【MySQL性能优化】- MySQL结构与SQL执行过程
MySQL结构与SQL执行过程
😄生命不息,写作不止
🔥 继续踏上学习之路,学之分享笔记
👊 总有一天我也能像各位大佬一样
🏆 博客首页 ??@怒放吧德德??To记录领地
🌝分享学习心得,欢迎指正,大家一起学习成长!

前言
上阶段初步学习了索引与优化,以及对Explain的使用,接着来就来初识一下SQL执行的时候底层是如何执行的,这样有助于我们对SQL的理解,才能够更好的对SQL进行优化。
SQL执行结构
首先,我们需要了解一下SQL执行的结构,我们通过一张图来简单的认识一下。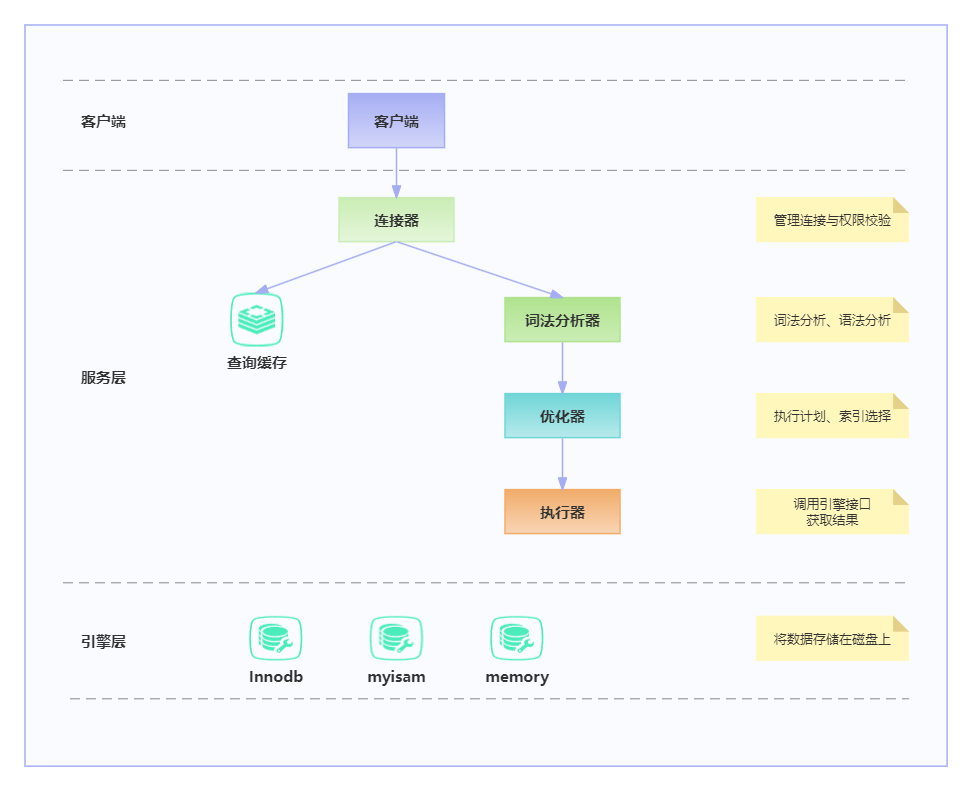
MySQL的架构可以大致分为两层:服务层和存储引擎层。
- 服务层:也被称为服务器层,主要包括连接处理、授权认证、事务管理、锁管理等服务器的一般性服务以及大部分的标准SQL功能实现。更具体的说,连接管理、缓冲查询、解析查询、优化查询以及执行查询等功能都在这一层实现。也就是在服务层进行SQL语句的解析、优化、缓存以及部分内置函数的实现,以及触发器、存储过程等。
- 存储引擎层:也被称为引擎层,负责数据的存储和提取,其架构模式使MySQL具有插件式的存储引擎架构,这是MySQL为数不多的跨平台数据库,支持多种存储引擎的数据库。这一层为上一层提供API接口,一些基础的功能如行级锁、事务等都通过各自的存储引擎来实现。
连接器
我们知道,MySQL其实也就是个服务器,是需要我们通过客户端(JDBC、Navicat等)去连接操作。而连接器就是负责管理客户端与服务器之间的连接。
:::info
当客户端向MySQL发起连接请求时,连接器就会进行身份校验,通过输入的账号密码来校验是否正确。如果认证成功,连接器还会在内部检查用户的权限等信息。
连接器还负责管理连接的生命周期,例如在没有活动的情况下,长时间未使用的连接可能会被自动断开(MySQL默认是8小时)。同时,连接器也负责复用已经建立好的连接,这样可以避免频繁进行连接和断开连接带来的开销。
:::
这里我们来介绍一下相关操作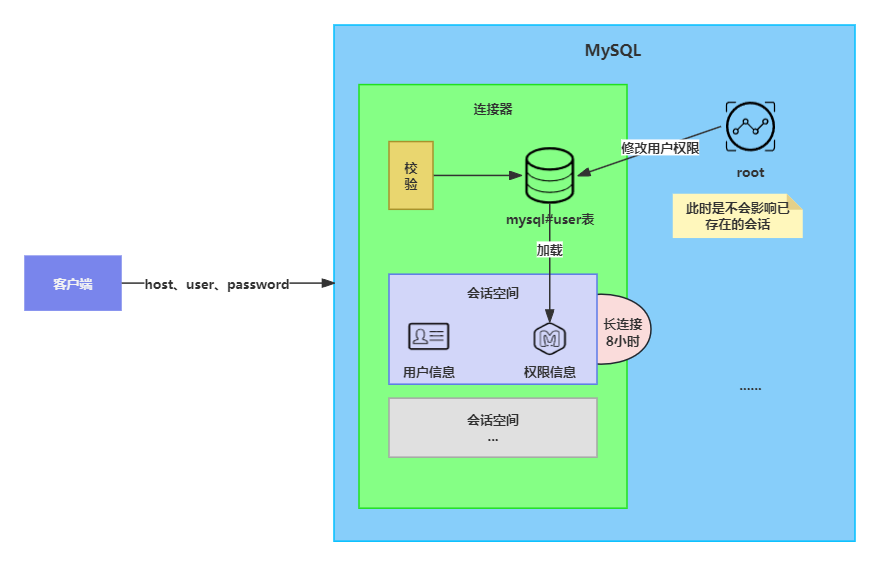
首先,通过用户、密码连接MySQL服务器,连接器会根据mysql数据库下的user表去进行用户校验和权限校验,还会根据host校验用户的host是否可以连接。此时连接器会开辟一个连接会话,里面会存储用户信息以及权限信息等,连接器会负责管理连接的生命周期,在没有活动的情况下,长时间未使用的连接可能会被自动断开。同时,连接器也负责复用已经建立好的连接,这样可以避免频繁进行连接和断开连接带来的开销。而默认存活时间是8小时。
如果使用root用户去修改了刚刚建立连接成功的用户的权限,那么是不会影响到已经存在的连接权限的。只有在新的连接才会刷新权限。
我们可以通过show processlist查看此时对数据库的连接情况。其中command列显示位Sleep就表示空闲连接。
mysql> show processlist;
+----+-----------------+-----------------+------------+---------+-------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------------+------------+---------+-------+------------------------+------------------+
| 5 | event_scheduler | localhost | NULL | Daemon | 14076 | Waiting on empty queue | NULL |
| 9 | root | localhost:64252 | shunhe_lms | Sleep | 7247 | | NULL |
| 10 | root | localhost:53424 | shunhe_lms | Sleep | 5473 | | NULL |
| 11 | root | localhost:53436 | shunhe_lms | Sleep | 5479 | | NULL |
| 12 | root | localhost:53437 | shunhe_lms | Sleep | 5972 | | NULL |
| 13 | root | localhost:56472 | NULL | Query | 0 | init | show processlist |
| 14 | root | localhost:56736 | rtmg_lms | Sleep | 3 | | NULL |
+----+-----------------+-----------------+------------+---------+-------+------------------------+------------------+
7 rows in set (0.00 sec)
当客户端连接MySQL成功后,如果没有后续操作,就会处于空闲状态。如果一直不发送command到服务端,连接器就会自动断开,默认时间是8小时,可以通过wait_timeout来控制。
mysql> show global variables like "wait_timeout";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+
1 row in set, 1 warning (0.01 sec)
所谓长连接,指的是客户端发起连接成功之后,如果还继续发送请求,就会使用同一个连接。如果每次执行完之后就断开连接了,下次的请求就需要再次重连,这就是短连接。
我们知道,如果每次需要与数据库进行通信时都建立新的连接并在使用完毕后关闭,会导致性能开销大,资源浪费,不适应高并发等问题。所以在开发中,我们通过会用到数据库连接池,由池来管理连接,常见连接池有(Druid、HikariCP、DBCP 、C3P0 、Proxool ),旨在提高数据库访问的性能和效率,在应用程序与数据库之间建立连接是一种开销较大的操作。但是此处需要注意的是,长连接有可能会导致MySQL占用大量内存系统资源,导致资源耗尽。这是因为MySQL在执行过程中临时使用的内存是管理在连接对象里面的。这些资源在连接断开的时候开会释放。如果长连接一直累积,就可能会导致内存占用过多,最终导致系统内存耗尽,触发 OOM 错误,表现出来就是MySQL服务器异常重启了。
查询缓存
MySQL查询缓存是一种用于存储查询结果的机制,以提高相同查询的性能。但是查询缓存是个非常鸡肋的功能,在MySQL8.0就已经废弃了这个功能。
先来了解一下查询缓存的工作原理:当一个查询被执行时,MySQL会检查查询缓存,看是否已经有相同的查询在缓存中。如果找到匹配的查询,MySQL会直接返回缓存中的结果,而不执行实际的查询。如果不在缓存中,则会继续后面的流程,执行完毕获取结果后,将结果存入查询缓存中。查询缓存会以key-value形式来存储。如果MySQL不是执行复杂操作,可以直接返回查询结果,这个效率会比较高。
那么为什么说查询缓存会被废弃呢?
这主要还是因为查询缓存弊大于利, 查询缓存的失效是非常频繁的。只要对一个表的更新,表上的所有查询缓存都会被清空,也有可能导致才把数据缓存起来,还没用到,但是又更新了,就会导致全部清空。对于频繁更新操作的数据来说,查询缓存的命中率就非常低。
对于频繁修改的数据固然不适合查询缓存,如果是字典表、参数表,像这种基本在于查询很少修改的才适合使用查询缓存。在MySQL的配置文件中,提供了按需使用的方式,需要在my.conf的配置文件中配置参数query_cache_type设置成DEMAND。
说到query_cache_type,就来简单学习一下。这是MySQL 中用于配置查询缓存的参数之一。该参数指定查询缓存的工作模式,决定是否启用查询缓存以及如何使用。
# my.conf
# 0/OFF(默认值):禁用查询缓存(OFF)
# 1/ON:启用查询缓存(ON),但只对具有 SQL_CACHE 标志的查询缓存结果。
# 2/DEMAND:启用查询缓存(DEMAND),但只对具有 SQL_NO_CACHE 标志的查询缓存结果。
query_cache_type=2
这样的设置就能够使用查询缓存。可以在查询语句的开头加上SQL_CACHE关键字来指定该查询需要被缓存。
SELECT SQL_CACHE * FROM table_name
可以通过以下指令来查询实例是否开启缓存机制
show global variables like "%query_cache_type%";
也可以查看缓存的命中率
show status like "%Qcache%";
其显示的参数如下:
- Qcache_free_blocks:表示查询缓存中的空闲块数。每个块是一个查询缓存中的内存单元。该参数显示了当前可用于存储新查询结果的空闲块数量。
- Qcache_free_memory:查询缓存中的空闲内存量。
- Qcache_hits:查询缓存命中的次数,表示有多少查询在缓存中找到了结果而不必实际执行。
- Qcache_inserts:向缓存中插入的查询次数,表示有多少查询被加入到查询缓存中。
- Qcache_lowmem_prunes:由于内存不足,从缓存中删除的查询数量。
- Qcache_not_cached:未被缓存的查询数量,表示有多少查询不符合缓存条件而没有被缓存。
- Qcache_queries_in_cache:缓存中当前存储的查询数量。
- Qcache_total_blocks:表示查询缓存中总共的块数。这是查询缓存的总内存块数量,包括已被使用和空闲的块。
注:MySQL8.0已经移除了查询缓存。
分析器
在执行SQL语句,需要对其进行解析,会先通过分析器进行词法分析。我们传入的SQL语句也就是一些字符串与空格拼接出来的语句,而MySQL需要知道这些字符串分别代表了什么意思。词法分析之后就需要进行语法分析。语法分析的主要任务是检查SQL语句的语法结构是否合法,并将其转换为一种数据库内部可以理解的形式。当检测到语法不对的时候,就会抛出You have an error in your SQL syntax;错误。
词法分析
词法分析会将输入的SQL语句分解成一系列的词法单元(tokens),每个词法单元代表一个关键字、标识符、运算符或其他语法结构。
将输入的SQL语句切割成一个个的词法单元。词法分析器识别关键字、标识符、运算符、常量等,并生成一个标记流(token stream)。
- 标记流是一个包含了从输入SQL语句中提取出的所有词法单元的序列。每个词法单元都是标记流中的一个标记。
- 标记类型:
- 关键字(Keywords): SQL语言的保留字,如SELECT、FROM、WHERE等。
- 标识符(Identifiers): 表名、列名等用户定义的标识符。
- 运算符(Operators): 比如+、-、*、/等。
- 常量(Literals): 字符串、数字等。
- 注释(Comments): SQL语句中的注释。
语法分析
语法分析负责将输入的SQL语句转换为语法树(Syntax Tree),从而能够理解和执行这个SQL语句。它反映了SQL语句的层次结构和语法关系。每个节点代表一个语法单元,而树的结构描述了SQL语句中的嵌套和顺序关系。
分析器的原理
我们可以通过一张图来了解整个分析器的执行流程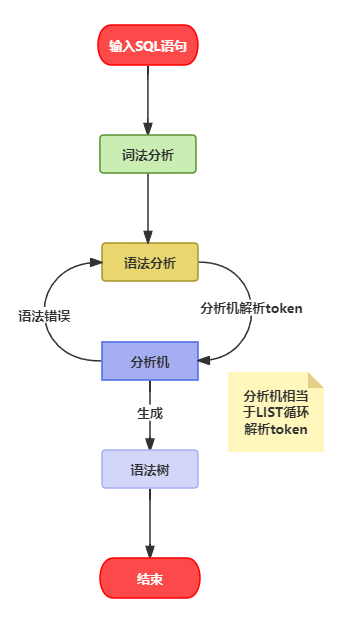
首先,当我们输入一条SQL语句,MySQL获取这条语句进行词法分析,①也就是会将输入的SQL语句分解为词法单元(tokens),每个词法单元代表一个关键字、标识符、运算符或其他语法结构,最终会生成表记流。接着进行语法分析,②分析机会根据SQL语句的语法规则,构建语法树,表示SQL语句的结构和语法关系。之后执行引擎就能够根据这棵语法树得知哪些字段,哪些条件。
语法分析树(Syntax Tree),也叫语法树*,是通过对输入文本进行语法分析而生成的一种树状结构。在数据库领域,语法分析树通常用于表示SQL查询语句的语法结构,它反映了语句中各个元素之间的层次关系和语法规则。在idea中可以使用
ANTLR v4的插件去查看解析出来的语法树。(antlr v4是根据语法生成解析器,构建和遍历解析树,不只是sql,只要是符合指定语法都能解析成树。)
生成的语法树如下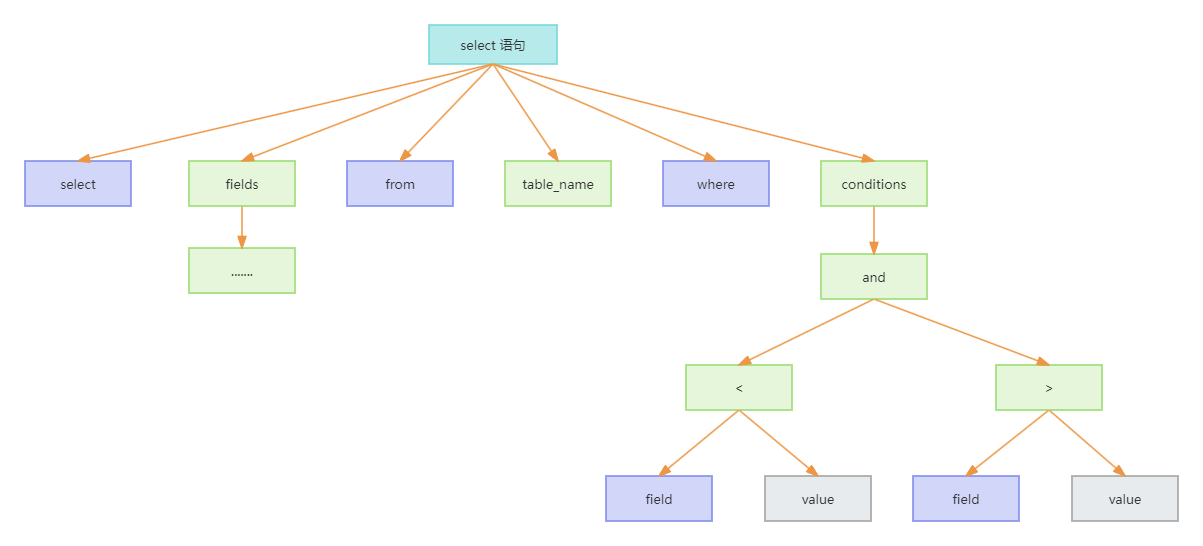
简单使用antlr v4
首先需要下载语法文件,可以通过https://github.com/antlr/grammars-v4/tree/master/sql/mysql/Positive-Technologies下载MySqlLexer.g4和MySqlParser.g4文件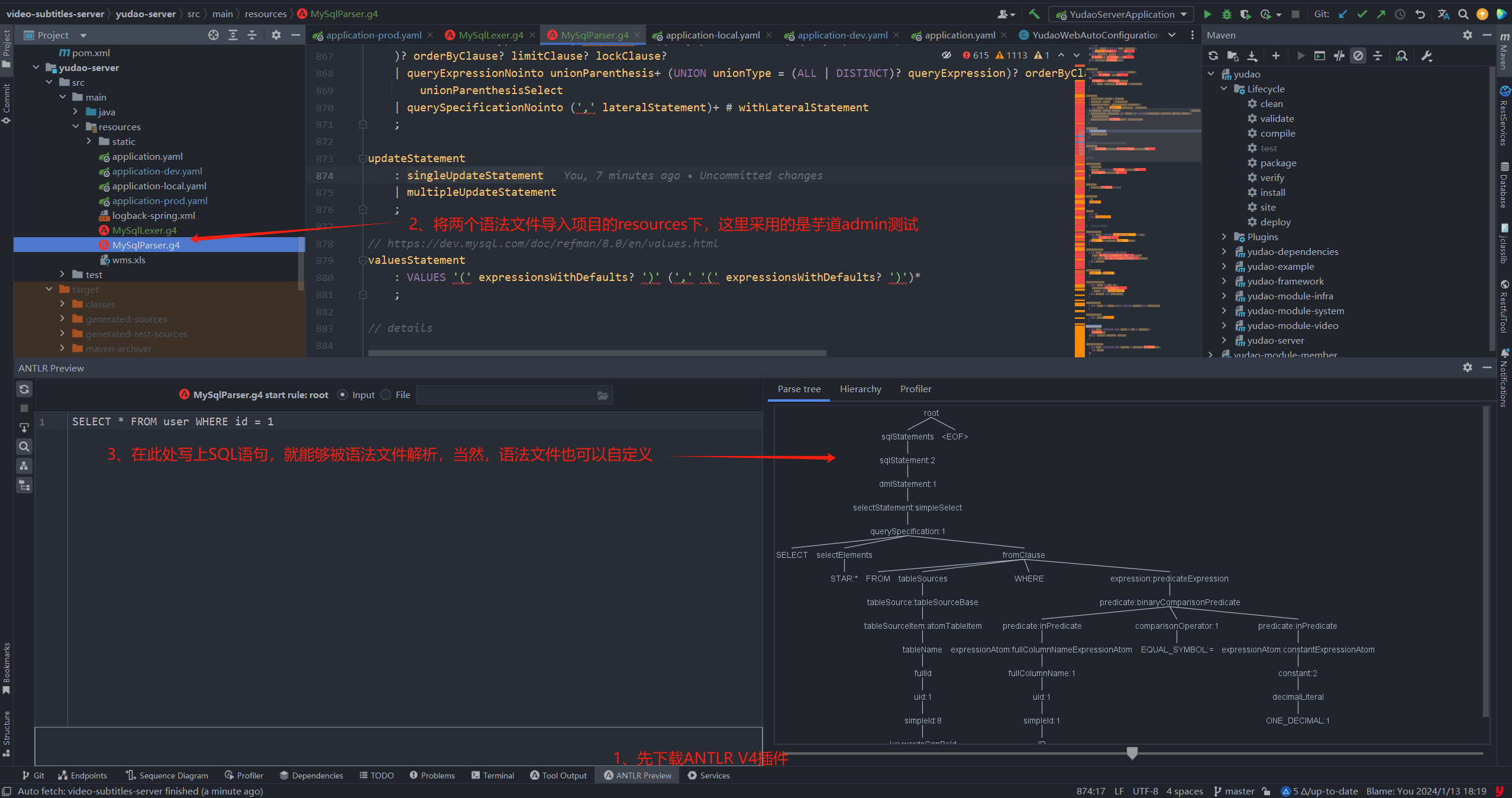
也可以自己选择构建的语法
可得测出来的结果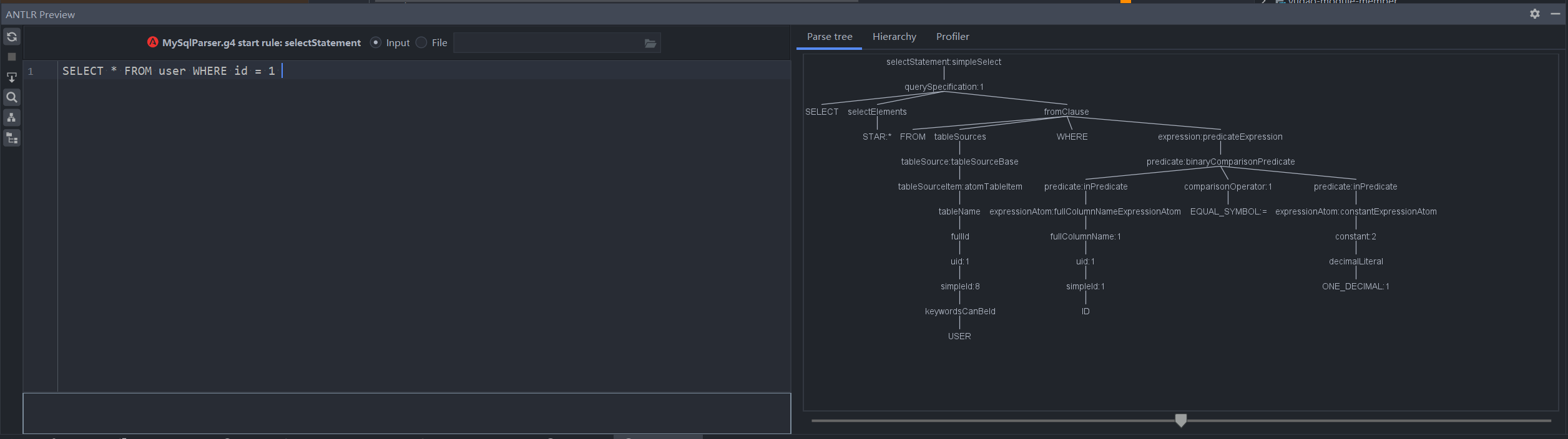
关于antlr v4这里推荐几篇博客:
优化器
在分析器将SQL语句的文本转换为一个解析树之后,优化器的任务就是找到最有效率的执行这个查询的方法。优化器的目标是选择一个最佳的执行计划,以最小化查询的总成本,包括CPU、IO等资源的使用。
当执行一条SQL的时候,能使用的索引有多个,那么此时就是由优化器来决定走哪个索引能够使执行效率更快。
执行器
执行器是负责执行查询计划的组件。在查询处理的最后阶段,优化器选择了一个最优的执行计划,而执行器则负责按照这个执行计划执行查询,获取实际的结果并返回给用户,但是在此之前会去校验一下用户有没有对这张表的查询权限,如果没有权限将会报权限错误。
我们根据一条SQL来理解执行器的作用。(假设user没有创建name的索引)
select name, age from user where name = ‘lyd’;
在执行器将要处理这条SQL的时候,如果有权限,将会打开user表继续执行,打开表的时候回去根据表的引擎定义,去使用引擎提供的接口。
- 调用innodb引擎接口获取表的第一行,判断name是不是’lyd’,如果不是就跳过,是的话就存到结果集。
- 调用innodb引擎接口获取下一行,重复相同判断,筛选数据集,直到最后一行。
- 执行器执行完,将符合条件的结果行组成记录集返回给客户端。
基本就是以上的流程,简单描述就是循环遍历+校验条件+存储行数据。如果是有索引的情况下,也是一样的道理,优化器会指定好索引,执行器会根据索引去遍历获取数据。
总结
总的来说,执行一条SQL语句需要先将语句进行词法分析,切分成一系列的词法单元。接着在根据语法分析器去进行语法分析,去解析词法单元(token),如果没有出现语法错误,将会SQL语句生成语法树。优化器会选择一个最优的执行计划。最后由执行器去执行SQL语句,筛选符合的结果集返回给客户端。本次学习记录了SQL执行结构与进行过程。
👍分享是提升的动力,创作不易,如有错误请指正,感谢观看!记得点赞哦!👍
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 100天精通Python(实用脚本篇)——第113天:基于Tesseract-OCR实现OCR图片文字识别实战
- 光伏收益计算工具:实现可持续能源投资的决策支持
- Docker部署Mysql5.7x和Myslq8.x
- python冒泡排序
- Java:选择哪个Java IDE好?
- 谷粒商城-商品服务-品牌管理-阿里云云存储+JSR303数字校验+统一异常处理
- 唱作歌手朱卫明的粤语版《兄弟情》:一曲深情唱尽人间真挚情感
- 【OD统一考试( C&D 卷)】反射计数 ,JAVA 解答
- 基于SpringBoot的乡村养老服务管理系统
- LabVIEW在机器人视觉抓取系统中应用