Flink实战之时间语义
接下来本文分析Flink的时间语义。时间语义是Flink中非常精妙的一部分设计,也可以
说是Flink最为重要的一个设计。可以说如果不能很好的理解Flink的时间语义,那就无法保证流
式计算的数据处理是正确的。因此,有必要单独提出一个章节来分析时间语义。
之前已经介绍过,对于流式数据处理,顺序是非常重要的。而顺序是通过时间来表示的。尤其对于开窗计算,时间顺序不同会直接导致窗口无法正确的收集数据。但是,数据在网络传输的过程中,会产生各种中断或者延迟。很可能后发生的消息,经过网络传输后,反而先到达Flink进行计算。或者某些连续的数据由于网络不稳定产生了终端。最终处理的顺序就乱了。因此,就有必要定义不同的时间语义,用来管理消息的顺序。
1、Flink的三种自然时间语义
在Flink中定义了三种基本的时间语义:
1 Event Time: 事件真实发生的时间。
2 Ingestion Time: 事件进入Flink的时间。也就是由Data Source读入的时间。
3 Process Time: 事件进入Processor真正开始计算的时间。
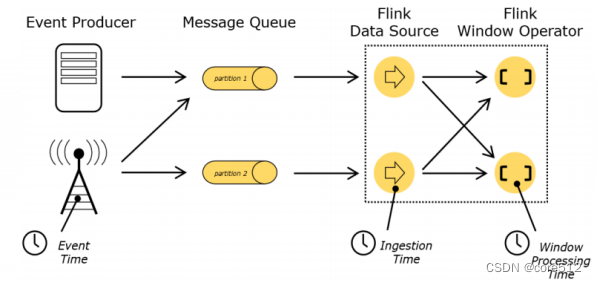
在这三种时间语义当中,通常情况下,我们关注最多的是EventTime,因为那才是计算过程中真正需要关心的时间,但是Flink是无法直接知道Event的发生时间的。IngestionTime没有太多业务价值,通常不会太过关心。而ProcessingTime是Flink能够自行知道的时间,在EventTime不确定的情况下,Flink就只能根据ProcessingTime来进行计算了。
关于Event Time和Procss Time,其实在之前的开窗函数中经常看到。Flink对不同的时间语义提供了很多默认的开窗函数。
2、设置Event Time
在大部分的业务场景下,我们更应该关注的其实是Event Time。比如,我们对一个系统的日志进行一些时间敏感的流式操作时,更关注的应该是从log日志中分析出来的事件时间EventTime,而不会太关注Flink是什么时候开始计算的,也就是ProcessTime。
如果需要使用Event Time,需要在StreamExecutionEnvironment中进行设置。具体可以自行进行指定
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
但是你会注意到,在Flink1.12版本中,这个设置的API已经过期了,因为在1.12版本中,Flink已经将默认的ProcessTime改为了EventTime,因此,就不再需要显示的进行声明了。如果要使用ProcessTime,大部分场景下都提供了显示的API调用。
接下来,事件发生其实是在Flink计算之前的,是Flink所不知道的。所以要使用事件时间语义,那就必须要告诉Flink事件时间的定义。通常事件时间都是作为事件中的一个字段传递进来,例如下面的示例就指定使用Stock时间自己的timestamp字段作为EventTime。
final WatermarkStrategy<Stock> stockWatermarkStrategy = WatermarkStrategy.
<Stock>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Stock>() {
@Override
public long extractTimestamp(Stock element, long recordTimestamp) {
return element.getTimestamp();
}
});
stockStream.assignTimestampsAndWatermarks(stockWatermarkStrategy);
在Watermark的定义过程中, forBoundedOutOfOrderness就是Flink针对乱序数据提供的一种实现方法。另外还有一个forMonotonousTimestamps方法是Flink针对单调有序的数据提供的一种实现方法。这里就涉及到了另一个概念,Watermark。这是Flink中用来进行时间定义的一个重要概念。具体的区别会在后面讲解WaterMark的时候再来理解。
接下来的withTimestampAssigner方法是给数据指定EventTime的一种方法。这个方法是可选的,Flink新版本中对于时间语义做了大量的优化,在计算过程中,会尽最大的努力自行获取EventTime。例如没有指定EventTime的情况下,会自动使用ProcessingTime来计算。例如如果使用Flink提供的kafka connector,那Flink会去识别kafka各个分区的消息投递时间,自动完成EventTime的设置。
3、 Flink如何处理乱序数据?
现在分析清楚了Event Time和Process Time两种时间语义,那在进行window开窗操作时,乱序的问题就出现了。例如我们考虑这样的情况,有1到6这样五个事件发送到Flink。
(1) -> (2) -> (3) -> (4) -> (5) -> (6)
这个示例中每个括号里的数字表示这个事件的发生时间,单位假定为秒。 Event Time。很显然,这是正常不发生乱序的情况。现在我们按照每5秒开启一个滚动窗口。那Flink的处理顺序是这样的, 会预先开启一个[0,5)的一个左开右闭的bucket,用来接收从0秒到5秒的事件。依次将事件放到这个bucket里。当发现第五秒的消息 (5) 到了之后,就将这个bucket进行关闭,不再接收新的数据,准备进行后续的窗口聚合操作。
这是正常的处理流程。但是如果数据在网络传输过程中出现了乱序,例如像这样
(1) -> (2) -> (5) -> (3) -> (4) -> (6)
那同样的开窗过程就会出现问题。Flink依然是按照[0,5)开启一个窗口。但是当(5)数据过来时,Bucket已经关闭,进行后续的窗口计算了。那后面的(3) 和 (4) 两个数据就没有bucket来存放了。那这样的乱序数据要如何处理呢?
Flink会通过一系列完整的机制来处理数据乱序问题。
1 WaterMark 水位线。窗口可以设置一个短暂的等待时间,等后面的数据到了,再关闭窗口。
2 allowLateness 延迟窗口关闭时间。在窗口关闭后设置一个延迟时间,延迟时间内到达的数据,会在后续窗口计算过程中重新进行一次窗口聚合。
3 sideOutputStream 侧输出流 这是最后的兜底方案。窗口完成聚合计算后,就不再接收数据了。这些长期迟到的数据,用户只能选择另外收集一个侧输出流中,自己决定该要如何处理。
4、WaterMark 水位线
4.1 水位线机制
Watermark是Flink处理乱序数据的第一道闸门,也是最为重要的一个机制。
首先来理解下什么是Watermark
Watermark的本质就是一个时间戳,表示数据的事件时间Event Time推进到了哪一个时间点。从数据形式上,Watermark是只增不减的,这也是Watermark这个词的意义,这代表着事件在按正常时间顺序往下推进。Watermark必须与事件时间相关联,这样Watermark才有业务含义。Watermark会随着数据流一起传输,可以把它看成是一个特殊的数据。
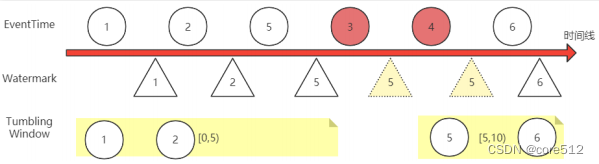
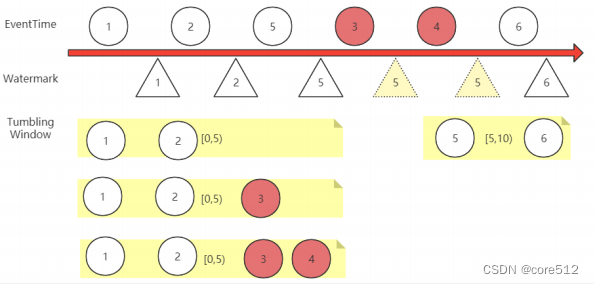
从上面这个图,我们可以理解一下Watermark的基本工作机制:
1 Watermark只增不减。例如图中 5,3,4 三个事件发生了乱序,那Watermark只会记录最高位的5。直到后面6数据来了之后,才会往上继续推高。
2 Flink对数据流进行开窗后,会根据事件时间EventTime来判断数据属于哪一个窗口。但是窗口何时关闭,则通过Watermark来判断。例如,对一个KeyedStream,进行5秒的滚动开窗Tumbling Window后,Flink会依次划分多个window(这些window的本质是一个一个的Bucket,数据桶),每个window都是左开右闭的,就会划分出[0,5),[5,10)这样的一个一个窗口。这些窗口会依靠Watermark水位线来判断是否需要关闭。图中,[0,5)这个窗口会等到5号Watermark出现时,就进行关闭,开始进行后续的窗口聚合计算。
3 如果事件时间的顺序是一致的,那么这样的窗口划分是没有什么问题的。 但是事件时间发生乱序时,就不可避免的会造成数据丢失。例如图中,当事件3和事件4过来时,[0,5)这个窗口已经关闭,无法再接收数据。如果不做处理,那么事件3和事件4在流式计算过程中就丢失了。
Watermark如何处理乱序问题
Watermark处理乱序问题的方式比较简单,就是与真实的事件时间EventTime之间,保存一个延迟。
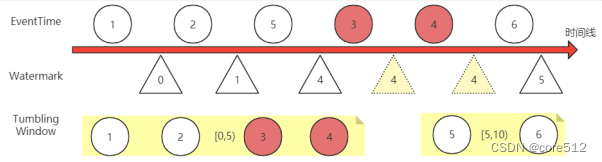
例如还是上面的示例,如果让Watermark与EventTime之间保持一个1秒的延迟,那么当5号事件过来时,Watermark还只到4,[0,5)这个窗口就不会关闭,会继续等待收集新的事件。事件3和事件4就能正常被这个窗口收集。而直到事件6过来后,Watermark被推高到了5,这时[0,5)这个窗口才会关闭,停止收集数据,开始进行后续的窗口聚合计算。
Watermark的这个延迟时间一般不宜设置过长,因为会影响事件的响应速度。另外,由于无法精确的预测事件的乱序程度,所以,Watermark机制并不能完全处理乱序问题。还需要有后续的兜底方案。
你可以把window比作一辆班车,这个班车专门接送下午五点到六点之间下班的员工回家。但是到了六点这一刻,可能还有一部分员工在路上,没有赶过来。这时,希望班车可以稍微晚一点出发,尽量让路上的员工能够赶得上。那这时的做法是什么呢?WaterMark机制的做法就是调整班车上的时间表,把班车上的时间往前调两分钟。公交车司机依然是在自己认为的六点整这一时刻发车,但是实际上发车时间延迟到了六点过2分,这样,在这2分钟之内赶过来的员工,依然还是可以上车。很显然,在这种机制下,等待的时间是不宜过长的,因为一整车的员工还在车上等着呢。
如何分配Watermark
这样再回头来看之前的WatermarkStrategy定义:
final WatermarkStrategy<Stock> stockWatermarkStrategy = WatermarkStrategy.<Stock>forBoundedOutOfOrderness(Duration.ZERO);
对于乱序的数据流,forBoundedOutOfOrderness方法传入的这个时间参数,就是表示这个延迟时间。而如果事件时间本身就是严格有序递增的,那就不会有乱序的问题,也就不需要有延迟时间了。所以WatermarkStrategy针对有序数据流提供的forMonotonousTimestamps方法,就不再需要传一个时间参数了。
final WatermarkStrategy<Stock> stockWatermarkStrategy =
WatermarkStrategy.forMonotonousTimestamps();
接下来还有一个问题,Watermark的推高都是通过事件来推动的,那如果一个数据流长期没有事件,就会造成Watermark长期得不到推高,很多window窗口,就会进行无用的数据数据等待。这时,WatermarkStrategy就提供了一个处理空闲数据流的方式,来定时推高Watermark。
final WatermarkStrategy<Stock> stockWatermarkStrategy =
WatermarkStrategy.withIdleness(Duration.ofSeconds(10))
4.2 定制Watermark生成策略
Flink内置的针对有序数据流和无序数据流的两个Watermark机制,已经能够应对大部分的自定义计算过程。但是,在对接一些特定数据源时,其实可以将Watermark的分配机制整合到Source数据源中。例如,如果使用Flink提供的Kafka connector,就不需要定制Watermarkstrategy,因为Flink提供的消费者端已经实现了一套WatermarkStrategy了。
在WatermarkStrategy类内部,有一个WatermarkGenerator接口的属性,负责生成Watermark。如果需要自己定制Watermark实现类,可以通过实现WatermarkGenerator接口的方式来定制。这个接口的定义也比较简单明了。
@Public
public interface WatermarkGenerator<T> {
/**
* 每个事件到来时调用。
* event 传入的事件
* eventTimestamp 就是当前抽取出来的事件时间。
* output 通过output.emitWatermark方法推高新的Watermark。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 定期进行调用。
* 调用的间隔事件根据配置ExecutionConfig#getAutoWatermarkInterval()
*/
void onPeriodicEmit(WatermarkOutput output);
}
WatermarkGenerator中两个方法的作用都比较明显,由此,可以再去看下内置的两个
WatermarkGenerator是如何实现的。
WatermarkStrategy.forBoundedOutOfOrderness(Duration)方法实际上就是给WatermarkStrategy指定了一个BoundedOutOfOrdernessWatermarks实现。当前版本下,他的源码是这样的:
@Public
public class BoundedOutOfOrdernessWatermarks<T> implements WatermarkGenerator<T> {
/** The maximum timestamp encountered so far. */
private long maxTimestamp;
/** The maximum out-of-orderness that this watermark generator assumes. */
private final long outOfOrdernessMillis;
/**
* Creates a new watermark generator with the given out-of-orderness bound.
* @param maxOutOfOrderness The bound for the out-of-orderness of the event
timestamps.
*/
public BoundedOutOfOrdernessWatermarks(Duration maxOutOfOrderness) {
checkNotNull(maxOutOfOrderness, "maxOutOfOrderness");
checkArgument(!maxOutOfOrderness.isNegative(), "maxOutOfOrderness cannot be
negative");
this.outOfOrdernessMillis = maxOutOfOrderness.toMillis();
// start so that our lowest watermark would be Long.MIN_VALUE.
this.maxTimestamp = Long.MIN_VALUE + outOfOrdernessMillis + 1;
}
//每次事件过来,就推高Watermark
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
maxTimestamp = Math.max(maxTimestamp, eventTimestamp);
}
//定期发送Watermark
@Override
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
}
而WatermarkStrategy.forMonotonousTimestamps()方法的实现方式则更加简单粗暴。最终指定的AscendingTimestampsWatermarks策略就是Duration为0的BoundedOutOfOrdernessWatermarks。
@Public
public class AscendingTimestampsWatermarks<T> extends BoundedOutOfOrdernessWatermarks<T>
{
/** Creates a new watermark generator with for ascending timestamps. */
public AscendingTimestampsWatermarks() {
super(Duration.ofMillis(0));
}
}
4.3 Watermark传播机制
我们在开始设置环境时就将环境的平行度设置为1,env.setParallism。这样,只要有一个超过了Watermark的数据进来,就会关闭上一个计算窗口。但是,如果将并行度设置为其他的值,例如4。那你会发现,提交一个超过Watermark的数据,并不会触发上一个计算窗口的关闭动作,而需要等到积累了4个或者以上的超过Watermark的数据时,才会触发上一个计算窗口的关闭动作。这中间其实涉及到了Watermark在Slot之间的传递机制。
在定制Watermark生成策略时,通过WatermarkOutput的emitWatermark往下游发射Watermark。而Flink中,这个Watermark会在各个计算流程之间传递,并在处理过程中进行整合。例如某一个计算任务,他的上游任务有N个并行度,那就有N个Slot进行并行计算。由于每个Slot的处理时间及网络传输时间不一样,也就会产生N个不同的Watermark。那当前任务就需要将所有的上游Watermark都保留下来,然后选取最靠后的Watermark作为上游计算的整体Watermark。
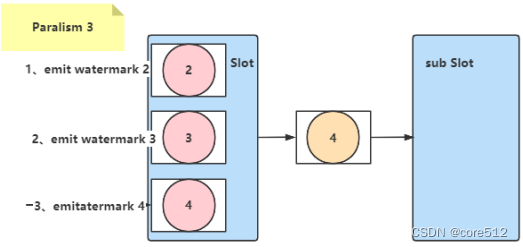
这种传播机制,对于SocketStream这个数据源,有序需要阻塞线程,所以只能以一个线程(也
就是并行度1)读取数据。所以这时,Flink只能通过读取三个或以上的数据,将这些数据尽量平均
的分配给各个线程(并行度),这样才能保证能够正常往下游slot传递Watermark。所以才会出现
示例中说到的那种情况。
在对接Kafka这样的数据源时,这个问题就不会太过明显。因为这些数据源本身就实现了多线程的数据读取。
5、allowLateness 允许等待时间
对于WindowedStream和AllWindowedStream,可以通过allowLateness设置一个等待时间,作为watermark后的补充。
默认情况下,这个等待时间是被设置为0,当事件的EventTime晚于watermark后,这个事件就会被抛弃,也就是说,窗口将不再接收这些数据。
而Flink对于这些迟到的数据,允许进行一些补偿处理。当手动设置了等待时间,例如5秒后。Flink依然会在watermark时间到了之后关闭窗口,进行后续的窗口集合计算。但是,在只有5秒内,有事件进来时,Flink会重新进行一次聚合计算,将这些新来的事件包含进来。
对于之前提到的比喻: 当班车在六点过2分出发,到达目的地后,将进行一次点名登记。这时,如果设置一个3分钟的等待时间。从六点过2分到六点过5分,这段时间,允许员工自行赶到目的地。如果等待时间内,有员工过来了,就重新进行一次点名登记。只到六点过5分后,再有员工赶过来,也不再进行点名登记了。
从这个机制中可以看出,等待时间内的数据处理是比较消耗性能的,所以等待时间一般不宜设置过长。另外,注意下,在TumblingWindow下,每个数据肯定都是有所属窗口的。
6、sideOutputStream 侧输出流
通过上面两个步骤,对于乱序数据,Flink已经做了两次的宽大处理。一次是Watermark,对于短期迟到的数据,Watermark机制可以让窗口等待迟到数据来了再关闭窗口。另一次是延迟时间allowLatenenss,对于超过Watermark等待时间的迟到数据,延迟时间机制可以在迟到数据到达窗口后,重新进行一次后续窗口聚合计算。但是,这些机制依然无法保证所有数据能够完全被窗口收录。对于那些超过了最长等待时间的事件,Flink的处理思路是不再提供统一的处理,而是将这些事件单独放到另一个侧输出流中,由用户决定到底要如何处理这些数据。到底是将这些数据抛弃掉,还是进行一些补偿的计算行为,都由用户程序来决定。
侧输出流的作用其实还不只是在于处理乱序数据,他是完全交由用户自行完成的一个补偿机制。从一个主要的DataStream数据流中,可以产生任意数量的侧输出结果流。并且这些结果流的数据类型也不需要完全与主要的数据里中的数据类型一致。并且不同的侧输出流,他们的类型也不必要完全相同。总之,这个测数据流完全由用户自行把控。
使用输出流,首先需要进行明确的定义。
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};
接下来可以通过用户自定义的一些Funciton算子来实现侧输出流的数据收录。包括:
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
关于ProcessFunction,是Flink提供的一套底层基础API。我们之前了解的各种DataStreamAPI,都是基于ProcessFunction这一套API构建起来的,具体可以参见:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/stream/operators/process_function.html
你可以使用在上述方法中向用户暴露的context参数,将数据发送到outputtag标识的侧输出流。例如这样:
DataStream<Integer> input = ...;
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = input
.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(
Integer value,
Context ctx,
Collector<Integer> out) throws Exception {
// 发送数据到主要的输出
out.collect(value);
// 发送数据到旁路输出
ctx.output(outputTag, "sideout-" + String.valueOf(value));
}
});
接下来,可以在DataStream的运算结果上使用getSideOutput(OutputTag)方式获取侧输出流,进行后续的侧输出流处理。
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = ...;
DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);
整个侧输出流相当于是对所有异常数据的一个兜底操作,不光对于超时的事件可以用侧输出流进行最后的补偿处理,对于一些不正确的噪点事件,也可以用侧输出流的方式进行最后的操作。而对于侧输出流中没有捕获的事件, Flink就爱莫能助,只能放弃了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python实验:关灯游戏
- 【LeetCode每日一题】447. 回旋镖的数量(枚举+哈希表)
- RTMP vs SRT:延迟与最大带宽的比较
- 【C++PCL】点云处理最小图割分割
- 嵌入式培训机构四个月实训课程笔记(完整版)-Linux网络编程第一天-socket编程(物联技术666)
- 从零开始学习Python基础语法:打开编程大门的钥匙
- TA百人计划学习笔记 3.2混合模式及剔除
- linux cuda环境搭建
- R语言【cli】——ansi_strwrap():将ANSI样式的字符串包装为一定的宽度
- 《网络是怎样连接的》2.5节图表(自用)