【JVM】执行引擎 Execution Engine
一、简介
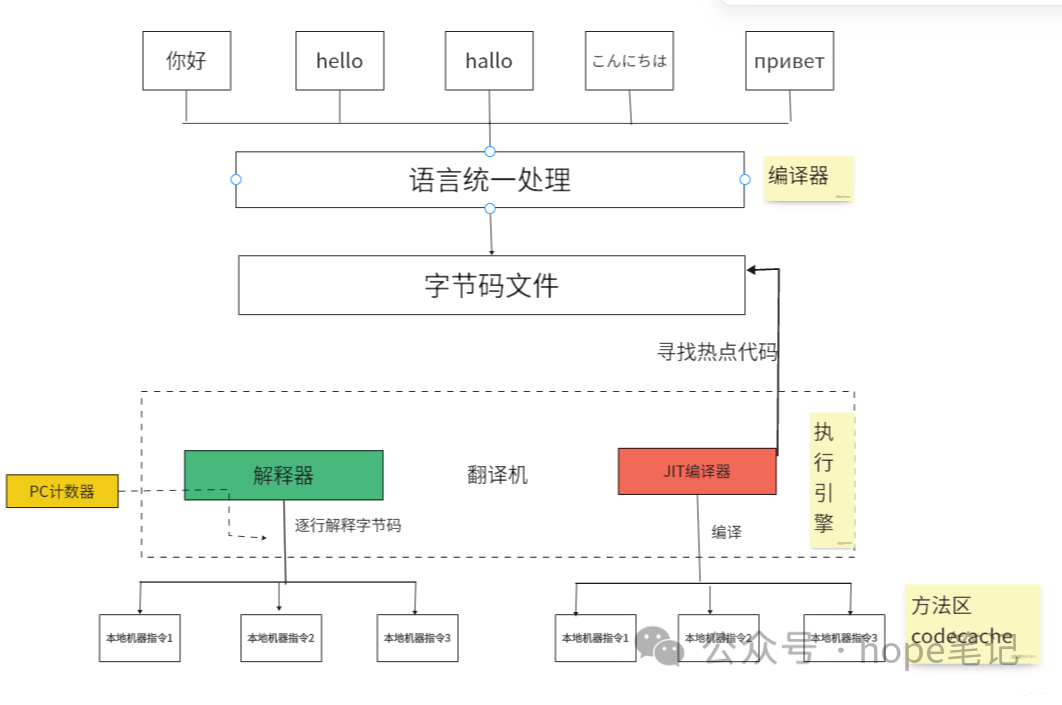
执行引擎是Java虚拟机(JVM)的核心组成部分之一,它的主要任务是负责装载字节码到其内部。由于字节码并不能够直接运行在操作系统之上,因此需要将字节码指令解释/编译为对应平台的本地机器指令,简单来说JVM的执行引擎充当了高级语言翻译为机器语言的译者。
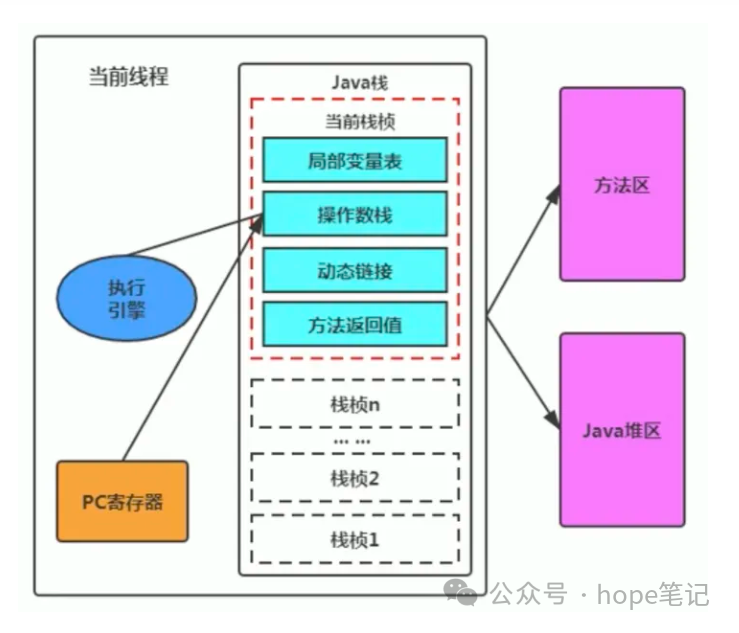
执行引擎在执行的过程中究竟需要执行什么样子的字节码指令完全依赖于 PC 寄存器。
每当执行一项指令操作以后,PC 寄存器就会更新下一条需要被执行的指令地址。
当然方法在执行的过程中,执行引擎有可能会通过存储在局部变量表中的对象引用准确定位到存储在 Java 堆区中的对象实例信息,以及通过对象头中的元数据指针定位到目标对象的类型信息。
从外观上来看,所有的 Java 虚拟机的执行引擎输入、输出都是一致的:输入的是字节码二进制流,处理过程是字节码解释执行的等效过程,输出的是执行结果。
二、解析器
解释器:当 Java 虚拟机启动时会根据预定义的规范对字节码采用逐行解释的方式执行,将每条字节码中的内容“翻译”为对应平台的本地机器指令执行。
1. 字节码解释器
字节码解释器是解释执行的,所谓解释执行,就是将Java字节码转成C++代码,再将C++代码编译成本地代码(硬编码),之所以会转成C++代码,是因为HotSpot虚拟机(本文中所说的Java虚拟机都是指HotSpot虚拟机)是C++代码编写的,所以Java字节码指令的底层实现都是由C++代码实现,执行字节码指令其实就是执行对应的C++代码,而执行C++代码之前会将C++代码编译成本地代码,然后再执行。
所以,字节码解释器在工作的时候,它是逐行代码进行解释执行,准确地说是逐条字节码指令解释执行,由于字节码指令操作对象是栈帧中的操作数栈(伴随着入栈、出栈操作),因此我们常说字节码解释器是“基于栈的字节码解释执行引擎”。
为了更深入地理字节码解释器的执行过程,下面通过一段简单的程序来进行说明:
public int add(){
int a = 5;
int b = 15;
return a + b;
}通过javap命令,生成字节码如下:
public int add();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
?????????0:?bipush????????5
2: istore_1
?????????3:?bipush????????15
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: ireturn由上面这段字节码可知,Java虚拟机会为这个add()方法分配深度为2的操作数栈和个数为3的局部变量表(Code属性中包含了操作数栈深度和局部变量表大小,详细可以了解一下class文件结构)。
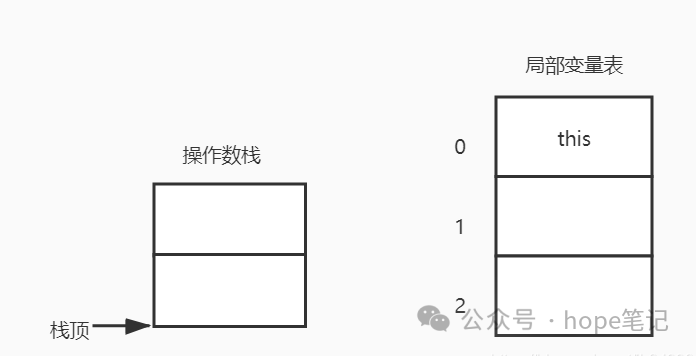
为什么局部变量表的大小是3个呢,程序中明明只有a、b两个局部变量啊?是因为add()方法是非对象实例方法(<init>方法)的局部变量表中索引0的位置永远是this指针。
2. 模板解释器
模板解释器是编译执行的,它的执行过程是直接将Java字节码编译成本地代码(硬编码),然后执行本地代码。相当于对于每一条字节码指令,都将它最后生成的本地代码给提前写死了,JVM初始化的时候,就会直接将字节码指令对应的本地代码给加载到内存中,执行的时候直接执行对应的本地代码即可,这样就跳过了字节码转C++以及由C++编译成本地代码的过程,提高了执行速度。如下代码所示,JVM初始化时会将每一个字节码指令的模板都创建处理,def函数就是为字节码指令创建模板的,每个模板都会生成该指令对应的本地代码。
运行模式
a. 字节码解释器
早期JVM采用的就是该模式,字节码解释器模式下,逐条指令执行,代码运行速度相对较慢,因为它的编译条件相对宽松,编译所需要的信息较少,因此编译速度快,可以通过虚拟机参数-Xint设置;
b. 模板解释器
模板解释器执行速度很快,但是因为它需要将代码全部编译成本地代码,因此它编译需要收集的信息比较多,所以编译速度比较慢,可以通过虚拟机参数-Xcomp设置。
c.字节码解释器 + 模板解释器
可以通过虚拟机参数-Xmixed设置,通过上面的分析,可能大家会觉得,既然模板解释器执行速度快,那JVM肯定采用模板解释器来执行,其实并不是。在说明原因之前,先提一个概念:热点代码。
热点代码
顾名思义,热点代码就是经常被执行的代码,虚拟机会判断一个方法或者一个代码块的运行特别频繁,就会把这些代码认定为热点代码,热点代码主要包含两类代码:被多次调用的方法、被多次执行的循环体,多次调用的方法很好理解,多次执行的循环体是指一个方法内如果存在一个循环体,虽然这个方法可能只是被执行一次或者寥寥几次,但是这个循环体却被多次执行,主要体现在循环次数,那么这个循环体也是热点代码。
热点探测
虚拟机是如何判断一段代码是不是热点代码呢,这就需要有一套热点探测的机制了,JVM主要有两种热点探测机制:
1)基于采样的热点探测
虚拟机定期检查各个线程的栈顶,如果发现某个方法频繁出入栈顶,就将该方法认定为热点代码;
2)基于计数器的热点探测
为每个代码块(方法或者循环体)维护一个计数器,每执行一次代码块,计数器+1,当计数器值达到阈值时,就认定该代码块为热点代码,HotSpot采用的就是这种方式。Client 编译器模式下,该阈值是 1500;Server编译器模式下,该阈值是10000,也可以通过虚拟机参数-XX:CompileThreshold设定。不过热点代码的地位不是一直保持热度的,当该代码块一段时间没有执行或者执行次数无法达到阈值时,热度就会衰减一半,比如某个热点代码块的热点值是10000,热度衰减后,就变成了5000。
热点代码缓存
热点代码缓存在方法区中的一块内存空间,这块内存空间叫Code Cache。可以通过命令java -client -XX:+PrintFlagsFinal -version | grep CodeCache查看Code Cache默认大小。
介绍了热点代码之后,再来说说现在的JVM为什么采用混合执行模式,试想一下,假如采用了模板解释器模式,不管三七二十一,直接对所有代码都编译成硬编码,可能大部分代码都只是执行一次或者少数几次,这样编译全部代码就造成了性能浪费,而且对于现在动辄几百兆甚至几个G的应用,如果采用纯模板解释器,应用的启动就会很慢,可能启动后很长时间都无法使用,这也无法接受,因此采用混合模式,在应用启动后的前期,使用字节码解释器解释执行,当程序运行了一段时间之后,JVM就能够根据代码块的执行次数判断哪些代码属于热点代码,就会将热点代码保存在方法区,下次执行的时候就使用模板解释器编译执行,就无需再编译了,从而提升了性能。现在的虚拟机默认都是采用混合模式,可以通过java -version命令查看。
三种运行模式性能比较,如果当一个程序非常大的话,可能模板执行器模式耗时就会比混合模式更久些,因为编译需要更长的时间。
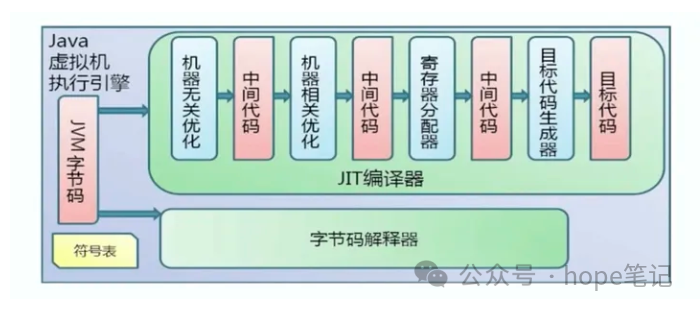
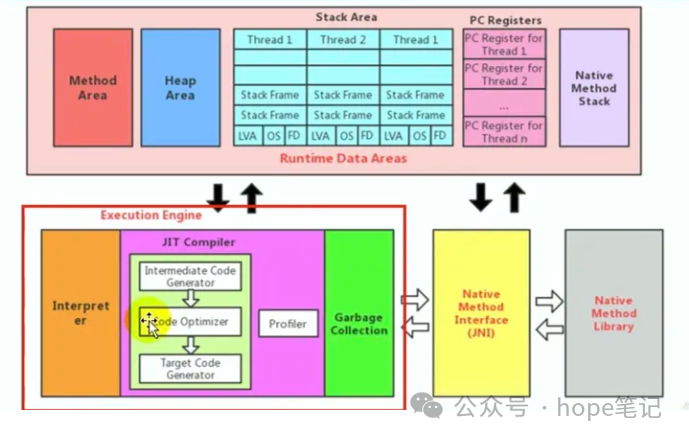
三、JIT编译器
JIT ( Just In Time Compiler) 编译器:就是虚拟机将源代码直接编译成和本地机器平台相关的机器语言。
即时编译器
前面介绍的模板解释器所执行的本地代码就是即时编译器编译生成的,因此所谓的混合运行模式(-Xmixed)其实就是字节码解释器和即时编译器混合使用的方式。所以当使用解释执行模式时(-Xint),则只使用了字节码解释器,即时编译器并没有用;当使用编译模式执行时,这时候即时编译器就会起作用(编译后的本地代码给模板解释器使用)。常见的即时编译器主要有两种:C1编译器(客户端编译器)和C2编译器(服务端编译器),当虚拟机采用client模式工作时,使用的是C1即时编译器,采用server模式工作时,使用的是C2即时编译器,默认是server模式,见上文中java -version执行结果的截图,也可以使用-client和-server参数设置。
C1编译器
client模式下的即时编译器,它触发的条件相对宽松,需要收集的信息较少,它会对字节码在编译的时候进行浅程度的优化,因此相对于C2编译器,它的编译速度更快,但是执行速度相对较慢。
C2编译器
server模式下的即时编译器,触发的条件比较苛刻,它会对代码进行更深层次的优化,因此它的编译程度比较深,编译后的代码质量更高,随之带来的也是更高的编译耗时,但是它的执行速度更快。
混合编译
由于即时编译器编译本地代码需要占用程序运行时间, 通常要编译出优化程度越高的代码, 所花费的时间便会越长;而且想要编译出优化程度更高的代码, 解释器可能还要替编译器收集性能监控信息, 这对解释执行阶段的速也有所影响。为了在程序启动响应速度与运行效率之间达到最佳平衡,HotSpot虚拟机在编译子系统中加入了分层编译的功能(即混合编译),混合编译根据编译器编译、 优化的规模与耗时, 划分出不同的编译层次, 其中包括:
-
第0层。程序纯解释执行, 并且解释器不开启性能监控功能(Profiling) 。
-
第1层。使用客户端编译器将字节码编译为本地代码来运行, 进行简单可靠的稳定优化, 不开启性能监控功能。
-
第2层。仍然使用客户端编译器执行, 仅开启方法及回边次数统计等有限的性能监控功能。
-
第3层。仍然使用客户端编译器执行, 开启全部性能监控, 除了第2层的统计信息外, 还会收集如分支跳转、 虚方法调用版本等全部的统计信息。
-
第4层。使用服务端编译器将字节码编译为本地代码, 相比起客户端编译器, 服务端编译器会启用更多编译耗时更长的优化, 还会根据性能监控信息进行一些不可靠的激进优化。
即时编译器触发条件
上面其实已经在热点代码中介绍过了,当方法执行次数达到指定的阈值时,就会触发即时编译,同时也可以指定,即时编译器编译的其实就是热点代码,只有存在热点代码时,即时编译器才会起作用。
当虚拟机执行到一个方法的时候,会先判断该方法是不是已经编译过(判断是否存在该方法对应的本地代码),如果存在,则直接执行该本地代码;如果不存在,才会将该方法的热点计数器+1,然后判断是否达到设定的阈值,一旦达到了阈值,则会触发即时编译器进行编译。所以当一个代码块一旦触发过即时编译,那么以后每次执行它都是执行它被编译后的本地机器码,也即采用的是编译执行模式(-Xcomp)。
需要注意的是,当即时编译器进行编译时,执行引擎并不会等待其编译完成,而是直接使用字节码解释器解释执行,当即时编译器编译完成后,下一次再执行该方法的时候就会执行已经编译后的本地代码了,这样做的目的是尽可能的提高执行效率,防止同步等待造成性能浪费。
即时编译器实现
如果触发了即时编译,那么就会产生一个即时编译任务,将这个任务放到队列里,然后由VM_THREAD线程(linux系统)从这个队列里取出任务执行。而这个VM_THREAD线程可能会有多个,可以通过命令java -client -XX:+PrintFlagsFinal -version | grep CICompilerCount 查看有多少个线程(默认4个),可以通过参数:-XX:CICompilerCount=XXX进行设置,从而对即时编译器进行调优。
javac编译器与即时编译器
文中所说的“编译”都是指即时编译器的编译过程,它与javac将java代码编译成字节码是完全不同的。java编译器是由Java代码实现,是Java虚拟机之外的编译器,又称前端编译器;而即时编译器完全是在Java虚拟机内部进行,由C++代码实现,又称后端编译器,它主要是运行时将字节码编译成本地机器码。由于Java程序要运行的话,需要先经过javac将.java文件编译成.class文件,这个过程在虚拟机外部进行;然后由执行引擎执行字节码,而执行引擎执行字节码主要是由解释器+即时编译器搭配进行,这个过程在虚拟机内部进行,基于此,我们常说“Java是半编译半解释型的语言”。
JDK 1.0 时代,将 Java 语言定位为“解释执行”还是比较准确的,再后来, Java 也发展出可以直接生成本地代码的编译器。
现在 JVM 在执行 Java 代码的时候,通常都会将解释执行和编译执行二者结合起来进行。
四、机器码、指令、汇编语言
1. 机器码
各种用二进制编码方式表示的指令,叫做机器指令码。开始,人们就用它编写程序,这就是机器语言。
机器语言虽然能够被计算机理解和接受,但和人们的语言差别太大,不易被人们理解和记忆,并且用它编程容易出差错。
用它编写的程序一经输入计算机, CPU 直接读取运行,因此和其他语言编的程序相比,执行速度最快。
机器指令与 CPU 紧密相关,所以不同种类的 CPU 所对应的机器指令也就不同。
2. 指令
由于机器码是有 0 和 1 组成的二进制序列,可读性实在太差,于是人们发明了指令。
指令就是把机器码中特定的 0 和 1 序列,简化成对应的指令(一般为英文简写,如 mov,inc 等),可读性稍好。
由于不同的硬件平台,执行的是同一个操作,对应的机器码可能不同,所以不同的硬件平台的同一种指令(比如 mov), 对应的机器码也可能不同。
3. 指令集
不同的硬件平台,各自支持的指令是有差别的。因此每个平台所支持的指令,称之为对应平台的指令集。如常见的 X86 指令集,对应的是 x86 架构的平台, ARM 指令集,对应的是 ARM 架构的平台。
4. 汇编语言
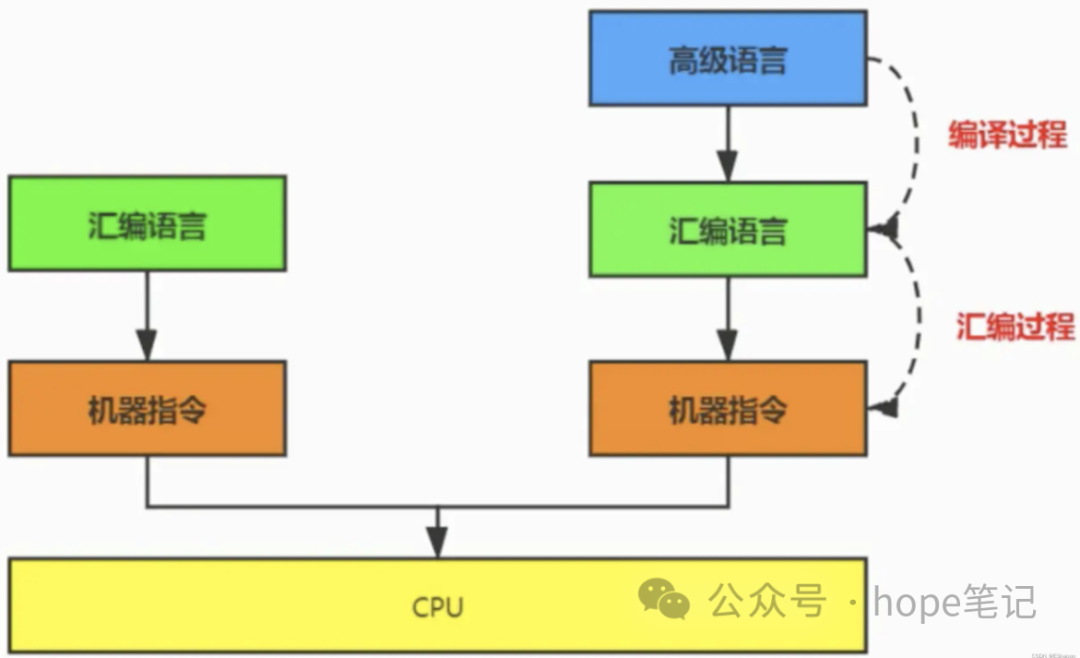
由于指令的可读性还是太差,于是人们又发明了汇编语言。
在汇编语言中,用助记符(Mnemonics)代替机器指令的操作码,用地址符号(Symbol)或标号(Label) 代替指令或操作数的地址。
在不同的硬件平台,汇编语言对应着不同的机器语言指令集,通过汇编过程转换成机器指令,由于计算机只认识指令码,所以用汇编语言编写的程序还必须翻译成机器指令码,计算机才能识别和执行。
5. 高级语言
为了使计算机用户编程更容易些,后来就出现了各种高级计算机语言。高级计算机语言比机器语言、汇编语言更接近人的语言。
当计算机执行高级语言编写的程序时,仍然需要把程序解释和编译成机器的指令码。完成这个过程的程序就叫做解释程序或编译程序。
关于以上所述大致用图展示如下:
6. 字节码
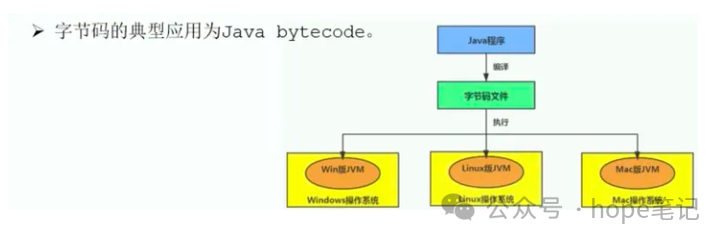
字节码是一种中间状态的(中间码)的二进制(文件),它比机器码更抽象,需要直译器转译后才能成为机器码。
字节码主要是为了实现特定软件运行和软件环境、与硬件环境无关。
字节码的实现方式是通过编译器和虚拟机器。编译器将原码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接运行的指令,字节码的典型应用为 Java bytecode 。
五、Java 代码编译和执行过程
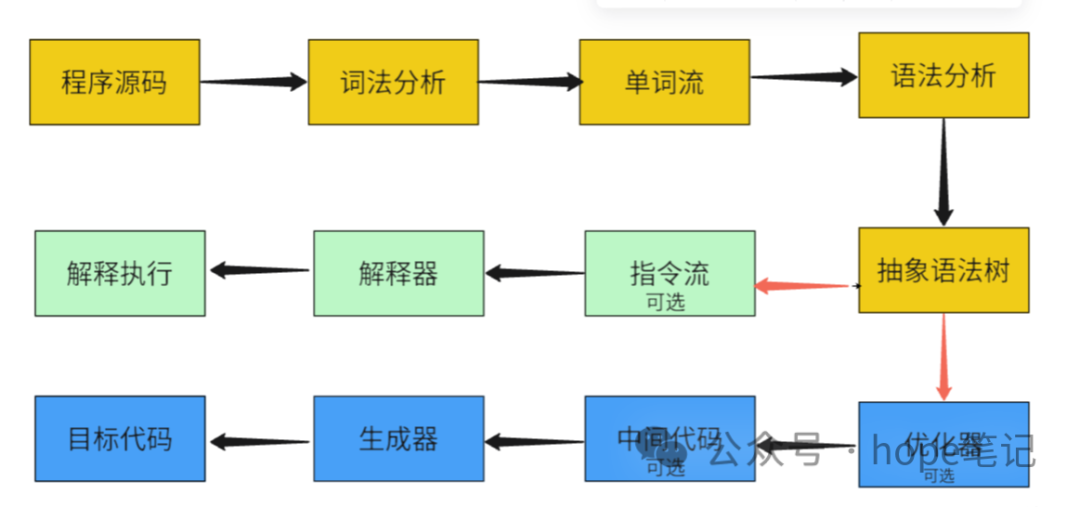
大部分的程序代码转换成物理机的目标代码或虚拟机能执行的指令集之前,都需要经过上图中的各个步骤。
Java 代码编译是由 Java 源码编译器来完成,流程图如下所示:
JVM 的主要任务是负责装载字节码到其内部,但字节码并不能够直接运行在操作系统之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只是一些能够被 JVM 所识别的字节码指令、符号表,以及其他的辅助信息。
那么,如果想让一个 java 程序运行起来,执行引擎(Execution Engine) 的任务就是将字节码指令解释/编译为对应平台上的本地机器指令才可以。简单来说,JVM 中的执行引擎充当了将高级语言翻译为机器语言的译者。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 云原生MeetUp| 1222 KubeSphere + 敏捷 主题分享会
- 数据结构与算法教程,数据结构C语言版教程!(第五部分、数组和广义表详解)一
- Fiddler 无法抓包手机 https 报文的解决方案来啦!!
- 拓扑排序实现循环依赖判断 | 京东云技术团队
- 【Python】torch中的.detach()函数详解和示例
- Redis持久化
- 【电子通识】开漏输出和推挽输出有什么差别?
- 安科瑞预付费用户电能管理系统能实现哪些功能?
- 爬虫工作量由小到大的思维转变---<第三十七章 Scrapy redis里面的key >
- MATLAB算法实战应用案例精讲-【图像处理】FPGA(补充篇)