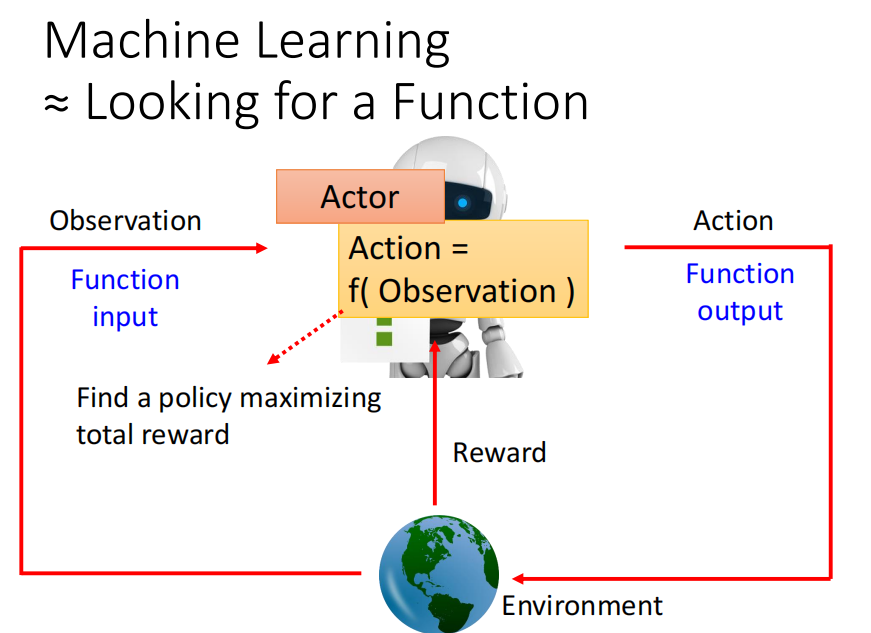
P114 增强学习 RL ---没懂,以后再补充
发布时间:2024年01月11日


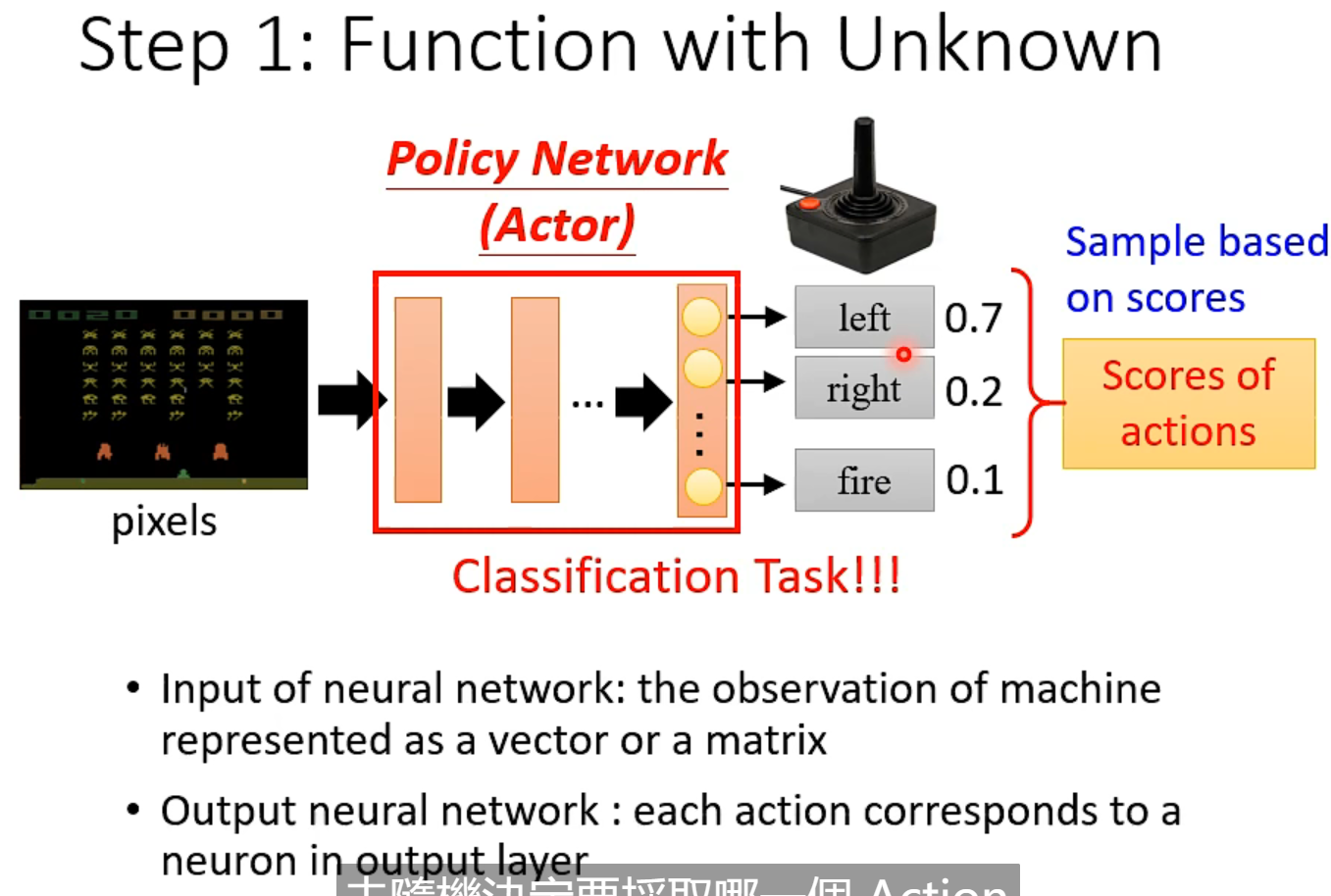
sample: 如 70% 的概率向左 20%的概率向右 10% 的概率开火
不是left 分数最高,就直接向左。而是随机sample
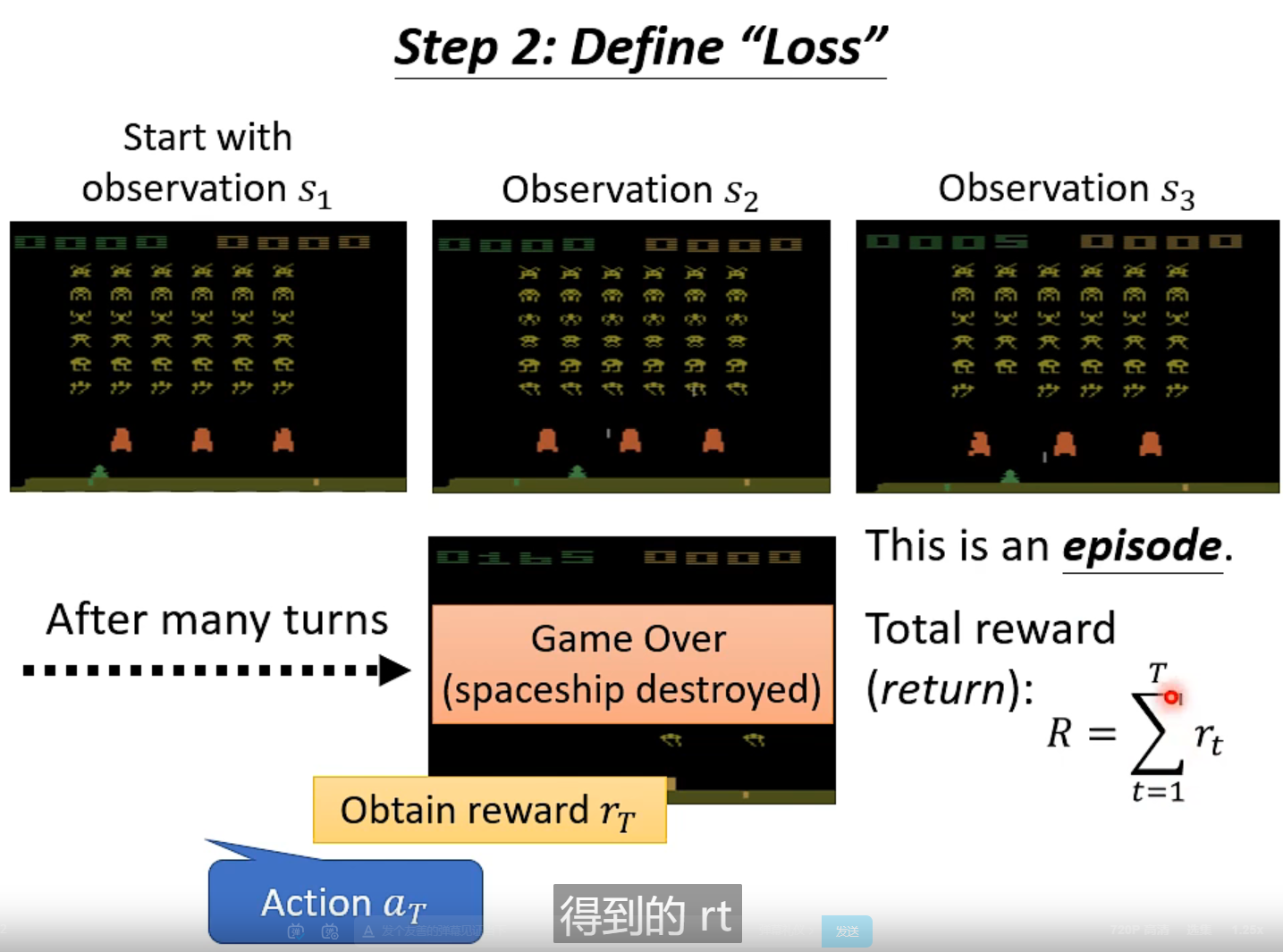
total reward (return) R 就是优化的目标,分数越高约好
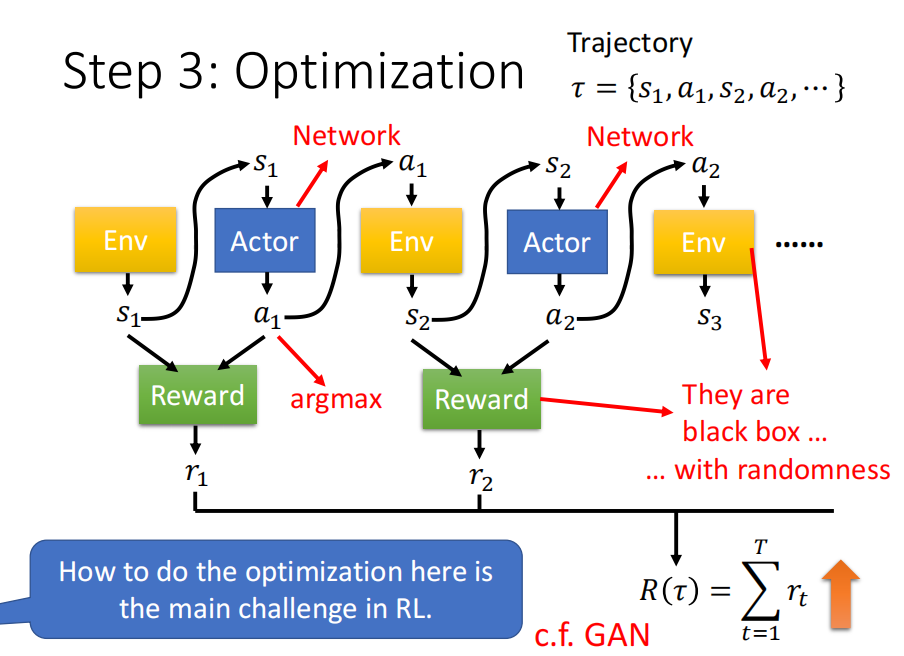
-total reward= loss
Policy Gradient
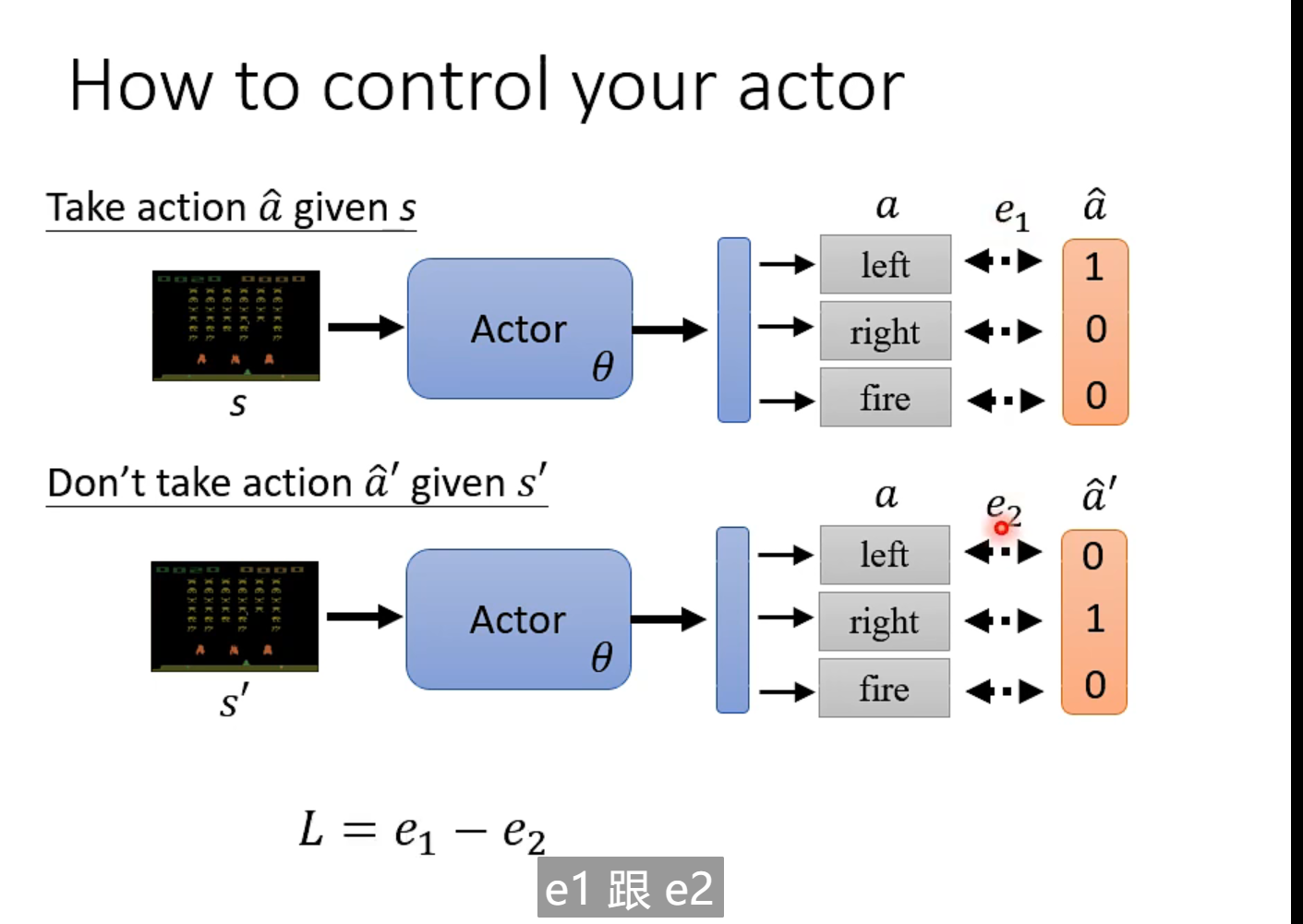
当环境是s 时
文章来源:https://blog.csdn.net/weixin_39107270/article/details/135484461
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 离散数学3
- 基于ssm旅游攻略网站设计论文
- windows配置supervisor办法
- 生态增长 TVL 飙升,Metis 或是 Layer2 最具潜力黑马
- Python-实现高并发的常见方式
- Java 设计者模式以及与Spring关系(一)单例和建造者模式
- C#爬虫1688以图搜图API接口功能的实现
- 图像文件怎么才能转换为Excel
- 第十二讲_ArkUI相对布局(RelativeContainer)
- 【精通C语言】:深入解析for循环,从基础到进阶应用