LLM之LangChain(三)| LangChain和LlamaIndex与4个任务的比较

? ? ? ?大模型已经发展一年了,然而大模型的幻觉问题一直令人诟病,其中检索增强生成(RAG)是缓解幻觉比较有效的方式。目前有两个基于LLM的应用框架可以很容易实现RAG Pipeline,分别是LangChain和LlamaIndex,本文将在四个任务上对比一下这两个框架的不同实现。
LangChain:一个使用LLM开发应用程序的通用框架。
?LlamaIndex:一个专门用于构建RAG系统的框架。
? ? ? ? 两个框架的基本对比,如下图所示:
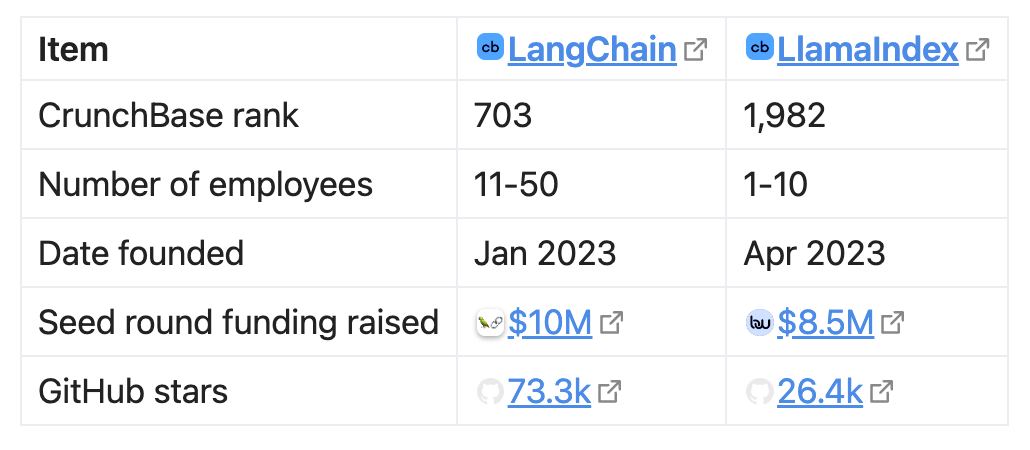
? ? ? ?尽管LlamaIndex的目标市场比LangChain要小得多(使用Github stars表示社区的活跃度),但其资金数额接近LangChain。LangChain还提供了更多企业级的产品(比如LangServe、LangSmith等等)。本文将使用两个框架并行完成一些基本任务,通过并排展示代码片段,希望能帮助您在自己的RAG聊天机器人中做出更明智的决定。
任务一:使用本地LLM创建聊天机器人
? ? ? ?为避免每次运行脚本时,框架都加载千兆模型到内存中,我们使用一个与OpenAI兼容的LLM推理 API
??? ???a)以下是使用LlamaIndex的实现方式:
from llama_index.llms import ChatMessage, OpenAILikellm = OpenAILike(api_base="http://localhost:1234/v1",timeout=600, # secsapi_key="loremIpsum",is_chat_model=True,context_window=32768,)chat_history = [ChatMessage(role="system", content="You are a bartender."),ChatMessage(role="user", content="What do I enjoy drinking?"),]output = llm.chat(chat_history)print(output)
? ????? b)以下是使用LangChain的实现方式:
from langchain.schema import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIllm = ChatOpenAI(openai_api_base="http://localhost:1234/v1",request_timeout=600, # secs, I guess.openai_api_key="loremIpsum",max_tokens=32768,)chat_history = [SystemMessage(content="You are a bartender."),HumanMessage(content="What do I enjoy drinking?"),]print(llm(chat_history))
? ? ? ?对于这两者,OpenAI的API Key是必须的。
? ? LangChain区分了可聊天LLM(ChatOpenAI)和仅完成LLM(OpenAI),而LlamaIndex在构造函数中使用is_chat_model参数对其进行控制。
? ? LlamaIndex区分了官方的OpenAI端点和OpenAILike端点,而LangChain则通过openai_api_base参数确定将请求发送到哪里。
? ? ? ?虽然LlamaIndex使用role参数标记聊天消息,但LangChain使用单独的类。
? ? ? ?到目前为止,这两个框架的情况看起来并没有太大的不同。
任务二:为本地文件构建RAG系统
? ? ? ?一旦有了LLM,我们就可以读取本地文件夹中的文件来构建一个简单的RAG系统。
? ? ? ? ??以下是使用LlamaIndex的实现方法:
from llama_index import ServiceContext, SimpleDirectoryReader, VectorStoreIndex?service_context = ServiceContext.from_defaults(embed_model="local",llm=llm, # This should be the LLM initialized in the task above.)documents = SimpleDirectoryReader(input_dir="mock_notebook/",).load_data()index = VectorStoreIndex.from_documents(documents=documents,service_context=service_context,)engine = index.as_query_engine(service_context=service_context,)output = engine.query("What do I like to drink?")print(output)
? ? ? ? 下面是使用LangChain的实现方式,代码量将翻一番,不过还可以接受:
from langchain_community.document_loaders import DirectoryLoader# pip install "unstructured[md]"loader = DirectoryLoader("mock_notebook/", glob="*.md")docs = loader.load()from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = text_splitter.split_documents(docs)from langchain_community.embeddings.fastembed import FastEmbedEmbeddingsfrom langchain_community.vectorstores import Chromavectorstore = Chroma.from_documents(documents=splits, embedding=FastEmbedEmbeddings())retriever = vectorstore.as_retriever()from langchain import hub# pip install langchainhubprompt = hub.pull("rlm/rag-prompt")def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)from langchain_core.runnables import RunnablePassthroughrag_chain = ({"context": retriever | format_docs, "question": RunnablePassthrough()}| prompt| llm # This should be the LLM initialized in the task above.)print(rag_chain.invoke("What do I like to drink?"))
? ? ? 这些代码清楚地说明了这两个框架之间的不同抽象级别。LlamaIndex使用一个名为“query_engine”的包来包装RAG管道,但LangChain会展示内部组件,包括检索到的文档的连接符、提示模板“based on X please answer Y”,以及链本身(如上面的LCEL所示)。
? ? ? ?当使用LangChain时,你必须在第一次尝试时就确切地知道你想要什么,例如,调用from_documents的位置。LlamaIndex不需要显式选择存储后端的情况下可以使用矢量存储索引,而LangChain似乎建议您立即选择一个(每个人在使用LangChain从文档中创建矢量索引时,似乎都明确选择了后端)。
? ? ? ?更有趣的是,尽管LangChain和LlamaIndex都在提供类似Huggingface Hub的云服务(即LangSmith Hub和LlamaHub)。注意的是使用LangChain的hub.pull调用时,它只下载一个简短的文本模板,内容如下:
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don’t know the answer, just say that you don’t know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
任务三:构建一个支持RAG的聊天机器人
? ? ? 在第一个任务中,我们构建了一个可以对话但不太了解用户的意图;在第二个例子中,我们构建了一个了解你但不能保留聊天历史数据。现在让我们把这两者结合起来。
? ? ? ?使用LlamaIndex,只需将as_query_engine与as_chat_engine交换即可:
# Everything from above, till and including the creation of the index.engine = index.as_chat_engine()output = engine.chat("What do I like to drink?")print(output) # "You enjoy drinking coffee."output = engine.chat("How do I brew it?")print(output) # "You brew coffee with a Aeropress."
? ? ? ? 对于LangChain,我们需要详细说明。按照官方教程(https://python.langchain.com/docs/expression_language/cookbook/retrieval),让我们先定义记忆:
# Everything above this line is the same as that of the last task.from langchain_core.runnables import RunnablePassthrough, RunnableLambdafrom langchain_core.messages import get_buffer_stringfrom langchain_core.output_parsers import StrOutputParserfrom operator import itemgetterfrom langchain.memory import ConversationBufferMemoryfrom langchain.prompts.prompt import PromptTemplatefrom langchain.schema import format_documentfrom langchain_core.prompts import ChatPromptTemplatememory = ConversationBufferMemory(return_messages=True, output_key="answer", input_key="question")
大致步骤如下:
1.在LLM开始时,从内存中加载聊天历史记录。
load_history_from_memory = RunnableLambda(memory.load_memory_variables) | itemgetter("history")load_history_from_memory_and_carry_along = RunnablePassthrough.assign(chat_history=load_history_from_memory)
2.要求LLM使用上下文:“Taking the chat history into consideration, what should I look for in my notes to answer this question?”来丰富问题。
rephrase_the_question = ({"question": itemgetter("question"),"chat_history": lambda x: get_buffer_string(x["chat_history"]),}| PromptTemplate.from_template("""You're a personal assistant to the user.Here's your conversation with the user so far:{chat_history}Now the user asked: {question}To answer this question, you need to look up from their notes about """)| llm| StrOutputParser())
PS:我们不能只是将两者连接起来,因为话题可能在对话中发生了变化,使聊天日志中的大多数语义信息变得无关紧要。
3.运行RAG管道。请注意,我们是如何通过暗示“我们作为用户将自己查找笔记”来欺骗LLM的,但事实上,我们现在要求LLM承担重任。我感觉很糟糕。
retrieve_documents = {"docs": itemgetter("standalone_question") | retriever,"question": itemgetter("standalone_question"),}
4.向LLM提问:“Taking the retrieved documents as reference (and — optionally — the conversation so far), what would be your response to the user’s latest question?”
def _combine_documents(docs):prompt = PromptTemplate.from_template(template="{page_content}")doc_strings = [format_document(doc, prompt) for doc in docs]return "\n\n".join(doc_strings)compose_the_final_answer = ({"context": lambda x: _combine_documents(x["docs"]),"question": itemgetter("question"),}| ChatPromptTemplate.from_template("""You're a personal assistant.With the context below:{context}To the question "{question}", you answer:""")| llm)
5.将最终响应附加到聊天历史记录中。
# Putting all 4 stages together...final_chain = (load_history_from_memory_and_carry_along| {"standalone_question": rephrase_the_question}| retrieve_documents| compose_the_final_answer)# Demo.inputs = {"question": "What do I like to drink?"}output = final_chain.invoke(inputs)memory.save_context(inputs, {"answer": output.content})print(output) # "You enjoy drinking coffee."inputs = {"question": "How do I brew it?"}output = final_chain.invoke(inputs)memory.save_context(inputs, {"answer": output.content})print(output) # "You brew coffee with a Aeropress."
任务四:Agent
? ? ? ?如果你把与你交谈的LLM角色视为一个人,RAG管道可以被认为是这个人使用的工具。一个人可以使用多个工具,LLM也是如此。你可以使用它提供搜索谷歌、查找维基百科、查看天气预报等工具。这样,你的聊天机器人就可以回答其直接知识之外的问题。
? ? ? ?随着越来越多工具的出现,需要决定使用哪些工具,以及使用顺序。这种能力被称为“agency”。因此,拥有代理权的LLM的角色被称为“agent”。
Agent有很多种类,最常见的就是ReAct范式(https://www.promptingguide.ai/techniques/react)
? ? ? ? 下面是LlamaIndex Agent的实现方式:
# Everything above this line is the same as in the above two tasks,# till and including where `notes_query_engine` is defined.# Let's convert the query engine into a tool.from llama_index.tools import ToolMetadatafrom llama_index.tools.query_engine import QueryEngineToolnotes_query_engine_tool = QueryEngineTool(query_engine=notes_query_engine,metadata=ToolMetadata(name="look_up_notes",description="Gives information about the user.",),)from llama_index.agent import ReActAgentagent = ReActAgent.from_tools(tools=[notes_query_engine_tool],llm=llm,service_context=service_context,)output = agent.chat("What do I like to drink?")print(output) # "You enjoy drinking coffee."output = agent.chat("How do I brew it?")print(output) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."
? ? ? ?请注意,对于我们的后续问题“我如何冲泡咖啡”,agent的回答与查询引擎不同,这是因为agent可以自己决定是否从我们的笔记中查找。如果他们有足够的信心回答问题,agent可能不使用任何工具。关于“我如何……”的问题可以用两种方式来解释:要么是关于通用选项,要么是关于事实回忆。显然,agent选择了前一种方式来理解它,而查询引擎(有责任从索引中查找文档)不得不选择后一种方式。
? ? ? ? LangChain针对Agent提供高级抽象:
# Everything above is the same as in the 2nd task, till and including where we defined `rag_chain`.# Let's convert the chain into a tool.from langchain.agents import AgentExecutor, Tool, create_react_agenttools = [Tool(name="look_up_notes",func=rag_chain.invoke,description="Gives information about the user.",),]react_prompt = hub.pull("hwchase17/react-chat")agent = create_react_agent(llm, tools, react_prompt)agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools)result = agent_executor.invoke({"input": "What do I like to drink?", "chat_history": ""})print(result) # "You enjoy drinking coffee."result = agent_executor.invoke({"input": "How do I brew it?","chat_history": "Human: What do I like to drink?\nAI: You enjoy drinking coffee.",})print(result) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."
? ? ? ?尽管仍然需要手动管理聊天历史记录,但与创建RAG链相比,创建agent要容易得多,create_react_agent和AgentExecutor可以完成大部分Agent功能。
总结
? ? ? LlamaIndex和LangChain是用于构建LLM应用程序的两个框架。虽然LlamaIndex专注于RAG用例,但LangChain似乎应用更广泛。但它们在实践中有何不同?在这篇文章中,我们比较了两个框架在完成四个常见任务时的表现:
-
连接到本地LLM实例并构建聊天机器人。
-
索引本地文件并构建RAG系统。
-
将以上两者结合起来,制作一个具有RAG功能的聊天机器人。
-
将聊天机器人转换为Agent,这样它可以使用更多的工具并进行简单的推理。
参考文献:
[1]?https://lmy.medium.com/comparing-langchain-and-llamaindex-with-4-tasks-2970140edf33
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 阿里云服务器实例选择参考:经济型、通用算力型与通用型的比较
- go学习笔记
- 科普-电子合同签署,这三步不能忽视
- ArcGIS Pro SDK 将几何输出为要素
- 网络工程师:计算机基础知识面试题(二)
- TS在vue3中的初使用
- auto关键字的含义以及常见用法,C++11中的关键字
- python:PyCharm更改.PyCharm配置文件夹存储位置
- Go : ssh操作(五)功能集合
- 中职网络安全应急响应—Server2228