【PaperReading】5. Open-Vocabulary SAM
| Category | Content |
| 论文题目 | Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively |
| 作者 | Haobo Yuan1 Xiangtai Li1 Chong Zhou1 Yining Li2 Kai Chen2 Chen Change Loy1 1S-Lab, Nanyang Technological University 2Shanghai Artificial Intelligence Laboratory {haobo.yuan, xiangtai.li, chong033, ccloy}@ntu.edu.sg {liyining, chenkai}@pjlab.org.cn Project page: https://www.mmlab-ntu.com/project/ovsam Code: https://github.com/HarborYuan/ovsam |
| 发表年份 | 2024 |
| 摘要 | 这篇论文介绍了一种在计算机视觉领域中用于交互式分割和识别的新方法。该方法结合了两个模型:分割任何模型(SAM)和CLIP(对比语言图像预训练),创建了开放词汇的SAM。这个模型通过结合SAM的分割能力和CLIP的现实世界识别能力,显著提高了计算效率。 |
| 引言 | 文章强调了在视觉基础模型领域整合不同模型的重要性,并介绍了SAM和CLIP模型的基本原理。 |
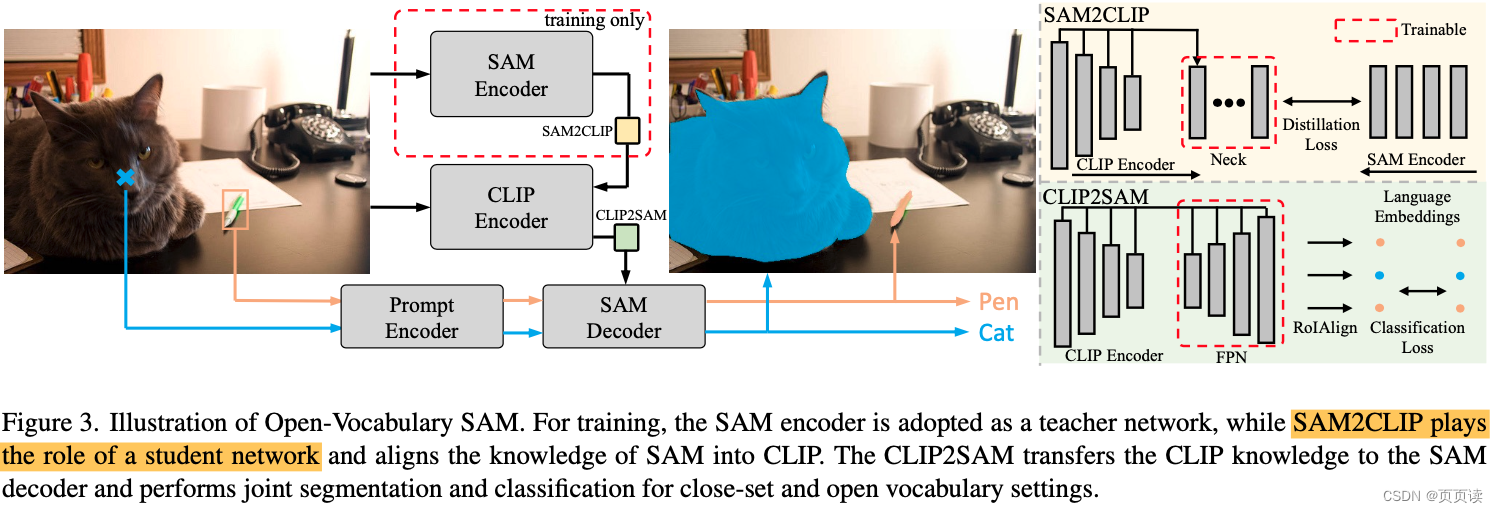
| 主要内容 | 详细讨论了开放词汇SAM模型的设计和实现方法。这个模型是通过整合两个先进的模型:分割任何模型(SAM)和CLIP(对比语言图像预训练)来构建的。SAM模型擅长于图像分割,而CLIP模型则在图像和文本的关联识别方面表现出色。论文的核心在于开发了两个模块——SAM2CLIP和CLIP2SAM——以实现这两个模型间的知识转移。 SAM2CLIP模块的主要功能是将SAM的图像分割能力传递给CLIP,这样CLIP不仅能识别图像中的对象,还能理解这些对象的确切边界。另一方面,CLIP2SAM模块则是将CLIP的强大语言-图像识别能力传递给SAM。这使得SAM不仅能分割图像,还能更准确地识别和理解图像中的对象。 这种双向知识转移使得开放词汇SAM模型能够有效地处理更复杂的图像分割和识别任务。论文还详细讨论了这种集成方法对模型性能的具体影响,以及如何优化这两个模块以实现更好的识别精度和分割效果。 |
| 实验 | 文中进行了多项实验,证明了开放词汇SAM在分割和识别任务上的优越性能。实验涵盖了不同的数据集和探测器,特别在COCO开放词汇基准上展示了其显著的性能提升。实验结果表明,与简单结合SAM和CLIP的基线方法相比,开放词汇SAM在处理小对象识别和多样化数据集方面表现出色。 |
| 结论 | 在结论部分,论文强调开放词汇SAM模型在交互式图像分割和识别领域中的创新和有效性。通过结合SAM和CLIP模型,研究展示了在处理多样化和复杂的图像场景时的显著性能提升。实验结果证实了这种集成方法在识别准确率和分割效果上的优势。该研究不仅提升了图像处理的能力,也为未来的视觉识别技术提供了新的研究方向和应用可能性。 |
| 阅读心得
| 这篇论文主要的亮点是他引入了两个模块:SAM2CLIP 和 CLIP2SAM,实现了CLIP和SAM的对齐,这种融合方法是隐式的,而不是简单的concat或者直接crop出来feature。更具有泛化性,文中说尤其对小目标提升显著,因为小目标如果用crop的方法出来的feature很小,会丢失很多信息。 其中本文中用到的adapter 是来自另外两篇工作:
本论文方法架构图:
|


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C Primer Plus 第6版 编程练习 chapter 14
- CSS 边框
- Spring Boot笔记2
- 30、卷积 - 参数 stride 的作用
- 使用Docker在centos7服务器部署SpringBoot程序
- 【RocketMQ系列九】SpringCloudStream整合RocketMQ
- AQS的详细解释
- 【Python】Python 正则表达式
- 基于遗传算法的微电网优化调度
- 每日一水:leetcode1576.替换所有的问号