决策树与随机森林
发布时间:2024年01月08日
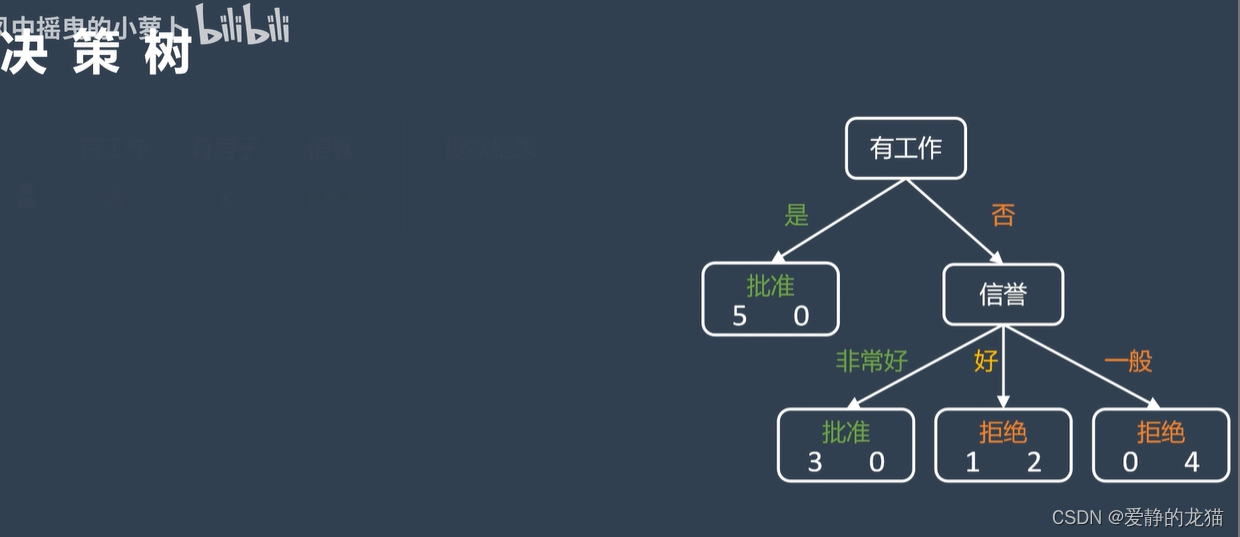
决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。
它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分。
决策树的标准好坏
可以用一个标准定义:基尼系数

当下标准的不确定程度
就是所有决策的概率之和
选择基尼系数最小的

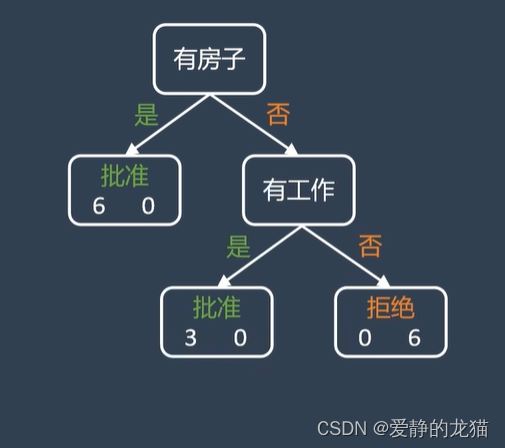
有三个标准,第一轮比较后选择房子

决策树的优缺点
一般选择二叉树
优点:
- 简单的理解和解释,树木可以可视化;
- 需要很少的数据准备,其他技术通常需要归一化。
缺点:
- 决策树学习者可以创建不能很好的推广数据的过于复杂的数,因为会产生过拟合。
改进:
- 随机森林
随机森林
包含很多决策树

随机森林就是通过集成学习的Bagging思想将多棵树集成的一种算法:它的基本单元就是决策树。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,其实这也是随机森林的主要思想--集成思想的体现。“随机”的含义我们会在下面讲到。
我们要将一个输入样本进行分类,就需要将它输入到每棵树中进行分类。将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想。

预设模型的超参数?
几个树,几个层?
随机采用,训练每一个决策树
输入待测样本,再把每个树的结果整合
优缺点

文章来源:https://blog.csdn.net/2302_79394843/article/details/135467349
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 官宣!OpenAI正式推出GPT商店:已有超300万自定义ChatGPT
- Java小案例-RocketMQ的11种消息类型,你知道几种?(请求应答消息)
- Vue中避免滥用this去读取data中数据
- 前端性能优化之图像优化
- 一天吃透计算机网络面试八股文
- 一起玩儿物联网人工智能小车(ESP32)——25. 利用超声波传感器测量距离
- 浅析ARMv8体系结构:Memory Type
- 越权漏洞(以fish鲶鱼靶场举例)
- Nacos删除配置
- A股贵如金?Python量化验证AH股溢价效应,跟着买15年18倍?