Qdrant向量数据库
Qdrant 是专为扩展过滤支持而设计的向量相似度搜索引擎和向量数据库,这使得它适用于各种基于神经网络的语义匹配、图像搜索等应用。
Qdrant 使用 Rust 🦀 编写,即使在高负载下也能快速、可靠地工作。
Qdrant架构
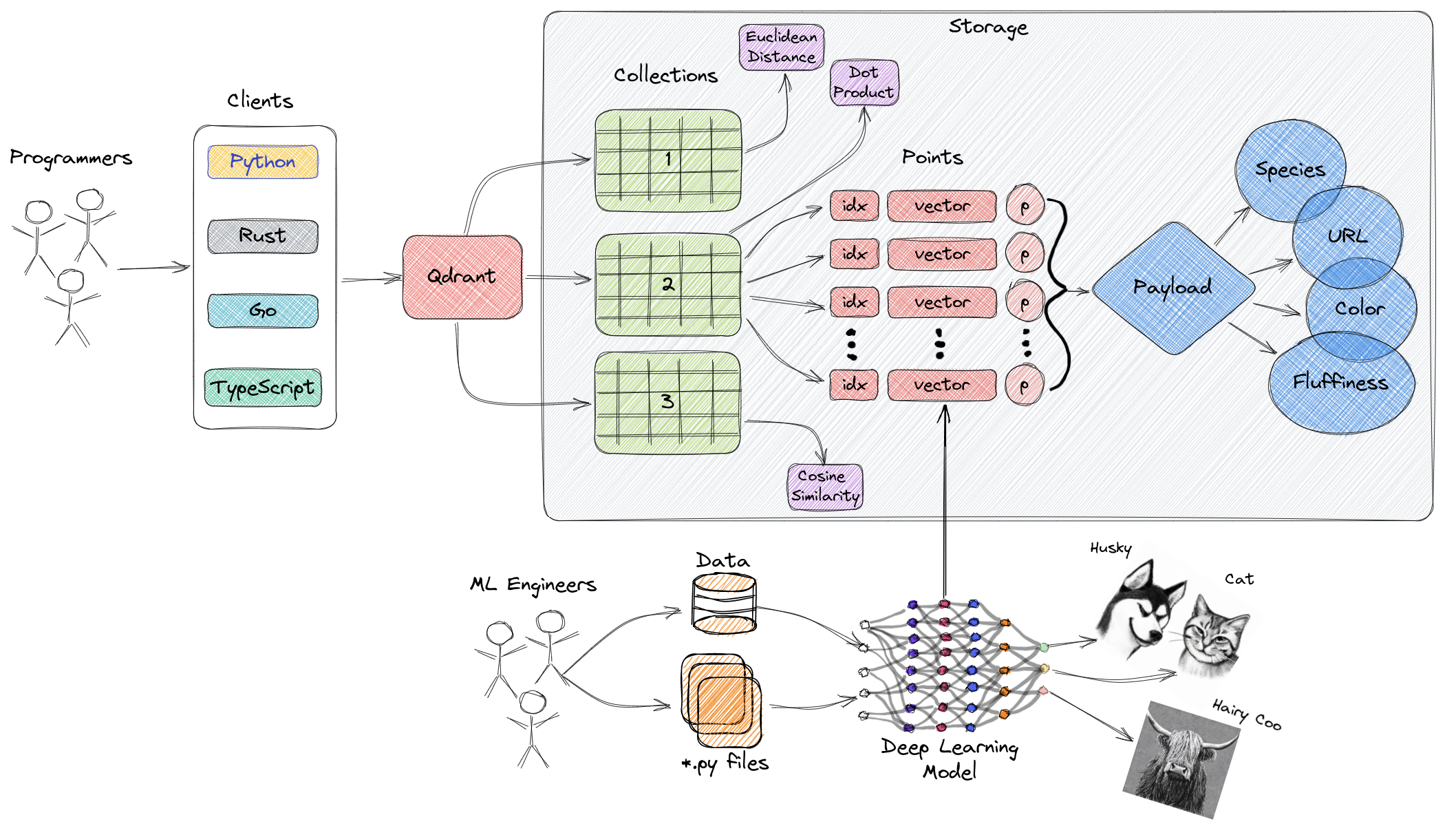
上图展示了 Qdrant 一些主要组件的高级概述。以下是您应该熟悉的术语。
- 集合(Collections):集合是一组命名的点(带有有效负载的向量),您可以在其中进行搜索。同一集合中每个点的向量必须具有相同的维度,并通过单个度量进行比较。命名向量可用于在单个点中包含多个向量,每个向量都可以有自己的维度和度量要求。
- 距离度量(Distance Metrics):这些用于测量向量之间的相似性,必须在创建集合的同时选择它们。度量的选择取决于向量的获取方式,特别是取决于将用于编码新查询的神经网络。
- 点(Points):点是 Qdrant 运行的中心实体,它们由向量和可选的 id 和有效负载组成。
-
- id:向量的唯一标识符。
- 矢量(Vector):数据的高维表示,例如图像、声音、文档、视频等。
- 有效负载(Payload):有效负载是一个 JSON 对象,其中包含可以添加到向量中的附加数据。
- 存储(Storage):Qdrant 可以使用两种存储选项之一:内存存储(将所有向量存储在 RAM 中,具有最高速度,因为仅需要持久性才需要磁盘访问)或Memmap存储(创建与磁盘上的文件)。
- 客户端:可用于连接到 Qdrant 的编程语言。
快速开始
在开始之前,请确保 Docker 已安装并在您的系统上运行。
快速启动
docker run --privileged -p 6333:6333 qdrant/qdrant--privileged 是我本地执行时出现Operation not permitted进程创建受限加的,一般不用加

数据挂载启动
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant在默认配置下,所有数据都将存储在该./qdrant_storage目录中。
Qdrant 现在可以访问:
- REST API:本地主机:6333
- 网页用户界面:本地主机:6333/dashboard
- GRPC API:本地主机:6334
网页直接访问面板: http://127.0.0.1:6333/collections/dashboard
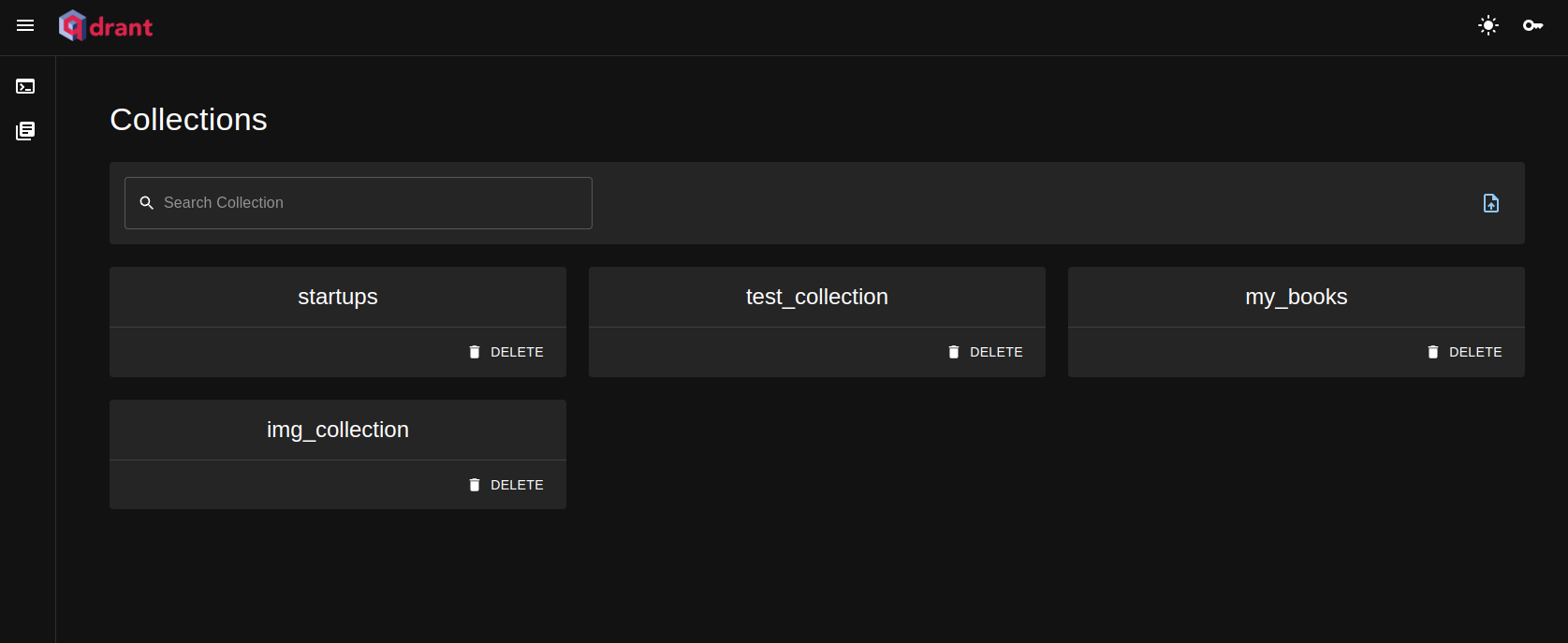
网页直接访问API:http://127.0.0.1:6333/collections,就可以看到
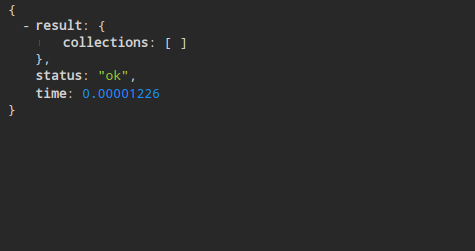
collections返回当前的所有集合,那就让我们来用python客户端连接,并创建一个集合吧
增删改查
创建一个集合
您将把所有矢量数据存储在 Qdrant 集合中,我们就这样称呼它test_collection吧。该集合将使用点积距离度量来比较向量。
from qdrant_client.http.models import Distance, VectorParams
client.create_collection(
collection_name="test_collection",
vectors_config=VectorParams(size=4, distance=Distance.DOT),
)
size:向量的大小(维度)
distance:距离度量类型
- COSINE 余弦相似度(Cosine similarity):余弦相似度是一种常用的向量相似度度量方法,它衡量了两个向量之间的夹角余弦值。在Qdrant中,可以使用COSINE作为距离度量方法来计算余弦相似度。
- EUCLID 欧氏距离(Euclidean distance):欧氏距离是最常见的距离度量方法,用于计算向量空间中两个向量之间的直线距离。在Qdrant中,可以使用L2作为距离度量方法来计算欧氏距离。
- 点积(Dot Product):它是一种常见的向量运算。点积是将两个向量的对应元素相乘,并将乘积相加得到的标量值。可以使用点积来计算向量之间的夹角余弦值。夹角余弦值反映了两个向量的方向相似程度。夹角余弦值的取值范围在 -1 到 1 之间。
相似性学习模型中最典型的度量是余弦度量。

添加向量
现在让我们添加一些带有有效负载的向量。有效负载是您想要与向量关联的其他数据:
from qdrant_client.http.models import PointStruct
operation_info = client.upsert(
collection_name="test_collection",
wait=True,
points=[
PointStruct(id=1, vector=[0.05, 0.61, 0.76, 0.74], payload={"city": "Berlin"}),
PointStruct(id=2, vector=[0.19, 0.81, 0.75, 0.11], payload={"city": "London"}),
PointStruct(id=3, vector=[0.36, 0.55, 0.47, 0.94], payload={"city": "Moscow"}),
PointStruct(id=4, vector=[0.18, 0.01, 0.85, 0.80], payload={"city": "New York"}),
PointStruct(id=5, vector=[0.24, 0.18, 0.22, 0.44], payload={"city": "Beijing"}),
PointStruct(id=6, vector=[0.35, 0.08, 0.11, 0.44], payload={"city": "Mumbai"}),
],
)
print(operation_info)执行结果:
operation_id=0 status=<UpdateStatus.COMPLETED: 'completed'>运行查询
让我们问一个基本问题 - 我们存储的哪个向量与查询向量最相似[0.2, 0.1, 0.9, 0.7]?
search_result = client.search(
collection_name="test_collection", query_vector=[0.2, 0.1, 0.9, 0.7], limit=3
# , with_vectors=True, with_payload=True
)
print(search_result)执行结果:
ScoredPoint(id=4, version=0, score=1.362, payload={"city": "New York"}, vector=None),
ScoredPoint(id=1, version=0, score=1.273, payload={"city": "Berlin"}, vector=None),
ScoredPoint(id=3, version=0, score=1.208, payload={"city": "Moscow"}, vector=None)结果以相似度递减的顺序返回。请注意,默认情况下,这些结果中缺少有效负载和矢量数据。有关如何启用它的信息,请参阅结果中的有效负载和向量。
执行结果:
[
ScoredPoint(id=4, version=0, score=1.362, payload={'city': 'New York'}, vector=[0.18, 0.01, 0.85, 0.8]),
ScoredPoint(id=6, version=0, score=1.28, payload={'city': 'Berlin'}, vector=[0.05, 0.61, 0.76, 0.75]),
ScoredPoint(id=1, version=0, score=1.273, payload={'city': 'Berlin'}, vector=[0.05, 0.61, 0.76, 0.74])
]思考:上面的举例模式类似现实生活中什么场景呢???
添加过滤器
我们可以通过按有效负载过滤来进一步缩小结果范围。让我们查找包含“London”的最接近的结果。
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
search_result = client.search(
collection_name="test_collection",
query_vector=[0.2, 0.1, 0.9, 0.7],
query_filter=Filter(
must=[FieldCondition(key="city", match=MatchValue(value="London"))]
),
with_payload=True,
limit=3,
)
print(search_result)
执行结果:
ScoredPoint(id=2, version=0, score=0.871, payload={"city": "London"}, vector=None)您刚刚进行了矢量搜索。您将向量加载到数据库中并使用您自己的向量查询数据库。Qdrant 找到最接近的结果并向您提供相似度分数。
client.search()参数说明:
- collection_name(必需):要搜索的集合名称。
- query_vector(必需):查询向量。可以是以下类型之一:
-
- types.NumpyArray:NumPy 数组表示的向量。
- Sequence[float]:浮点数列表表示的向量。
- Tuple[str, List[float]]:带有向量名称的元组。
- types.NamedVector:命名向量对象。
- query_filter(可选):过滤器条件。可以使用 types.Filter 类型的对象来指定过滤条件。默认为 None。
- search_params(可选):搜索参数。可以使用 types.SearchParams 类型的对象来指定搜索参数。默认为 None。
-
- ef(可选):查询的有效范围(Efficient Search)。它控制搜索的速度和准确性之间的权衡。较高的值会提高搜索准确性,但会增加搜索时间。
- ef_search(可选):查询期间的最大搜索次数。它控制搜索的时间和资源消耗。较高的值会增加搜索时间,但可能提高搜索结果的准确性。
- limit(可选):返回结果的最大数量。默认为 10。
- offset(可选):结果偏移量,用于分页。默认为 0。
- with_payload(可选):是否返回结果的负载信息。
-
- True:返回搜索结果中的所有载荷数据。
- False:不返回任何载荷数据。
- Sequence[str]:指定要返回的特定载荷字段列表。
- with_vectors(可选):是否返回结果的向量信息。
- score_threshold(可选):结果的得分阈值。只返回得分高于或等于阈值的结果。默认为 None,表示不应用阈值。
- append_payload(可选):是否将负载信息追加到搜索结果中。默认为 True。
- consistency(可选):读一致性选项。可以是 types.ReadConsistency 类型的对象,用于指定读操作的一致性级别。默认为 None。
- **kwargs:其他可选参数。
search方法返回一个包含 types.ScoredPoint 对象的列表,每个对象表示一个得分较高的向量点。
我们可以根据需要使用这些参数来执行 Qdrant 的搜索操作,并根据返回结果进行进一步处理。
删除向量
def test_delete(self):
self.client.delete(
collection_name="test_collection",
points_selector=models.PointIdsList(
points=[6],
),
)删除指定过滤器下的向量
def test_delete_filter(self):
self.client.delete(
collection_name="test_collection",
points_selector=models.FilterSelector(
filter=models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(value="New York"),
),
],
)
),
)问题:上面入参的都是用vector=[0.05, 0.61, 0.76, 0.74]这种向量,那和我的业务数据怎么关联呢???
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大数据毕业设计:python房源数据爬虫分析预测系统+可视化 +商品房数据(源码+讲解视频)?
- linux可访问内网,如何设置访问域名网站
- Mybatis Java API - SqlSessionFactoryBuilder
- 【主题广范|见刊快】2024年教育科学与公共关系国际学术会议(ICEAPR 2024)
- CNAS中兴新支点——软件兼容测试从哪些方面判断
- Java项目学生管理系统一前后端环境搭建
- 中国农业银行 企业网上银行 相关注意事项合辑 不断更新中...
- MacOS - 苹果电脑程序还能正常启动,但图标消失不见了~
- JavaScript(第二篇)浮点数运算精度问题,一网打尽所有相关面试题
- Educational Codeforces Round 124 (Rated for Div. 2) (D 边缘点bfs推答案 C贪心)