python爬虫--网页代码抓取
我回来了。
前言
爬虫,第一章
一、爬虫是什么?
爬虫是指一种自动化程序,通常被用于互联网上的数据采集。这些程序会模拟人类用户的行为,通过访问网页、抓取数据、分析内容等方式来收集网络上的信息。爬虫通常被用于搜索引擎索引、数据挖掘、信息监控、网站更新等领域。它们可以帮助用户快速获取大量的信息,
二、使用步骤
也就10行。
代码如下(示例):
import requests
from faker import Faker
fake = Faker()
url = "https://www.freebuf.com"
headers = {
"User-Agent": fake.user_agent()
}
response = requests.get(url, headers=headers)
print(response.text)
让我们运行一下

报错了,,让我们看下信息
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='www.freebuf.com', port=443): Max retries exceeded with url: / (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1002)')))
哦,是SSL 证书验证失败导致的,那怎么解决
-
确保Python 版本和相关的库都是最新的,有时候问题可以通过升级解决。
-
在使用 requests.get() 时,可以设置 verify 参数为 False,这样可以跳过 SSL 证书验证。例如:
response = requests.get(url, headers=headers, verify=False) -
更新你的 SSL 证书。有时候问题是由于过期的证书引起的,更新证书可能会解决问题。
-
确保你的网络环境没有被代理或防火墙篡改,有时候这些因素也会导致 SSL 验证失败。
我都懒得弄,我就选择第二个,改好了,运行一下


可能就有人抱怨了,“还要在代码里输入网址”,这个怎么解决,熟悉python的知道应该用input函数。请看第二版
import requests
from faker import Faker
fake = Faker()
url = input("请输入要访问的网站URL:")
headers = {
"User-Agent": fake.user_agent(),
}
response = requests.get(url, headers=headers, verify=False)
print(response.text)
运行一下

怎么又出问题啊,好像是对我进行了一些重定向和cookie设置,可能是为了阻止爬虫或恶意访问,换网站
可能还有人就抱怨了,抓到的代码第二天就没了,然后就就就出现了第三版
import requests
from faker import Faker
import os
fake = Faker()
url = input("请输入要访问的网站URL:")
headers = {
"User-Agent": fake.user_agent(),
}
response = requests.get(url, headers=headers, verify=False)
output_text = response.text
# 询问用户是否要将输出结果写入文件
create_file = input("是否要保存输出结果?(y/n):")
if create_file.lower() == "y":
desktop_path = os.path.join(os.path.join(os.environ['USERPROFILE']), 'Desktop')
file_path = os.path.join(desktop_path, 'output.txt')
with open(file_path, 'w',encoding='utf-8') as file:
file.write(output_text)
print(f"输出结果已写入文件 {file_path}")
else:
print(output_text)
ok,运行一下
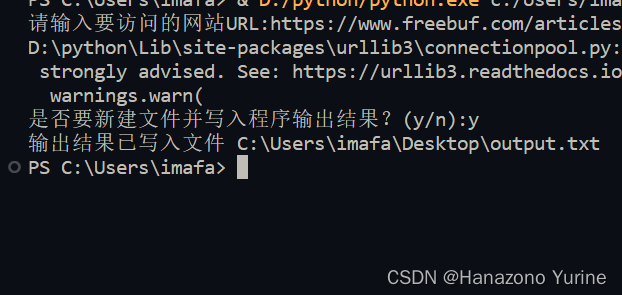
成功了
代码讲解
第一版
import requests
from faker import Faker
fake = Faker()
url = "https://www.freebuf.com"
headers = {
"User-Agent": fake.user_agent()
}
response = requests.get(url, headers=headers)
print(response.text)
requests 库和 faker 库。requests 库用于发送 HTTP 请求,而 faker 库用于生成虚假的数据。
首先,我们导入了 requests 和 Faker 库。然后,我们创建了一个 Faker 实例并初始化了一个 URL 变量,该变量存储了要发送请求的网站 URL。接着,我们创建了一个名为 headers 的字典变量,其中包含了 User-Agent 的值,该值是使用 Faker 生成的一个随机的用户代理信息。最后,我们使用 requests 库发送了一个 GET 请求,并在请求中包含了我们创建的 headers。最终,我们打印出了请求得到的响应文本。
第二版
import requests
from faker import Faker
fake = Faker()
url = input("请输入要访问的网站URL:")
headers = {
"User-Agent": fake.user_agent(),
}
response = requests.get(url, headers=headers, verify=False)
print(response.text)
requests库从用户输入的URL获取网页内容,并使用Faker库生成一个随机的User-Agent。
- 首先,导入了
requests和Faker库。 - 然后,创建了一个
Faker对象,用于生成随机数据。 - 提示用户输入要访问的网站URL,并将输入的URL存储在
url变量中。 - 创建了一个
headers字典,其中包含一个随机的User-Agent。fake.user_agent()会生成一个有效的User-Agent字符串。 - 使用
requests.get()函数发起GET请求,传入URL、headers和verify参数。headers参数传递了之前创建的headers字典,verify参数设置为False表示不验证SSL证书。 - 获取响应内容,并将响应内容存储在
response变量中。 - 使用
print()函数打印响应的文本内容。
第三版
import requests
from faker import Faker
import os
fake = Faker()
url = input("请输入要访问的网站URL:")
headers = {
"User-Agent": fake.user_agent(),
}
response = requests.get(url, headers=headers, verify=False)
output_text = response.text
# 询问用户是否要将输出结果写入文件
create_file = input("是否要保存输出结果?(y/n):")
if create_file.lower() == "y":
desktop_path = os.path.join(os.path.join(os.environ['USERPROFILE']), 'Desktop')
file_path = os.path.join(desktop_path, 'output.txt')
with open(file_path, 'w',encoding='utf-8') as file:
file.write(output_text)
print(f"输出结果已写入文件 {file_path}")
else:
print(output_text)
主要功能是获取用户输入的URL,并从该URL获取网页内容。生成一个随机的User-Agent,并询问用户是否要将输出结果写入文件。
- 首先,导入了
requests、Faker和os库。 - 创建了一个
Faker对象,用于生成随机数据。 - 提示用户输入要访问的网站URL,并将输入的URL存储在
url变量中。 - 创建了一个
headers字典,其中包含一个随机的User-Agent。fake.user_agent()会生成一个有效的User-Agent字符串。 - 使用
requests.get()函数发起GET请求,传入URL、headers和verify参数。headers参数传递了之前创建的headers字典,verify参数设置为False表示不验证SSL证书。 - 获取响应内容,并将响应内容存储在
output_text变量中。 - 使用
input()函数询问用户是否要将输出结果写入文件。用户输入的字符串将被转换为小写。 - 如果用户输入为
y,则使用os.path.join()函数创建一个桌面路径,并将其与output.txt连接在一起,以获得文件的完整路径。然后,使用open()函数以写入模式打开文件,并使用write()函数将输出文本写入文件。最后,使用print()函数打印出文件路径。 - 如果用户输入为
n,则直接打印输出文本。
总结
这是爬虫爬取html代码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【管理】如何正确与员工沟通
- 给多行文本的每行添加指定的前缀textwrap.indent()
- 「Vue3面试系列」Vue3 所采用的 Composition Api 与 Vue2 使用的 Options Api 有什么不同?
- 数据库连接报错Io 异常: The Network Adapter could not establish the connection
- 算法竞赛备赛进阶之数位DP训练
- 别再写一堆的 for 循环了!Java 8 中的 Stream 轻松遍历树形结构,是真的牛逼!
- CLion调试Nodejs源码
- 【离线】牛客小白月赛39 G
- 排序算法8----归并排序(非递归)(C)
- whale-quant 学习 part2:金融市场的基本概念