数据湖和传统数仓区别及湖仓一体
1.数据仓库
早期系统采用关系型数据库来存放管理数据,但是随着大数据技术的兴起,人们对于多方面数据进行分析的需求愈加强烈,这就要求建立一个能够面向分析、集成保存大量历史数据的新型管理机制,这一机制就是数据仓库。
数据仓库通常存储来自不同源的数据,集成源数据以提供统一的视图。这些资源可以包括事务系统、应用程序日志文件、关系数据库等等。
数据仓库特性:
- 面向主题:与传统数据库面向应用进行数据组织的特点相对应,数据仓库中的数据是面向主题进行组织的。在较高层次上完整、统一地刻划各个分析对象所涉及的企业各项数据,以及数据之间的联系。
- 集成:数据仓库的数据是从原有的分散的数据库数据中抽取得来。数据进入数据仓库之前,必然要经过统一与综合处理。
- 不断变化:为了发现业务变化的趋势、存在的问题,或者新的机会,需要分析大量的历史数据。换句话说,数据仓库中的数据是反映了某一历史时间点的数据快照,这也就是术语“随时间变化”的含义。同时,在从数据集成输入数据仓库开始到最终被删除,数据又是有生存周期的。
- 非易失:非易失指的是,一旦进入到数据仓库中,数据就不应该再有改变。数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一般情况下并不进行修改操作。
2.数据湖
随着当前大量信息化发展和电子设备产品普及,产生大量的照片、视频、文档等非结构化数据,人们也想通过大数据技术找到这些数据的关系。随之而来的数据湖就产生了。
数据湖没有统一的概念,每家厂商都有其自己的理解,具体见上篇文章。但基本都包含以下特性。
数据湖特性:
-
统一的数据存储,存放原始的数据。
-
支持任意结构的数据存储,包括结构化、半结构化、非结构化。
-
支持多种计算分析,适用多种应用场景。
-
支持任意规模的数据存储与计算能力。
数据湖虽然适合数据的存储,但又缺少一些关键功能,比如不支持事务、缺乏一致性/隔离性、不保证执行数据质量等,这样的短板决定了,让数据湖来承载读写访问、批处理、流作业是不现实的。而且,数据湖缺乏结构性,一旦没有被治理好,就会变成数据沼泽。
3.数据仓库和数据湖区别

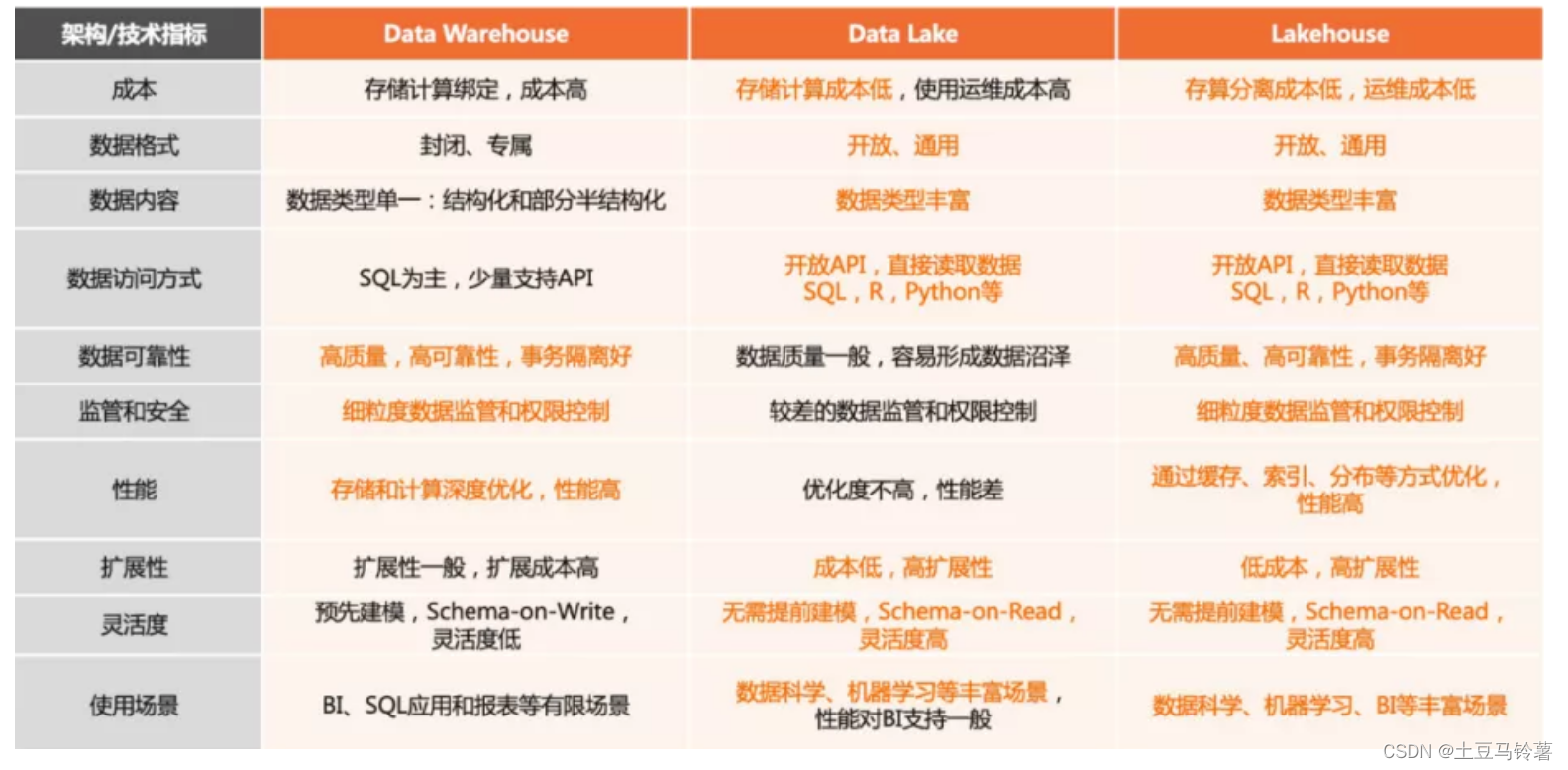
综合比较来看,数据仓库和数据湖,是大数据架构的两种设计取向。两者在设计的根本分歧点是对包括存储系统访问、权限管理、建模要求等方面的把控。
数据湖优先的设计,通过开放底层文件存储,给数据入湖带来了最大的灵活性。进入数据湖的数据可以是结构化的,也可以是半结构化的,甚至可以是完全非结构化的原始日志。另外,开放存储给上层的引擎也带来了更多的灵活度,各种引擎可以根据自己针对的场景随意读写数据湖中存储的数据,而只需要遵循相当宽松的兼容性约定。但同时,文件系统直接访问使得很多更高阶的功能很难实现,例如,细粒度(小于文件粒度)的权限管理、统一化的文件管理和读写接口升级也十分困难。
而数据仓库优先的设计,更加关注的是数据使用效率、大规模下的数据管理、安全/合规这样的企业级成长性需求。数据经过统一但开放的服务接口进入数据仓库,数据通常预先定义 schema,用户通过数据服务接口或者计算引擎访问分布式存储系统中的文件。通过抽象数据访问接口/权限管理/数据本身,来换取更高的性能(无论是存储还是计算)、闭环的安全体系、数据治理的能力等。
下面这个图很直接的说明了数据仓库和数据湖的区别:

4.湖仓一体
湖仓一体,即打通数据仓库和数据湖两套体系,让数据和计算在湖和仓之间自由流动,从而构建一个完整的有机的大数据技术生态体系。
湖仓一体的特性:
- 事务支持:Lakehouse可以处理多条不同的数据管道。这意味着它可以在不破坏数据完整性的前提下支持并发的读写事务。
- Schemas:数仓会在所有存储其上的数据上施加Schema,而数据湖则不会。Lakehouse的架构可以根据应用的需求为绝大多数的数据施加schema,使其标准化。
- 报表以及分析应用的支持:报表和分析应用都可以使用这一存储架构。Lakehouse里面所保存的数据经过了清理和整合的过程,它可以用来加速分析。同时相比于数仓,它能够保存更多的数据,数据的时效性也会更高,能显著提升报表的质量。
- 数据类型扩展:数仓仅可以支持结构化数据,而Lakehouse的结构可以支持更多不同类型的数据,包括文件、视频、音频和系统日志。
- 端到端的流式支持:Lakehouse可以支持流式分析,从而能够满足实时报表的需求,实时报表在现在越来越多的企业中重要性在逐渐提高。
- 计算存储分离:我们往往使用低成本硬件和集群化架构来实现数据湖,这样的架构提供了非常廉价的分离式存储。Lakehouse是构建在数据湖之上的,因此自然也采用了存算分离的架构,数据存储在一个集群中,而在另一个集群中进行处理。
- 开放性:Lakehouse在其构建中通常会使Iceberg,Hudi,Delta Lake等构建组件,首先这些组件是开源开放的,其次这些组件采用了Parquet,ORC这样开放兼容的存储格式作为下层的数据存储格式,因此不同的引擎,不同的语言都可以在Lakehouse上进行操作。
湖仓一体的优势
- 减少数据冗余:如果一个组织同时维护了一个数据湖和多个数据仓库,这无疑会带来数据冗余。在最好的情况下,这仅仅只会带来数据处理的不高效,但是在最差的情况下,它会导致数据不一致的情况出现。湖仓一体的结合,能够去除数据的重复性,真正做到了唯一。
- 降低存储成本:数据仓库和数据湖都是为了降低数据存储的成本。数据仓库往往是通过降低冗余,以及整合异构的数据源来做到降低成本。而数据湖则往往使用大数据文件系统和Spark在廉价的硬件上存储计算数据。湖仓一体架构的目标就是结合这些技术来最大力度降低成本。
- 拉通数据应用团队:数据科学倾向于与数据湖打交道,使用各种分析技术来处理未经加工的数据。而报表分析师们则倾向于使用整合后的数据,比如数据仓库或是数据集市。而在一个组织内,往往这两个团队之间没有太多的交集,但实际上他们之间的工作又有一定的重复和矛盾。而当使用湖仓一体架构后,两个团队可以在同一数据架构上进行工作,避免不必要的重复。
- 避免数据沼泽:在数据湖中,数据停滞是一个最为严重的问题,如果数据一直无人治理,那将很快变为数据沼泽。我们往往轻易的将数据丢入湖中,但缺乏有效的治理,长此以往,数据的时效性变得越来越难追溯。湖仓一体的引入,对于海量数据进行治理,能够更有效地帮助提升分析数据的时效性。
- 预防兼容风险:数据分析仍是一门兴起的技术,新的工具和技术每年仍在不停地出现中。一些技术可能只和数据湖兼容,而另一些则又可能只和数据仓库兼容。湖仓一体的架构意味着为两方面做准备。
数据仓库、数据湖和湖仓一体的区别:
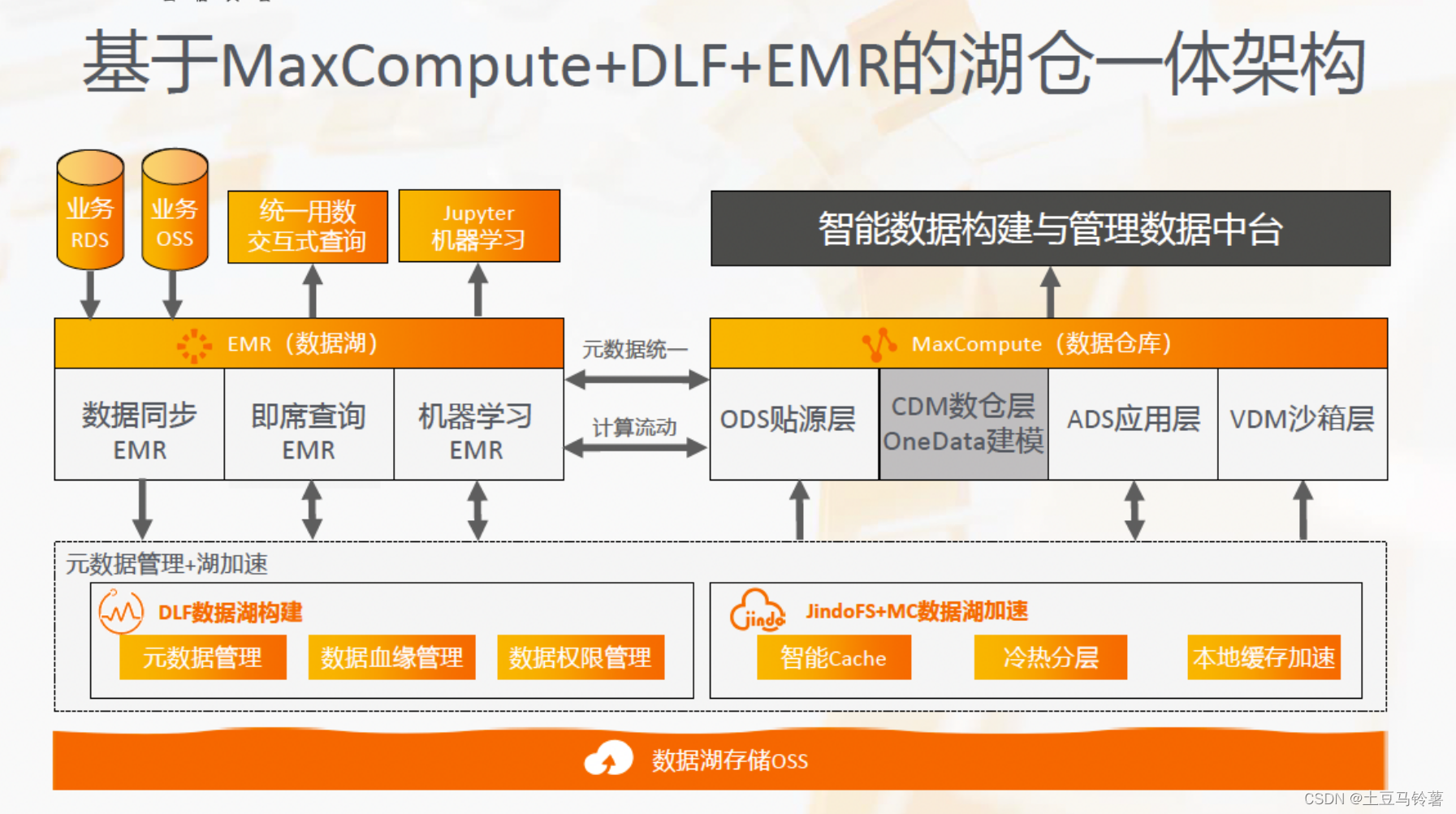
5.湖仓一体方案架构
典型的湖仓一体架构:
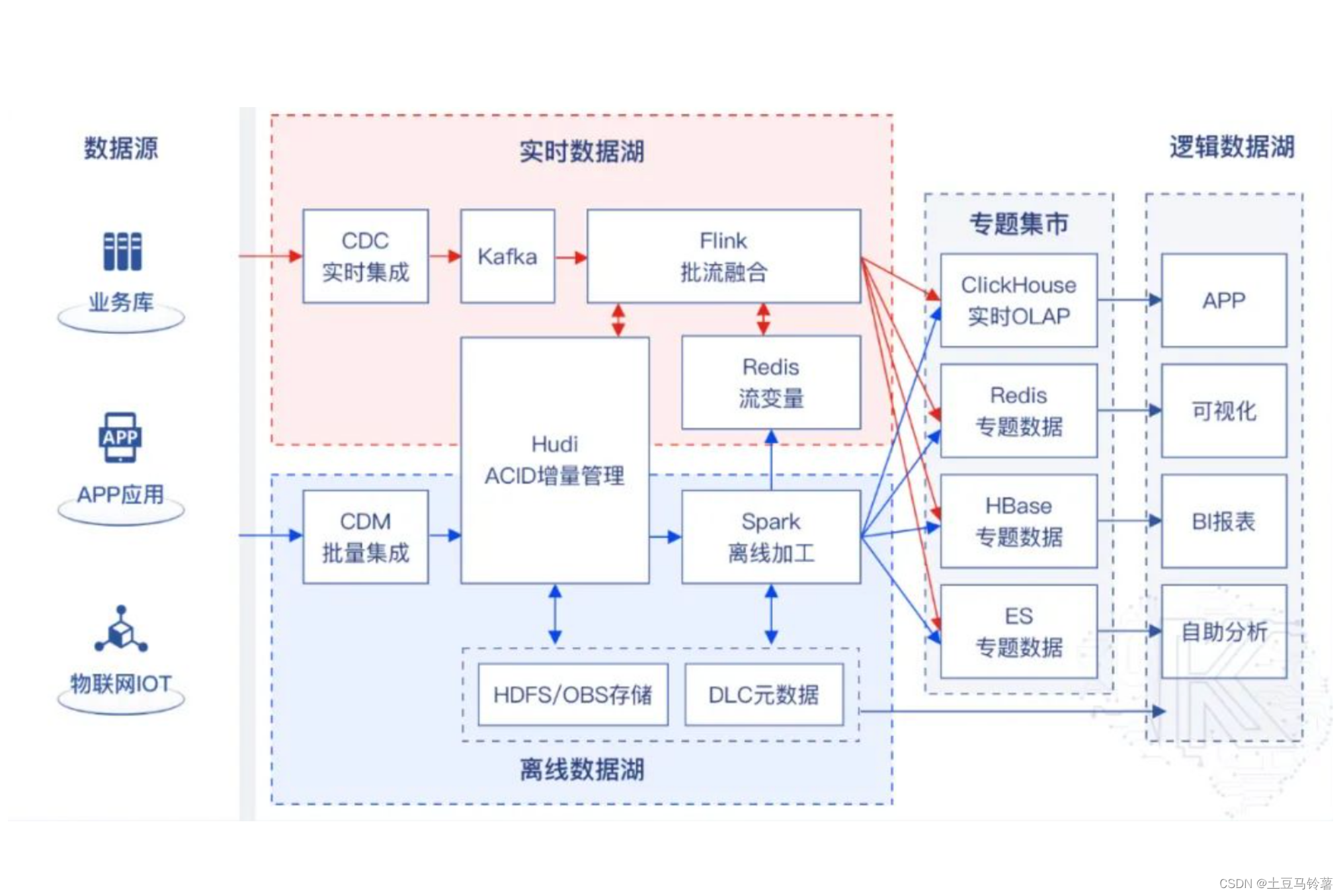
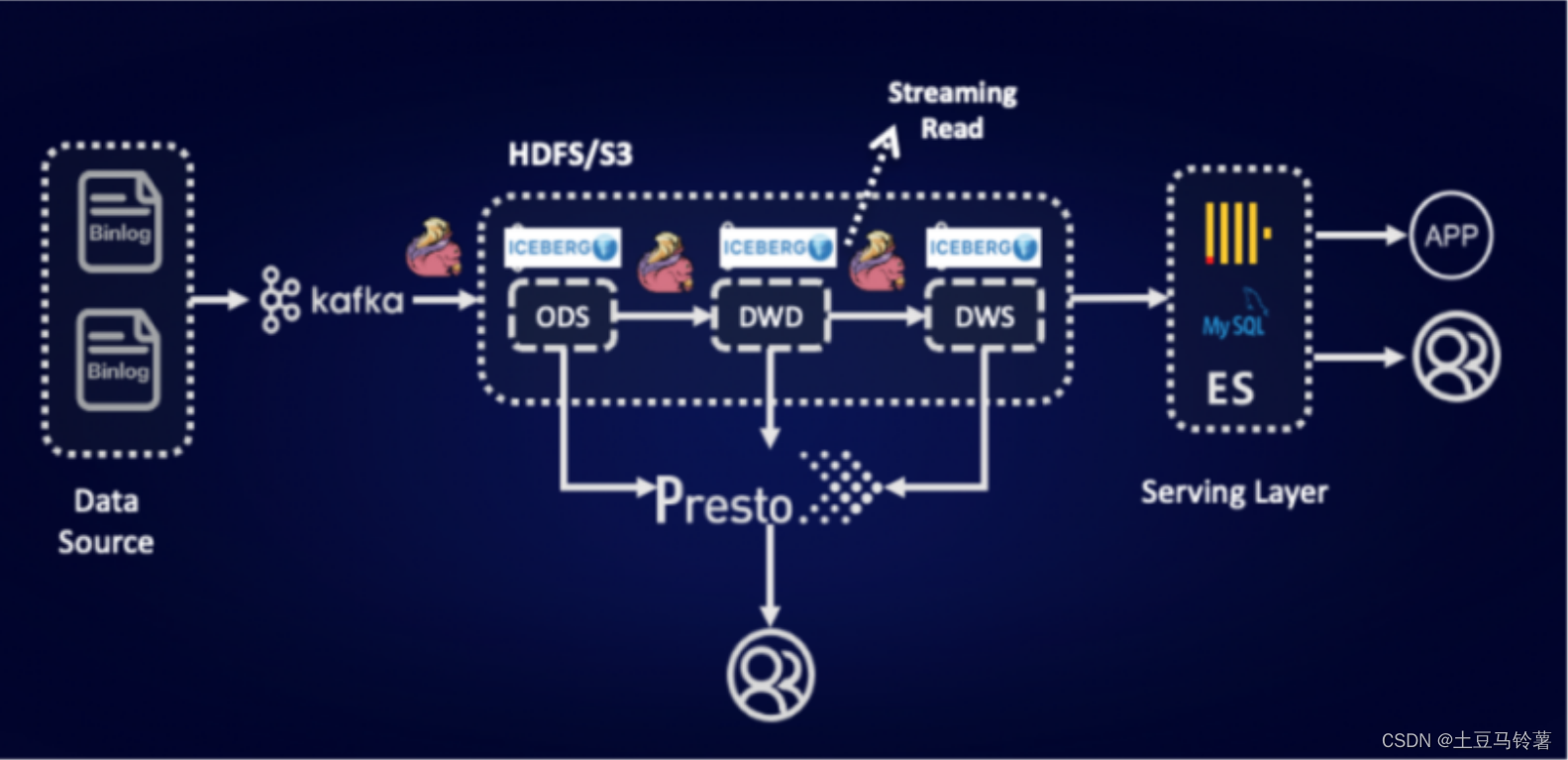
湖仓一体近实时的流批一体架构:
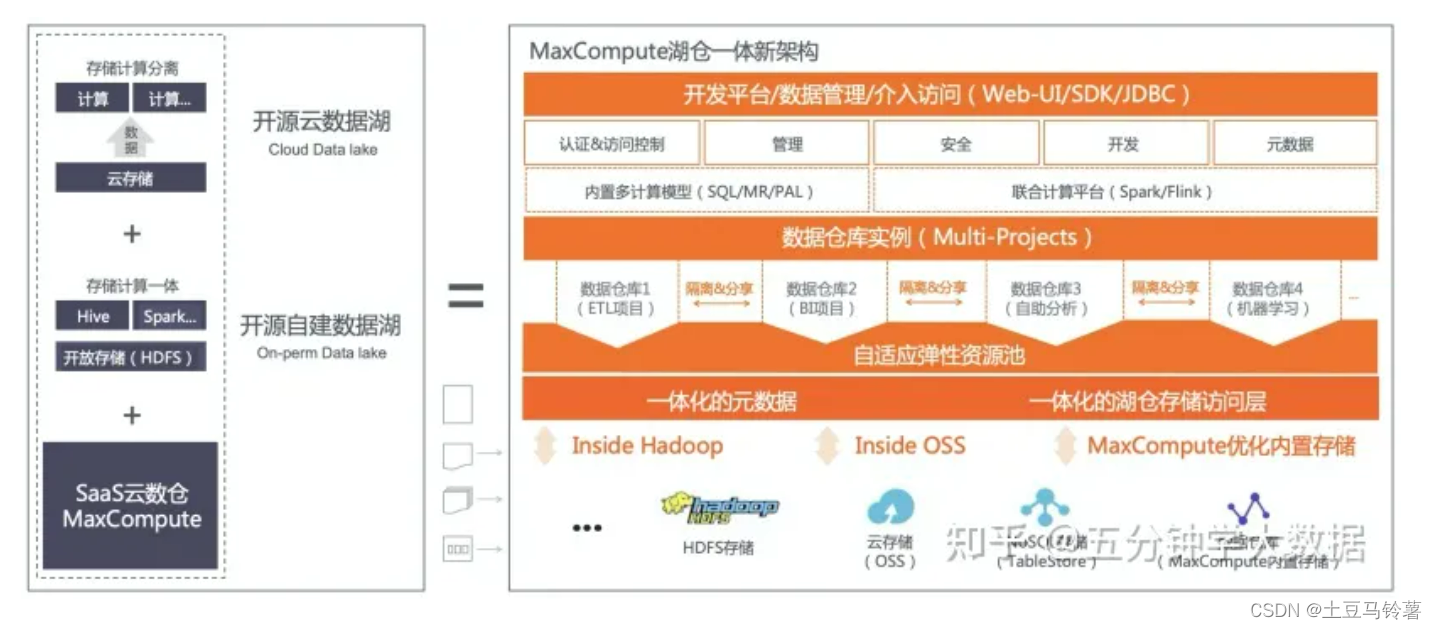
阿里云湖仓一体方案架构:
参考文章:https://blog.csdn.net/qq_43842093/article/details/135188755
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- x-cmd pkg | smartctl - 用于监测和分析硬盘的工具
- DartSDK下载
- 服务器运维小技巧(一)——如何进行远程协助
- 使用 C++/WinRT 创作 API
- Samtec行业科普 | 样品至关重要
- 必看 | 如何用「八爪鱼RPA」搬迁旧帮助中心站点到「HelpLook」?
- PTA.植树
- 网络知识点之-MPLS VPN
- 48种国内外的PCB设计工具-你知道的有哪几种呢?
- SpringCloud之Eureka组件工作原理详解