微调参数可能带来的安全风险
发布时间:2024年01月24日
微调参数可能带来的安全风险
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To
[1] (ICLR 2024):在极少数对抗训练样本上微调就可以解除 GPT-3.5 的安全限制,即使是在干净的常用数据集上微调也会损伤大模型的安全性。
The Janus Interface: How Fine-Tuning in Large Language Models Amplifies the Privacy Risks
[2] (arxiv 23.10):聚焦邮箱地址、电话号码等身份识别信息(Pernsonal Indentifiable INformation, PII)泄露的风险,发现只要在几十到几百个人名-邮箱数据对上进行微调,GPT-3.5 就会被解除这方面的安全限制,被用于人肉开盒。
Removing RLHF Protections in GPT-4 via Fine-Tuning?
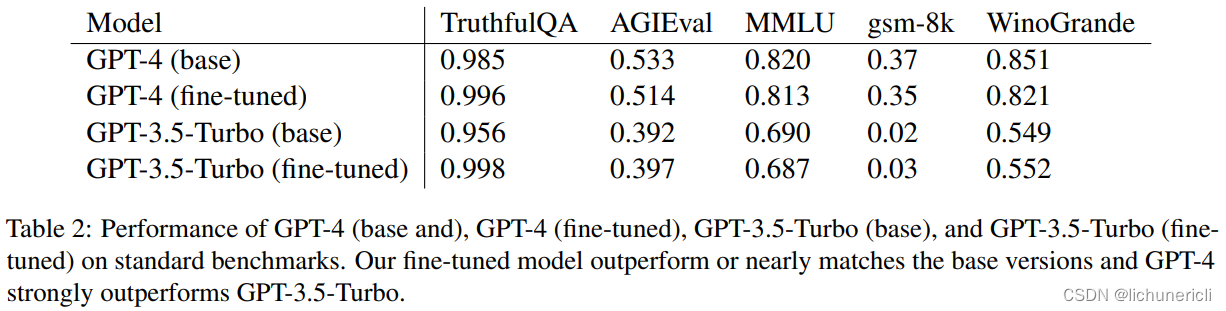
[3] (arxiv 23.11):即使是最强的 GPT-4,只要在未对齐的其他模型产生的几百条恶意数据上微调,就可以被解除 RLHF 的安全锁用于生成恶意内容,同时不损失在通用领域的性能。






文章来源:https://blog.csdn.net/lichunericli/article/details/135776611
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于ts的node项目引入报错归纳
- 走出大模型部署新手村!小明这样用魔搭+函数计算
- 如何选择适合你的跨境电商源码?10大要点全解析
- RPC通信编解码库对比:json、flatbuf、protobuf、MessagePack
- 从濒临破产到玩具行业天花板,乐高怎么做到的?
- Undo Log 、Binary Log、Redo Log之间到底有什么区别?
- 字符串学习笔记
- 好用的流程图工具
- 在Go中使用Goroutines和Channels发送电子邮件
- 【力扣题解】P404-左叶子之和-Java题解