k8s实践(14)--scheduler调度器和pod调度策略
一、scheduler调度器
1、kube-scheduler简介
k8s实践(10) -- Kubernetes集群运行原理详解 介绍过kube-scheduler。
kube-scheduler是运行在master节点上,其主要作用是负责资源的调度(Pod调度),通过API Server的Watch接口监听新建Pod副本信息, 按照预定的调度策略将Pod调度到相应的Node节点上;
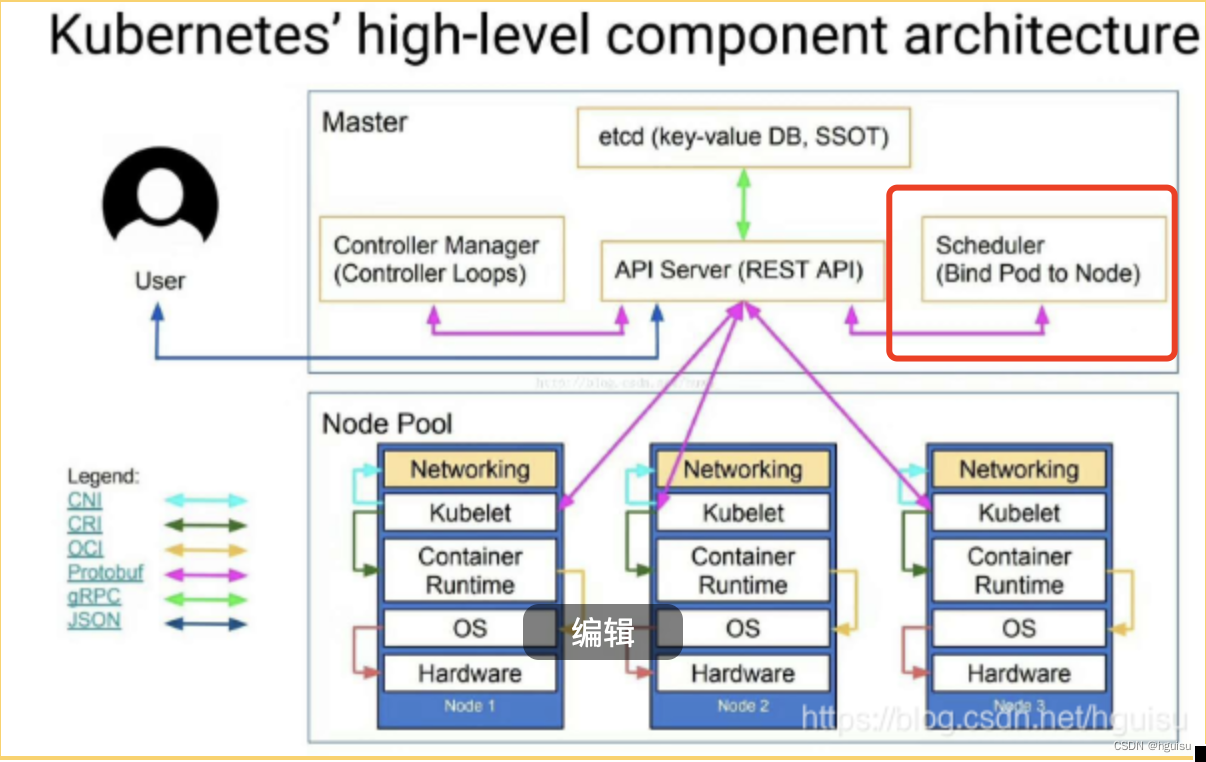
?创建Pod的整个流程,时序图如下:

1. 用户提交pod资源请求:用户提交创建Pod的请求,可以通过API Server的REST API ,也可用Kubectl命令行工具,支持Json和Yaml两种格式;
2. API Server 处理请求:API Server 处理用户请求,存储Pod数据到Etcd;
3. Schedule调度pod:Schedule通过和 API Server的watch机制,实时查看到新的pod,按照预定的调度策略将Pod调度到相应的Node节点上;
???? 一旦 Etcd 存储 Pod 信息成功便会立即通知APIServer,APIServer会立即把Pod创建的消息通知Scheduler,Scheduler发现 Pod 的属性中 Dest Node 为空时(Dest Node=””)便会立即触发调度流程进行调度。
在调度的过程当中有3个阶段:节点预选、节点优选、节点选定,从而筛选出最佳的节点:
???????????????????? 1)过滤主机(节点预选):调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机从而完成节点的预选;
??????????????????? 2)主机打分(节点优选):对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等;对预选出的节点进行优先级排序,以便选出最合适运行Pod对象的节点.
??????????????????? 3)选择主机(节点选定):选择打分最高的主机,进行binding操作,结果存储到Etcd中;
4. kubelet创建pod:? kubelet根据Schedule调度结果执行Pod创建操作: 调度成功后,会启动container, docker run, scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器。
2、Scheduler原理分析
?????? k8s Scheduler的作用是将待调度的Pod(API新创建的Pod、Controller Manager为补足副本而创建的Pod等)按照特定的调度算法和调度策略绑定到集群中的某个合适的Node上,并将绑定信息写入etcd中。
???? 在整个调度过程中涉及三个对象,分别是:待调度Pod列表、可用Node列表,以及调度算法和策略。
????? 随后,目标节点上的kubelet通过API Server监听到k8s Scheduler产生的Pod绑定事件,然后获取对应的Pod清单,下载Image镜像,并启动容器。
完整的流程如下所示:
k8s Scheduler当前提供的默认调度流程分为以下两步:
1)预选调度过程,即遍历所有目标Node,筛选出符合要求的候选节点,kubernetes内置了多种预选策略(xxx Predicates)供用户选择。
2)确定最优节点,在第一步的基础上采用优选策略(xxx Priority)计算出每个候选节点的积分,最高积分者胜出。
k8s Scheduler的调度流程是通过插件方式加载的“调度算法提供者”(AlgorithmProvider)具体实现的。一个AlgorithmProvider其实就是包括了一组预选策略与一组优选策略的结构体。
注册AlgorithmProvider的函数如下:
func RegisterAlgorithmProvider(name string, predicateKeys, priorityKeys util.StringSet)
它包含三个参数:
??? name.string,算法名;
??? predicateKeys,为算法用到的预选策略集合;
??? priorityKeys,为算法用到的优选策略的集合;
Scheduler中可用的预选策略包含:NoDiskConflict, PodFitsResources, PodSelectorMatches, PodFirstHost, CheckNodeLabelPresence, CheckServiceAffinity和PodFitsPorts策略等。
其默认的AlgorithmProvider加载的预选策略Predicates包括:PodFitsPorts, PodFitsResources, NoDiskConflict, MatchNodeSelector(PodSelectorMatches) 和 HostName(PodFitsHost),即每个节点只有通过前面提及的5个默认预选策略后,才能初步被选中,进入下一个流程。
常用的预选策略:
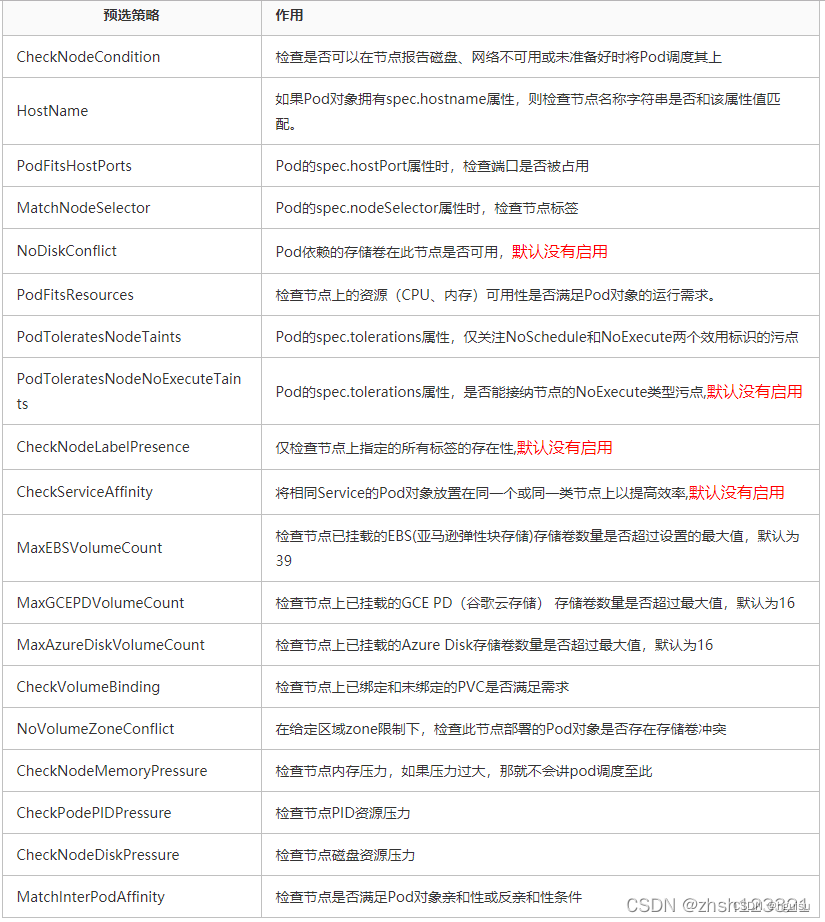
1)NoDiskConflict :pod依赖的存储卷在此节点是否可用,默认不开启
????? 判断备选Pod的gcePersistentDisk或AWSElasticBlockStore和备选的节点中已存在的Pod是否存在冲突。检测过程如下:
??? 首先,读取备选Pod的所有Volume的信息(即pod.Spec.Volumes),对每个Volume执行以下步骤进行冲突检测。
??? 如果该Volume是gcePersistentDisk,则将Volume和备选节点上的所有Pod的每个Volume进行比较,如果发现相同的gcePersistentDisk,则返回false,表明存在磁盘冲突,检查结束,反馈给调度器该备选节点不适合作为备选Pod;如果该Volume是AWSElasticBlockStore,则将Volume和备选节点上的所有Pod的每个Volume进行比较,如果发现相同的AWSElasticBlockStore,则返回false,表明存在磁盘冲突,检查结束,反馈给调度器该备选节点不适合备选Pod。
??? 如果检查完备选Pod的所有Volume均未发现冲突,则返回true,表明不存在磁盘冲突,反馈给调度器该备选节点适合备选Pod。
2)PodFitsResources :选择节点上资源(内存和CPU)是否满足pod运行需求
判断备选节点的资源是否满足备选Pod的需求,检测过程如下:
??? 计算备选Pod和节点中已存在Pod的所有容器的需求资源(内存和CPU)的总和。
??? 获得备选节点的状态信息,其中包含节点的资源信息。
??? 如果备选Pod和节点中已存在Pod的所有容器的需求资源(内存和CPU)的总和,超出了备选节点拥有的资源,则返回false,表明备选节点不适合备选Pod,否则返回true,表明备选节点适合备选Pod。
3)PodSelectorMatches: 当pod存在spec.nodeSelector标签选择器,检查节点标签。
判断备选节点是否包含备选Pod的标签选择器指定的标签。
??? 如果Pod没有指定spec.nodeSelector标签选择器,则返回true。
??? 否则,获得备选节点的标签信息,判断节点是否包含备选Pod的标签选择器(spec.nodeSelector)所指定的标签,如果包含,则返回true,否则返回false。
4)PodFitsHost:如果Pod存在spec.nodeName属性
???? 判断备选Pod的spec.nodeName域所指定的节点名称和备选节点的名称是否一致,如果一致,则返回true,否则返回false。
5)CheckNodeLabelPresence
如果用户在配置文件中指定了该策略,则Scheduler会通过RegisterCustomFitPredicate方法注册该策略。该策略用于判断策略列出的标签在备选节点中存在时,是否选择该备选节点。
??? 读取备选节点的标签列表信息。
??? 如果策略配置的标签列表存在于备选节点的标签列表中,且策略配置的presence值为false,则返回false,否则返回true;如果策略配置的标签列表不存在于备选节点的标签列表中,且策略配置的presence为true,则返回false,否则返回true。
6)CheckServiceAffinity
如果用户在配置文件中指定了该策略,则Scheduler会通过RegisterCustomFitPredicate方法注册该策略。该策略用于判断备选节点是否包含策略指定的标签,或包含和备选Pod在相同Service和Namespace下的Pod所在节点的标签列表。如果存在,则返回true,否则返回false。
7)PodFitsPorts
判断备选Pod所用的端口列表中的端口是否在备选节点中已被占用,如果被占用,则返回false,否则返回true。
Scheduler中的优选策略
Scheduler中的优选策略包含:LeastRequestedPriority、CalculateNodeLabelPriority和BalancedResourceAllocation等。
每个节点通过优选策略时都会算出一个得分,计算各项得分,最终选出得分值最大的节点作为优选的结果(也是调度算法的结果)。
下面是对优选策略的详细说明:
1) LeastRequestedPriority
优先从备选节点列表中选择资源消耗最小的节点(CPU+内存)。
2) CalculateNodeLabelPriority
如果用户在配置文件中指定了该策略,则scheduler会通过RegisterCustomPriorityFunction方法注册该策略。该策略用于判断策略列出的标签在备选节点中存在时,是否选择该备选节点。
如果备选节点的标签在优先策略的标签列表中且优选策略的presence为true,或者备选节点的标签不在优选策略的标签列表中且优选策略的presence值为false,则备选节点score=10,否则备选节点score=0。
3) BalancedResourceAllocation
优先从备选节点列表中选择各项资源使用率最均衡的节点。
二、Pod调度
在Kubernetes系统中,Pod在大部分场景下都只是容器的载体而已,通常需要通过RC、Deployment、DaemonSet、Job等对象来完成Pod的调度和自动控制功能。
k8s提供了常用的4大调度规则,如下:
- 自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出;
- 定向调度:NodeName、NodeSelector;
- 亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity;
- 污点(容忍)调度:Taints、Toleration;
三、RC、Deployment的pod调度
???? RC的主要功能之一就是自动部署容器应用的多份副本,以及持续监控副本的数量,在集群内始终维护用户指定的副本数量。
????? 在调度策略上,除了使用系统内置的调度算法选择合适的Node进行调度,也可以在Pod的定义中使用NodeName、NodeSelector或NodeAffinity来指定满足条件的Node进行调度。
1、基于NodeName定向调度
Pod.spec.nodeName用于强制约束将Pod调度到指定的Node节点上,这里说是“调度”,但其实指定了nodeName的Pod会直接跳过Scheduler的调度逻辑,直接写入PodList列表,该匹配规则是强制匹配。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: springbootweb
name: springbootweb-deployment
spec:
replicas: 1
selector:
matchLabels:
app: springbootweb
template:
metadata:
labels:
app: springbootweb
spec:
nodeName: node23.turing.com
containers:
- image: registry.tuling123.com/springboot:latest
imagePullPolicy: IfNotPresent
name: springbootweb
ports:
- containerPort: 9081
hostPort: 9981
imagePullSecrets:
- name: registry-key-secret
2、基于NodeSelector:定向调度
???? Kubernetes Master上的scheduler服务(kube-Scheduler进程)负责实现Pod的调度,整个过程通过一系列复杂的算法,最终为每个Pod计算出一个最佳的目标节点,通常我们无法知道Pod最终会被调度到哪个节点上。实际情况中,我们需要将Pod调度到我们指定的节点上,可以通过Node的标签和pod的nodeSelector属性相匹配来达到目的。
??? 其核心思想是,为工作节点(node)打上标签,比如地区、机房、CPU密集、IO密集等。然后在创建pod的描述文件时指定对应标签,调度器就会将pod调度到符合标签选择器规则的工作节点上。
NodeSelector(Pod.spec.nodeSelector)是通过kubernetes的label-selector机制进行节点选择,由scheduler调度策略MatchNodeSelector调度策略进行label匹配,调度pod到目标节点,该匹配规则是强制约束。
启用节点选择器的步骤为:
(1)首先通过kubectl label命令给目标Node打上标签
???????? kubectl label nodes <node-name> <label-key>=<label-value>
???????? 例:#kubectllabel nodes k8s-node-1 zonenorth
??? (2)然后在Pod定义中加上nodeSelector的设置,例:
apiVersion:v1
kind: Pod
metadata:
name: redis-master
label:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: redis-master
images: kubeguide/redis-master
ports:
- containerPort: 6379
nodeSelector:
zone: north
运行kubectl create -f命令创建Pod,scheduler就会将该Pod调度到拥有zone=north标签的Node上。 如果多个Node拥有该标签,则会根据调度算法在该组Node上选一个可用的进行Pod调度。
??? 需要注意的是:如果集群中没有拥有该标签的Node,则这个Pod也无法被成功调度。
3、Affinity:亲和性调度
Affinity主要分为三类:
nodeAffinity(node亲和性): 以node为目标,解决pod可以调度到哪些node的问题;podAffinity(pod亲和性) : 以pod为目标,解决pod可以和哪些已存在的pod部署在同一个拓扑域中的问题;podAntiAffinity(pod反亲和性) : 以pod为目标,解决pod不能和哪些已存在pod部署在同一个拓扑域中的问题;
关于亲和性(反亲和性)使用场景的说明:
亲和性
如果两个应用频繁交互,那就有必要利用亲和性让两个应用的尽可能的靠近,这样可以减少因网络通信而带来的性能损耗。
反亲和性
当应用的采用多副本部署时,有必要采用反亲和性让各个应用实例打散分布在各个node上,这样可以提高服务的高可用性。
?
4、NodeAffinity亲和性
4、NodeAffinity亲和性该调度策略是将来替换NodeSelector的新一代调度策略。由于NodeSelector通过Node的Label进行精确匹配,所有NodeAffinity增加了In、NotIn、Exists、DoesNotexist、Gt、Lt等操作符来选择Node。调度侧露更加灵活。
1)、NodeAffinity 的亲和性表达
目前有以下几种亲和性表达。
硬限制:RequiredDuringSchedulingIgnoredDuringExecution
必须满足指定的规则才可以调度 Pod 到 Node 上,相当于 硬限制。
软限制:PreferredDuringSchedulingIgnoredDuringExecution
强调优先满足指定规则,调度器会尝试调度 Pod 到 Node 上,但并不强求,相当于 软限制。
多个优先级规则还可以设置权重(weight)值,以此来定义执行的先后顺序。
?
节点亲和性权重
我们可以为 PreferredDuringSchedulingIgnoredDuringExecution 亲和性类别的每个实例设置 weight 字段,取值范围是 1 ~ 100。当调度器找到能够满足 Pod 的其他调度请求的节点时,调度器会比那里节点满足的所有的偏好性规则,并将对应表达式的 weight 值加和。最终的加和值会添加到该节点的其他优先级函数的评分之上。在调度器为 Pod 做出调度决定时,总分最高的节点的优先级也最高。
IgnoredDuringExecution
如果一个 Pod 所在的节点在 Pod 运行期间标签发生了变更,不再符合该 Pod的节点亲和性需求,则系统将忽略 Node 上 label 的变化,该 Pod 能继续在该节点运行。
?
2)、NodeAffinity 的语法规则
NodeAffinity 语法支持的操作符包括In,NotIn,Exists,DoesNotExist,Gt,Lt。虽然没有节点排斥功能,但是用 NotIn 和 DoesNotExist 就可以实现排斥的功能了。
??? In:label的值在某个列表中
??? NotIn:label的值不在某个列表中
??? Gt:label的值大于某个值
??? Lt:label的值小于某个值
??? Exists:某个label存在
??? DoesNotExist:某个label不存在
关系符使用说明:
- matchExpressions:
? - key: nodeenv????????????? # 匹配存在标签的key为nodeenv的节点
??? operator: Exists
? - key: nodeenv????????????? # 匹配标签的key为nodeenv,且value是"xxx"或"yyy"的节点
??? operator: In
??? values: ["xxx","yyy"]
? - key: nodeenv????????????? # 匹配标签的key为nodeenv,且value大于"xxx"的节点
??? operator: Gt
??? values: "xxx"
3)、NodeAffinity 的注意事项
??? 如果同时定义了 nodeSelector 和 nodeAffinity,那么必须两个条件都得到满足,Pod 才能最终运行到指定的 Node 上。
??? 如果 nodeAffinity 指定了多个 nodeSelectorTerms,那么其中一个能够匹配成功即可。
??? 如果在 nodeSelectorTerms 中有多个 matchExpressions,则一个节点必须满足所有matchExpressions 才能运行该 Pod。
4、案例
通过配置 NodeAffinity 的 PreferredDuringSchedulingIgnoredDuringExecution 来实现,优先将 Pod 投递到 32G 内存的节点,其次 16G 内存节点,最后 8G 内存节点。
spec:
containers:
- name: xxxxx
image: xxxxx
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 20
preference:
matchExpressions:
- key: mem
operator: In
values:
- memory32
- weight: 10
preference:
matchExpressions:
- key: mem
operator: In
values:
- memory16
- weight: 1
preference:
matchExpressions:
- key: mem
operator: In
values:
- memory8
四、DaemonSet:特定场景调度
DaemonSet用于管理集群中每个Node上仅运行一份Pod的副本实例,如图:
这种用法适合一些有下列需求的应用:
??? 在每个Node上运行个以GlusterFS存储或者ceph存储的daemon进程
??? 在每个Node上运行一个日志采集程序,例如fluentd或者logstach
??? 在每个Node上运行一个健康程序,采集Node的性能数据。
DaemonSet的Pod调度策略类似于RC,除了使用系统内置的算法在每台Node上进行调度,也可以在Pod的定义中使用NodeSelector或NodeAffinity来指定满足条件的Node范围来进行调度。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年【陕西省安全员C证】考试题库及陕西省安全员C证考试内容
- Jenkins——在流水线管道中使用指定的JDK
- vscode运行python项目
- 文章解读与仿真程序复现思路——电力自动化设备EI\CSCD\北大核心《基于新能源-负荷相似性的源荷储协调调峰优化调度》
- 《操作系统》—— 处理机调度算法
- 当忘记Windows 10的PIN码时,你就来对地方法了
- 5V低压步进电机驱动芯片GC6150,应用于摄像机,机器人 医疗器械等产品中。具有低噪声、低振动的特点
- 基于Flutter构建小型新闻App
- LitJson-Json字符串转对像时:整型与字符串或字符串转:整型进的类型不一致的处理
- MySQL卸载-Windows版