如何使用pytorch定义一个多层感知神经网络模型——拓展到所有模型知识
# 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
import torchvision.transforms as transforms
import torchvision.datasets as datasets
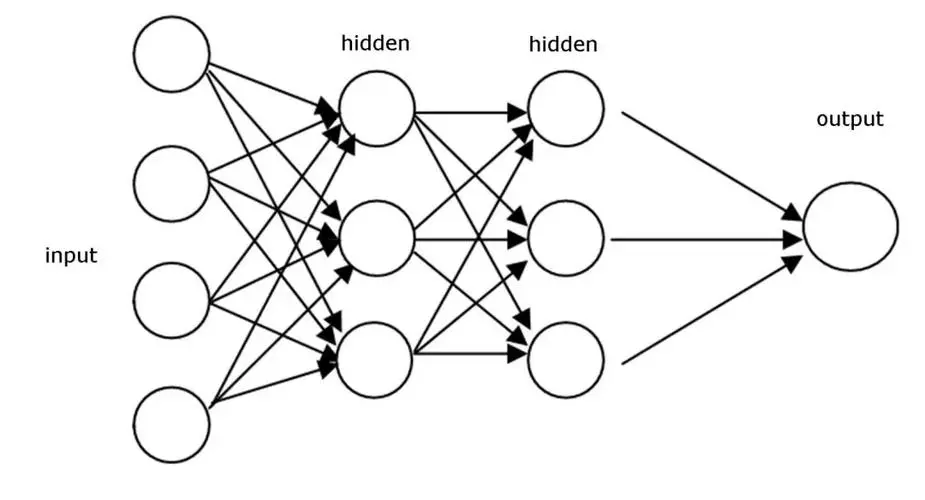
# 定义MLP模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
# 创建一个顺序的层序列:包括一个扁平化层、两个全连接层和ReLU激活
self.layers = nn.Sequential(
nn.Flatten(), # 将28x28的图像扁平化为784维向量
nn.Linear(28 * 28, 512), # 第一个全连接层,784->512
nn.ReLU(), # ReLU激活函数
nn.Linear(512, 256), # 第二个全连接层,512->256
nn.ReLU(), # ReLU激活函数
nn.Linear(256, 10) # 第三个全连接层,256->10 (输出10个类别)
)
def forward(self, x):
return self.layers(x) # 定义前向传播
# 加载FashionMNIST数据集
# 定义图像的预处理:转换为Tensor并标准化
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# 下载FashionMNIST数据并应用转换
dataset = datasets.FashionMNIST(root="./data", train=True, transform=transform, download=True)
# 划分数据集为训练集和验证集
train_len = int(0.8 * len(dataset)) # 计算80%的长度作为训练数据
val_len = len(dataset) - train_len # 剩下的20%作为验证数据
train_dataset, val_dataset = random_split(dataset, [train_len, val_len])
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 训练数据加载器,批量大小64,打乱数据
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False) # 验证数据加载器,批量大小64,不打乱
# 初始化模型、损失函数和优化器
model = MLP() # 创建MLP模型实例
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器
# 训练模型
epochs = 5 # 定义训练5个epochs
for epoch in range(epochs):
model.train() # 将模型设置为训练模式
for inputs, labels in train_loader: # 从训练加载器中获取批次数据
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
optimizer.zero_grad() # 清除之前的梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新权重
# 在每个epoch结束时验证模型性能
model.eval() # 将模型设置为评估模式
total_correct = 0
with torch.no_grad(): # 不计算梯度,节省内存和计算量
for inputs, labels in val_loader: # 从验证加载器中获取批次数据
outputs = model(inputs) # 前向传播
_, predicted = outputs.max(1) # 获取预测的类别
total_correct += (predicted == labels).sum().item() # 统计正确的预测数量
accuracy = total_correct / val_len # 计算验证准确性
print(f"Epoch {epoch + 1}/{epochs} - Validation accuracy: {accuracy:.4f}") # 打印验证准确性
nn.Flatten() 是一个特殊的层,它将多维的输入数据“展平”为一维数据。这在处理图像数据时尤为常见,因为图像通常是多维的(例如,一个大小为28x28的灰度图像在PyTorch中会有一个形状为[28, 28]的张量)。
在神经网络的某些层,特别是全连接层(如nn.Linear)之前,通常需要对数据进行扁平化处理。因为全连接层期望其输入是一维的(或者更准确地说,它期望输入的最后一个维度对应于特征,其他维度对应于数据的批次)。
为了更具体,让我们看一个例子:
考虑一个大小为[batch_size, 28, 28]的张量,这可以看作是一个batch_size数量的28x28图像的批次。当我们传递这个批次的图像到一个nn.Linear(28*28, 512)层时,我们需要先将图像展平。也就是说,每个28x28的图像需要转换为长度为784的一维向量。因此,输入数据的形状会从[batch_size, 28, 28]变为[batch_size, 784]。
nn.Flatten()就是做这个转换的。在这个特定的例子中,它会将[batch_size, 28, 28]的形状转换为[batch_size, 784]。
总结一下:nn.Flatten()用于将多维输入数据转换为一维,从而使其可以作为全连接层(如nn.Linear)的输入。
-
transforms.Compose:
这是一个简单的方式来链接(组合)多个图像转换操作。它会按照提供的顺序执行列表中的每个转换。 -
transforms.ToTensor():
这个转换将PIL图像或NumPy的ndarray转换为FloatTensor。并且它将图像的像素值范围从0-255变为0-1。简言之,它为我们完成了数据类型和值范围的转换。 -
transforms.Normalize((0.5,), (0.5,)):
这个转换标准化张量图像。给定的参数是均值和标准差。在这里,均值和标准差都是0.5。
使用给定的均值和标准差,这会将值范围从[0,1]转换为[-1,1]。
整个transform的目的是:
- 将图像数据从PIL格式转换为PyTorch张量格式。
- 将像素值从[0,255]范围转换为[0,1]范围。
- 使用给定的均值和标准差进一步标准化像素值,使其范围为[-1,1]。
初始化模型、损失函数和优化器
-
model = MLP():
- 这里我们实例化了我们之前定义的MLP类,从而创建了一个多层感知器(MLP)模型。
-
criterion = nn.CrossEntropyLoss():
- 在分类任务中,交叉熵损失函数 (CrossEntropyLoss) 是最常用的损失函数之一。它衡量真实标签和预测之间的差异。
- 注意:CrossEntropyLoss在内部执行softmax操作,因此模型输出应该是未经softmax处理的原始分数(logits)。
-
optimizer = optim.Adam(model.parameters(), lr=0.001):
- 优化器负责更新模型的权重,基于计算的梯度来减少损失。
- Adam是一种流行的优化器,它结合了两种扩展的随机梯度下降:Adaptive Gradients 和 Momentum。
- model.parameters()是传递给优化器的,它告诉优化器应该优化/更新哪些权重。
- lr=0.001定义了学习率,这是一个超参数,表示每次权重更新的步长大小。
常见的相关资料解答
- 模型 (在torch.nn中):
除了基本的MLP外,PyTorch提供了很多预定义的层和模型,常见的包括:
Convolutional Neural Networks (CNNs):
nn.Conv2d: 2D卷积层,常用于图像处理。
nn.Conv3d: 3D卷积层,常用于视频处理或医学图像。
nn.MaxPool2d: 最大池化层。
Recurrent Neural Networks (RNNs):
nn.RNN: 基本的RNN层。
nn.LSTM: 长短时记忆网络。
nn.GRU: 门控循环单元。
Transformer Architecture:
nn.Transformer: 用于自然语言处理任务的Transformer模型。
Batch Normalization, Dropout等:
nn.BatchNorm2d: 批量归一化。
nn.Dropout: 防止过拟合的正则化方法。
- 损失函数 (在torch.nn中):
常见的损失函数有:
Classification:
nn.CrossEntropyLoss: 用于分类任务的交叉熵损失。
nn.BCEWithLogitsLoss: 用于二分类任务的二元交叉熵损失,包括内部的sigmoid操作。
nn.MultiLabelSoftMarginLoss: 用于多标签分类任务。
Regression:
nn.MSELoss: 均方误差,用于回归任务。
nn.L1Loss: L1误差。
Generative models:
nn.KLDivLoss: Kullback-Leibler散度,常用于生成模型。
- 优化器 (在torch.optim中):
常见的优化器有:
optim.SGD: 随机梯度下降。
optim.Adam: 一个非常受欢迎的优化器,结合了AdaGrad和RMSProp的特点。
optim.RMSprop: 常用于深度学习任务。
optim.Adagrad: 自适应学习率优化器。
optim.Adadelta: 类似于Adagrad,但试图解决其快速降低学习率的问题。
optim.AdamW: Adam的变种,加入了权重衰减。
每文一语
学习是不断的发展的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言中char类型的变量在计算机的存储以及存储的二进制数之间的关系
- 能源互联网:照亮我们绿色、智能的未来
- 集简云新增邮件发送功能,适用多种创意场景并提升邮件发送效率
- python使用贪心算法解决作业调度问题
- 监督学习 - 多层感知机回归(Multilayer Perceptron Regression,MLP Regression)
- 大一C语言程序细节复盘2
- CC工具箱使用指南:【应用符号系统】
- 自然语言处理-情感分析及数据集
- 1.[BUU][极客大挑战 2019]EasySQL1
- 勇哥带您手搓一个信息发布系统CMS(3)--thymeleaf使用中通用方法设计