MySQL undo日志精讲2-undo日志写入
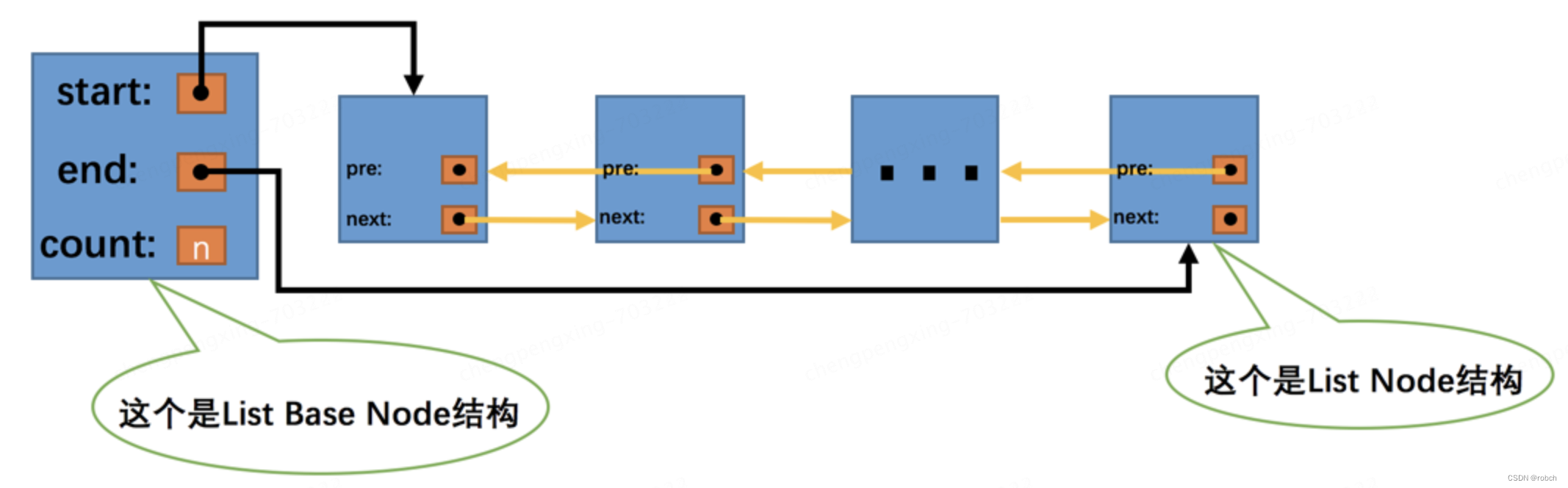
通用链表结构
在写入undo日志的过程中会使用到多个链表,很多链表都有同样的节点结构,如图所示:
 在某个表空间内,我们可以通过一个页的页号和在页内的偏移量来唯一定位一个节点的位置,这两个信息也就相当于指向这个节点的一个指针。所以:
在某个表空间内,我们可以通过一个页的页号和在页内的偏移量来唯一定位一个节点的位置,这两个信息也就相当于指向这个节点的一个指针。所以:
Pre Node Page Number 和 Pre Node Offset的组合就是指向前一个节点的指针
Next Node Page Number 和 Next Node Offset的组合就是指向后一个节点的指针。
整个List Node占用12个字节的存储空间。
为了更好的管理链表,设计InnoDB的大佬还提出了一个基节点的结构,里边存储了这个链表的头节点、尾节点以及链表长度信息,基节点的结构示意图如下:
?? 其中:
其中:
List Length表明该链表一共有多少节点。
First Node Page Number和First Node Offset的组合就是指向链表头节点的指针。
Last Node Page Number和Last Node Offset的组合就是指向链表尾节点的指针。
整个List Base Node占用16个字节的存储空间。
所以使用List Base Node和List Node这两个结构组成的链表的示意图就是这样:
FIL_PAGE_UNDO_LOG页面
我们前面介绍表空间的时候说过,表空间其实是由许许多多的页面构成的,页面默认大小为16KB。这些页面有不同的类型,比如类型为 FIL_PAGE_INDEX 的页面用于存储聚簇索引以及二级索引,类型为FIL_PAGE_TYPE_FSP_HDR 的页面用于存储表空间头部信息的,还有其他各种类型的页面,其中有一种称之为 FIL_PAGE_UNDO_LOG 类型的页面是专门用来存储undo日志的,这种类型的页面的通用结构如下图所示(以默认的16KB大小为例):
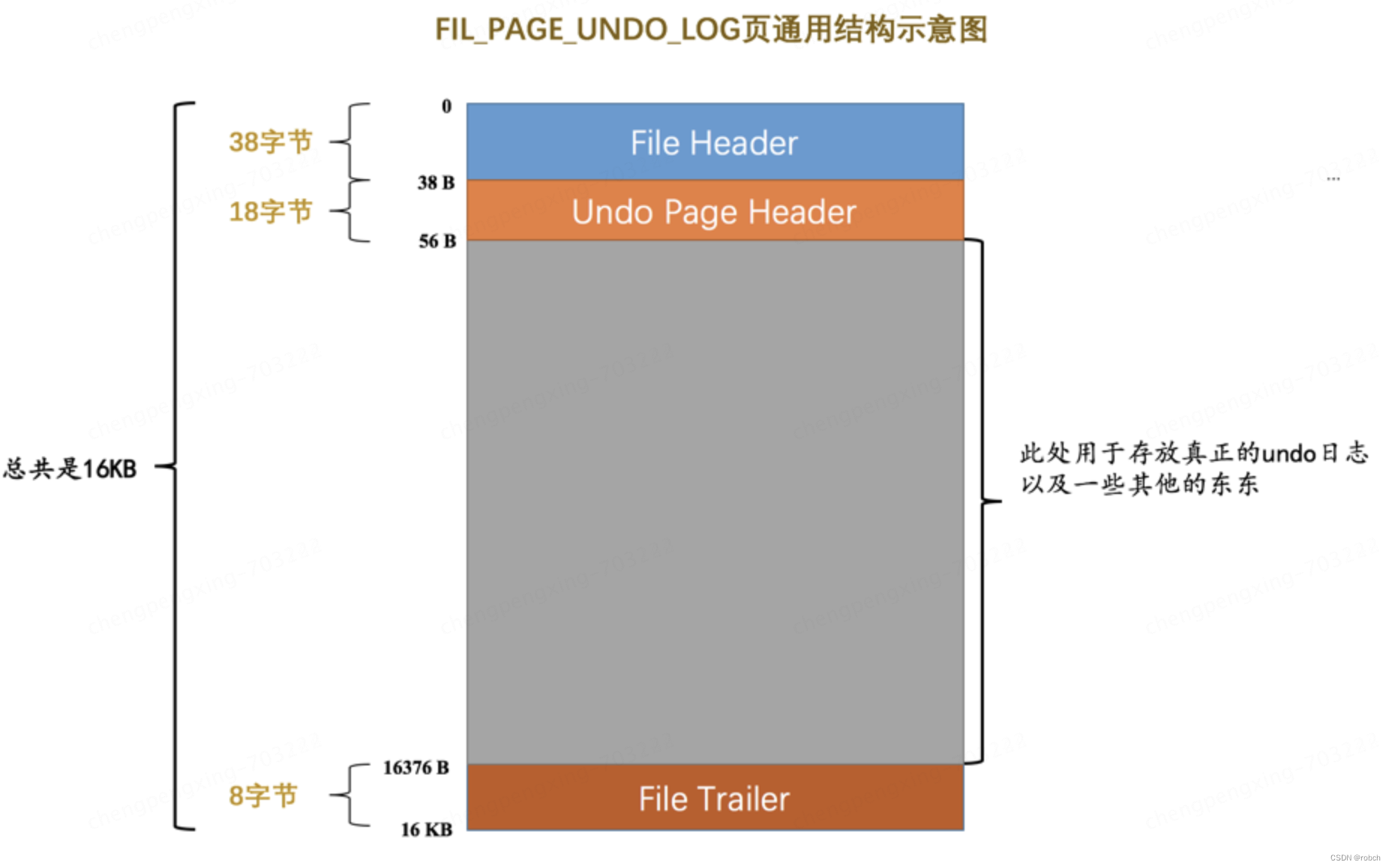 “类型为FIL_PAGE_UNDO_LOG的页” 这种说法太绕口,以后我们就简称为Undo页面了。上图中的File Header和File Trailer是各种页面都有的通用结构,我们前面介绍过很多遍了,这里就不赘述了(忘记了的可以到讲述数据页结构或者表空间的章节中查看)。Undo Page Header是Undo页面所特有的,我们来看一下它的结构:
“类型为FIL_PAGE_UNDO_LOG的页” 这种说法太绕口,以后我们就简称为Undo页面了。上图中的File Header和File Trailer是各种页面都有的通用结构,我们前面介绍过很多遍了,这里就不赘述了(忘记了的可以到讲述数据页结构或者表空间的章节中查看)。Undo Page Header是Undo页面所特有的,我们来看一下它的结构:
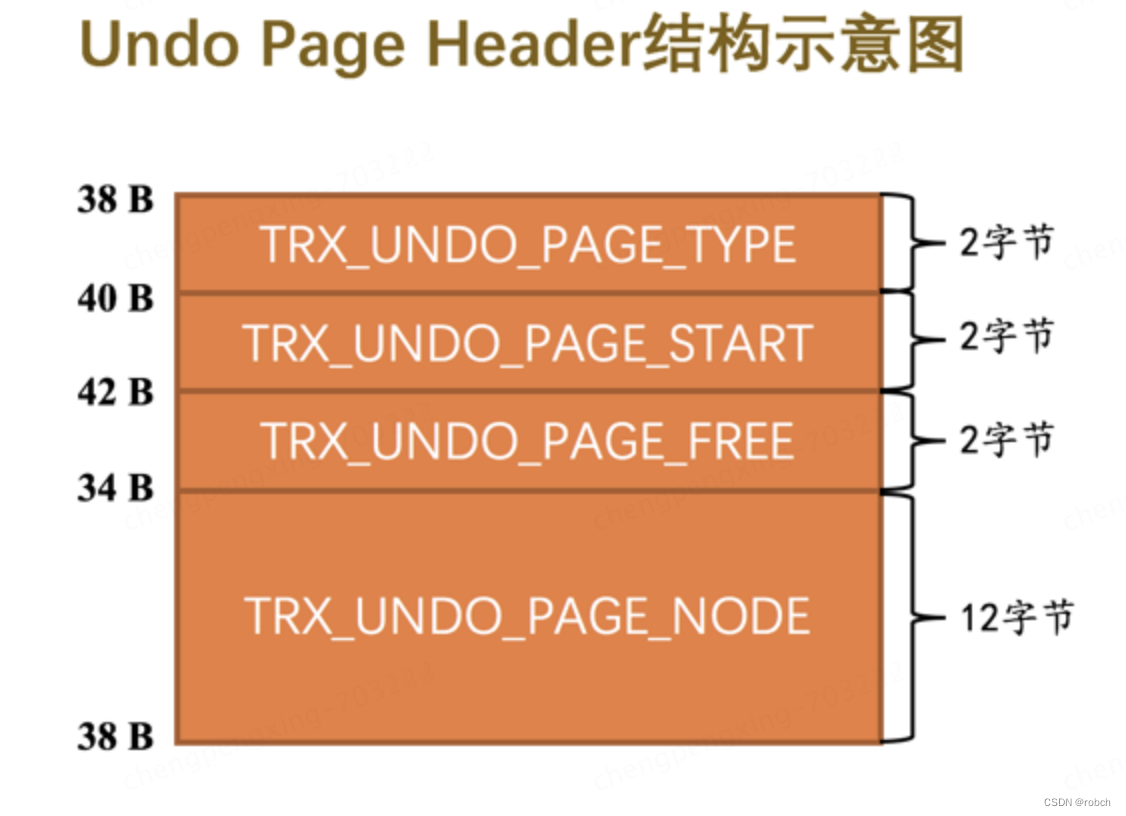 其中各个属性的意思如下:
其中各个属性的意思如下:
TRX_UNDO_PAGE_TYPE:本页面准备存储什么种类的undo日志。
我们前面介绍了好几种类型的undo日志,它们可以被分为两个大类:
TRX_UNDO_INSERT(使用十进制1表示):类型为TRX_UNDO_INSERT_REC的undo日志属于此大类,一般由INSERT语句产生,
或者在UPDATE语句中有更新主键的情况也会产生此类型的undo日志。
TRX_UNDO_UPDATE(使用十进制2表示),除了类型为TRX_UNDO_INSERT_REC的undo日志,其他类型的undo日志都属于这个大类,
比如我们前面说的TRX_UNDO_DEL_MARK_REC、TRX_UNDO_UPD_EXIST_REC什么的,一般由DELETE、UPDATE语句产生的undo日志属于这个大类。
这个 TRX_UNDO_PAGE_TYPE 属性可选的值就是上面的两个,用来标记本页面用于存储哪个大类的undo日志,不同大类的undo日志不能混着存储,
比如一个Undo页面的TRX_UNDO_PAGE_TYPE属性值为TRX_UNDO_INSERT,那么这个页面就只能存储类型为TRX_UNDO_INSERT_REC的undo日志,
其他类型的undo日志就不能放到这个页面中了。
小贴士:之所以把undo日志分成两个大类,是因为类型为TRX_UNDO_INSERT_REC的undo日志在事务提交后可以直接删除掉,
而其他类型的undo日志还需要为所谓的 MVCC 服务,不能直接删除掉,对它们的处理需要区别对待。当然,
如果你看这段话迷迷糊糊的话,那就不需要再看一遍了,现在只需要知道undo日志分为2个大类就好了,更详细的东西我们后边会仔细介绍的。
TRX_UNDO_PAGE_START:表示在当前页面中是从什么位置开始存储undo日志的,或者说表示第一条undo日志在本页面中的起始偏移量。
TRX_UNDO_PAGE_FREE:与上面的TRX_UNDO_PAGE_START对应,表示当前页面中存储的最后一条undo日志结束时的偏移量,或者说从这个位置开始,可以继续写入新的undo日志。
TRX_UNDO_PAGE_NODE:代表一个List Node结构(链表的普通节点,我们上面刚说的 12字节的 node)。
假设现在向页面中写入了3条undo日志,那么TRX_UNDO_PAGE_START和TRX_UNDO_PAGE_FREE的示意图就是这样:
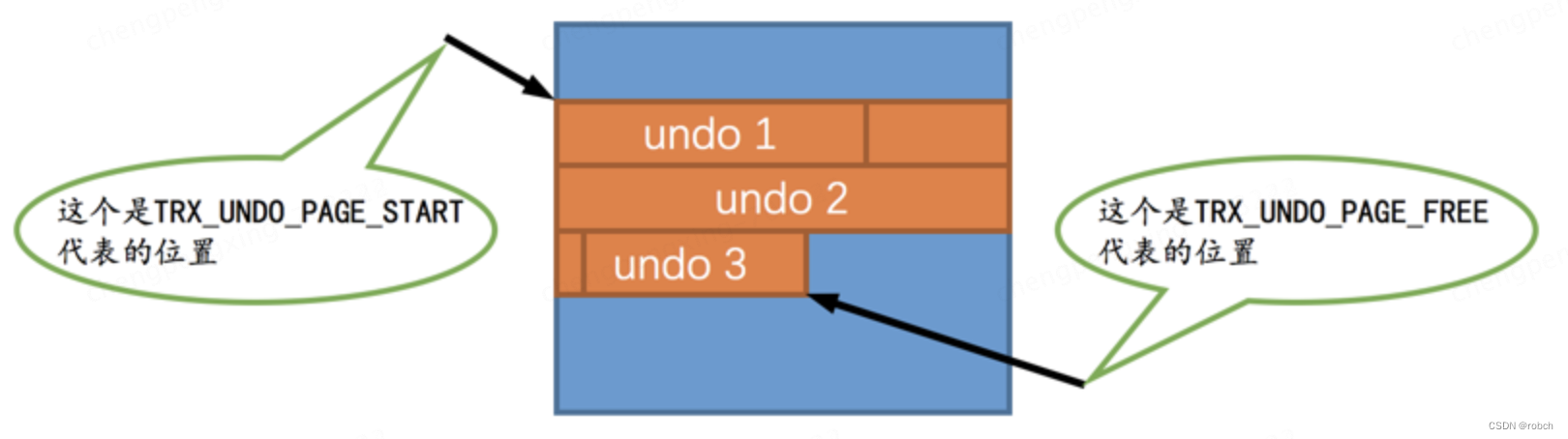 当然,在最初一条undo日志也没写入的情况下,TRX_UNDO_PAGE_START 和
当然,在最初一条undo日志也没写入的情况下,TRX_UNDO_PAGE_START 和
TRX_UNDO_PAGE_FREE 的值是相同的。
Undo页面链表
单个事务中的Undo页面链表
因为一个事务可能包含多个语句,而且一个语句可能对若干条记录进行改动,而对每条记录进行改动前,都需要记录1条或2条的undo日志,所以在一个事务执行过程中可能产生很多undo日志,这些日志可能一个页面放不下,需要放到多个页面中,这些页面就通过我们上面介绍的 TRX_UNDO_PAGE_NODE 属性连成了链表:
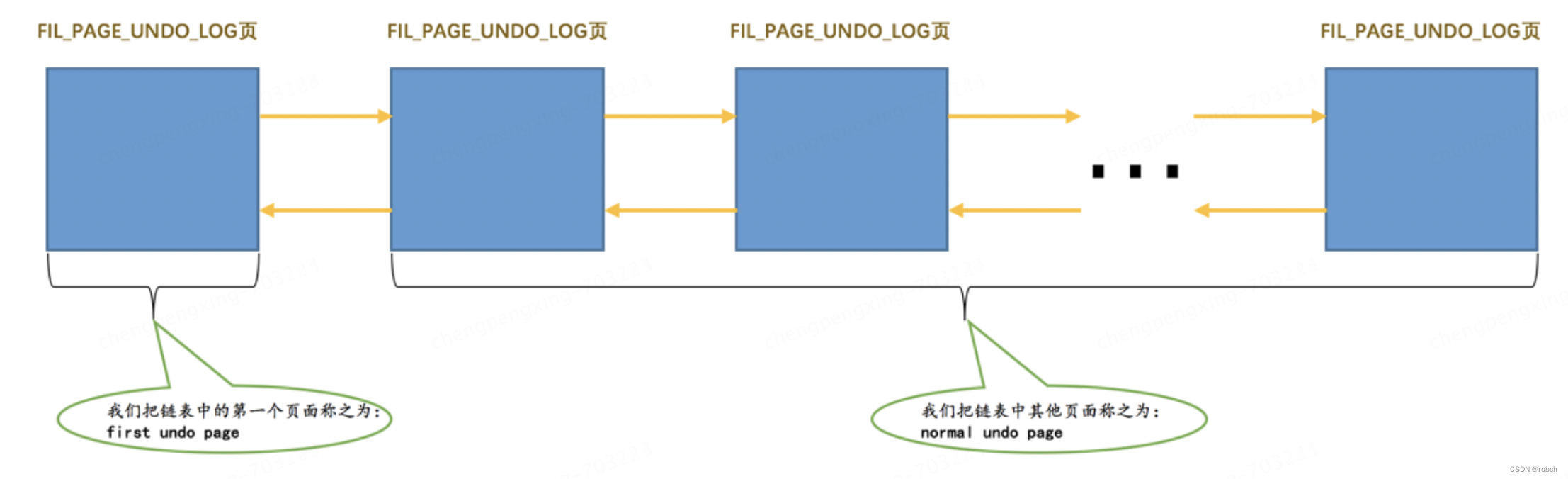 在一个事务执行过程中,可能混着执行INSERT、DELETE、UPDATE语句,也就意味着会产生不同类型的undo日志。但是我们前面又强调过,同一个Undo页面要么只存储TRX_UNDO_INSERT大类的undo日志,要么只存储TRX_UNDO_UPDATE大类的undo日志,反正不能混着存,所以在一个事务执行过程中就可能需要2个Undo页面的链表,一个称之为insert undo链表,另一个称之为update undo链表;
在一个事务执行过程中,可能混着执行INSERT、DELETE、UPDATE语句,也就意味着会产生不同类型的undo日志。但是我们前面又强调过,同一个Undo页面要么只存储TRX_UNDO_INSERT大类的undo日志,要么只存储TRX_UNDO_UPDATE大类的undo日志,反正不能混着存,所以在一个事务执行过程中就可能需要2个Undo页面的链表,一个称之为insert undo链表,另一个称之为update undo链表;
另外,设计InnoDB的大佬规定对普通表和临时表的记录改动时产生的undo日志要分别记录(我们稍后阐释为什么这么做),所以在一个事务中最多有4个以Undo页面为节点组成的链表。当然,并不是在事务一开始就会为这个事务分配这4个链表,具体分配策略如下:
刚刚开启事务时,一个Undo页面链表也不分配。
当事务执行过程中向普通表中插入记录或者执行更新记录主键的操作之后,就会为其分配一个普通表的insert undo链表。
当事务执行过程中删除或者更新了普通表中的记录之后,就会为其分配一个普通表的update undo链表。
当事务执行过程中向临时表中插入记录或者执行更新记录主键的操作之后,就会为其分配一个临时表的insert undo链表。
当事务执行过程中删除或者更新了临时表中的记录之后,就会为其分配一个临时表的update undo链表。
总结一句就是:按需分配,什么时候需要什么时候再分配,不需要就不分配。
多个事务中的Undo页面链表
为了尽可能提高 undo 日志的写入效率,不同事务执行过程中产生的undo日志需要被写入到不同的Undo页面链表中。
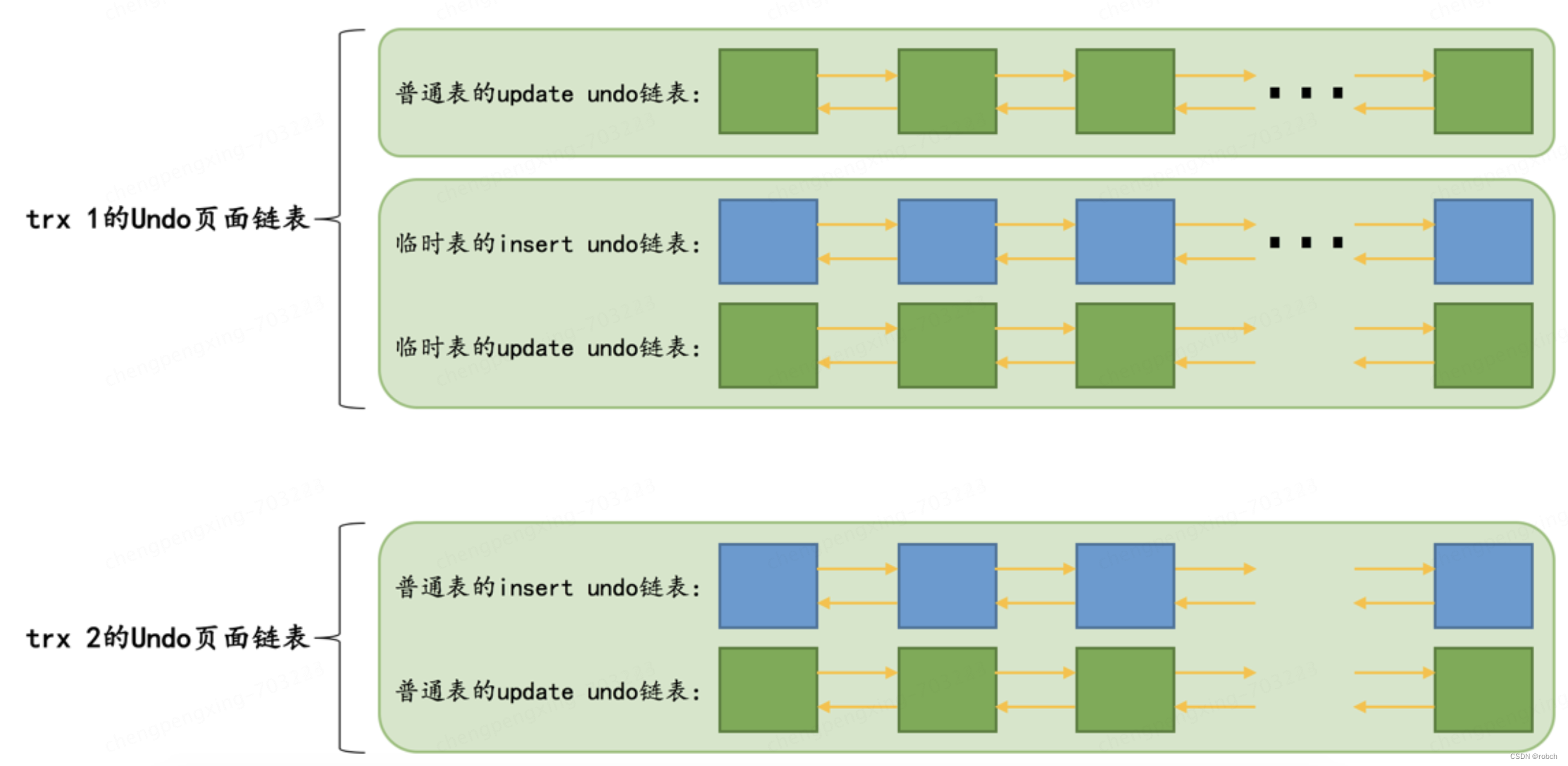
比方说现在有事务id分别为1、2的两个事务,我们分别称之为trx 1和trx 2,假设在这两个事务执行过程中:
trx 1对普通表做了DELETE操作,对临时表做了INSERT和UPDATE操作。
InnoDB会为trx 1分配3个链表,分别是:
针对普通表的update undo链表
针对临时表的insert undo链表
针对临时表的update undo链表。
trx 2对普通表做了INSERT、UPDATE和DELETE操作,没有对临时表做改动。
InnoDB会为trx 2分配2个链表,分别是:
针对普通表的insert undo链表
针对普通表的update undo链表。
综上所述,在trx 1和trx 2执行过程中,InnoDB共需为这两个事务分配5个Undo页面链表,画个图就是这样:
??
Undo日志具体写入过程
段(Segment)的概念
简单讲,这个段是一个逻辑上的概念,本质上是由若干个零散页面和若干个完整的区组成的。比如一个B+树索引被划分成两个段,一个叶子节点段,一个非叶子节点段,这样叶子节点就可以被尽可能的存到一起,非叶子节点被尽可能的存到一起。每一个段对应一个 INODE Entry 结构,这个INODE Entry 结构描述了这个段的各种信息,比如段的ID,段内的各种链表基节点,零散页面的页号有哪些等信息(具体该结构中每个属性的意思大家可以到表空间那一章里再次重温一下)。我们前面也说过,为了定位一个 INODE Entry,设计InnoDB的大佬设计了一个 Segment Header 的结构:
?
整个Segment Header占用10个字节大小,各个属性的意思如下:
Space ID of the INODE Entry:INODE Entry结构所在的表空间ID。
Page Number of the INODE Entry:INODE Entry结构所在的页面页号。
Byte Offset of the INODE Ent:INODE Entry结构在该页面中的偏移量
知道了表空间ID、页号、页内偏移量,不就可以唯一定位一个INODE Entry的地址了么~
Undo Log Segment Header
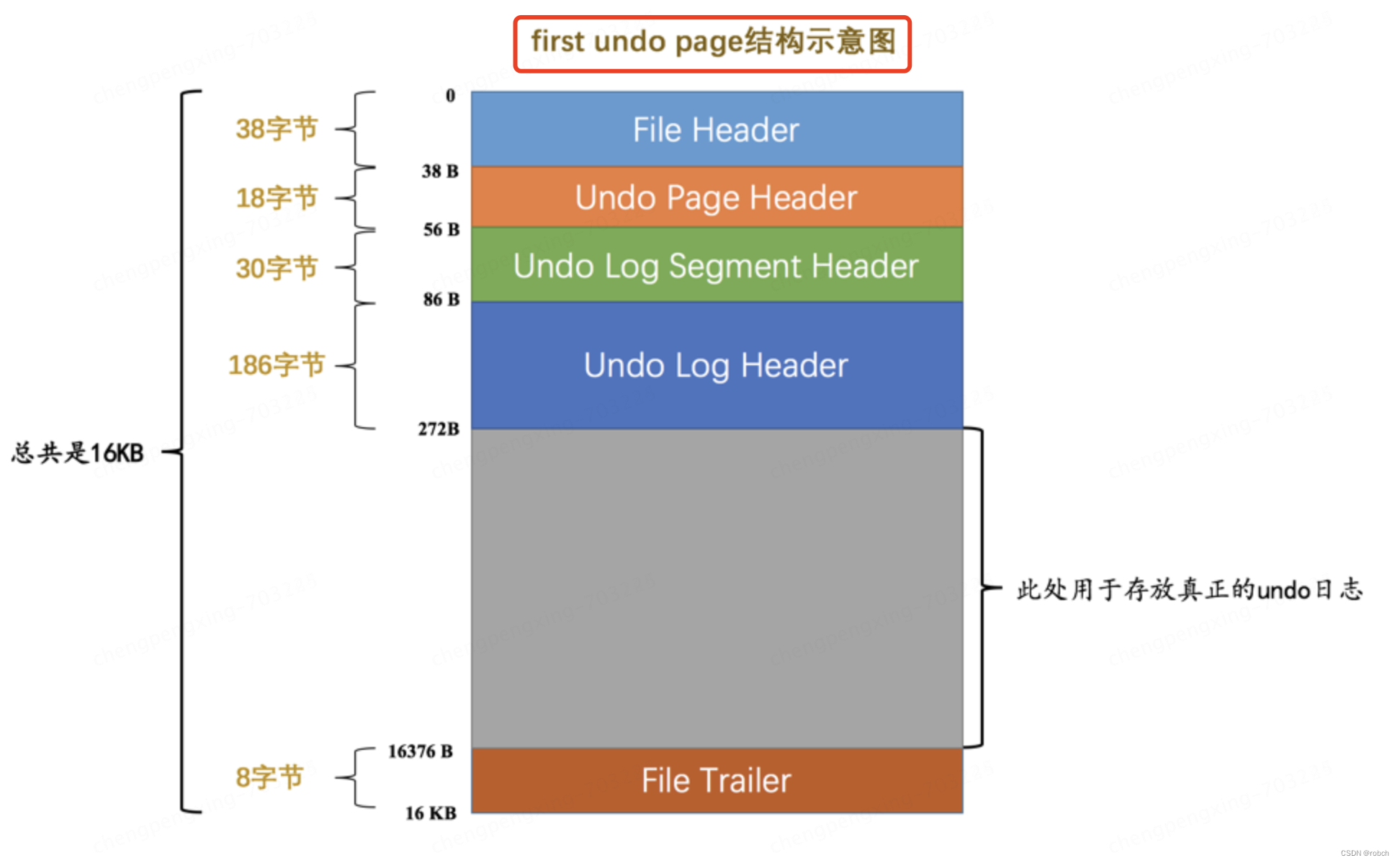
设计InnoDB的大佬规定,每一个Undo页面链表都对应着一个段,称之为Undo Log Segment 。也就是说链表中的页面都是从这个段里边申请的 ,所以他们在Undo页面链表的第一个页面,也就是上面提到的 first undo page 中设计了一个称之为 Undo Log Segment Header 的部分,这个部分中包含了该链表对应的段的 segment header 信息以及其他的一些关于这个段的信息,所以Undo页面链表的第一个页面其实长这样:
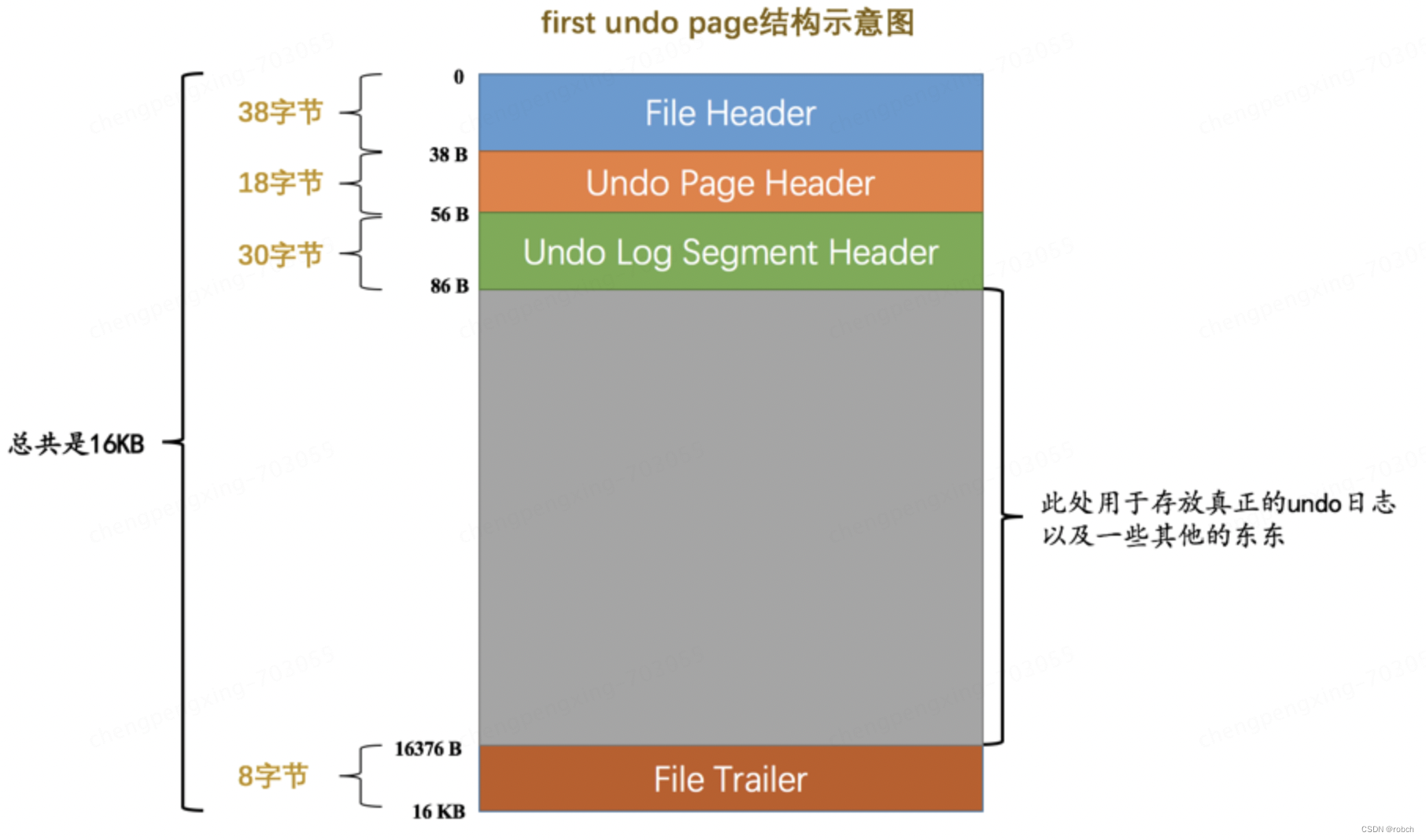
可以看到这个Undo链表的第一个页面比普通页面多了个Undo Log Segment Header,我们来看一下它的结构:

Undo Log Header
一个事务在向Undo页面中写入undo日志时的方式是十分简单暴力的,就是直接往里怼,写完一条紧接着写另一条,各条undo日志之间是亲密无间的。写完一个Undo页面后,再从段里申请一个新页面,然后把这个页面插入到Undo页面链表中,继续往这个新申请的页面中写。设计InnoDB的大佬认为同一个事务向一个Undo页面链表中写入的undo日志算是一个组,比方说我们上面介绍的trx 1由于会分配3个Undo页面链表,也就会写入3个组的undo日志;trx 2由于会分配2个Undo页面链表,也就会写入2个组的undo日志。
回滚段-Rollback Segment Header 页面
我们现在知道一个事务在执行过程中最多可以分配4个 Undo 页面链表,在同一时刻不同事务拥有的 Undo 页面链表是不一样的,所以在同一时刻系统里其实可以有许许多多个 Undo 页面链表存在。为了更好的管理这些链表,设计InnoDB的大佬又设计了一个称之为 Rollback Segment Header 的页面,在这个页面中存放了各个 Undo 页面链表的 first undo page 的页号,他们把这些页号称之为 undo slot 。
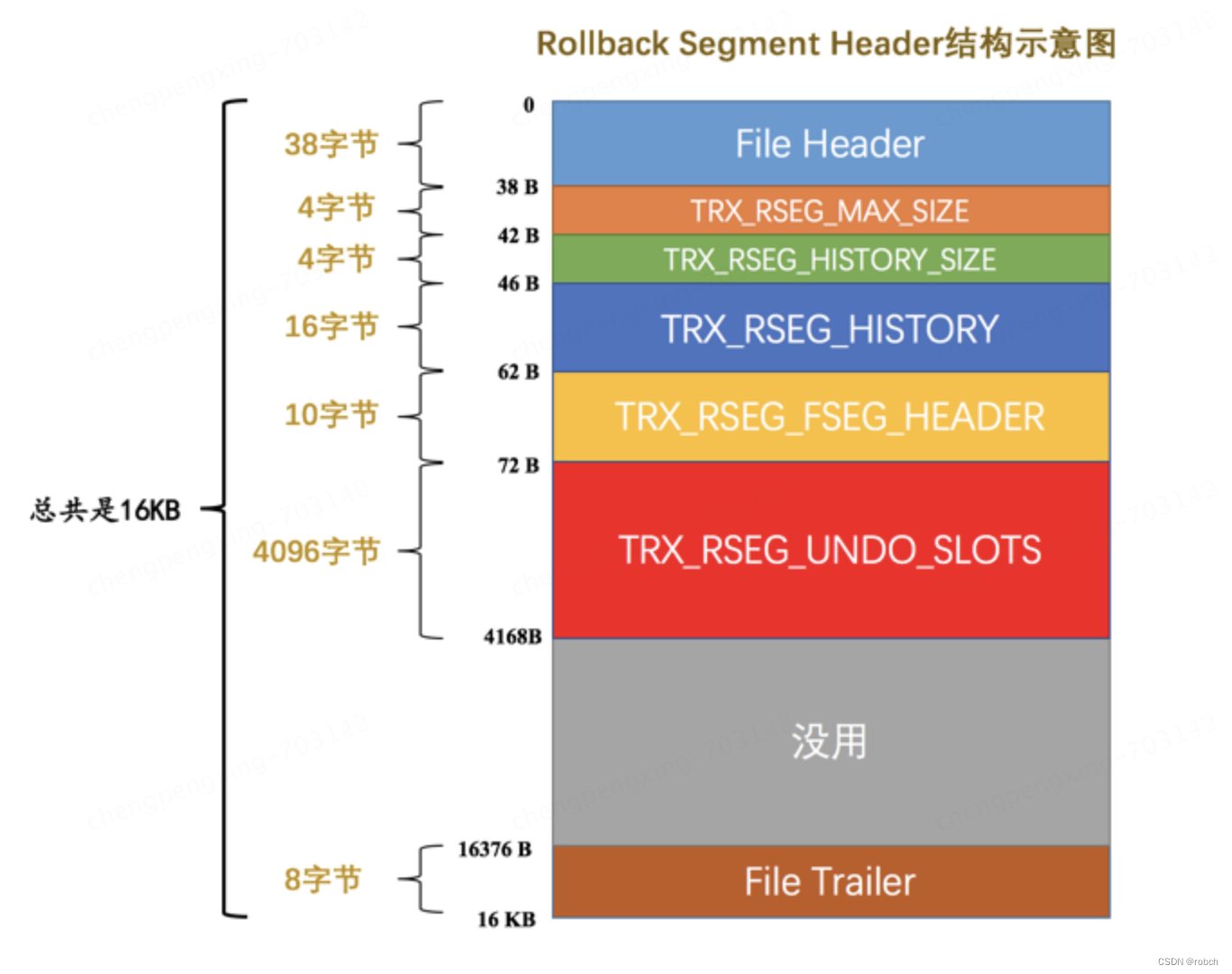
设计InnoDB的大佬规定,每一个 Rollback Segment Header 页面都对应着一个段,这个段就称为Rollback Segment,翻译过来就是回滚段。与我们之前介绍的各种段不同的是,这个Rollback Segment里其实只有一个页面(这可能是设计InnoDB的大佬们的一种洁癖,他们可能觉得为了某个目的去分配页面的话都得先申请一个段,或者他们觉得虽然目前版本的MySQL里Rollback Segment里其实只有一个页面,但可能之后的版本里会增加页面也说不定)。
从回滚段中申请Undo页面链表
初始情况下,由于未向任何事务分配任何Undo页面链表,所以对于一个Rollback Segment Header页面来说,它的各个undo slot都被设置成了一个特殊的值:FIL_NULL(对应的十六进制就是0xFFFFFFFF),表示该undo slot不指向任何页面。
随着时间的流逝,开始有事务需要分配Undo页面链表了,就从回滚段的第一个undo slot开始,看看该undo slot的值是不是FIL_NULL:
- 如果是FIL_NULL,那么在表空间中新创建一个段(也就是Undo Log Segment),然后从段里申请一个页面作为Undo页面链表的 first undo page,然后把该 undo slot 的值设置为刚刚申请的这个页面的地址,这样也就意味着这个undo slot被分配给了这个事务。
- 如果不是 FIL_NULL,说明该 undo slo t已经指向了一个undo链表,也就是说这个 undo slot 已经被别的事务占用了,那就跳到下一个undo slot,判断该undo slot的值是不是FIL_NULL,重复上面的步骤。
一个Rollback Segment Header页面中包含1024个undo slot,如果这1024个undo slot的值都不为FIL_NULL,这就意味着这1024个undo slot都已经名花有主(被分配给了某个事务),此时由于新事务无法再获得新的Undo页面链表,就会回滚这个事务并且给用户报错:
Too many active concurrent transactions
用户看到这个错误,可以选择重新执行这个事务(可能重新执行时有别的事务提交了,该事务就可以被分配Undo页面链表了)。
undo 日志在崩溃时的作用???
redo 日志最终是需要写在磁盘里的,
undo 日志是存在内存里的,但是写 undo 页对应 的 redo 是在磁盘里的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 函数栈帧的创建与销毁【此一篇,足以让卿彻底扫盲】
- VMware17 下载安装教程
- uniapp|微信小程序:隐私保护指引说明
- 最小二乘法的简介及应用实例
- 聊聊 Jetpack Compose 的 “自定义布局” -- SubcomposeLayout()
- 一站式解决方案!Electron、Vite和Vue 3助你打造功能丰富桌面应用
- 程序在FLASH中的执行效率比RAM中高?
- 使用Python进行Yolo目标检测的带txt标签进行数据增强
- Python:将print内容写入文件
- Underscore骨骼