7、InternVL
发布时间:2024年01月02日
简介
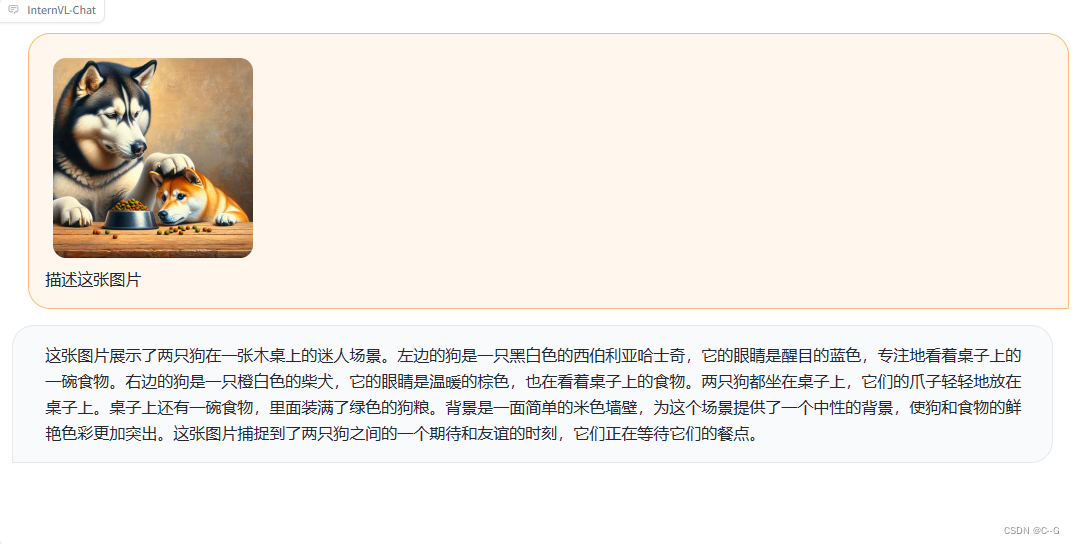
使用网络获取的油画图片,InternVL识别还算可以。
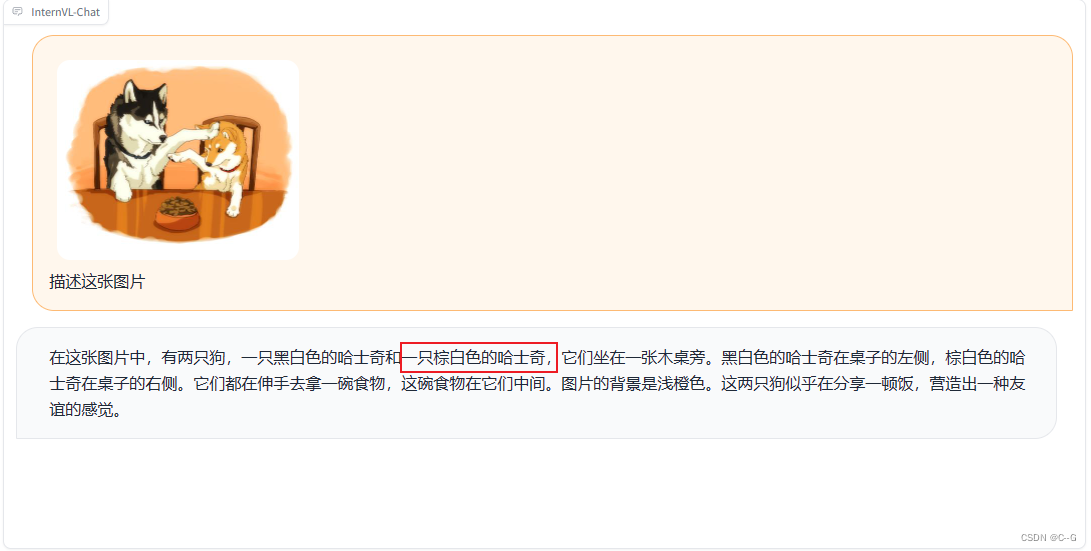
使用stable diffusion生成的图片,InternVL能很好的识别。
权重
模型搭建
下载源码
git clone https://github.com/OpenGVLab/InternVL.git
创建环境
conda create -n internvl python=3.9 -y
conda activate internvl
下载pytorch依赖,要求PyTorch>=2.0,torchvision>=0.15.2,CUDA>=11.6
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
# or
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
下载 flash-attn==0.2.8,这是因为不同版本的 flash attention 会产生细微的结果差异。
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
git checkout v0.2.8
python setup.py install
下载 timm=0.6.11 、mmcv-full==1.6.2
pip install -U openmim
pip install timm==0.6.11
mim install mmcv-full==1.6.2
下载 transformers==4.32.0
pip install transformers==4.32.0
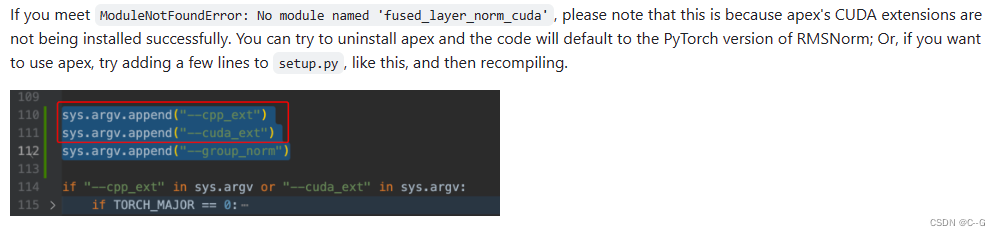
下载 apex
git clone https://github.com/NVIDIA/apex.git
git checkout 2386a912164b0c5cfcd8be7a2b890fbac5607c82 # https://github.com/NVIDIA/apex/issues/1735
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
下载依赖包
pip install opencv-python termcolor yacs pyyaml scipy
使用Huggingface快速开始
InternViT-6B
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
model = AutoModel.from_pretrained(
'OpenGVLab/InternViT-6B-224px',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image = Image.open('./examples/image1.jpg').convert('RGB')
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-6B-224px')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
outputs = model(pixel_values)
InternVL-C(ontrastive) and InternVL-G(enerative)
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
from transformers import AutoTokenizer
model = AutoModel.from_pretrained(
'OpenGVLab/InternVL-14B-224px',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternVL-14B-224px')
tokenizer = AutoTokenizer.from_pretrained(
'OpenGVLab/InternVL-14B-224px', use_fast=False, add_eos_token=True)
tokenizer.pad_token_id = 0 # set pad_token_id to 0
images = [
Image.open('./examples/image1.jpg').convert('RGB'),
Image.open('./examples/image2.jpg').convert('RGB'),
Image.open('./examples/image3.jpg').convert('RGB')
]
prefix = 'summarize:'
texts = [
prefix + 'a photo of a red panda', # English
prefix + '一张熊猫的照片', # Chinese
prefix + '二匹の猫の写真' # Japanese
]
pixel_values = image_processor(images=images, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
input_ids = tokenizer(texts, return_tensors='pt', max_length=80,
truncation=True, padding='max_length').input_ids.cuda()
# InternVL-C
logits_per_image, logits_per_text = model(
image=pixel_values, text=input_ids, mode='InternVL-C')
probs = logits_per_image.softmax(dim=-1)
# tensor([[9.9609e-01, 5.2185e-03, 6.0070e-08],
# [2.2949e-02, 9.7656e-01, 5.9903e-06],
# [3.2932e-06, 7.4863e-05, 1.0000e+00]], device='cuda:0',
# dtype=torch.bfloat16, grad_fn=<SoftmaxBackward0>)
# InternVL-G
logits_per_image, logits_per_text = model(
image=pixel_values, text=input_ids, mode='InternVL-G')
probs = logits_per_image.softmax(dim=-1)
# tensor([[9.9609e-01, 3.1738e-03, 3.6322e-08],
# [8.6060e-03, 9.9219e-01, 2.8759e-06],
# [1.7583e-06, 3.1233e-05, 1.0000e+00]], device='cuda:0',
# dtype=torch.bfloat16, grad_fn=<SoftmaxBackward0>)
# please set add_eos_token to False for generation
tokenizer.add_eos_token = False
image = Image.open('./examples/image1.jpg').convert('RGB')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
tokenized = tokenizer("English caption:", return_tensors='pt')
pred = model.generate(
pixel_values=pixel_values,
input_ids=tokenized.input_ids.cuda(),
attention_mask=tokenized.attention_mask.cuda(),
num_beams=5,
min_new_tokens=8,
)
caption = tokenizer.decode(pred[0].cpu(), skip_special_tokens=True).strip()
# English caption: a red panda sitting on top of a wooden platform
文章来源:https://blog.csdn.net/weixin_50973728/article/details/135341060
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 洗眼镜机到底是不是智商税吗?值得买吗?眼镜清洗机推荐
- vscode无识别已有的maven java项目(visual studio code not recognizing java project)
- 基于JAVA-SSM中小学智能排课系统(带自动排课算法)
- OpenCV读取视频失败<无可用信息,未为 opencv_world453.dll 加载任何符号> cv::VideoCapture
- 【Pytorch】搭建一个简单的泰坦尼克号预测模型
- 一文轻松入门Dubbo
- 〖大前端 - ES6篇①〗- ES6简介
- openssl3.2/test/certs - 036 - 768-bit issuer key
- HTML5-新增语义相关标签
- 1.2.3OSI参考模型(一)