SparkCore阶段练习
发布时间:2024年01月10日
阶段练习
-
查看数据集格式
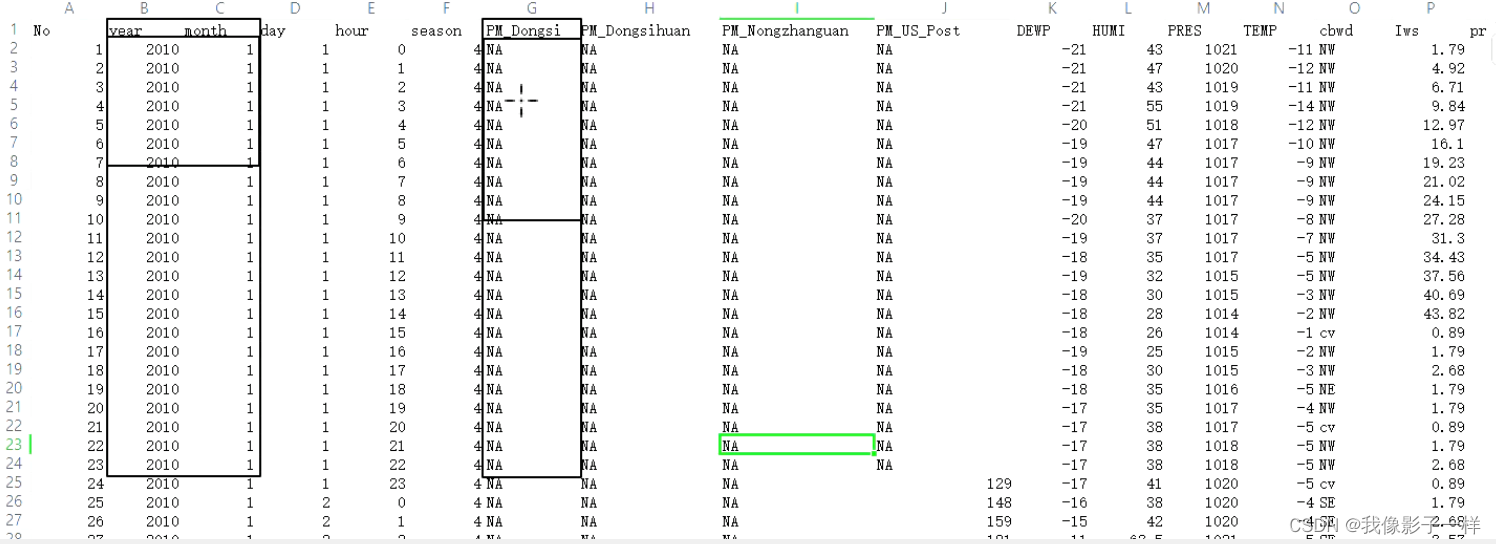
-
明确需求
-
明确步骤
-
读取文件
-
抽取需要的列
-
以年月为基础,进行 reduceByKey 统计Dongsi地区的PM
-
排序
-
获取结果
-
-
编码
-
拷贝数据集
data.rar(已上传资源——SparkCore阶段练习数据集)
-
创建类
-
编写代码
-
运行测试
@Test def pmProcess(): Unit = { ?// 1. 创建sc对象 ?val conf = new SparkConf().setMaster("local[6]").setAppName("stage_practice") ?val sc = new SparkContext(conf) ?// 2. 读取文件 ?val source = sc.textFile("./dataset/BeijingPM20100101_20151231_noheader.csv") ?// 3. 通过算子处理数据 ?// ? 3.1 map切数据 ((年,月),pm) ?source.map(item => ((item.split(",")(1), item.split(",")(2)), item.split(",")(6))) ?// ? 3.2 filter 过滤空 和 NA 数据 ? .filter(item => StringUtils.isNotEmpty(item._2) && !item._2.equalsIgnoreCase("NA")) // equalsIgnoreCase 判断两个字符串是否相等,忽略字符串的大小写, ?// ? 3.3 toInt 数据类型转换 ? .map(item => (item._1, item._2.toInt)) ?// ? 3.4 聚合数据 ? .reduceByKey((curr, agg) => curr + agg) ?// ? 3.5 排序 ? .sortBy(item => item._2, ascending = false) // 降序 ?// 4.获取结果 ? .take(10) ? .foreach(item => println(item)) ?// 5. 关闭sc ?sc.stop() }


-
文章来源:https://blog.csdn.net/m0_56181660/article/details/135467411
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 印章管理详解|契约锁帮助提前预防99%的印章风险
- Prometheus 薪资翻倍的监控系统?
- 八大算法排序@希尔排序(C语言版本)
- fuckingAlgorithm【双指针】19.删除链表的倒数第N个结点
- MIT 6.S081---Lab: page tables
- LabVIEW继电保护测试仪自动检测系统
- 鸿蒙开发之用户隐私权限申请
- docker 使用 vcs/2018 Verdi等 eda 软件
- 2023年山东省职业院校技能大赛高职组 “软件测试”赛项竞赛任务四 单元测试
- Android Bluetooth Framework源码剖析(二)它们都重要