【深度学习:LSTM Networks】了解 LSTM 网络
【深度学习:LSTM Networks】了解 LSTM 网络
循环神经网络
人类在思考时并不是每时每刻都从头开始。当你阅读这篇文章时,你会基于之前单词的理解来理解接下来的每个单词。你不会抛弃之前的所有内容,然后重新开始思考。你的思考是连续的。
传统的神经网络无法做到这一点,这是它们的一个主要缺点。例如,假设你想对电影中每个场景发生的事件类型进行分类。传统神经网络如何利用之前场景的信息来推理后续场景,这一点尚不清楚。
循环神经网络解决了这个问题。它们通过循环机制使信息能够持续存在于网络中。

在上图中,神经网络的一块 ,查看一些输入并输出一个值 。循环允许信息从网络的一个步骤传递到下一步。
这些循环让循环神经网络看起来有些神秘。然而,仔细思考一下,它们实际上与普通神经网络并没有太大区别。循环神经网络可以被视为同一个网络的多个副本,其中每个副本都将信息传递给下一个。考虑一下如果我们展开循环会发生什么:
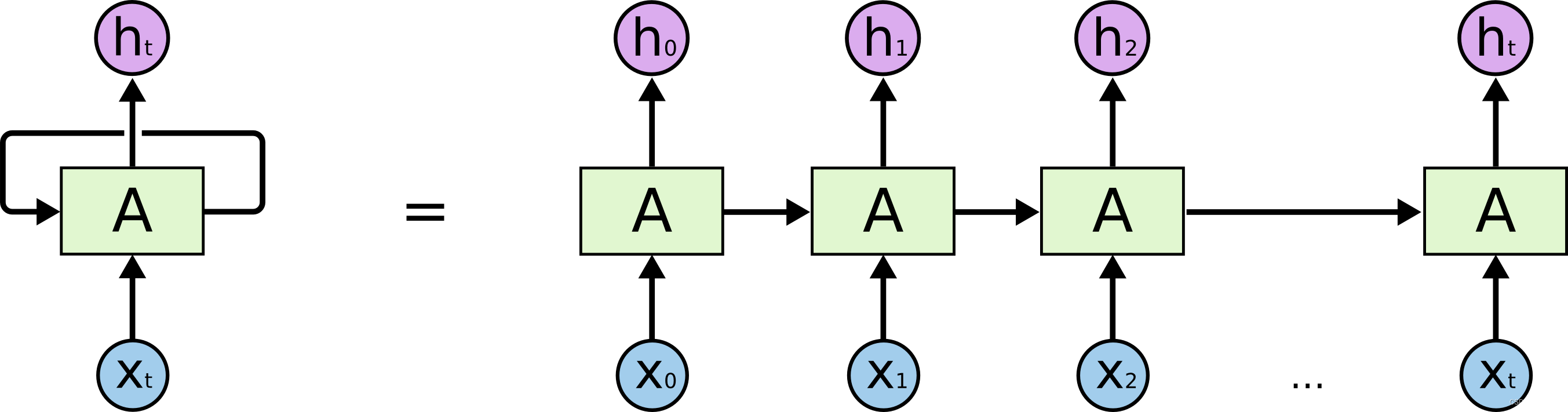
这种链状性质揭示了循环神经网络与序列和列表密切相关。它们是用于此类数据的神经网络的自然架构。
而且它们的确被广泛使用!在过去几年中,RNN在许多领域取得了惊人的成功,例如语音识别、语言建模、翻译和图像字幕等,例子数不胜数。我将把关于 RNN 可以实现的惊人壮举的讨论留给 Andrej Karpathy 的优秀博客文章《循环神经网络的不合理有效性》。但他们确实非常了不起。
这些成功背后的关键是“LSTM”——一种特殊类型的循环神经网络,它在许多任务上的表现远超传统模型。几乎所有激动人心的基于循环神经网络的成果都是通过LSTM实现的。本文将重点探讨这些LSTM。
长期依赖问题
RNN的一个吸引点是它们可能能将之前的信息与当前任务联系起来,比如利用前一个视频帧来理解当前帧。如果RNN能做到这点,那它们将非常有用。但是,真的能做到吗?这还有待观察。
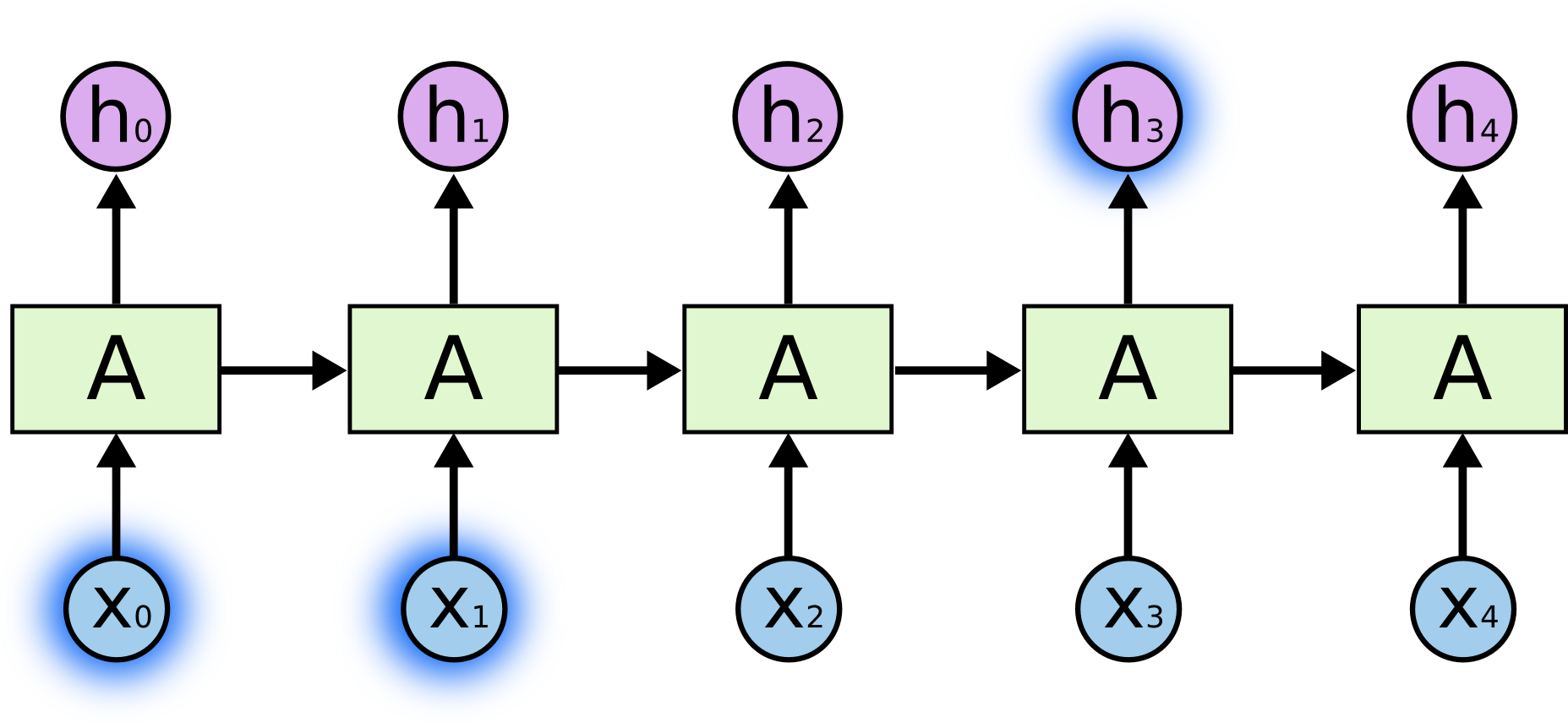
有时,我们只需要查看最近的信息来执行当前的任务。例如,考虑一个语言模型尝试根据之前的单词来预测下一个单词。如果我们试图预测“the clouds are in the sky”中的最后一个单词,我们不需要任何进一步的上下文——很明显下一个单词将是天空。在这种情况下,当相关信息与需要的信息之间的差距很小时,RNN 可以学习使用过去的信息。
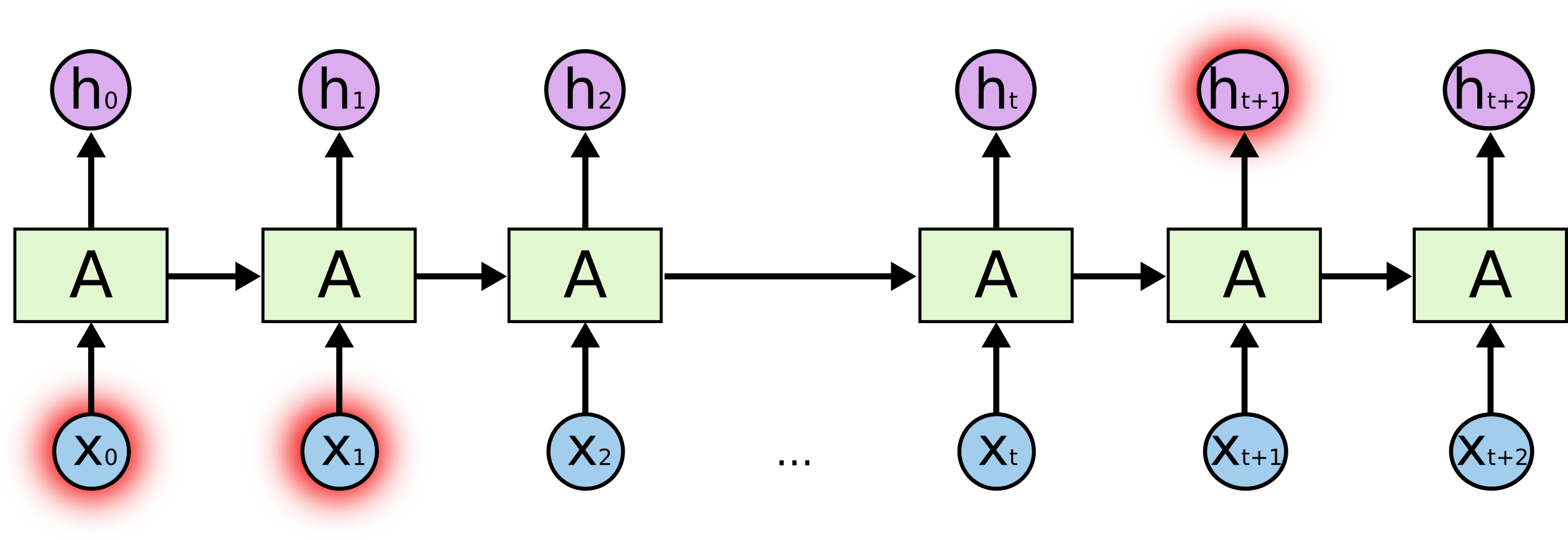
但也有一些情况我们需要更多背景信息。考虑尝试预测文本中的最后一个单词“我在法国长大……我说流利的法语。”最近的信息表明,下一个单词可能是一种语言的名称,但如果我们想缩小哪种语言的范围,我们需要更早的法国的上下文。相关信息与需要的信息点之间的差距完全有可能变得非常大。
不幸的是,随着差距的扩大,RNN 变得无法学习连接信息。
从理论上讲,RNN绝对具有处理这种“长期依赖关系”的能力。通过仔细选择参数,人类可以解决这类问题。然而,遗憾的是,在实际应用中,RNN似乎无法有效学习处理这些问题。 Hochreiter (1991) [德语] 和 Bengio 等人深入探讨了这个问题。 (1994),他发现了一些非常根本的原因来解释为什么这可能很困难。
幸运的是,LSTM并不面临这个问题!
相关知识传送门:
【深度学习:Recurrent Neural Networks】循环神经网络(RNN)的简要概述
LSTM 网络
长短期记忆网络(通常称为“LSTM”)是一种特殊类型的RNN,能学习长期依赖性。它们由Hochreiter和Schmidhuber在1997年提出,并在后续的研究中得到了广泛的完善和推广。在解决各种问题上,它们都表现出色,现在已被广泛应用。
LSTM 的设计明确是为了避免长期依赖问题。长时间记住信息实际上是他们的默认行为,而不是他们努力学习的东西!
所有循环神经网络都由一系列重复的神经网络模块组成。在标准的RNN中,这个重复模块通常结构简单,比如只有一个tanh层。

LSTM 也具有这种链式结构,但重复模块具有不同的结构。神经网络层不是单一的,而是四个,以非常特殊的方式相互作用。
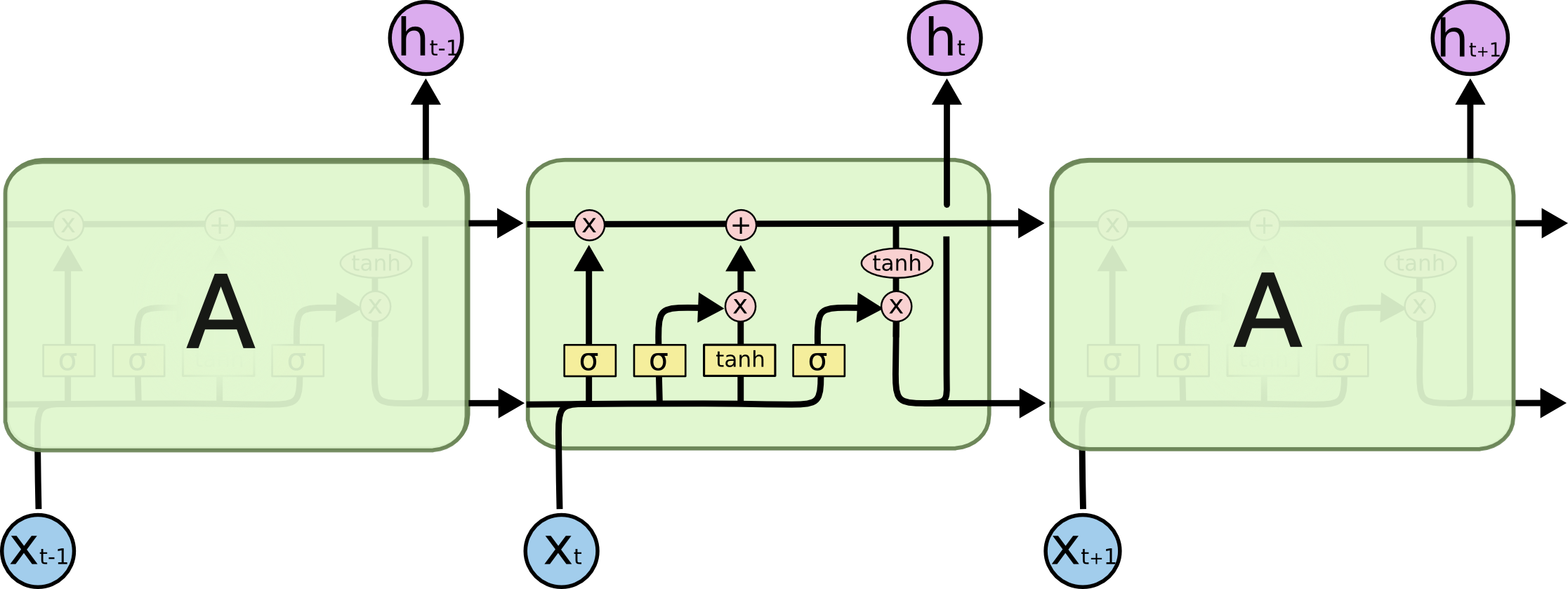
不要担心正在发生的事情的细节。稍后我们将逐步介绍 LSTM 图。现在,让我们试着适应我们将要使用的符号。

在上述图中,每条线传递一个完整的向量,从一个节点的输出到另一个节点的输入。粉红色圆圈表示点对点运算,如向量加法,而黄色方框代表学习神经网络层。线条的合并表示串联,分叉则表示内容被复制,并发送到不同的位置。
LSTM 背后的核心理念
LSTM的核心在于单元状态,即在图的顶部水平延伸的那条线。
细胞状态类似于传送带。它直接穿过整个链条,只发生少量的线性交互。信息可以轻易地沿着它流动而不发生改变。

LSTM确实能够删除或向细胞状态添加信息,由称为门的结构仔细调节。
门是一种选择性地控制信息通过的机制。它们由sigmoid神经网络层和点对点的乘法操作构成。

sigmoid层产生的输出值在0到1之间,这个值决定了应该允许多少信息通过。0的值意味着“不允许任何信息通过”,而1则意味着“允许所有信息通过”。
LSTM 有三个这样的门,用于保护和控制细胞状态。
LSTM 分步演练
LSTM的第一步是决定从单元状态中丢弃哪些信息。这一决定由一个名为“遗忘门层”的sigmoid层做出。它根据 h t ? 1 h_{t - 1} ht?1?和 x t x_t xt?,为细胞状态 C t ? 1 C_{t?1} Ct?1?的每个元素输出一个介于0和1之间的数字。1表示“完全保留”,而0表示“完全舍弃”。
让我们回到我们的语言模型的例子,它试图根据之前的所有单词来预测下一个单词。在这种问题中,单元格状态可能包括当前主语的性别,以便使用正确的代词。当我们看到一个新的主体时,我们想要忘记旧主体的性别。

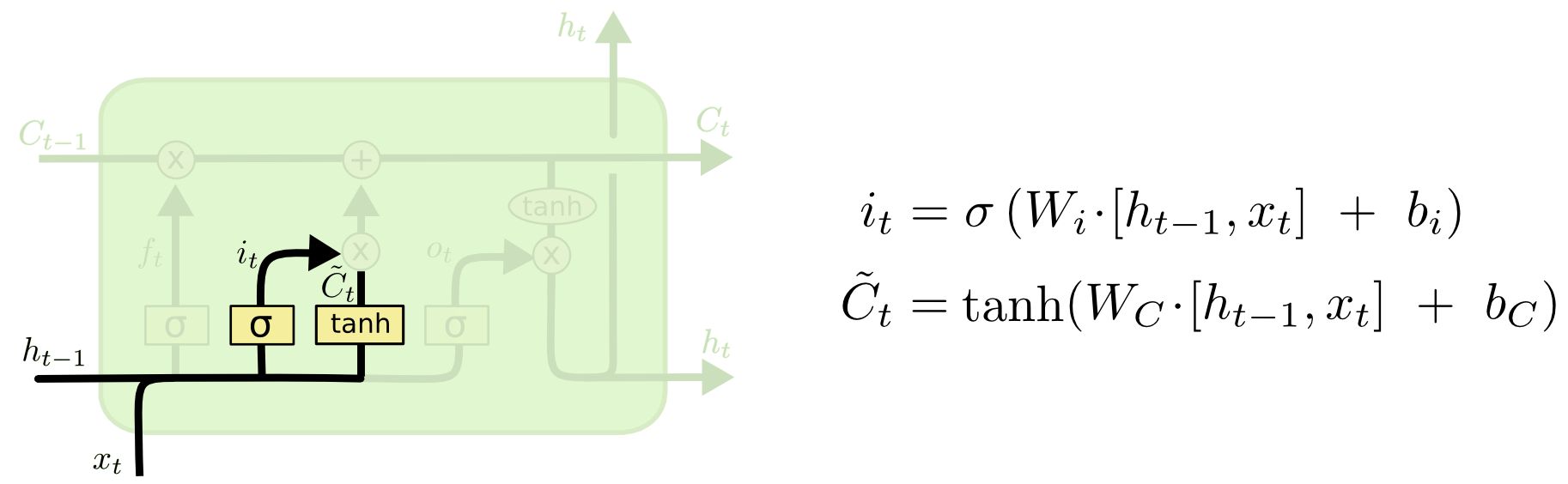
接下来,决定细胞状态中应存储哪些新信息,这分为两部分。首先,“输入门层”(又是一个sigmoid层)决定哪些值将被更新。然后,一个tanh层生成一个新的候选值向量
C
t
~
\tilde{C_t}
Ct?~?,这将被添加到状态中。接下来的步骤将结合这两部分来更新状态。
在我们的语言模型示例中,我们希望将新主题的性别添加到单元格状态中,以取代我们忘记的旧主题。
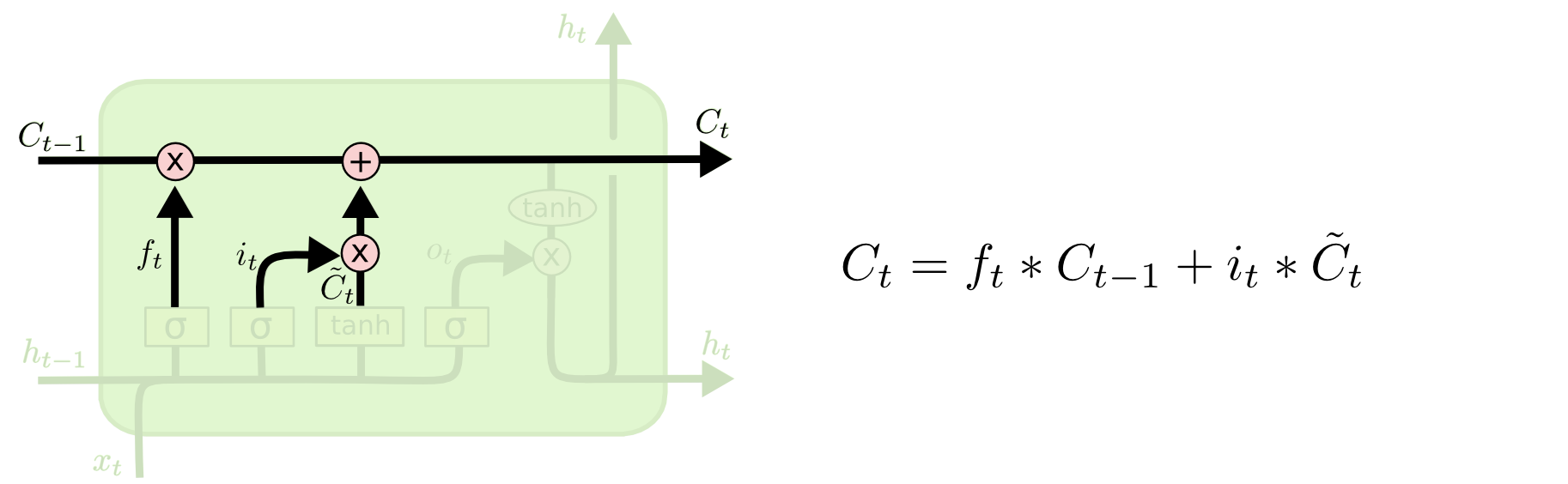
现在是时候将旧的细胞状态
C
t
?
1
C_{t?1}
Ct?1?更新为新的细胞状态
C
t
C_t
Ct?了。前面的步骤已经确定了要执行的操作,我们只需将其付诸实施。
我们用旧状态乘以 f t f_t ft?, 我们忘记了早前决定忘记的事情。然后加上它 i t ? C t ~ i_t ? \tilde{C_t} it??Ct?~?。 这是新的候选值,根据我们决定更新每个状态值的程度进行缩放。
在语言模型的例子中,这是我们实际删除旧主体性别信息并添加新信息的地方,就像我们在前面的步骤中决定的那样。
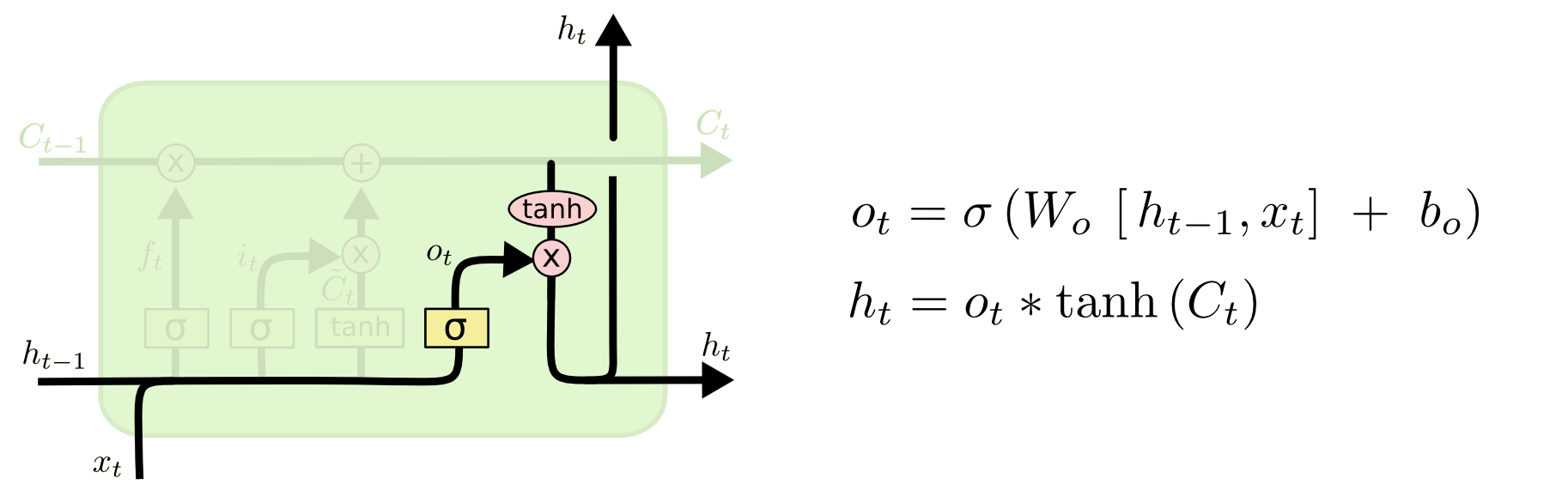
最后一步是决定输出什么。这个输出基于细胞状态,但是一个经过筛选的版本。首先,一个sigmoid层决定了我们想要输出细胞状态的哪些部分。然后,我们将细胞状态通过一个tanh函数(把值映射到-1和1之间),并将其与sigmoid门的输出相乘,这样我们就只输出我们决定输出的那部分。
对于语言模型示例,由于它刚刚看到了一个主题,因此它可能想要输出与动词相关的信息,以防接下来会出现动词。例如,它可能会输出主语是单数还是复数,这样我们就知道如果接下来是动词,动词应该变成什么形式。
长短期记忆的变体
至此,我描述的是一个非常基础的LSTM模型。但并非所有LSTM都与此完全相同。实际上,几乎每篇涉及LSTM的论文都会使用略有不同的版本。虽然差异微小,但其中一些变体值得一提。
由Gers和Schmidhuber(2000)介绍的一种流行的LSTM变体是添加“窥视孔连接”。这意味着我们让栅极层来观察细胞的状态。
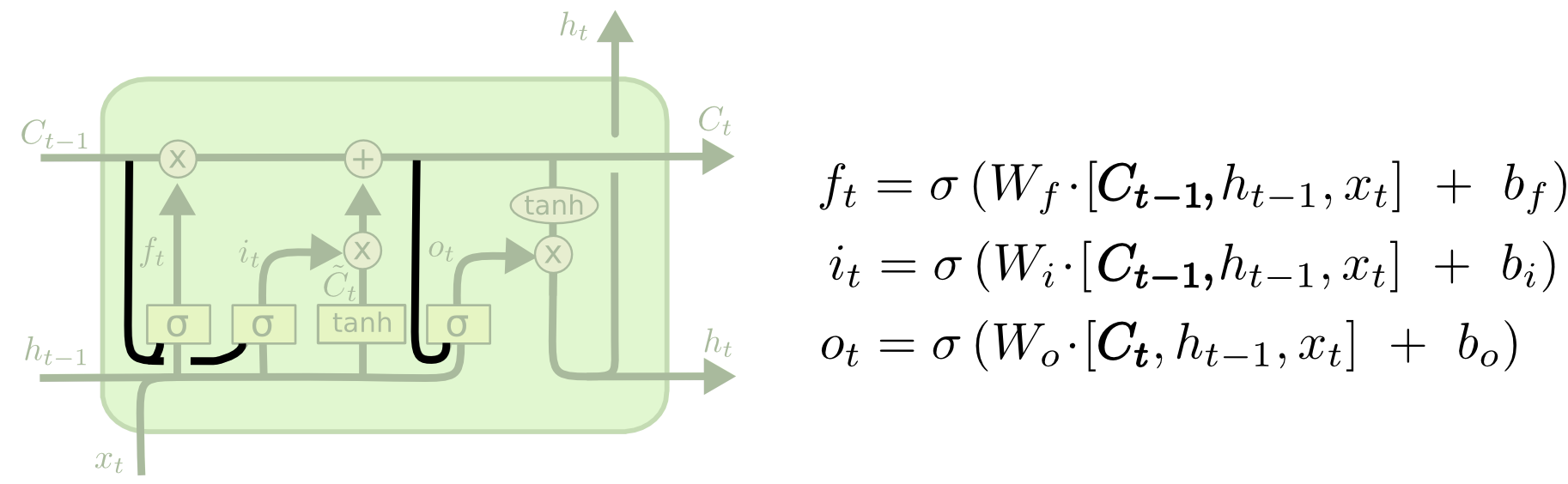
上面的图表在所有的门上都加了窥视孔,但是许多报纸只给了一些窥视孔,而没有给其他的。
另一种变化是使用耦合的遗忘门和输入门。我们不是单独决定要忘记什么和要添加什么新信息,而是一起做出这些决定。只有当我们要输入一些东西的时候我们才会忘记。只有当我们忘记一些旧的东西时,我们才会向状态输入新的值。
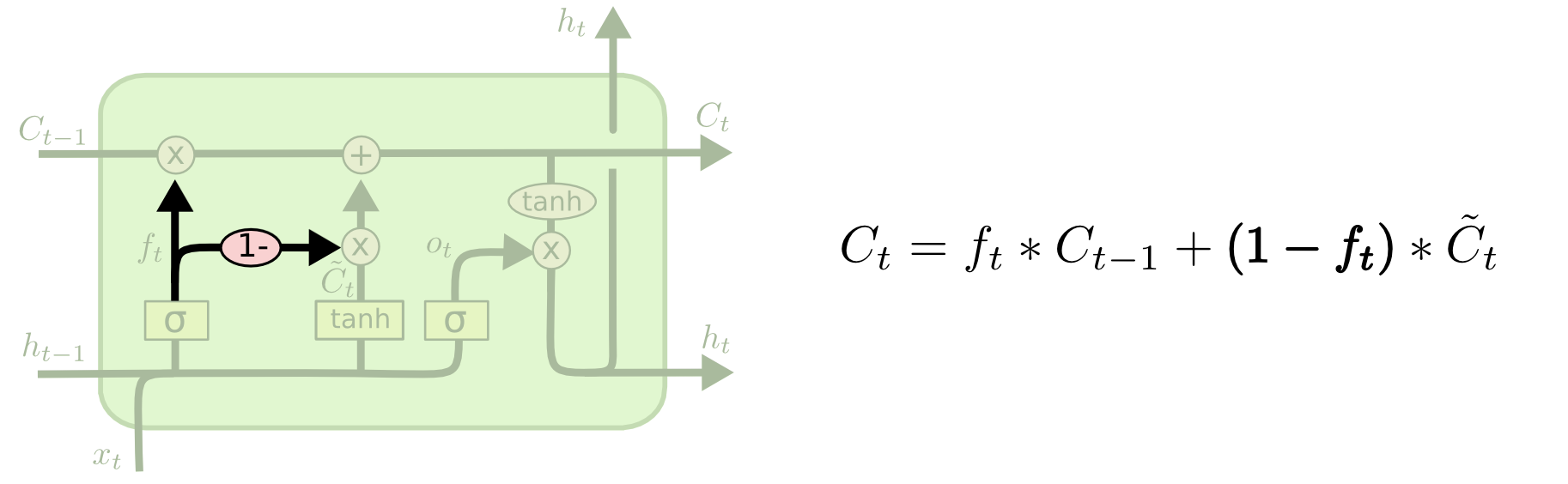
LSTM的一个更显著的变体是由Cho等人(2014年)引入的门控循环单元(GRU)。它将遗忘门和输入门结合为一个“更新门”,同时合并了细胞状态和隐藏状态,并进行了其他一些更改。这种模型比标准的LSTM更为简洁,并且正变得越来越受欢迎。

这些只是几个最著名的LSTM变体。还有很多其他的,比如Yao等人(2015)的深度门控rnn。还有一些完全不同的方法来解决长期依赖,比如Koutnik等人的Clockwork rnn(2014)。
这些变体中哪一个是最好的?这些差异重要吗?Greff等人(2015)对流行的变体做了一个很好的比较,发现它们都差不多。Jozefowicz等人(2015)测试了超过一万种RNN架构,发现一些在某些任务上比lstm工作得更好。
Conclusion
之前,我提到了人们利用RNN取得的显著成就。实际上,这些成就大多是通过使用LSTM实现的。对于大多数任务而言,它们确实表现得更出色!
将lstm写成一组方程,看起来相当令人生畏。希望在这篇文章中一步一步地介绍它们能让它们变得更容易接近。
lstm是我们用rnn所能完成的一大步。人们很自然地想知道:是否又迈出了一大步?研究人员的一个普遍观点是:“是的!还有一个步骤,那就是注意力!”这个想法是让RNN的每一步都从一些更大的信息集合中挑选信息来查看。例如,如果您使用RNN来创建描述图像的标题,它可能会选择图像的一部分来查看它输出的每个单词。事实上,Xu等人(2015)正是这样做的——如果你想探索注意力,这可能是一个有趣的起点!利用注意力已经取得了许多非常令人兴奋的结果,似乎更多的结果即将到来……
注意力并不是RNN研究中唯一令人兴奋的线索。例如,Kalchbrenner等人(2015)的网格lstm似乎非常有前途。在生成模型中使用rnn的工作-例如Gregor等人(2015),Chung等人(2015)或Bayer & Osendorfer(2015) -似乎也非常有趣。过去几年对于递归神经网络来说是一个激动人心的时刻,而未来的神经网络只会更加激动人心!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JuiceSSH结合内网穿透实现公网远程访问本地Linux虚拟机
- 下一代实时数据库:Apache Doris 【三】集群部署
- 基于Java SSM框架实现新闻推送系统项目【项目源码】计算机毕业设计
- 《应急响应: 网络安全的预防、发现、处置和恢复》
- 机器人能否提高企业生产力?剑桥大学揭开机器人部署生产力的U型曲线
- 前端er们,你真的会用useState么?
- 【常见问题】在Tkinter中使用Listbox.curselection()获取列表索引,为什么第一次返回为空元组
- 数仓建设学习路线(二)模型建设(2)
- ssm基于jsp的网络书店系统论文
- Vue学习计划-Vue3--核心语法(三)computed计算属性、watch监听、watchEffect函数