[基本功]决策树
决策树
什么时候结束划分?
- 当前结点包含的样本全属于同一类别,无需划分
- 当前属性值为空,或是所有样本在所有属性上取值相同,无法划分
- 当前结点包含的样本集合为空,不能划分
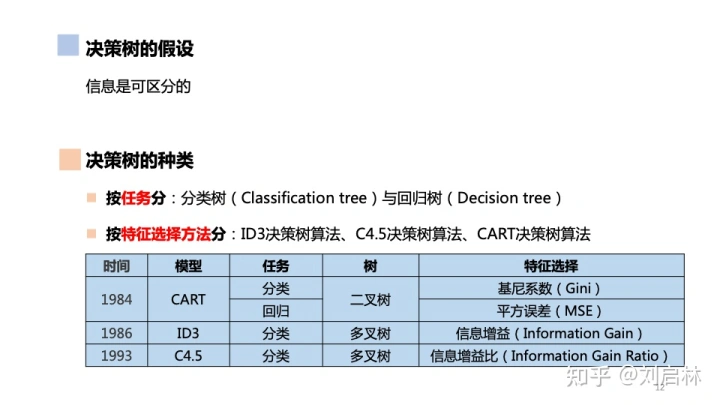
如何选择最优划分属性?
-
信息增益(ID3)
- 信息熵,可以度量样本集合纯度
E n t ( D ) = ? ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent(D)=-\sum_{k=1}^{|y|}p_klog_2p_k Ent(D)=?k=1∑∣y∣?pk?log2?pk?
- 熵越小,则D的纯度越高
- 用A属性对D样本集合进行划分,得到的信息增益为:
- 信息增益准则对可取值数目较多的属性有所偏好(比如ID,一人一个)
- 【必须离散属性,多叉树或二叉树】
-
增益率(C4.5)
- 增益率准则对可取值数目较少的属性有所偏好,因此C4.5并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性。再从中选择增益率最高的。
- 【可连续可离散,多叉树或二叉树】
-
基尼指数(CART)
-
分类和回归都可用
- 数据集D的基尼值:
G i n i ( p ) = ∑ k = 1 K p k ( 1 ? p k ) = 1 ? ∑ k = 1 K p k 2 ( 越大越不纯 ) Gini(p)=\sum_{k=1}^Kp_k(1-p_k)=1-\sum_{k=1}^Kp_k^2(越大越不纯) Gini(p)=k=1∑K?pk?(1?pk?)=1?k=1∑K?pk2?(越大越不纯)
-
属性A的基尼指数:
G i n i _ i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) Gini\_index(D,a)=\sum_{v=1}^V\frac{|D^v|}{|D|}Gini(D^v) Gini_index(D,a)=v=1∑V?∣D∣∣Dv∣?Gini(Dv) -
选最小的
-
【可连续可离散,必须二叉树】
-
如何剪枝?
-
剪枝可以防止决策树过拟合,提高泛化性能
-
预剪枝,若当前节点的划分不能带来泛化性能提升,则停止划分并将当前结点标记为叶结点
-
优点:降低了过拟合风险,显著减少训练时间开销和测试时间开销
-
缺点:有些分支当前划分虽不能提升泛化性能,但在其基础上的后续划分却有可能导致性能显著提高,预剪枝基于贪心本质,带来了欠拟合风险
-
-
后剪枝,生成决策树后,自底向上对非叶节点考察,用单一叶结点代替整个子树
- 优点:欠拟合风险很小,泛化性能往往优于预剪枝决策树
- 缺点:训练时间开销比未剪枝决策树和预剪枝决策树大很多
-
其他
-
连续值处理
-
C4.5:二分法
-
对连续属性a,可考察包含n-1个元素的候选划分点集合
T a = { a i + a i + 1 2 ∣ 1 < = i < = n ? 1 } T_a=\{\frac{a_i+a_{i+1}}2|1<=i<=n-1\} Ta?={2ai?+ai+1??∣1<=i<=n?1} -
与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性
-
-
缺失值处理
- C4.5有自己的一套处理缺失值的方法
-
噪音数据可能影响决策树,在数据带有噪声的情况下,通过剪枝可将决策树的泛化性能提高25%
-
多变量决策树
- 非叶节点不再是仅对某个属性,而是对属性的线性组合进行测试
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 鸿蒙开发已解决-ArkTS@State 数组无法触发重绘
- Python_xpath_解析
- [计算机提升] 创建和管理一般共享文件夹
- 麒麟系统安装docker、mysql、clickhouse
- 实验用python实现决策树和随机森林分类
- centos如何下载chrome
- echarts 实现仪盘表效果
- Python开发神器
- PageHelper分页插件的使用
- with torch.no_grad()在Pytorch中的应用