大模型听课笔记——书生·浦语(4)
发布时间:2024年01月15日
大模型听课笔记——书生·浦语(4)
本节课的内容:单卡微调
大语言模型是在海量文本上以无监督或半监督的方式进行训练的,这些海量的文本赋予了大模型各方面的知识,但是当我们专注于某个领域,实际应用于某个领域或应用时,大语言模型的表现的表现就没有那么完美了。此时就引入了微调。
Finetune简介
而由于训练成本太过昂贵,
增量训练和指令跟随是两种常用的微调模式。
指令跟随示意图:

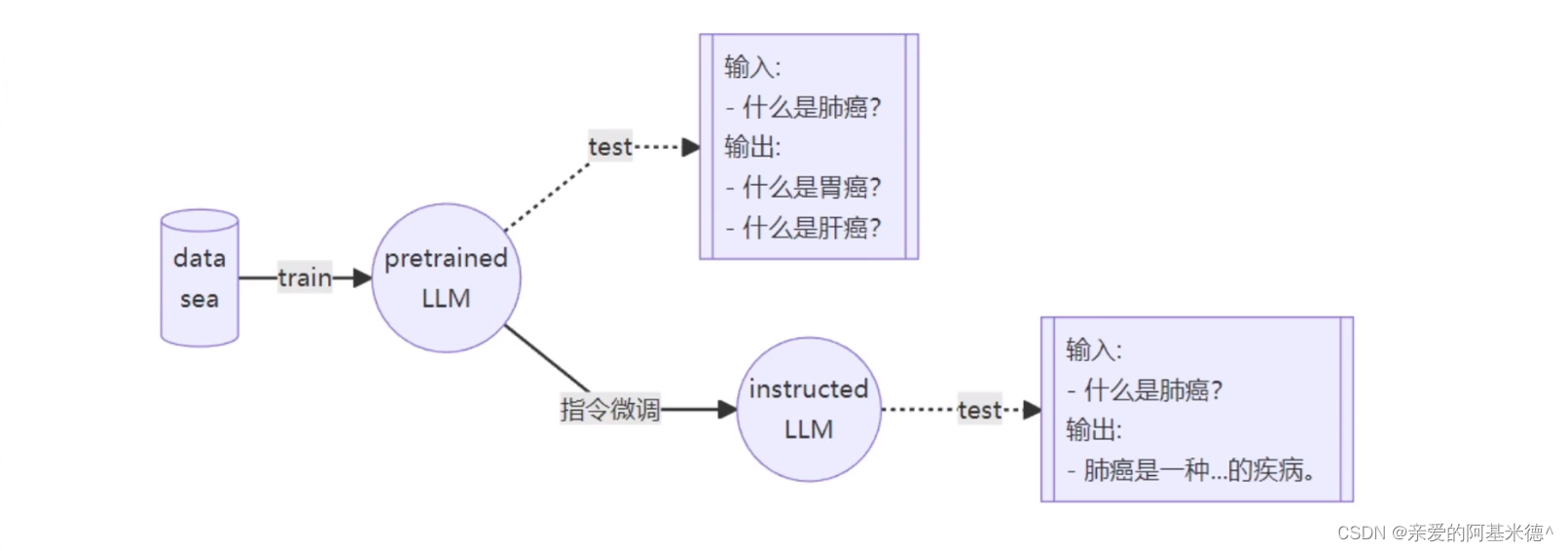
指令跟随微调的实现示意

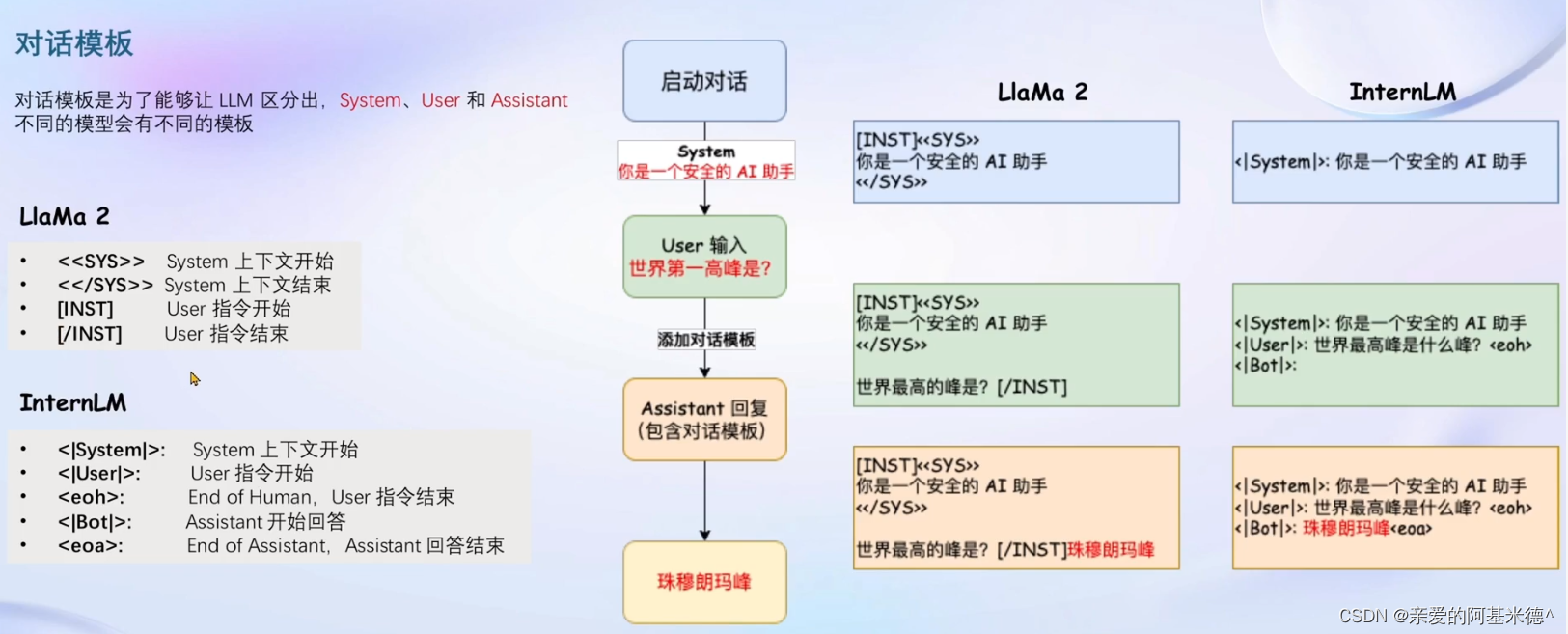
由于不同的微调多为不同的组织发行,对话模板一般不太相同。
根据对话模板完成对话构建后,我们需要将构建完成的数据输入模型,来进行损失,由于我们真正希望模型回答的部分是对话的答案部分,所欲计算损失如图也只计算答案的部分。

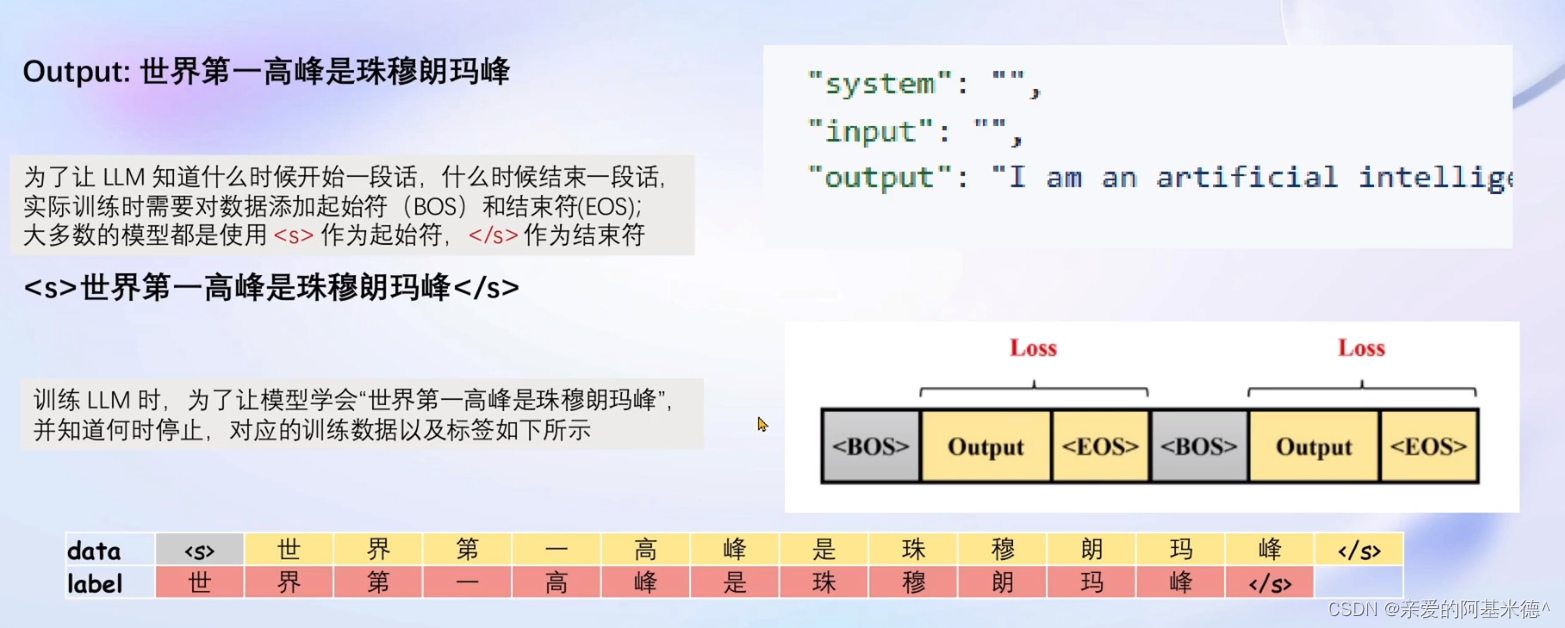
增量预训练微调
增量训练的数据不需要构建对话,只需要陈述事实。
所以将对话模板的system和user的对话内容留空,只计算assistant的损失
Xtuner中使用的微调原理
LoRA & QLoRA
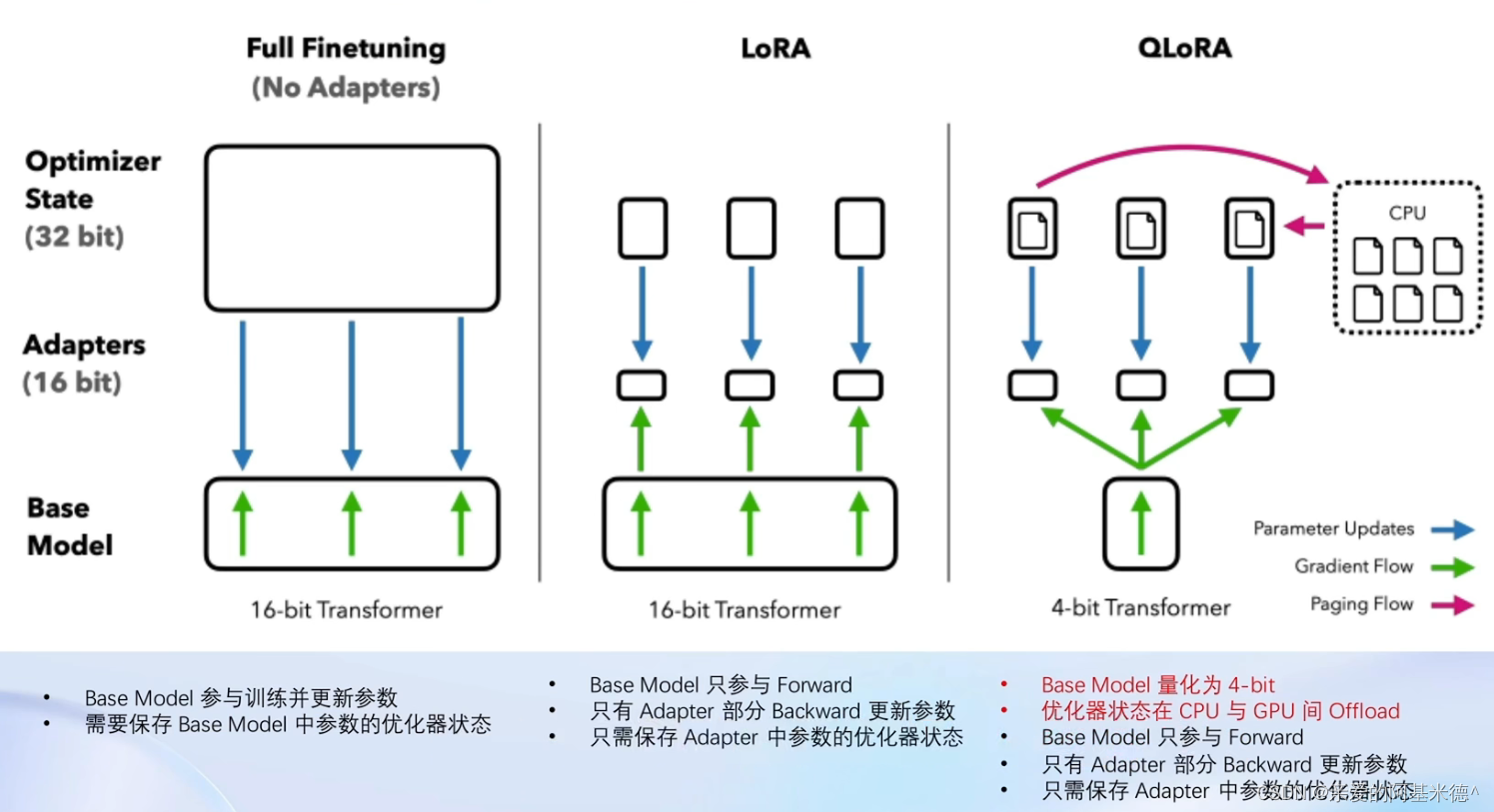
全参数微调需要太多的显存开销
LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS
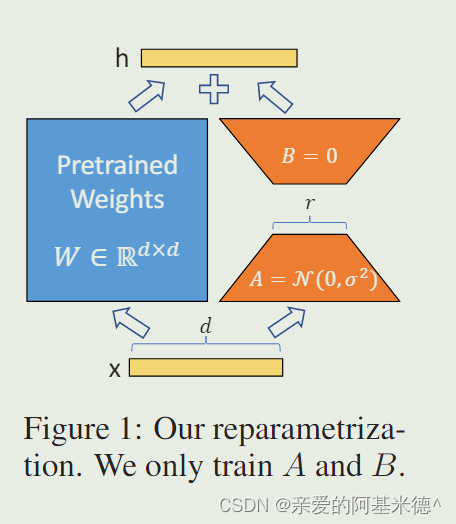
LLM的主要参数集中在模型中的Linear,训练这些会耗费大量的显存
LoRA通过在原本的Linear旁,新增一个支路,包含两个连续的小Linear,新增的支路通常会叫做Adapter。
而Adapter的参数量要远小于原本的Linear,所以可以提大幅降低显存消耗。
Full Finetunning 、LoRA 与 QLoRA的对比
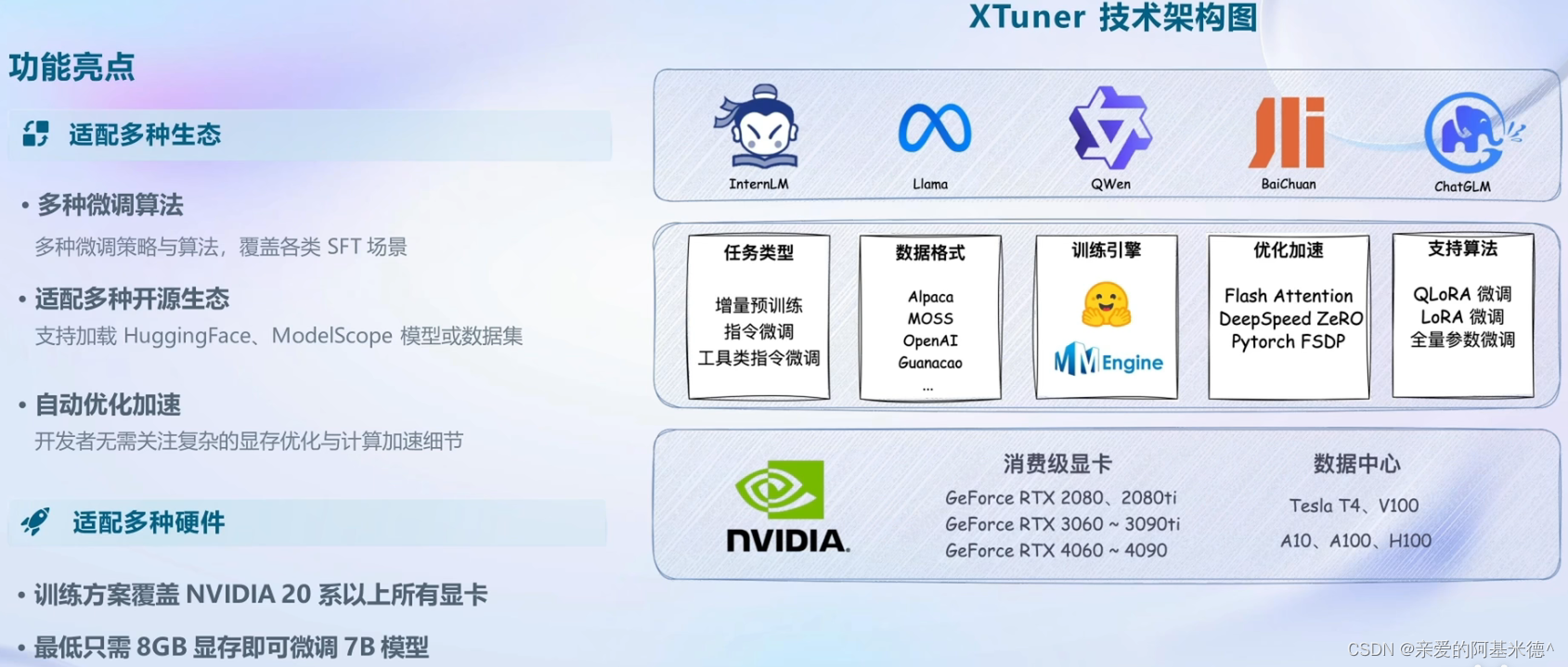
XTuner 简介

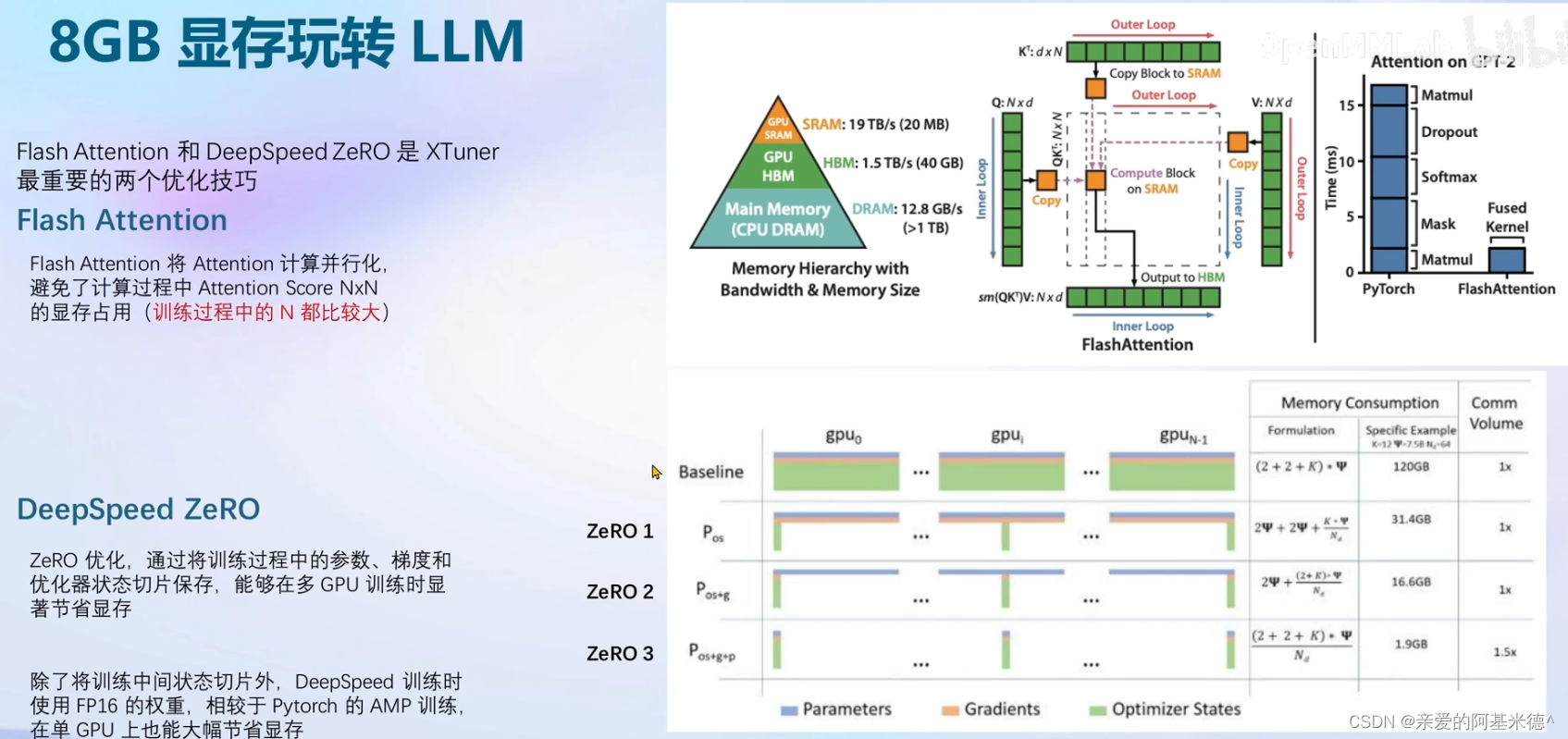
Xtuner默认会开启
Flash Attention,DepSpeed ZeRO则需要在启动时增加启动参数
文章来源:https://blog.csdn.net/rabbit9798/article/details/135482950
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- h2-database 安装部署学习
- 网站被挂黑链怎么办
- npm 安装包遇到问题的常用脚本(RequestError: socket hang up)
- 使用Enterprise Architect绘制架构图
- 字符串倒序输出
- tp如何开启监听SQL
- python进行简单的app自动化测试(pywinauto)+ 截屏微信二维码
- Python+Appium自动化测试的使用步骤
- 【零基础入门TypeScript】TypeScript - 环境设置
- Redis面试题13