西南民族大学机器学习复习资料、计算机网络复习资料、操作系统复习资料、数据库复习资料、自然语言处理整理资料、强化学习整理资料打包出售,也可以单卖。
名词解释 5题 每题2分
选择题 15题 每题2分
简述题 2题 每题5分
计算题 5题 40分
编程题 10分
机器学习是什么?
让机器从数据中寻找或者总结出一个模型。
泛化能力:学得的模型适用于新样本的能力
分类:输出结果是离散值
回归:输出结果是连续值
监督学习:训练样本有标记
无监督学习:训练样本无标记
半监督学习:训练样本部分标记
假设空间:监督学习的任务是学习一个模型,是模型能够对任意给定的输入做出好的预测。模型属于由输入空间到输出空间的映射集合,这个几个就是假设空间。
版本空间:与训练集一直的假设集合
没有免费午餐定理:无论A算法多么聪明,B算法多笨拙,但是他们的期望性能相同。
评估一个模型的好坏更主要看泛化误差
习题:
学习器学习能力太强大,可能导致过拟合
一般通过增加训练轮数或增加模型复杂度等方式可以改善欠拟合
过拟合相对欠拟合更难解决
如果样本是小样本数据,更适合自助法。
误差:模型输出与样本真实值之间的差异
过拟合:用力过猛,学习能力过于强大,把不太一般的特征都学习到了。
欠拟合:用力不足,学习能力低下。
评估方法
目标:对于模型/学习器的泛化误差进行评估
专家样本:训练集 + 测试集
训练集:训练误差
测试集:测试误差(近似泛化误差)
要求:测试集数据独立同分布并与训练集互斥
留出法:
k折交叉验证法:将专家样本等份划分为k个数据集,轮流用k-1个用于训练,一个用于测试
自助法:随机有放回的取m个数据构成数据集D’,用D中不包含D‘的样本作为测试集。缺点为:改变了初始数据集的分布 适用于小样本数据集
性能度量:
TP:真正例 算法预测它为好瓜 这个西瓜实际情况也是好瓜
FP:假正例 算法预测它是好西瓜 但是这个真实情况为怀西瓜
FN:假反例 算法预测为换西瓜 但这个西瓜真实是好西瓜
TN:真反例 算法预测为好西瓜,真实情况为坏西瓜
查准率和查全率是一对矛盾的指标,一般说,当查准率高的时候,查全率一般很低,查全率高时,查准率一般很低。
P-R曲线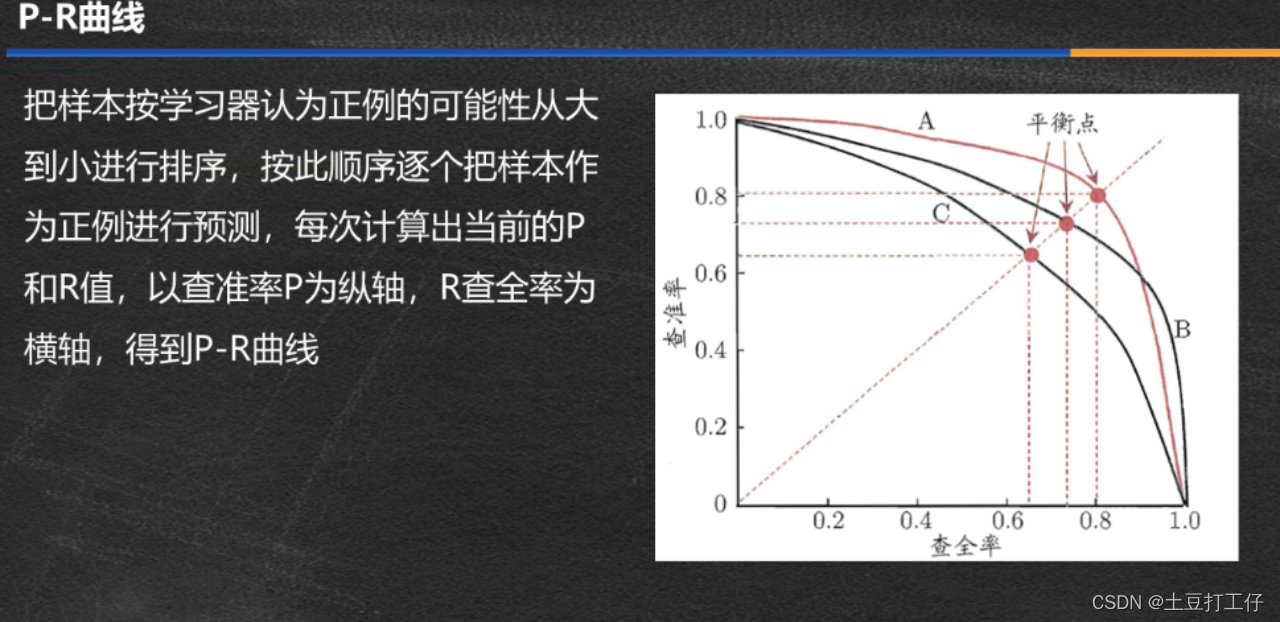
完全包住另一曲线,性能更优,比如A比C优。
ROC和AUC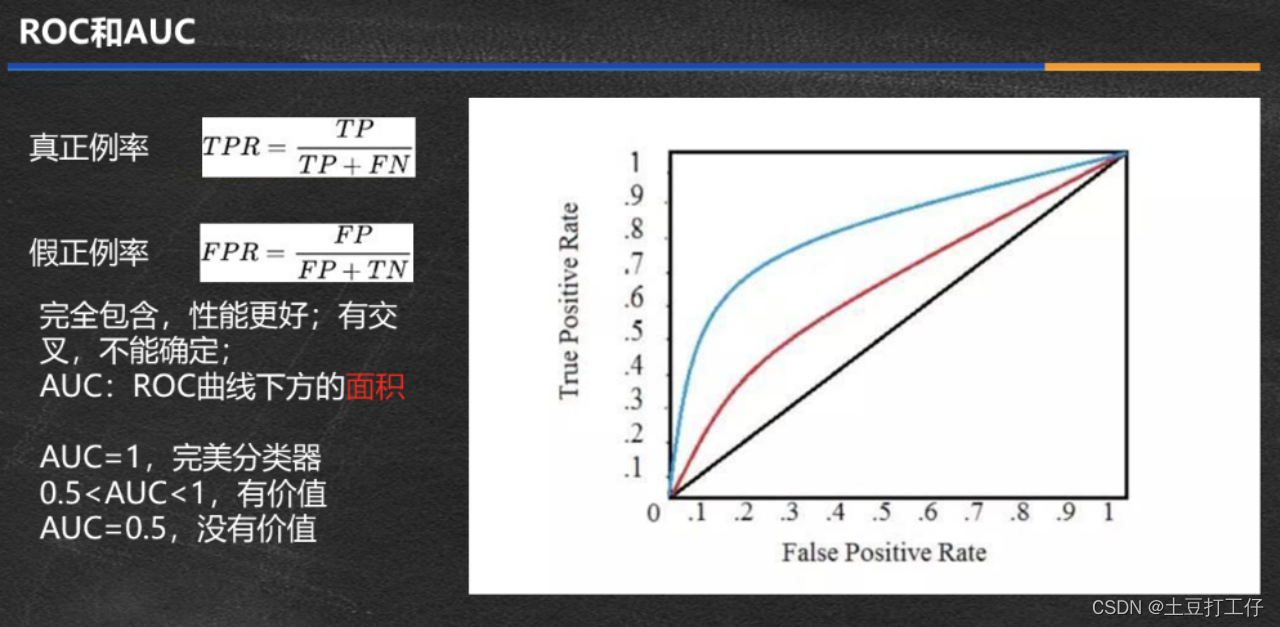
泛化错误率和构成:偏差 + 方差 + 噪声
偏差(bias):模型输出与真实值的偏离程度,刻画了算法的拟合能力。
方差:同样大小的训练集的变动导致学习性能的变化。
噪声:当前学习器所能达到的泛化误差的下限。
偏差大:欠拟合 方差大:过拟合
如何找最小误差:最小二乘法?
均方误差最小化,找到一条直线,使所有样本到直线上的欧式距离之和最小
线性回归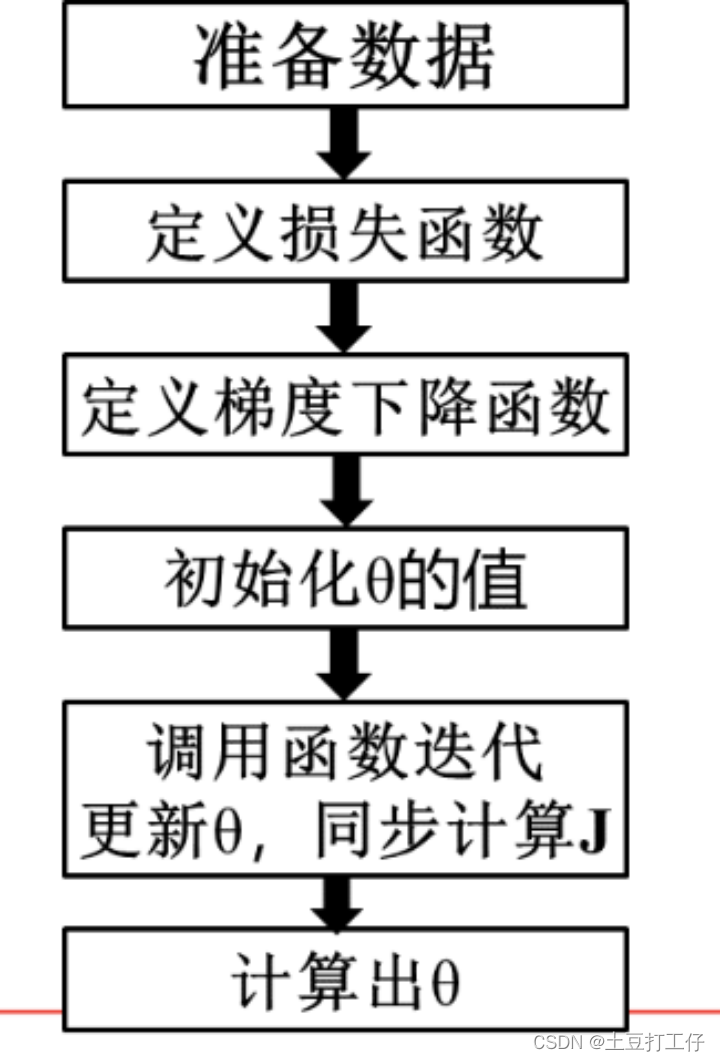
一般流程总结
一般线性回归模型的损失函数曲线不存在局部最优点。
假设函数F(x) = wx ,在梯度下降过程中,如果w0处的导数为负,w的值会变大。
关于学习率:
1 学习率过大,损失值会变大
2 学习率过小,损失值会变小,只是速度慢
3 学习率较大,有可能没有办法找到最小损失
多元线程回归的一般步骤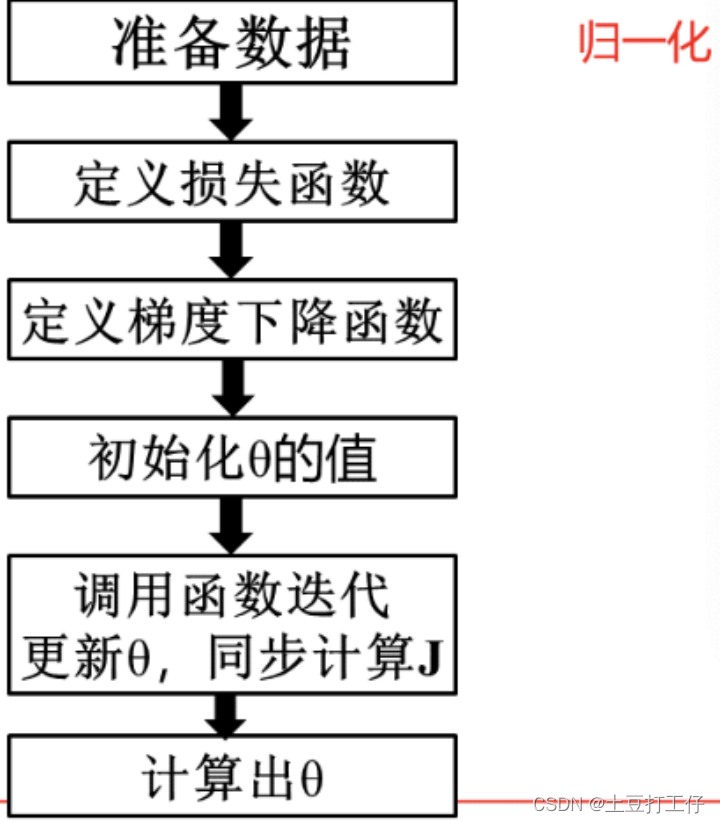
决策树
决策树可以用于分类和回归
对某一时间发生概率小,信息量大
样本集合信息熵越大,纯度越小
决策树由一个根节点、多个中间节点、多个叶子节点构成
决策树的节点属性可以采用信息增益、信息增益率、基尼系数来确定
决策树算法包括:ID3、ID4、C4.5、CART
剪枝的作用:处理过拟合
决策树是一种非参数的监督学习方法,它能够从一系列有特征的标签的数据总结出决策规则,并用树状图的结构来呈现这些规则,来解决分类和回归问题。
信息熵越小,D的纯度就越高
ID3算法
基尼指数越大,样本的不确定性就越大。
剪枝处理
神经网络
感知机不能解决线性不可分
神经网络的监督学习方法的一般思路:
1 初始化权重 2 获取输入送入模型并获得输出,依据正确输出计算误差
3 BP算法调整权重 4 重复2 3 步
SVM
SVM可以解决二分类、多分类、回归问题。
找到最优线的三个条件 1 该直线分开了两类 2 该直线能够获得最大间隔 3 该直线处于间隔的中间,到所有支持向量的距离相等。
支持向量机需要找到最大间隔的超平面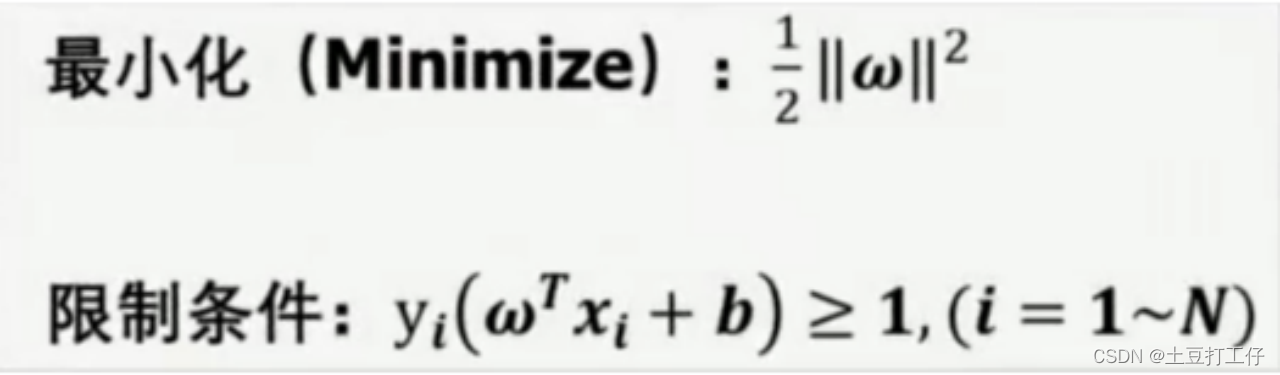
需要最大化d,等于最小化w。
只要一个对称函数对应的和矩阵半正定,就可以作为核函数。
朴素贝叶斯

概率模型训练的过程就是参数估计的过程
极大似然估计:估计出的参数使得已知样本出现的概率最大,即是使得训练数据的似然最大。
朴素:特征数据相互独立
拉普拉斯修正:为了便面其他属性携带了信息被训练集未出现的属性值抹去,在估计概率值通常进行平滑。
以上可出售的内容,需要可以联系。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ubuntu安装详细步骤
- 伊朗黑客利用新的 MediaPl 恶意软件攻击研究人员
- Java实战项目一:简易命令行计算器开发
- LINUX基础培训十之服务管理
- 华为机试真题实战应用【赛题代码篇】-等和子数组最小和(附Python、C++和Java代码)
- zabbix监控系统
- [LeetCode][Python]389. 找不同
- 体验全新升级的ON1 Photo RAW 2024,释放你的摄影潜能!
- 你知道程序员如何利用citywork实现财富自由吗?
- 【自然语言处理】【深度学习】文本向量化、one-hot、word embedding编码