【学习笔记】Java函数式编程03 Stream流-终结操作
书接上回
3.3.3 终结操作
3.3.3.1 forEach
对集合的每一个元素进行处理
接触很多了不赘述
3.3.3.2 count
用来获取当前流中的元素的个数
比如,打印出所有作家的作品的总数
System.out.println(authors.stream()
.flatMap(author -> author.getBooks().stream())
.count());
3.3.3.3 max和min
可以用来流中的最值。
查看源码可以发现这个方法是需要传入参数的
Optional<T> max(Comparator<? super T> comparator);
Optional<T> min(Comparator<? super T> comparator);
Comparator是一个比较器,但是这里的比较器是什么作用呢?其实stream流的球最值和前面的sorted的实现逻辑类似,都是要求先比较排序后再求最值
另外,这个方法的返回值是Optional类型,这个类型后续会再细讲。
所以max和min不用死记,学会sorted就可以满足需要了
3.3.3.4 ??collect
将流当中的元素转换为一个集合(List/Set/Map)。
阅读源码可以发现collect的两个参数都非常复杂,在实际使用中会使用工具类的方法来快速实现

小练习快速上手
1、获取一个所有作者名字的集合List
authors.stream()
.map(Author::getName)
.collect(Collectors.toList())
2、获取一个所有书名的集合SET
authors.stream()
.flatMap(author -> author.getBooks().stream())
.map(Book::getName)
.collect(Collectors.toSet());
顺带一提,由于set的去重作用,所有其实前面提到的“去重“的需求,也可以尝试用collect来实现
3、获取一个map集合,Key为作者名,Value为作品集List
沿用前面的思路,利用Collectors.toMap方法实现,但是转map是需要指定key和v的,研究toMap方法就可以发现:这里确实要求传入两个Function函数式接口,如下

尝试先写一个匿名内部类的原生写法,然后进行简化:
// 获取一个map集合,Key为作者名,Value为作品集List
List<Author> authors = Author.getAuthor(5);
Map<String, List<Book>> map = authors.stream()
.collect(Collectors.toMap(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName();
}
}, new Function<Author, List<Book>>() {
@Override
public List<Book> apply(Author author) {
return author.getBooks();
}
}));
System.out.println(map);
// 第一次简化
authors.stream()
.collect(Collectors.toMap(author -> author.getName(), author -> author.getBooks()));
// IDEA提供的进一步简化
authors.stream()
.collect(Collectors.toMap(Author::getName, Author::getBooks));
不难发现,toMap方法就是分别指定key和value就可以实现转map的要求了
4、获取一个map集合,Key为作者名,Value为作者
注意:需求不同,这次是将val作为作者本身的对象,这个其实也是比较常见的需求
Map<String, List<Author>> collect = author.stream()
.collect(Collectors.groupingBy(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName();
}
}));
// 简化后
author.stream().collect(Collectors.groupingBy(Author::getName));
介绍完简单的终结操作后,接下来还有一些比较复杂的操作。比如需求场景
- 判断是否有25岁以上的作家?
- 判断是不是所有作家都刚满18岁?
3.3.4 终结操作之查找与匹配
3.3.4.1 anyMatch
有任一元素符合条件,则返回true
3.3.4.2 allMatch
所有符合条件,则返回true
3.3.4.3 nonMatch
所有的元素都不符合条件
(这个不需要硬记,和allMatch互为补集)
3.3.4.4 findAny

这个操作用于获取流中的任意一个元素,注意,这个操作无法保证获取的是第一个元素
3.3.4.5 findFirst
这个操作用于获取流中的第一个元素。
- 这个终结操作一般需要结合
limit和sorted使用
补充说明
这两个方法返回的对象是JDK8新增的Optional对象,用于避免空指针等异常的,后续会详细介绍。
- 要获取里面的对象使用get()方法即可。
- ifPresent()方法可以在对象存在时,执行方法内的函数
3.3.5 ??终结操作之归并操作-reduce
reduce单词字面意思有减少的意思,可以引申为缩小、裁剪的意思

3.3.5.1 reduce概念
对流中的数据,按照指定的计算方式,计算出一个结果。(缩紧操作)
reduce的作用,将stream中的元素“组合”起来,最终传出组合的结果,起到一个紧缩、简化的作用。
两种实现方式
- 传入一个初始值,按照给定的计算方式以此与流中的每个元素进行“计算”,每次计算得到的结果都可以和后面的元素再进行计算,并最终给出结果。
- 没有初始值,而是将第一个元素给定为初始值,然后以此和流内的其他元素进行“计算”并给出结果。
两种方式对应reduce的两种重写方式
T reduce(T identity, BinaryOperator<T> accumulator);Optional<T> reduce(BinaryOperator<T> accumulator);
3.3.5.2 reduce有初始值的重写
T reduce(T identity, BinaryOperator<T> accumulator);
查看源码注释可以发现,双参数的实现逻辑如下:
T result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;
做两个求最值的快速练习——求出所有作家的最大年纪
List<Author> authors = Author.getAuthor();
// 先打印出每个作家的年纪
authors.stream()
.map(Author::getAge)
.sorted()
.forEach(System.out::println);
System.out.println("-----------------");
// 求最大值 匿名内部类写法
Integer max = authors.stream()
.map(Author::getAge)
.reduce(Integer.MIN_VALUE, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer element, Integer next) {
return element < next ? next : element;
}
});
System.out.println(max);
// 求最大值 lambda简化
Integer max1 = authors.stream()
.map(Author::getAge)
.reduce(Integer.MIN_VALUE, (element, next) -> element < next ? next : element);
System.out.println(max1);
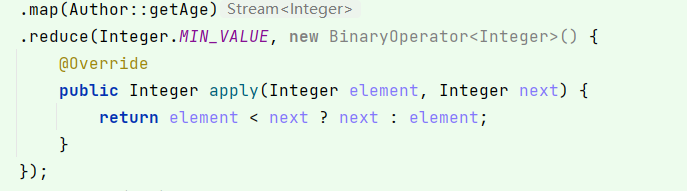
顺带一提前面学到的max()和min()底层就是使用reduce实现的
3.3.5.3 reduce无初始值的调用
Optional<T> reduce(BinaryOperator<T> accumulator);
实现低层逻辑是这样的:
boolean foundAny = false;
T result = null;
for (T element : this stream) {
if (!foundAny) {
foundAny = true;
result = element;
}
else
result = accumulator.apply(result, element);
}
return foundAny ? Optional.of(result) : Optional.empty();
逻辑就是:
- 第一个元素给定为初始值,然后以此和流内的其他元素进行“计算”并给出结果。
- 由于如果流为空返回的对象可能为空,所有这里使用了Optional进行包装
做个练习,一样是求最大年纪
// 匿名内部类原生写法
Optional<Integer> optional = authors.stream()
.map(Author::getAge)
.reduce(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer element, Integer next) {
return element < next ? next : element;
}
});
// lambda简化
Optional<Integer> optional1 = authors.stream()
.map(Author::getAge)
.reduce((element, next) -> element < next ? next : element);
optional.ifPresent(System.out::println);
optional1.ifPresent(System.out::println);
3.4 Stream流的注意事项
- 惰性求值
- 一次性流
- 不会影响原数据
3.4.1 惰性求值
没有任何终结操作,前面的中间操作都不会得到执行和保留。
- 实际开发过程中,由于没有终结操作的stream写法并不会编译报错
- 所以在写代码的时候一定要养成添加终结操作的习惯)
3.4.2 流是一次性的
在进行终结操作后,流会失效(报废。
举个例子:
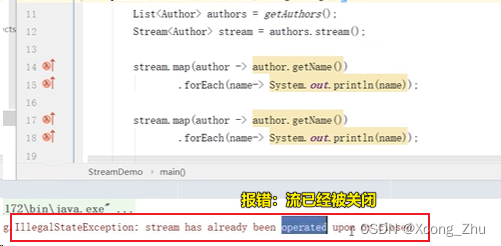
- 在实际开发过程中,使用stream流应该在调用stream()方法后就使用链式编程直到终结操作
- 如果需要再次操作,就重新调用并生成新的流即可
3.4.3 不会影响原数据
特指是正常操作,而且这也是选择stream流所期望的。
举个例子,在map操作中将年龄+10,其实集合中元素的年龄是不会变化的。
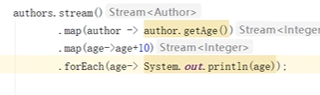
- 在实际开发中,如果是需要对集合的元素进行操作时,则不建议使用stream流
- 使用了stream流也应该尽量避免对集合中的元素进行操作(增删改)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!