复杂的 JSON 数据,该数据嵌套了列表和字典,数据文件 nested_mix.json 如下:
* { "school_name": "local primary school", "class": "Year 1", "info": { "president": "John Kasich", "address": "ABC road, London, UK", "contacts": { "email": "admin@e.com", "tel": "123456789" } }, "students": [ { "id": "A001", "name": "Tom", "math": 60, "physics": 66, "chemistry": 61 }, { "id": "A002", "name": "James", "math": 89, "physics": 76, "chemistry": 51 }, { "id": "A003", "name": "Jenny", "math": 79, "physics": 90, "chemistry": 78 }] } -
nested_mix.json 文件转换为 DataFrame:
# 使用 Python JSON 模块载入数据
with open('nested_mix.json','r') as f:
data = json.load(f)
df = pd.json_normalize(
data,
record_path =['students'],
meta=[
'class',
['info', 'president'],
['info', 'address'],
['info', 'contacts', 'tel'],
['info', 'contacts', 'email'],
]
)
print(df)
id name math physics chemistry class info.president \
0 A001 Tom 60 66 61 Year 1 John Kasich
1 A002 James 89 76 51 Year 1 John Kasich
2 A003 Jenny 79 90 78 Year 1 John Kasich
info.address info.contacts.tel info.contacts.email
0 ABC road, London, UK 123456789 admin@e.com
1 ABC road, London, UK 123456789 admin@e.com
2 ABC road, London, UK 123456789 admin@e.com
- 读取内嵌数据中的一组数据
6.4 读取内嵌的部分数据
-
以下是实例文件 nested_deep.json,我们只读取内嵌中的 math 字段:
* { "school_name": "local primary school", "class": "Year 1", "students": [ { "id": "A001", "name": "Tom", "grade": { "math": 60, "physics": 66, "chemistry": 61 } }, { "id": "A002", "name": "James", "grade": { "math": 89, "physics": 76, "chemistry": 51 } }, { "id": "A003", "name": "Jenny", "grade": { "math": 79, "physics": 90, "chemistry": 78 } }] } -
这里我们需要使用到 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性
pip install glom
Collecting glom
Downloading glom-23.5.0-py3-none-any.whl (102 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m102.7/102.7 kB[0m [31m352.2 kB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: attrs in /Users/gcc/opt/anaconda3/lib/python3.9/site-packages (from glom) (21.4.0)
Collecting face==20.1.1
Downloading face-20.1.1-py3-none-any.whl (51 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m51.1/51.1 kB[0m [31m1.2 MB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: boltons>=19.3.0 in /Users/gcc/opt/anaconda3/lib/python3.9/site-packages (from glom) (23.0.0)
Installing collected packages: face, glom
Successfully installed face-20.1.1 glom-23.5.0
Note: you may need to restart the kernel to use updated packages.
df[‘students’].apply(lambda row: glom(row, ‘grade.math’)):对 DataFrame 中的 ‘students’ 列执行操作。
对于 ‘students’ 列中的每一行,使用 glom 函数提取嵌套的 ‘grade.math’ 数据。
这一步中,使用了 apply 方法,对于 ‘students’ 列中的每一行,将其作为参数传递给 lambda 函数,该函数使用 glom 提取 ‘grade.math’。
from glom import glom
df=pd.read_json('nested_deep.json')
data=df['students'].apply(lambda row: glom(row,'grade.math'))
print(data)
0 60
1 89
2 79
Name: students, dtype: int64
7.Pandas数据清洗
-
数据清洗是对一些没有用的数据进行处理的过程。
-
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。
-
在这个教程中,我们将利用 Pandas包来进行数据清洗。
-
本文使用到的测试数据 property-data.csv 下载地址:https://static.runoob.com/download/property-data.csv,如下所示:

-
表包含了四种空数据:
空值 n/a NA – na
7.2 Pandas 清洗空值
- 如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。
thresh:设置需要多少非空值的数据才可以保留下来的。
subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
df=pd.read_csv('property-data.csv')
print(df)
print('-------1------')
print(df['NUM_BEDROOMS'].isnull())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
0 False
1 False
2 True
3 False
4 False
5 True
6 False
7 False
8 False
Name: NUM_BEDROOMS, dtype: bool
- 以上例子中我们看到 Pandas 把 n/a 和 NA 当作空数据,na 不是空数据,不符合我们要求,我们可以指定空数据类型:
missing_values=["n/a","na","--"]
df=pd.read_csv('property-data.csv',na_values=missing_values)
print(df['NUM_BEDROOMS'])
print('-------1------')
print(df['NUM_BEDROOMS'].isnull())
0 3.0
1 3.0
2 NaN
3 1.0
4 3.0
5 NaN
6 2.0
7 1.0
8 NaN
Name: NUM_BEDROOMS, dtype: float64
-------1------
0 False
1 False
2 True
3 False
4 False
5 True
6 False
7 False
8 True
Name: NUM_BEDROOMS, dtype: bool
- 利用上述方法删除空数据的行
#如果不指定空数据类型
df = pd.read_csv('property-data.csv')
new_df = df.dropna()
print(new_df.to_string())
print('-------1------')
#如果指定空数据类型
missing_values=["n/a","na","--"]
df=pd.read_csv('property-data.csv',na_values=missing_values)
new_df=df.dropna()
print(new_df.to_string())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3.0 1 1000.0
- 注意:默认情况下,dropna() 方法返回一个新的 DataFrame,不会修改源数据。
- 如果你要修改源数据 DataFrame, 可以使用 inplace = True 参数:
df = pd.read_csv('property-data.csv')
df.dropna(inplace = True)
print(df.to_string())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
8 100009000.0 215.0 TREMONT Y na 2 1800
- 同时也可以移除指定列有空值的行:如移除 ST_NUM 列中字段值为空的行:
df = pd.read_csv('property-data.csv')
print(df.to_string())
print('-------1------')
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
7.3 Pandas替换空值
-
fillna() 方法可以替换一些空字段:
- pandas 的 fillna 函数用于替换 DataFrame 或 Series 中的缺失值(NaN)。缺失值是在数据中表示缺失或未知值的标记。
以下是 fillna 函数的基本语法:
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
主要参数:
value: 用于替换缺失值的标量值、字典、Series 或 DataFrame。
method: 用于指定填充缺失值的方法,例如 ‘ffill’(前向填充)或 ‘bfill’(后向填充)。
axis: 指定在哪个方向上填充,可以是 0(按列填充)或 1(按行填充)。
inplace: 如果为 True,则在原始对象上进行操作,不返回新的对象。
limit: 控制填充的次数,例如,如果设置为 1,则每列或每行中的第一个缺失值将被替换。
downcast: 指定数据类型转换,例如 ‘integer’、‘signed’、‘unsigned’、‘float’ 等。
- pandas 的 fillna 函数用于替换 DataFrame 或 Series 中的缺失值(NaN)。缺失值是在数据中表示缺失或未知值的标记。
df = pd.read_csv('property-data.csv')
print(df.to_string())
print('-------1------')
df.fillna(10000000, inplace = True)
print(df.to_string())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 10000000.0 LEXINGTON N 10000000 1 850
3 100004000.0 201.0 BERKELEY 12 1 10000000 700
4 10000000.0 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y 10000000 1 800
6 100007000.0 10000000.0 WASHINGTON 10000000 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 10000000
8 100009000.0 215.0 TREMONT Y na 2 1800
- 也可以指定某一个列来替换数据:
import pandas as pd
df = pd.read_csv('property-data.csv')
print(df.to_string())
print('-------1------')
df['PID'].fillna(2e9, inplace = True)
print(df.to_string())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 1.000010e+08 104.0 PUTNAM Y 3 1 1000
1 1.000020e+08 197.0 LEXINGTON N 3 1.5 --
2 1.000030e+08 NaN LEXINGTON N NaN 1 850
3 1.000040e+08 201.0 BERKELEY 12 1 NaN 700
4 2.000000e+09 203.0 BERKELEY Y 3 2 1600
5 1.000060e+08 207.0 BERKELEY Y NaN 1 800
6 1.000070e+08 NaN WASHINGTON NaN 2 HURLEY 950
7 1.000080e+08 213.0 TREMONT Y 1 1 NaN
8 1.000090e+08 215.0 TREMONT Y na 2 1800
-
替换空单元格的常用方法是计算列的均值、中位数值或众数。
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
-
mean() 函数
mean() 函数用于计算均值,即数据的平均值。对于 DataFrame,它默认按列计算均值,也可以通过指定 axis 参数来按行计算。
也可以计算某一列的均值。 -
median() 函数
median() 函数用于计算中位数,即数据的中间值。对于 DataFrame,它默认按列计算中位数,也可以通过指定 axis 参数来按行计算。
也可以计算某一列的中位数。 -
mode() 函数
mode() 函数用于计算众数,即数据中出现频率最高的值。对于 DataFrame,它默认按列计算众数,也可以通过指定 axis 参数来按行计算。
也可以计算某一列的众数。
这些函数提供了对数据分布中心趋势的不同度量。在数据分析中,通常会使用这些函数来了解数据的集中趋势,并更好地理解数据的分布。
-
-
使用 mean() 方法计算列的均值并替换空单元格:
注意:在 Pandas 中,计算列的均值时,如果某个元素是 NaN(缺失值),mean() 函数会自动忽略 NaN,并计算非缺失值的均值。
如果希望在计算均值时将 NaN 视为零,可以使用 fillna 函数将 NaN 替换为零,然后再计算均值:
import pandas as pd
df = pd.read_csv('property-data.csv')
print(df.to_string())
print('-------1------')
x = df["ST_NUM"].mean()
print("means:",x)
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
means: 191.42857142857142
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.000000 PUTNAM Y 3 1 1000
1 100002000.0 197.000000 LEXINGTON N 3 1.5 --
2 100003000.0 191.428571 LEXINGTON N NaN 1 850
3 100004000.0 201.000000 BERKELEY 12 1 NaN 700
4 NaN 203.000000 BERKELEY Y 3 2 1600
5 100006000.0 207.000000 BERKELEY Y NaN 1 800
6 100007000.0 191.428571 WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.000000 TREMONT Y 1 1 NaN
8 100009000.0 215.000000 TREMONT Y na 2 1800
- 使用 median() 方法计算列的中位数并替换空单元格:
df = pd.read_csv('property-data.csv')
print(df.to_string())
print('-------1------')
x = df["ST_NUM"].median()
print("median:",x)
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
median: 203.0
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 203.0 LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 203.0 WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
- 使用 mode() 方法计算列的众数并替换空单元格:
df = pd.read_csv('property-data.csv')
print(df.to_string())
print('-------1------')
x = df["ST_NUM"].mode()
print("mode:",x)
print('-------2------')
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
mode: 0 104.0
1 197.0
2 201.0
3 203.0
4 207.0
5 213.0
6 215.0
Name: ST_NUM, dtype: float64
-------2------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 201.0 LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 215.0 WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
7.4 Pandas 清洗格式错误数据
数据格式错误的单元格会使数据分析变得困难,甚至不可能。
我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
以下实例会格式化日期:
import pandas as pd
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df.to_string())
print('-------1------')
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
Date duration
day1 2020/12/01 50
day2 2020/12/02 40
day3 20201226 45
-------1------
Date duration
day1 2020-12-01 50
day2 2020-12-02 40
day3 2020-12-26 45
7.5 Pandas 清洗错误数据
-
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除。
以下实例会替换错误年龄的数据:
import pandas as pd
person = {
"name": ['gcc1', 'gcc2' , 'gcc3'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
df.loc[2, 'age'] = 30 # 修改数据
print(df.to_string())
name age
0 gcc1 50
1 gcc2 40
2 gcc3 30
-
也可以设置条件语句,筛选错误年龄的行:
将 age 大于 120 的设置为 120
person = {
"name": ['gcc1', 'gcc2' , 'gcc3'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x,"age"]>120:
df.loc[x,"age"]=120
print(df.to_string())
name age
0 gcc1 50
1 gcc2 40
2 gcc3 120
-
也可以将错误数据的行删除: 将 age 大于 120 的删除;
pandas 中的 drop 函数用于删除指定轴上的指定标签或索引。具体来说,它可以用于删除行或列,取决于 axis 参数的设置。
以下是 drop 函数的基本语法:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
主要参数:
labels: 要删除的行或列的标签。
axis: 删除的方向,可以是 0(行)或 1(列)。
index: 用于删除行的标签,与 labels 参数相同。
columns: 用于删除列的标签,与 labels 参数相同。
level: 在多层索引时,指定删除的级别。
inplace: 如果为 True,则在原始对象上进行操作,不返回新的对象。
errors: 如果指定的标签不存在,确定是否引发错误,默认是 ‘raise’,表示引发错误;可以设置为 ‘ignore’,表示忽略。
person = {
"name": ['gcc1', 'gcc2' , 'gcc3'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x,"age"]>120:
df.drop(x,inplace=True)
print(df.to_string())
name age
0 gcc1 50
1 gcc2 40
7.6 Pandas 清洗重复数据
- 如果我们要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。
duplicated() 函数
duplicated() 函数用于标记 DataFrame 或 Series 中的重复值。它返回一个布尔值的 Series,其中标记了是否重复。默认情况下,第一次出现的值不被视为重复,而后续的相同值被标记为重复。
参数说明
subset: 指定要检查重复值的列,可以是单个列名或多个列名的列表。默认是 None,表示检查整个行。
keep: 控制重复值的标记方式,有三个选项:
‘first’(默认): 保留第一次出现的值,后续相同值标记为重复。
‘last’: 保留最后一次出现的值,先前相同值标记为重复。
‘False’: 所有相同值都标记为重复。drop_duplicates() 函数
drop_duplicates() 函数用于删除 DataFrame 或 Series 中的重复值。默认情况下,保留第一次出现的值,删除后续的相同值。
参数说明
subset: 同样用于指定要检查重复值的列。
keep: 同样用于控制重复值的保留方式。
inplace: 如果为 True,则在原始对象上进行操作,不返回新的对象。
ignore_index: 如果为 True,则在删除重复值后重新索引。也可以通过传递参数来定制这两个函数的行为,例如,指定列名以检查重复值、保留最后一次出现的值等。这两个函数提供了对重复值的检测和删除的灵活性
如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
person = {
"name": ['gcc', 'gcc1', 'gcc1', 'gcc2'],
"age": [23, 40, 40, 23]
}
df = pd.DataFrame(person)
print(df.duplicated())
0 False
1 False
2 True
3 False
dtype: bool
- 删除重复数据,可以直接使用drop_duplicates() 方法。
person = {
"name": ['gcc', 'gcc1', 'gcc1', 'gcc2'],
"age": [23, 40, 40, 23]
}
df = pd.DataFrame(person)
df.drop_duplicates(inplace=True)
print(df)
name age
0 gcc 23
1 gcc1 40
3 gcc2 23
8. Pandas常用函数
8.1 读取数据
| 函数 | 功能 |
|---|---|
| pd.read_csv(filename) | 读取 CSV 文件 |
| pd.read_excel(filename) | 读取 Excel 文件 |
| pd.read_sql(query, connection_object) | 从 SQL 数据库读取数据 |
| pd.read_json(json_string) | 从 JSON 字符串中读取数据 |
| pd.read_html(url) | 从 HTML 页面中读取数据 |
pip install html5lib
Collecting html5lib
Downloading html5lib-1.1-py2.py3-none-any.whl (112 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m112.2/112.2 kB[0m [31m258.7 kB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: six>=1.9 in /Users/gcc/opt/anaconda3/lib/python3.9/site-packages (from html5lib) (1.16.0)
Requirement already satisfied: webencodings in /Users/gcc/opt/anaconda3/lib/python3.9/site-packages (from html5lib) (0.5.1)
Installing collected packages: html5lib
Successfully installed html5lib-1.1
Note: you may need to restart the kernel to use updated packages.
# 从 CSV 文件中读取数据
df = pd.read_csv('example.csv')
print(df.to_string())
print('--------1--------')
# 从 Excel 文件中读取数据
df = pd.read_excel('example2.xls')
print(df.to_string())
print('--------2--------')
# # 从 SQL 数据库中读取数据
# import sqlite3
# conn = sqlite3.connect('database.db')
# df = pd.read_sql('SELECT * FROM table_name', conn)
# 从 JSON 字符串中读取数据
df = pd.read_json('sites.json')
print(df.to_string())
print('--------3--------')
# 从 HTML 页面中读取数据
from bs4 import BeautifulSoup
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 找到包含表格的部分,可能需要根据实际情况修改选择器
table_soup = soup.find('table')
# 使用 pd.read_html 解析表格
# 如果在使用 pd.read_html(url) 时遇到 "No tables found" 错误,可能是因为页面上没有HTML表格或pandas无法正确解析页面的HTML结构。
# pd.read_html 函数的工作原理是查找HTML页面中的表格标签 <table> 并尝试将其解析为DataFrame。
if table_soup:
df = pd.read_html(str(table_soup))
print(df)
else:
print("No tables found.")
Name Age City
0 John 25 New York
1 Jane 30 San Francisco
2 Bob 22 Chicago
--------1--------
Name Age City
0 John 25 New York
1 Jane 30 San Francisco
2 Bob 22 Chicago
--------2--------
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
--------3--------
No tables found.
8.2 查看数据
| 函数 | 功能 |
|---|---|
| df.head(n) | 显示前 n 行数据 |
| df.tail(n) | 显示后 n 行数据 |
| df.info() | 显示数据的信息,包括列名、数据类型、缺失值等 |
| df.describe() | 显示数据的基本统计信息,包括均值、方差、最大值、最小值等 |
| df.shape | 显示数据的行数和列数 |
df=pd.read_csv('nba.csv')
# 显示前五行数据,head(n),默认为5
print(df.head())
print('--------1--------')
# 显示后五行数据
print(df.tail())
print('--------2--------')
# 显示数据信息
print(df.info())
print('--------3--------')
# 显示基本统计信息
print(df.describe())
print('--------4--------')
# 显示数据的行数和列数
print(df.shape)
print('--------5--------')
#转为numpy数据
import pandas as pd
pd.DataFrame({"A": [1, 2], "B": [3, 4]}).to_numpy()
Name Team Number Position Age Height Weight \
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0
College Salary
0 Texas 7730337.0
1 Marquette 6796117.0
2 Boston University NaN
3 Georgia State 1148640.0
4 NaN 5000000.0
--------1--------
Name Team Number Position Age Height Weight College \
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas
457 NaN NaN NaN NaN NaN NaN NaN NaN
Salary
453 2433333.0
454 900000.0
455 2900000.0
456 947276.0
457 NaN
--------2--------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 458 entries, 0 to 457
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 457 non-null object
1 Team 457 non-null object
2 Number 457 non-null float64
3 Position 457 non-null object
4 Age 457 non-null float64
5 Height 457 non-null object
6 Weight 457 non-null float64
7 College 373 non-null object
8 Salary 446 non-null float64
dtypes: float64(4), object(5)
memory usage: 32.3+ KB
None
--------3--------
Number Age Weight Salary
count 457.000000 457.000000 457.000000 4.460000e+02
mean 17.678337 26.938731 221.522976 4.842684e+06
std 15.966090 4.404016 26.368343 5.229238e+06
min 0.000000 19.000000 161.000000 3.088800e+04
25% 5.000000 24.000000 200.000000 1.044792e+06
50% 13.000000 26.000000 220.000000 2.839073e+06
75% 25.000000 30.000000 240.000000 6.500000e+06
max 99.000000 40.000000 307.000000 2.500000e+07
--------4--------
(458, 9)
--------5--------
array([[1, 3],
[2, 4]])
8.3 数据清洗
| 函数 | 功能 |
|---|---|
| df.dropna() | 删除包含缺失值的行或列 |
| df.fillna(value) | 将缺失值替换为指定的值 |
| df.replace(old_value, new_value) | 将指定值替换为新值 |
| df.duplicated() | 检查是否有重复的数据 |
| df.drop_duplicates() | 删除重复的数据 |
DataFrame.replace() 函数是 Pandas 中用于替换数据中的值的功能强大的函数。它可以根据指定的规则替换 DataFrame 或 Series 中的元素。
以下是 replace() 函数的基本语法:
DataFrame.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad')
主要参数:
- to_replace: 要替换的值,可以是单个值、列表、字典、正则表达式等。
- value: 替换为的值,可以是单个值或与 to_replace 对应的列表。
- inplace: 如果为 True,则在原始对象上进行操作,不返回新的对象。
- limit: 控制替换的次数,如果指定了,仅替换前几次出现的值。
- regex: 如果为 True,则 to_replace 中的值将被视为正则表达式。
- method: 当 to_replace 是列表时,可以使用 ‘pad’、‘ffill’ 或 ‘bfill’ 来指定用于替换的方法。
df=pd.read_csv('property-data.csv')
print(df)
print('-------1------')
# 删除包含缺失值的行或列
new_df = df.dropna()
print(new_df.to_string())
print('-------2------')
# 将缺失值替换为指定的值
new_df2=df.fillna(0)
print(new_df2.to_string())
print('-------3------')
# 将指定值替换为新值
new_df3=df.replace('BERKELEY', 'berkeley')
print(new_df3.to_string())
print('-------4------')
# 删除重复的数据,可以针对某一列的重复
new_df4=df.drop_duplicates(subset="ST_NAME")
print(new_df4.to_string())
print('-------4------')
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
8 100009000.0 215.0 TREMONT Y na 2 1800
-------2------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 0.0 LEXINGTON N 0 1 850
3 100004000.0 201.0 BERKELEY 12 1 0 700
4 0.0 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y 0 1 800
6 100007000.0 0.0 WASHINGTON 0 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 0
8 100009000.0 215.0 TREMONT Y na 2 1800
-------3------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 berkeley 12 1 NaN 700
4 NaN 203.0 berkeley Y 3 2 1600
5 100006000.0 207.0 berkeley Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------4------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
-------4------
8.4 数据选择和切片
| 函数 | 功能 |
|---|---|
| df[column_name] | 选择指定的列 |
| df.loc[row_index, column_name] | 通过标签选择数据 |
| df.iloc[row_index, column_index] | 通过位置选择数据 |
| df.filter(items=[column_name1, column_name2]) | 选择指定的列 |
| df.filter(regex=‘regex’) | 选择列名匹配正则表达式的列 |
| df.sample(n) | 随机选择 n 行数据 |
| df.ix[row_index, column_name] | 通过标签或位置选择数据 |
- ix方法在新版本的pandas中被废弃
- DataFrame.sample() 函数是 Pandas 中用于从 DataFrame 中随机抽样的函数。它允许你从数据集中选择指定数量或比例的随机样本。
- 以下是 sample() 函数的基本语法:
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
主要参数:
- n: 要抽样的行数。如果 n 为 None,则必须指定 frac。
- frac: 抽样的行的比例,应在 0 到 1 之间。
- replace: 如果为 True,则允许有放回抽样;如果为 False,则为无放回抽样。
- weights: 用于赋予不同样本不同权重的权重数组或 Series。
- random_state: 控制抽样的随机性的种子。
- axis: 指定抽样的方向,可以是 0(默认,按行抽样)或 1(按列抽样)。
i
df=pd.read_csv('property-data.csv')
print(df)
print('-------1------')
# 选择指定的列
print(df['ST_NUM'])
print('-------2------')
# 通过标签选择数据
print(df.loc[0,'ST_NUM'])
print('-------3------')
# 通过位置选择数据
print(df.iloc[0, 1])
print('-------4------')
# 选择指定的列
print(df.filter(items=['PID', 'ST_NUM']))
print('-------5------')
# 选择列名匹配正则表达式的列
print(df.filter(regex='S'))
print('-------6------')
# 随机选择 n 行数据
print(df.sample(n=5))
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
-------1------
0 104.0
1 197.0
2 NaN
3 201.0
4 203.0
5 207.0
6 NaN
7 213.0
8 215.0
Name: ST_NUM, dtype: float64
-------2------
104.0
-------3------
104.0
-------4------
PID ST_NUM
0 100001000.0 104.0
1 100002000.0 197.0
2 100003000.0 NaN
3 100004000.0 201.0
4 NaN 203.0
5 100006000.0 207.0
6 100007000.0 NaN
7 100008000.0 213.0
8 100009000.0 215.0
-------5------
ST_NUM ST_NAME NUM_BEDROOMS SQ_FT
0 104.0 PUTNAM 3 1000
1 197.0 LEXINGTON 3 --
2 NaN LEXINGTON NaN 850
3 201.0 BERKELEY 1 700
4 203.0 BERKELEY 3 1600
5 207.0 BERKELEY NaN 800
6 NaN WASHINGTON 2 950
7 213.0 TREMONT 1 NaN
8 215.0 TREMONT na 1800
-------6------
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
5 100006000.0 207.0 BERKELEY Y NaN 1 800
2 100003000.0 NaN LEXINGTON N NaN 1 850
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
8 100009000.0 215.0 TREMONT Y na 2 1800
4 NaN 203.0 BERKELEY Y 3 2 1600
8.5 数据排序
| 函数 | 功能 |
|---|---|
| df.sort_values(column_name) | 按照指定列的值排序 |
| df.sort_values([column_name1, column_name2], ascending=[True, False]) | 按照多个列的值排序 |
| df.sort_index() | 按照索引排序 |
data6={
"Name":["gcc1","gcc2","gcc3"],
"Age":[20,20,40],
"City":["changsha","shanghai","guangzhou"]
}
df=pd.DataFrame(data6)
print(df)
print('---------1---------')
# 按照指定列的值排序
new_df1=df.sort_values('Age')
print(new_df1)
print('---------2---------')
# 按照多个列的值排序
new_df2=df.sort_values(['Age', 'City'], ascending=[True, False])
print(new_df2)
print('---------3---------')
# 按照索引排序
new_df3=df.sort_index()
print(new_df3)
Name Age City
0 gcc1 20 changsha
1 gcc2 20 shanghai
2 gcc3 40 guangzhou
---------1---------
Name Age City
0 gcc1 20 changsha
1 gcc2 20 shanghai
2 gcc3 40 guangzhou
---------2---------
Name Age City
1 gcc2 20 shanghai
0 gcc1 20 changsha
2 gcc3 40 guangzhou
---------3---------
Name Age City
0 gcc1 20 changsha
1 gcc2 20 shanghai
2 gcc3 40 guangzhou
8.6 数据分组和聚合
| 函数 | 功能 |
|---|---|
| df.groupby(column_name) | 按照指定列进行分组 |
| df.aggregate(function_name) | 对分组后的数据进行聚合操作 |
| df.pivot_table(values, index, columns, aggfunc) | 生成透视表 |
- groupby 函数
参数说明:
by: 根据哪些列进行分组,可以是单个列名、多个列名的列表、Series 或者函数。
axis: 指定分组的方向,0 表示按行分组,1 表示按列分组,默认为 0。
level: 如果对象是多层索引,则指定要使用的级别进行分组,默认为 None。
as_index: 如果为 True,分组键将成为结果 DataFrame 的索引,默认为 True。
sort: 对分组键进行排序,默认为 True。
group_keys: 如果为 True,则在结果中添加分组键的标签,默认为 True。
- aggregate 函数
参数说明:
func: 聚合函数或函数列表,用于计算每列的统计量。
axis: 指定聚合的方向,0 表示按行聚合,1 表示按列聚合,默认为 0。
***args, kwargs: 传递给聚合函数的其他参数。
- pivot_table 函数
参数说明:
values: 需要聚合的列名。
index: 用于透视表的行索引。
columns: 用于透视表的列索引。
aggfunc: 用于聚合的函数或函数列表,默认为 ‘mean’。
fill_value: 用于填充缺失值的值。
margins: 添加行/列总计,默认为 False。
margins_name: 指定总计的标签,默认为 ‘All’。在 Pandas 中,透视表(通过 pivot_table 函数创建)与 Excel 中的透视表类似,具有以下主要作用:
汇总数据: 透视表可以根据一个或多个维度对数据进行汇总,提供了一种聚合数据的方式。这有助于生成更紧凑、易于理解的数据摘要,而不必查看整个原始数据集。
多维度分析: 透视表允许你同时在多个维度上对数据进行分析。通过定义行索引、列索引和聚合函数,可以在同一表格中查看数据的不同切片,使得多维度的数据分析更为直观。
灵活的数据呈现: 透视表使得数据以表格的形式更直观地呈现出来,易于阅读和理解。它提供了一种动态、交互式的方式来查看数据,而不必每次都编写复杂的代码。
统计计算: 透视表支持在不同维度上进行统计计算,如平均值、总和、计数等。这使得你可以轻松获取各维度上的统计信息,有助于发现数据的模式和趋势。
处理缺失值: 透视表提供了处理缺失值的选项,可以选择使用特定的值填充缺失值,也可以通过插值等方式进行填充。
可视化支持: 透视表的结果可以直接用于可视化,例如绘制图表。通过可视化,你可以更生动地展示数据,更容易向他人传达你的分析结果。
更复杂的分析: 透视表是进行更复杂的数据分析的基础。通过透视表,你可以探索数据中的关联性、趋势和异常值,进而支持更深入的分析
# 创建一个示例 DataFrame
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Value': [10, 15, 20, 25, 30, 35]}
df = pd.DataFrame(data)
# 按 'Category' 列分组,并计算每个组的平均值
grouped_df = df.groupby('Category').mean()
print(grouped_df)
Value
Category
A 20.0
B 25.0
# 创建一个示例 DataFrame
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Value': [10, 15, 20, 25, 30, 35]}
df = pd.DataFrame(data)
# 按 'Category' 列分组,并计算每个组的平均值和总和
agg_df = df.groupby('Category').aggregate({'Value': ['mean', 'sum']})
print(agg_df)
Value
mean sum
Category
A 20.0 60
B 25.0 75
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Value': [10, 15, 20, 25, 30, 35]}
df = pd.DataFrame(data)
#创建透视表,按'Category'分组并且计算每个组的平均值
pivot_table_df=df.pivot_table(values='Value',index='Category',aggfunc='mean')
print(pivot_table_df)
Value
Category
A 20
B 25
8.7 数据合并
| 函数 | 作用 |
|---|---|
| pd.concat([df1, df2]) | 将多个数据框按照行或列进行合并 |
| pd.merge(df1, df2, on=column_name) | 按照指定列将两个数据框进行合并 |
pandas 中的 concat 和 merge 函数都用于合并数据,但它们的用法和目的略有不同。
- concat 函数
作用: concat 用于沿着特定轴将多个数据结构进行连接,可以按行或按列进行连接。
参数说明:
objs: 要连接的对象,可以是 Series、DataFrame 或者这些对象的列表。
axis: 指定连接的轴,0 表示按行连接,1 表示按列连接。
join: 指定连接的方式,可以是 ‘outer’(默认)、‘inner’ 或 ‘ignore’。
keys: 用于创建层次化索引的标签,可以是单个标签或标签列表。
ignore_index: 如果为 True,则忽略原始索引,创建一个新的整数索引。
- merge 函数
作用: merge 用于根据一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN 操作。
参数说明:
left: 左侧的 DataFrame。
right: 右侧的 DataFrame。
on: 指定连接的键,可以是单个键名或多个键名的列表。
how: 指定连接的方式,可以是 ‘left’(左连接)、‘right’(右连接)、‘outer’(外连接,默认)、‘inner’(内连接)。
left_on, right_on: 分别指定左侧和右侧的连接键,用于处理键名不同的情况。
left_index, right_index: 如果为 True,则使用索引作为连接键。这两个函数都是在数据处理中常用的工具,concat 主要用于在行或列方向上进行简单的连接,而 merge 更适用于基于键进行连接的情况。选择使用哪个函数取决于具体的合并需求
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
print("DataFrame 1:")
print(df1)
print('---------1---------')
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
print("\nDataFrame 2:")
print(df2)
print('---------2---------')
# 沿着行方向连接两个 DataFrame
result_row = pd.concat([df1, df2], axis=0, ignore_index=True)
print("\nConcatenated by rows:")
print(result_row)
print('---------3---------')
# 沿着列方向连接两个 DataFrame
result_col = pd.concat([df1, df2], axis=1)
print("\nConcatenated by columns:")
print(result_col)
DataFrame 1:
A B
0 1 3
1 2 4
---------1---------
DataFrame 2:
A B
0 5 7
1 6 8
---------2---------
Concatenated by rows:
A B
0 1 3
1 2 4
2 5 7
3 6 8
---------3---------
Concatenated by columns:
A B A B
0 1 3 5 7
1 2 4 6 8
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value': [1, 2, 3]})
print("DataFrame 1:")
print(df1)
print('---------1---------')
df2 = pd.DataFrame({'key': ['A', 'B', 'D'], 'value': [4, 5, 6]})
print("\nDataFrame 2:")
print(df2)
print('---------2---------')
# 根据 'key' 列进行内连接
result_inner = pd.merge(df1, df2, on='key', how='inner')
print("\nInner Merge:")
print(result_inner)
print('---------3---------')
# 根据 'key' 列进行左连接
result_left = pd.merge(df1, df2, on='key', how='left')
print("\nLeft Merge:")
print(result_left)
DataFrame 1:
key value
0 A 1
1 B 2
2 C 3
---------1---------
DataFrame 2:
key value
0 A 4
1 B 5
2 D 6
---------2---------
Inner Merge:
key value_x value_y
0 A 1 4
1 B 2 5
---------3---------
Left Merge:
key value_x value_y
0 A 1 4.0
1 B 2 5.0
2 C 3 NaN
8.8 数据选择和过滤
df.query() 函数是 Pandas 中用于在 DataFrame 中进行查询的函数。它允许你使用一种类似 SQL 的语法来选择符合特定条件的行。
作用: 对 DataFrame 进行条件查询,筛选出满足特定条件的行。
df.query(expr, inplace=False, **kwargs)
参数说明:
- expr: 查询表达式,可以是一个字符串,表示要应用于 DataFrame 的查询条件。
- inplace: 如果为 True,则在原始 DataFrame 上进行就地修改,而不是返回一个新的 DataFrame。默认为 False。
- kwargs: 其他关键字参数,可以包含在查询表达式中使用的变量。
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': ['X', 'Y', 'Z', 'X', 'Y']}
df = pd.DataFrame(data)
print("Original DataFrame:")
print(df)
print('---------1---------')
# 使用 query 函数筛选出符合条件的行
result = df.query('B > 30')
print("\nFiltered DataFrame:")
print(result)
print('---------2---------')
#选择列中满足条件的行
print(df[df['B']>30])
Original DataFrame:
A B C
0 1 10 X
1 2 20 Y
2 3 30 Z
3 4 40 X
4 5 50 Y
---------1---------
Filtered DataFrame:
A B C
3 4 40 X
4 5 50 Y
---------2---------
A B C
3 4 40 X
4 5 50 Y
8.9 数据统计和描述
| 函数 | 功能 |
|---|---|
| df.describe() | 计算基本统计信息,如均值、标准差、最小值、最大值等。 |
| df.mean() | 计算每列的平均值。 |
| df.median() | 计算每列的中位数。 |
| df.mode() | 计算每列的众数。 |
| df.count() | 计算每列非缺失值的数量。 |
df.count() 函数是 Pandas 中的一个用于计算非空元素数量的函数。它返回每列中非空元素的数量,并以 Series 的形式返回结果。
作用: 统计每列中的非空元素数量。
语法:
df.count(axis=0, level=None, numeric_only=False)
参数说明:
axis: 指定计算的方向,0 表示按列计算,1 表示按行计算。默认为 0。
level: 如果 DataFrame 具有层次化索引,则可以指定在哪个层次上进行计算。默认为 None。
numeric_only: 如果为 True,则只计算数值类型的列。默认为 False。
import numpy as np
# 创建一个示例 DataFrame
data = {'A': [1, 2, np.nan, 4, 5],
'B': [10, 20, 30, np.nan, 50],
'C': ['X', 'Y', 'Z', 'X', 'Y']}
df = pd.DataFrame(data)
# 使用 count 函数统计每列中的非空元素数量
count_result = df.count()
print("Original DataFrame:")
print(df)
print("\nCount of non-null elements in each column:")
print(count_result)
Original DataFrame:
A B C
0 1.0 10.0 X
1 2.0 20.0 Y
2 NaN 30.0 Z
3 4.0 NaN X
4 5.0 50.0 Y
Count of non-null elements in each column:
A 4
B 4
C 5
dtype: int64
9.可视化
-
DataFrame 的plot方法可以快速绘制所有带标签的列,如以下例子:
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000)) ts = ts.cumsum() ts.plot()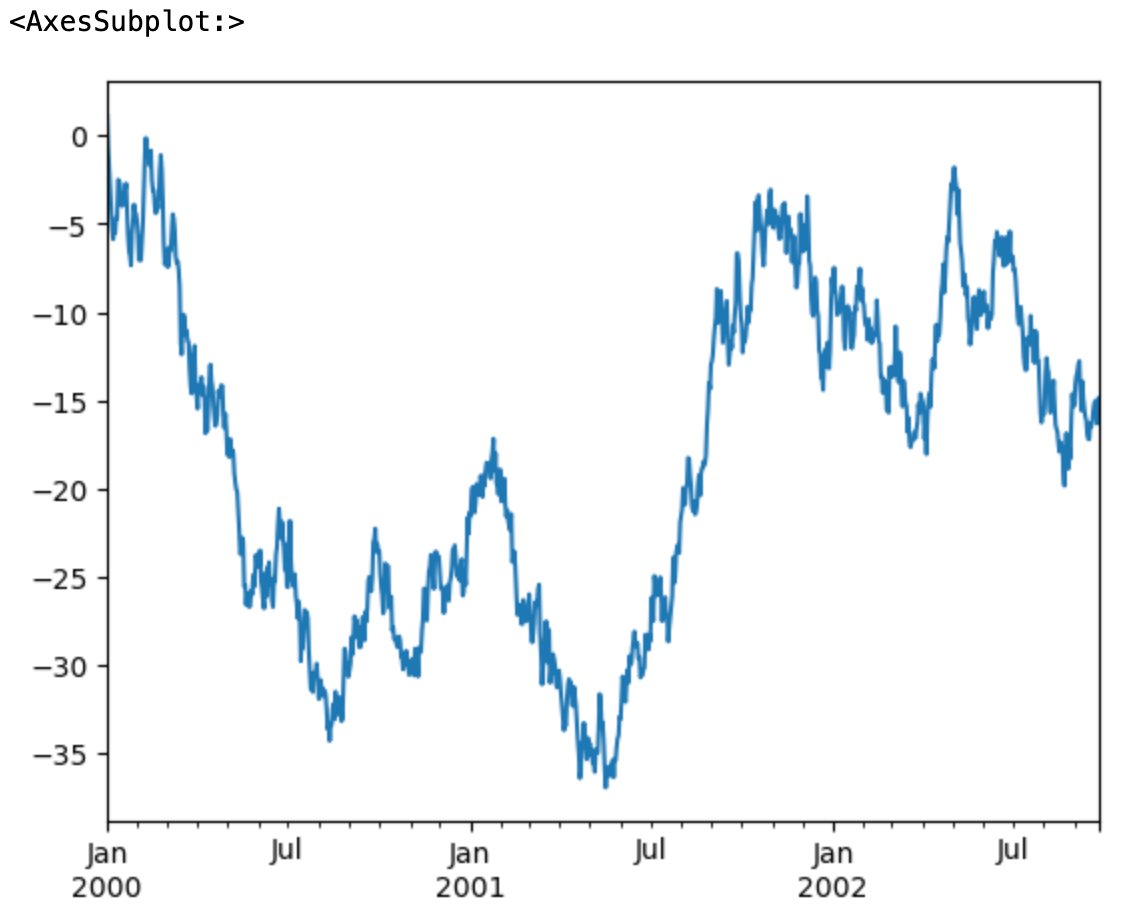
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index,columns=['A', 'B', 'C', 'D'])
df = df.cumsum()
plt.figure()
df.plot()
本文主要参考:Pandas 教程 | 菜鸟教程 (runoob.com)
更多详细参考资料见:Pandas (pypandas.cn)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【CV】使用 matplotlib.pyplot 绘制统计图、坐标系原点在不同的位置和添加辅助点和辅助线
- abp vnext 下载指定版本的项目
- 利用前缀和求解的lc题目汇总
- “MapStruct妙用指南:解锁Java对象映射的强大力量!“ ?
- 实战:使用Spring Boot监控SQL执行
- 【win】Windows下MSI Afterburner如何让其不在某个软件中显示帧数
- JRT实现原生Webservice发布
- 从机器指令的角度看一些位级操作
- 新手怎么做短视频小说推文?
- CNN-GRU-Attention卷积神经网络-门控循环单元多输入多输出预测,CNN-GRU-Attention回归预测。评价指标包括:R2、MAE、MSE、RMSE等,代码质量极高,方便学习和替