关于LINUX操作系统异常宕机重启的分析思路
一、先搞清楚现状
当收到系统宕机告警或者故障反馈时,需要先对情况进行核实。比如检查系统启动时间,是不是真实发生了重启?如果重启了,什么时间点发生的重启?重启了几次?重启之前有无变更操作?主机上运行的是哪一类应用?重启的主机是物理机还是虚拟机?等等情况,有助于对于故障的分析处理。
可以如下检查:
1、last查看机器最近重启时间,以及重启次数

2、确认重启后,查看主机是物理机还是虚拟机
dmidecode -t 1

3、检查看看是否有人为重启的动作,如果配置了命令审计,可以从message日志中看是否有人敲过reboot命令。或者用history命令也可以看到一些,但有时不一定会有记录下来。
主机命令审计配置和查看可参考这篇文章《LINUX加固之命令审计》
4、检查看看主机上都跑了些啥?例如oracle、mysql、ha、vcs等高可用集群软件相关的 。
二、硬件故障排查
在第一步做了相关检查后,确认是发生重启了,并且还是物理机,可以考虑是否硬件故障导致(硬件类内存、cpu故障频率高)。系统内可以通过ipmitool工具检查如下:
--安装工具
yum?install?OpenIPMI?ipmitool?-y
modprobe?ipmi_watchdog
modprobe?ipmi_poweroff
modprobe?ipmi_devintf
modprobe?ipmi_si
modprobe?ipmi_msghandler
--查看日志
ipmitool?sel?list
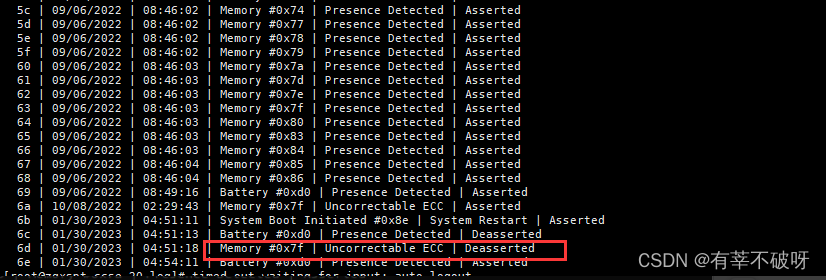
如果看到类似CPU或内存异常日志,同时时间点和机器重启时间对应上,那就是重启原因。
PS:硬件类问题机房值守人员可以现场查看和报修厂家检查,系统内ipmitool工具是个补充手段,方便远程轻松查看。如果ipmitool查看未有明显报错,也未必硬件一定都正常,建议还需要进行报修原厂,再进一步深度检查。
三、系统内dump日志检查
如果硬件类排查没什么问题或者是个虚拟机,可以进行系统内的日志分析,首先应该看看是否有产生dump日志。参考如下:
cd /var/crash目录下,看是否有生成crash日志目录产生,如下图有个127.0.0.1开头的目录

进到目录里就会有vmcore的dump日志,重启的原因就可以从dump日志找到蛛丝马迹。
crash日志分析可参考这篇《LINUX常用工具之kdump》
四、系统日志及性能检查
如果硬件日志和crash日志检查了都还没有收获,接下来要对系统日志及相关性能进行复盘检查,检查分析看看故障重启前,主机负载有没有突增,日志中有无异常类报错。可参照如下:
1、性能检查
这部分大部分系统应该都会接入到监控网管中心,可从监控中心去找下历史指标趋势,重点关注CPU、内存、磁盘IO、网络等指标是否有突增情况。
如果不具备监控中心的,或者故障前相关指标没采集到(监控采集有个时间差,瞬间的问题可能未必会捕捉到);可以从系统sar日志取查找相关信息
cd /var/log/sa,每天的系统监控会写到当天日期的sa文件中,例如11号的性能日志,可以查看sa11或者sar11文件。(注:sar文件可以直接读取,sa文件需要用sar命令加上-f参数指定具体sa文件读取内容)
![]()
关于sa文件的查看可以man 下sar去看看参数,例如
-A:所有报告的总和
-u:输出CPU使用情况的统计信息
-v:输出inode、文件和其他内核表的统计信息
-d:输出每一个块设备的活动信息
-r:输出内存和交换空间的统计信息
-b:显示I/O和传送速率的统计信息
-a:文件读写情况
-c:输出进程统计信息,每秒创建的进程数
-R:输出内存页面的统计信息
-y:终端设备活动情况
-w:输出系统交换活动信息
示例:查看11号当天故障某个时间点cpu情况,就可以用
sar -u -f sa11

?2、日志检查
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一,其他软件日志有时也会打印输出到里面。
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信息
/var/log/cron 与定时任务相关的日志信息
/var/log/spooler 与UUCP和news设备相关的日志信息
/var/log/boot.log 守护进程启动和停止相关的日志消息
/var/log/wtmp 该日志文件永久记录每个用户登录、注销及系统的启动、停机的事件
重点检查/var/log/message、dmesg日志、/var/log/secure等日志查看是否有error、fail、critical等关键报错信息。
五、ha等高可用集群相关软件日志检查
如果以上步骤都排查了一通,还是没找到重启的原因,那么从ha高可用的方向去查查看,如果有部署相关的软件,则去排查这些集群的日志,因为高可用集群通常会有一些驱逐、脑裂、重启节点等异常机制,也会触发机器发生重启。这块遇到了可以反馈让集群专业同事去协助排查,或者你也可以试着自己动手去检查相关日志,从不会到会,就是从每一次动手开始,后面也会去分享一些集群软件故障触发的主机重启案例。
六、其他排查方向及建议
1、如果是虚拟机故障,也建议虚拟化平台层去看看底层服务是否有异常。
2、各类日志不光是检查里面有没有异常内容,还需要关注是否日志在之前有正常输出,比如kdump是否做了配置,配置是否生效,如果不生效crash日志不会生成。其他日志也是一样。
3、操作系统一次重启可能涉及多多方面,不妨多去请教和咨询,有时是需要各专业同事共同诊断,才能把问题彻底搞清楚。
? ?
?There are many things that can not be broken!
?如果觉得本文对你有帮助,欢迎点赞、收藏、评论!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- selenium+python自动化测试之环境搭建
- vue3中的hook公共函数封装及运用
- 用轻量级ORM--Dapper调用MySQL存储过程
- 详解java继承
- 《向量数据库指南》让「引用」为 RAG 机器人回答增加可信度
- MySQL 常用函数介绍
- java-IO
- flutter学习-day23-使用extended_image处理图片的加载和操作
- leetcode hot 100
- Java数据结构与算法:动态规划之斐波那契数列