层次分析法(数模)
发布时间:2024年01月23日
例题

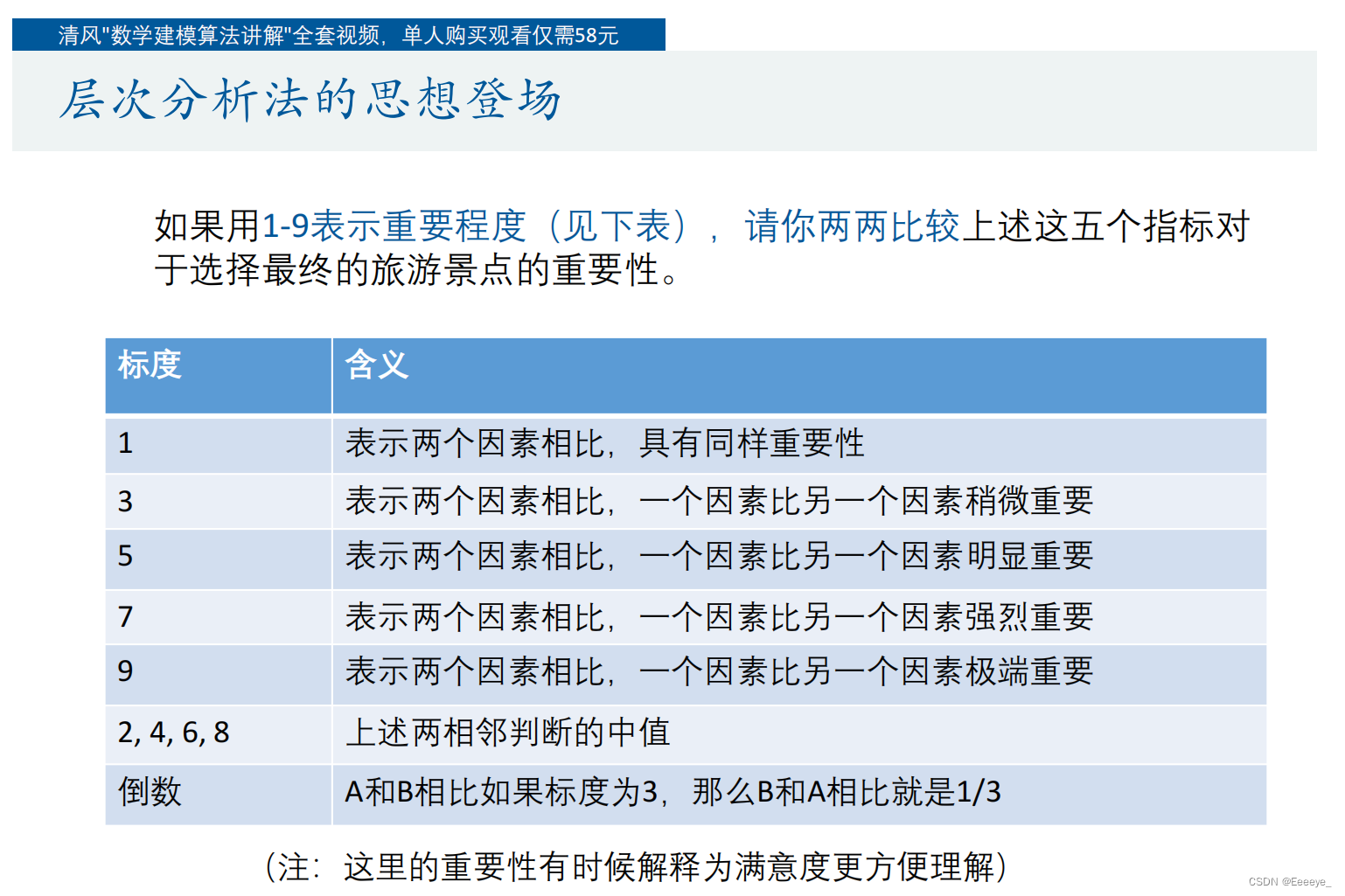
当遇到多个要素,很难一次性地客观地完成一整个权重表格,故使用两两对比来完成权重表格
层次分析法的思想
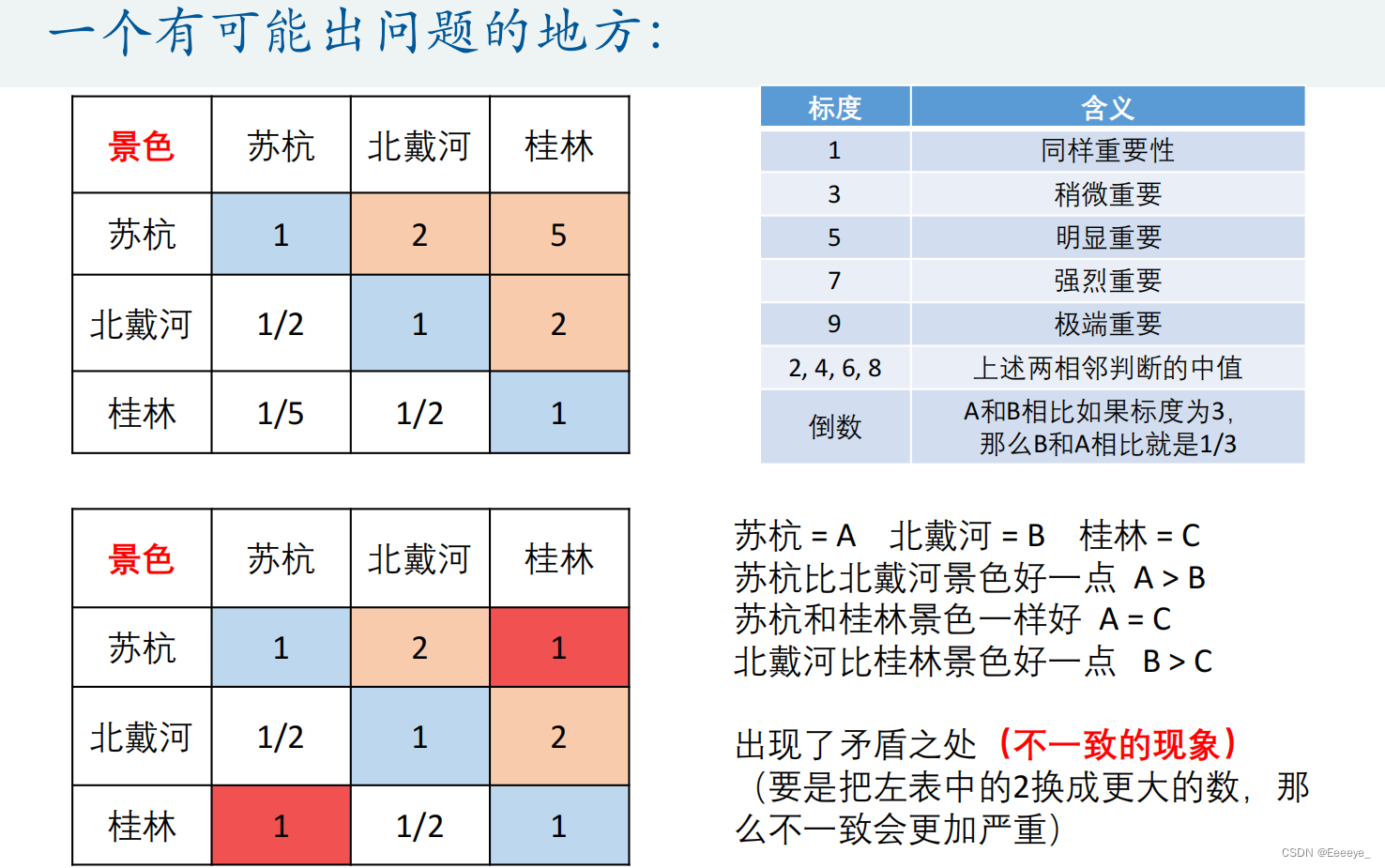
可能出现的问题
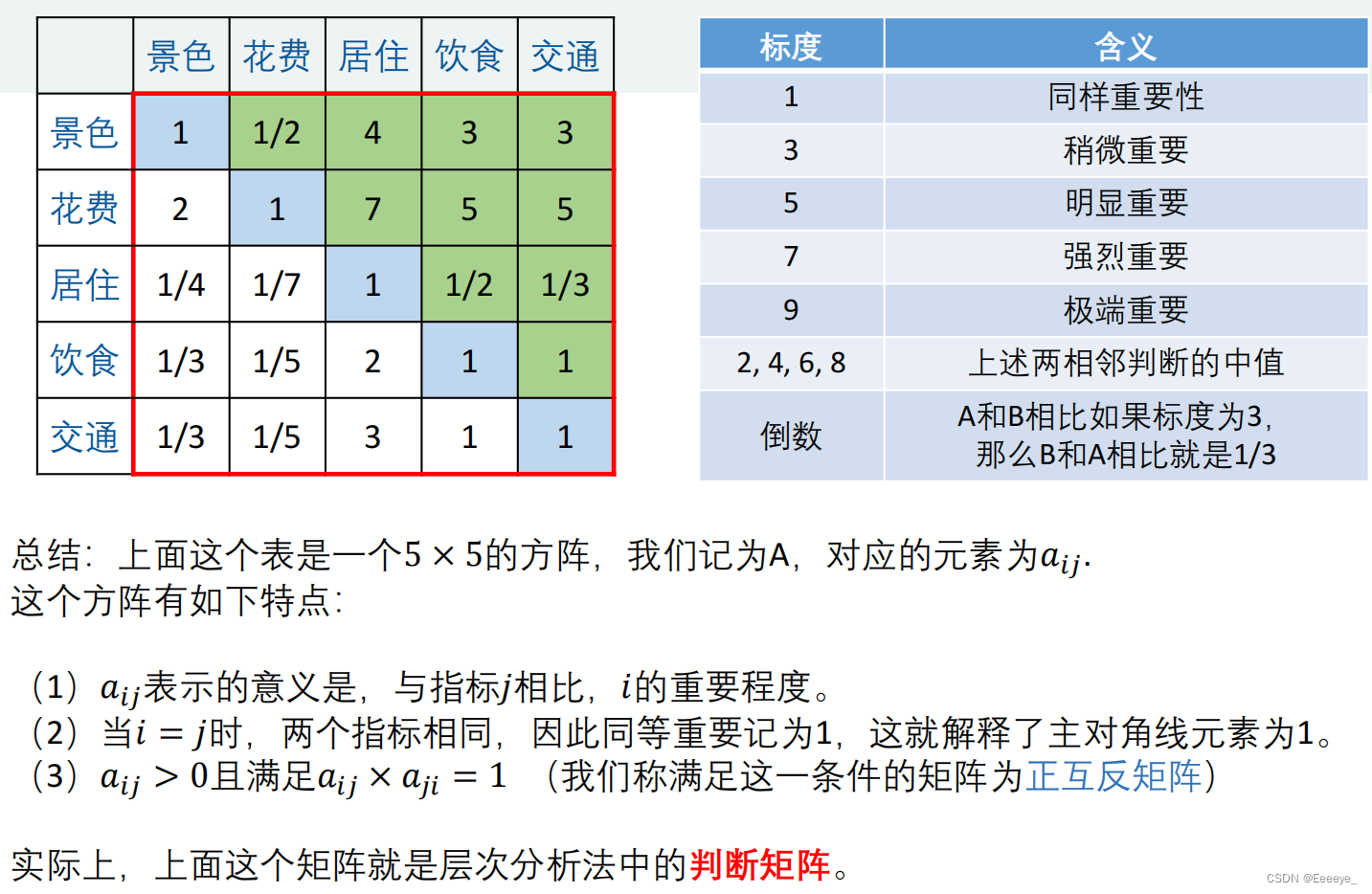
标准的矩阵(一致矩阵)

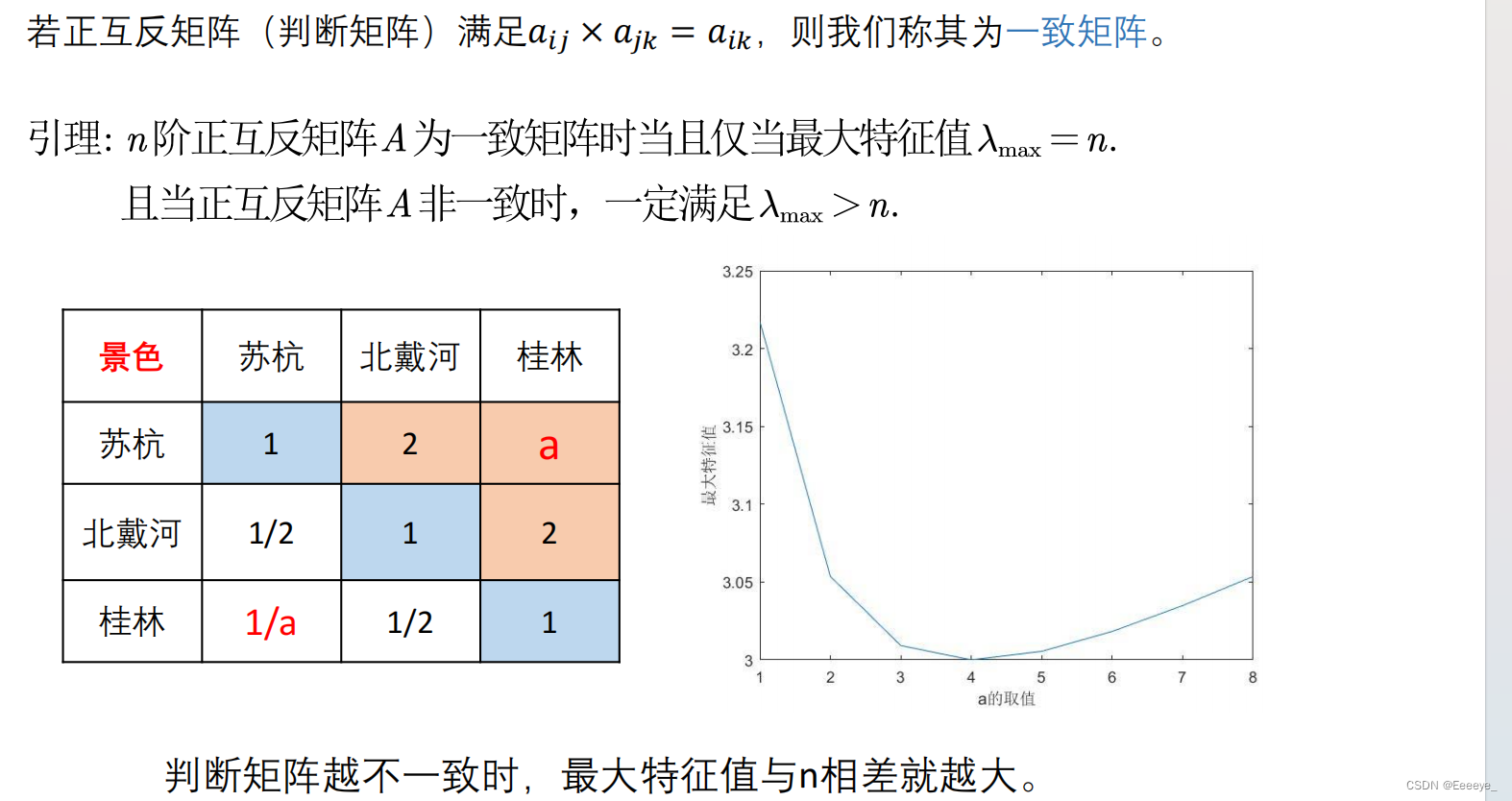
一致性检验

步骤(重要)
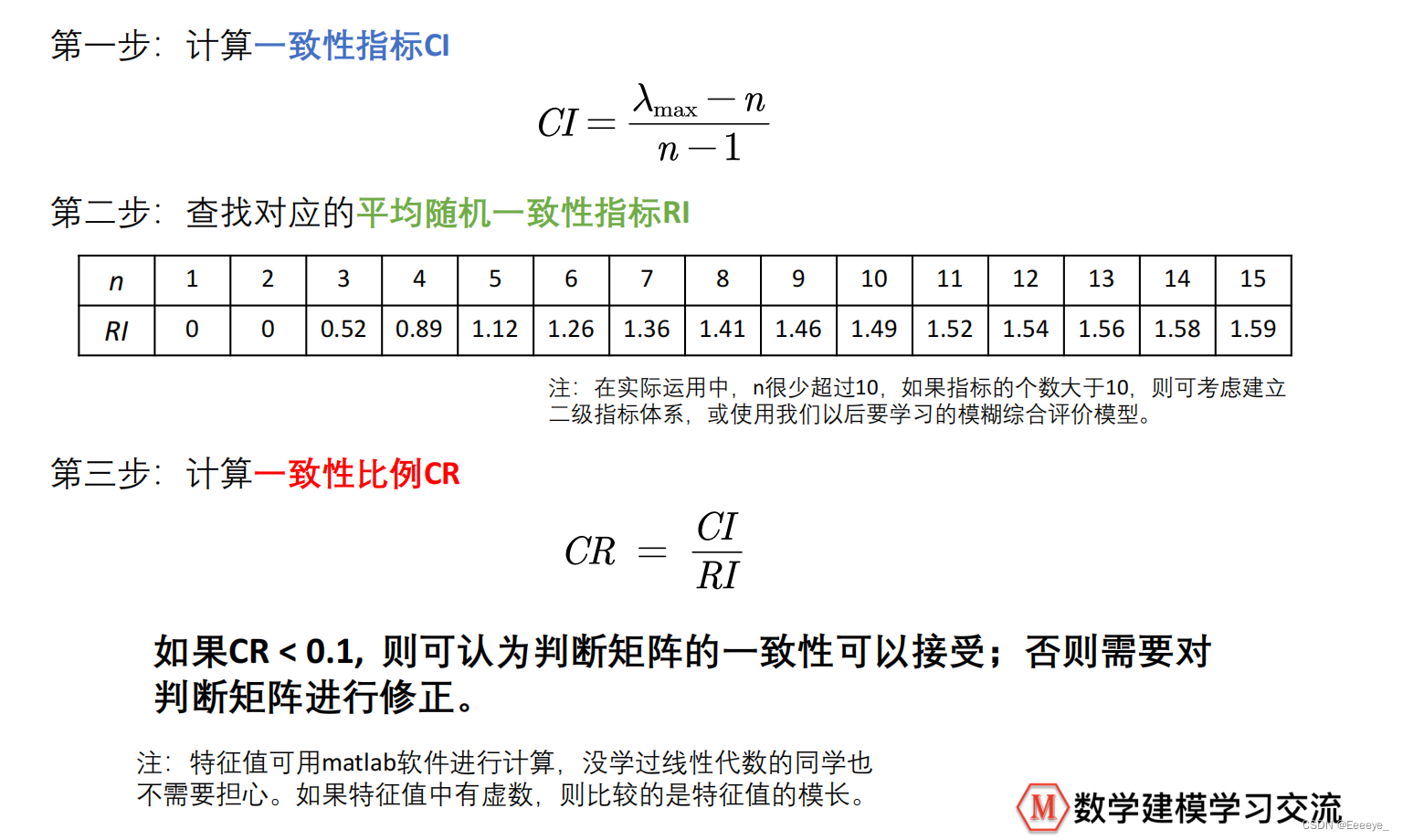
权重的计算
一致矩阵
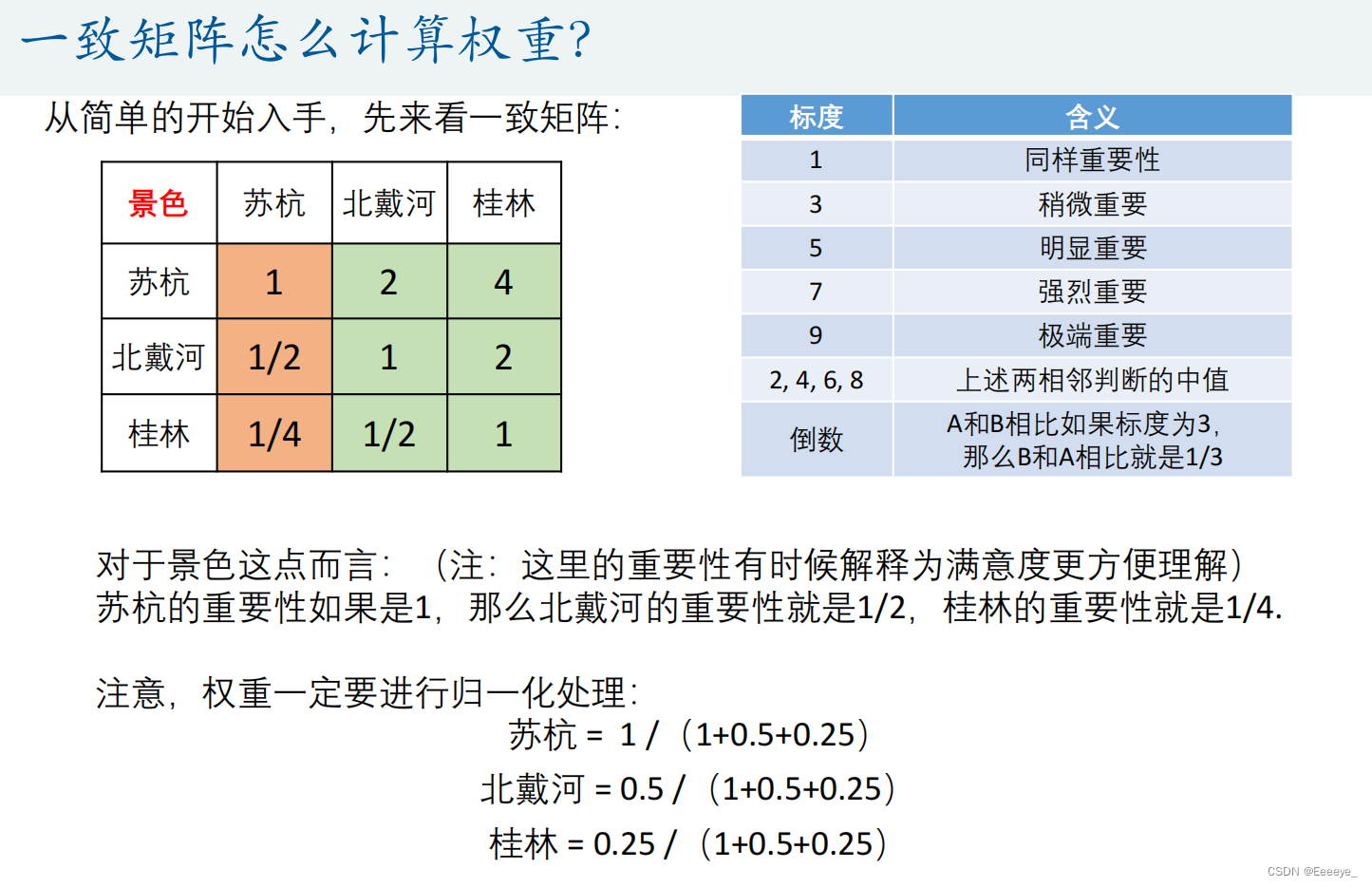
- 计算方法:挑选一列(例如苏杭)(在一致矩阵中,每一列计算结果都一样),要素之间所成的真正比例就是列中的比例(1、1/2、1/4),所以权重如上计算。
- 注意归一化
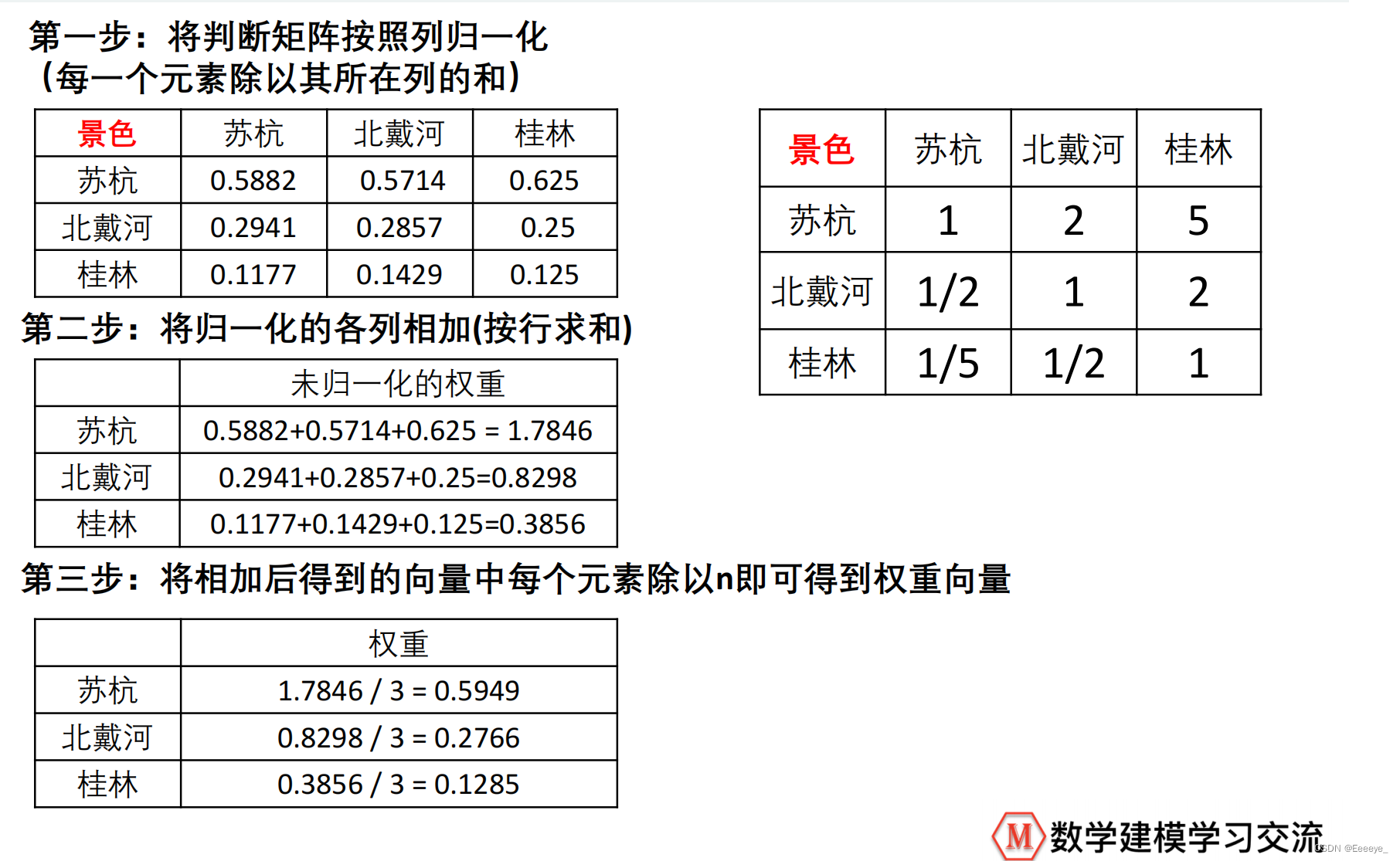
判断矩阵
方法1(算数平均法)

- 文字描述:
- 数学公式:

几何平均法
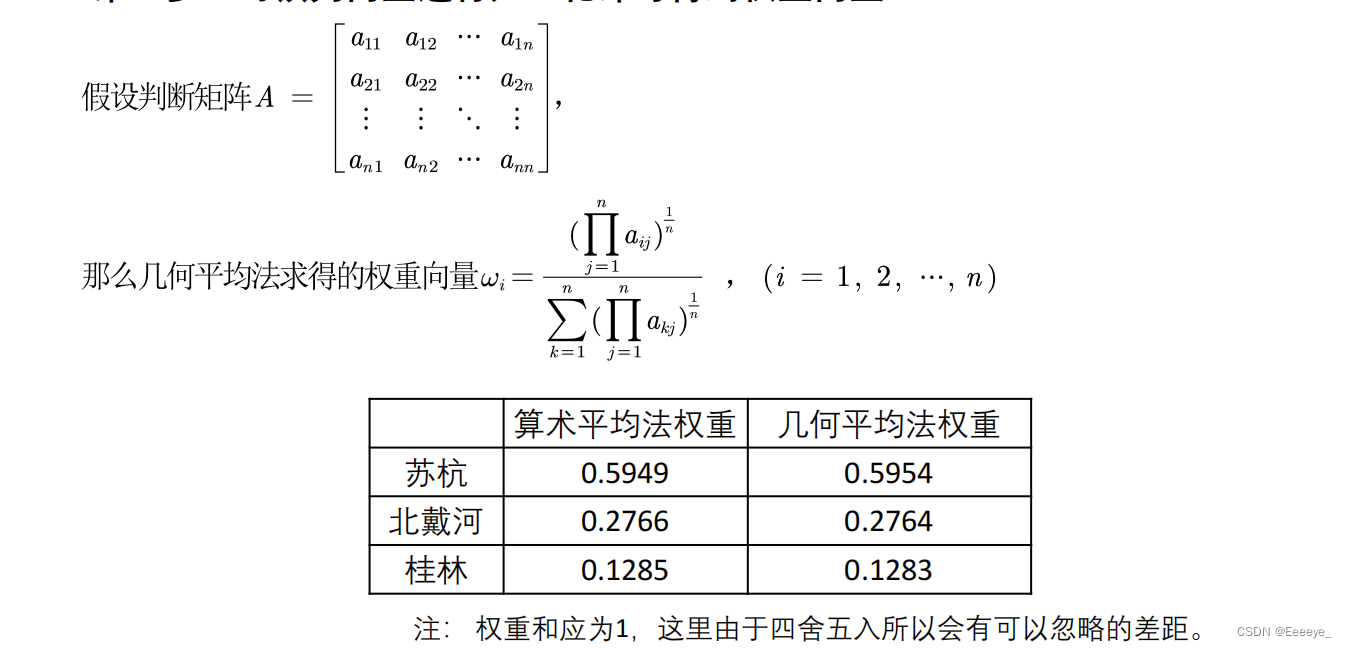
特征值法求权重(重要)

求权重,即求特征向量

如果判断矩阵可以通过一致性检验,那么就可以用相同的算法(特征值法)计算权重
汇总
利用Excel计算(F4可以锁定单元格)

论文体现
- 图例
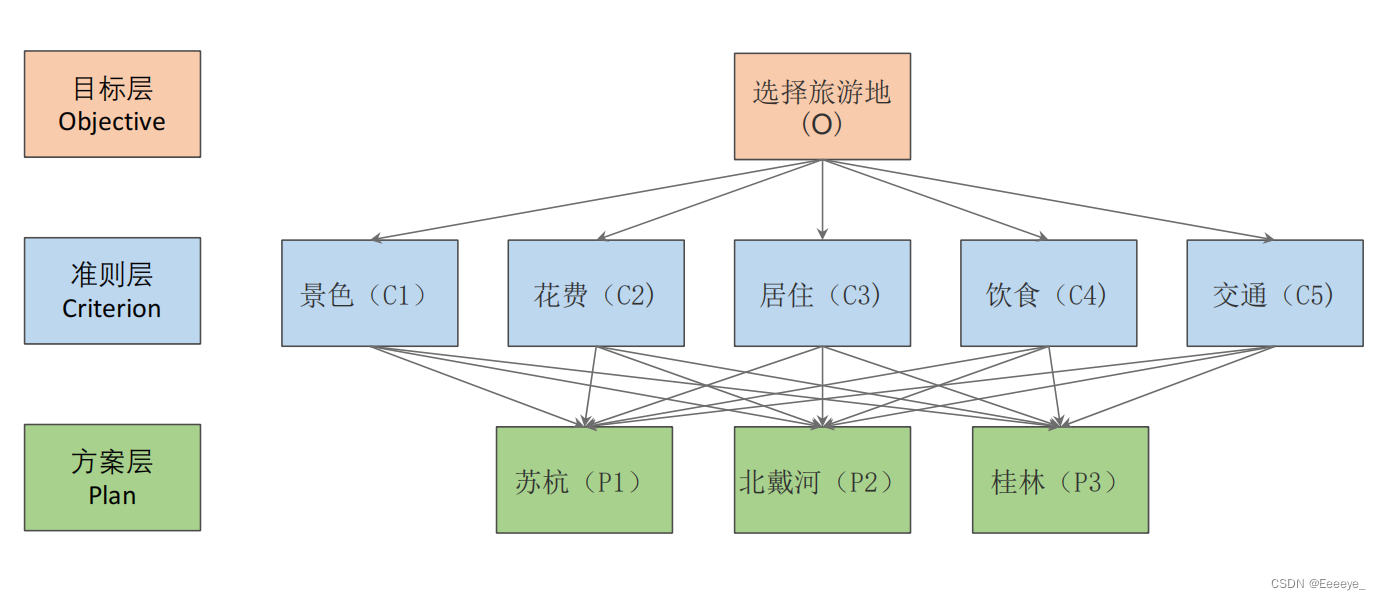
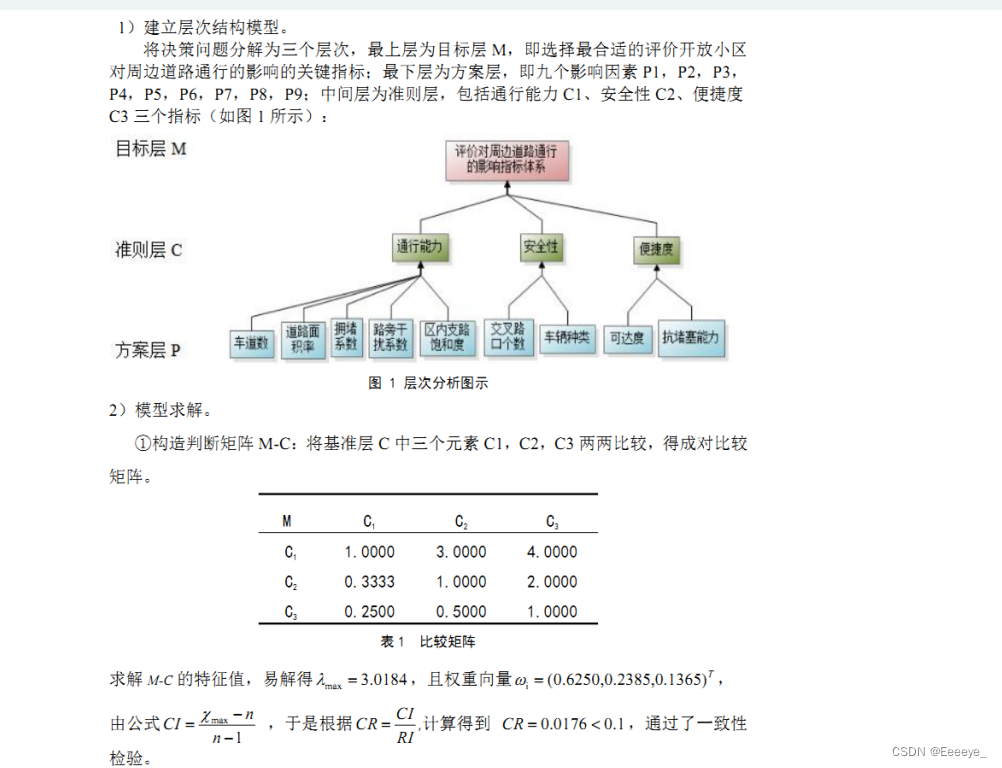
- 案例
局限性
当有实际数据时,应该选用其他方法
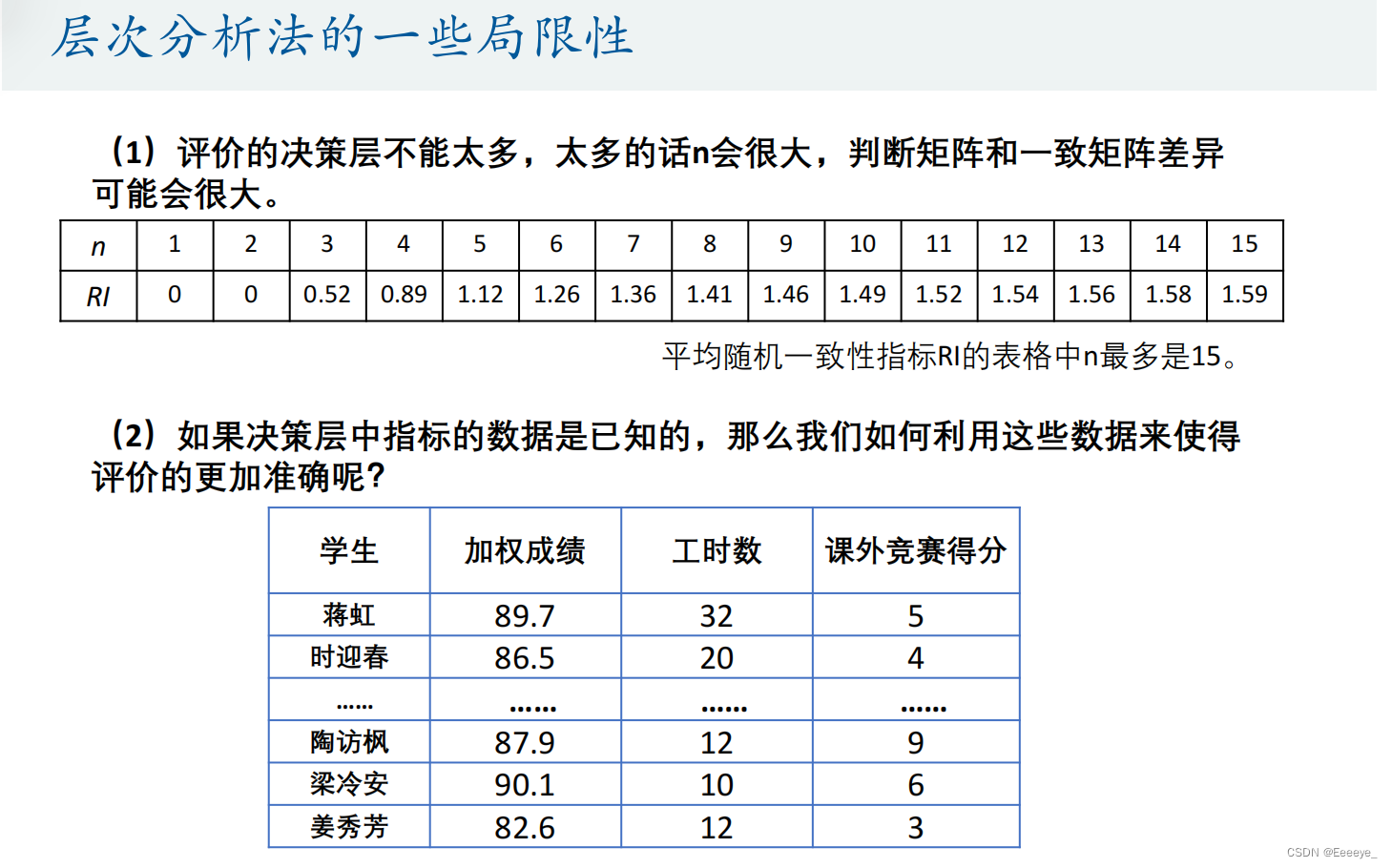
三种方法都使用

代码实现
计算之前先通过一致性检验(Max_eig最大特征值的求解在特征值求权重部分)
clc
CI = (Max_eig - n) / (n-1);
RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15
CR=CI/RI(n);
disp('一致性指标CI=');disp(CI);
disp('一致性比例CR=');disp(CR);
if CR<0.10
disp('因为CR < 0.10,所以该判断矩阵A的一致性可以接受!');
else
disp('注意:CR >= 0.10,因此该判断矩阵A需要进行修改!');
end
算术平均法
- 对于某个准则层的表格(例如花费)
disp('请输入判断矩阵A: ') % A = input('判断矩阵A=') A =[1 1 4 1/3 3; 1 1 4 1/3 3; 1/4 1/4 1 1/3 1/2; 3 3 3 1 3; 1/3 1/3 2 1/3 1] - 对列求和,然后求出权重(归一化):
% 第一步:将判断矩阵按照列归一化(每一个元素除以其所在列的和)
Sum_A = sum(A)
[n,n] = size(A) % 也可以写成n = size(A,1)
% 因为我们的判断矩阵A是一个方阵,所以这里的r和c相同,我们可以就用同一个字母n表示
SUM_A = repmat(Sum_A,n,1) %repeat matrix的缩写
% 另外一种替代的方法如下:
SUM_A = [];
for i = 1:n %循环哦,这一行后面不能加冒号(和Python不同),这里表示循环n次
SUM_A = [SUM_A; Sum_A]
end
clc;A
SUM_A
Stand_A = A ./ SUM_A
% 这里我们直接将两个矩阵对应的元素相除即可
- 对每个元素(方案层)(苏州)(每行)的各列进行求和,再除以元素的数量(列数)
sum(Stand_A,2)
% 第三步:将相加后得到的向量中每个元素除以n即可得到权重向量
disp('算术平均法求权重的结果为:');
disp(sum(Stand_A,2) / n)
几何平均法
% 第一步:将A的元素按照行相乘得到一个新的列向量
clc;A
Prduct_A = prod(A,2)
% prod函数和sum函数类似,一个用于乘,一个用于加 dim = 2 维度是行
% 第二步:将新的向量的每个分量开n次方
Prduct_n_A = Prduct_A .^ (1/n)
% 这里对每个元素进行乘方操作,因此要加.号哦。 ^符号表示乘方哦 这里是开n次方,所以我们等价求1/n次方
% 第三步:对该列向量进行归一化即可得到权重向量
% 将这个列向量中的每一个元素除以这一个向量的和即可
disp('几何平均法求权重的结果为:');
disp(Prduct_n_A ./ sum(Prduct_n_A))
特征值求权重
- 求出最大特征值
% 第一步:求出矩阵A的最大特征值以及其对应的特征向量
clc
[V,D] = eig(A) %V是特征向量, D是由特征值构成的对角矩阵(除了对角线元素外,其余位置元素全为0)
Max_eig = max(max(D)) %也可以写成max(D(:))哦~
- 找到最大特征值所在的位置(列):
% 那么怎么找到最大特征值所在的位置了? 需要用到find函数,它可以用来返回向量或者矩阵中不为0的元素的位置索引。
% 那么问题来了,我们要得到最大特征值的位置,就需要将包含所有特征值的这个对角矩阵D中,不等于最大特征值的位置全变为0
% 这时候可以用到矩阵与常数的大小判断运算
D == Max_eig
[r,c] = find(D == Max_eig , 1)
% 找到D中第一个与最大特征值相等的元素的位置,记录它的行和列。
- 归一化求权重(先求含有最大特征值的列)
% 第二步:对求出的特征向量进行归一化即可得到我们的权重
V(:,c)
disp('特征值法求权重的结果为:');
disp( V(:,c) ./ sum(V(:,c)) )
% 我们先根据上面找到的最大特征值的列数c找到对应的特征向量,然后再进行标准化。
代码优化
- 是否为方阵:
disp('请输入判断矩阵A') A=input('A='); ERROR = 0; [r,c]=size(A); if r ~= c || r <= 1 ERROR = 1; end- 是否为正互反矩阵:
- 是否为正:
if ERROR == 0
[n,n] = size(A);
%对矩阵进行一次sum函数会返回一个行列式,对行列式进行一次sum函数会返回一个数字
if sum(sum(A <= 0)) > 0
ERROR = 2;
end
end
- 是否a[i][j] == 1/a[j][i]:
if ERROR == 0
if sum(sum(A' .* A ~= ones(n))) > 0
ERROR = 4;
end
end
- n值是否过大超出一致性检验的范围
- n是否<=2,此时不必进行一致性检验:
RI=[0 0.00001 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15
% 这里n=2时,一定是一致矩阵,所以CI = 0,我们为了避免分母为0,将这里的第二个元素改为了很接近0的正数
对于n<=2的问题,也许也可以添加条件判断语句?
文章来源:https://blog.csdn.net/Eeeeye_/article/details/135750630
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!