NLP论文阅读记录 - 2021 | WOS01 通过对比学习增强 Seq2Seq 自动编码器进行抽象文本摘要
文章目录
前言

Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization(2104)
0、论文摘要
在本文中,我们通过对比学习提出了一种用于抽象文本摘要的去噪序列到序列(seq2seq)自动编码器。我们的模型采用标准的基于 Transformer 的架构,具有多层双向编码器和自回归解码器。为了增强其去噪能力,我们将自监督对比学习与各种句子级文档增强结合起来。 seq2seq 自动编码器和对比学习这两个组件通过微调进行联合训练,从而提高了文本摘要在 ROUGE 分数和人类评估方面的性能。我们对两个数据集进行了实验,并证明我们的模型优于许多现有基准,甚至达到了与使用更复杂的架构和广泛的计算资源训练的最先进的抽象系统相当的性能。
一、Introduction
1.1目标问题
文本摘要旨在生成准确的文本片段以捕获关键信息。现有的方法要么是提取的,要么是抽象的。提取方法从文档中选择句子,抽象方法根据输入文档作为摘要生成句子。近年来,随着自然语言处理(NLP)研究的进步,特别是在大规模预训练语言模型领域[1]-[4],抽象摘要已成为热门研究课题并取得了重大进展。在大多数现有的抽象摘要模型中,例如BART[5]、PEGASUS[6]和ProphetNet[7],都采用基于Transformer的架构[8]。它们通常首先使用大量语料库以无监督的方式进行预训练,然后针对有监督的下游应用程序针对特定的数据集进行微调。这些模型在各种文本理解任务上表现出了优越性,特别是在生成抽象摘要方面。
尽管在标准基准测试中具有令人印象深刻的性能,但这些深度网络在部署到现实系统中时通常很脆弱[9]。主要原因在于它们对各种噪声不具有鲁棒性,例如数据损坏[10]、分布偏移[11]或有害数据操纵[12]。此外,他们还可能严重依赖虚假模式预测[13]。正如之前的研究所证明的,seq2seq 模型在许多下游应用中发挥着关键作用。因此,我们希望在 NLP 任务中开发这样的 seq2seq 模型时能够启用其去噪能力。此外,许多先前的语言理解研究发现,基于 Transformer 的模型可能会严重忽略全局语义[14]。因为这些模型中的自注意力通常用于在预训练期间学习和预测单词级特征。由现有预训练语言模型学习的词嵌入聚合而成的句子嵌入无法有效且充分地捕获句子之间的语义[15]。这可能会导致后续任务(例如抽象总结)的性能不佳。原因是摘要需要广泛覆盖的自然语言理解,超越单个单词和句子的含义[16]。因此,为了构建去噪 seq2seq 模型,BART [5] 和 MARGE [17] 等最先进 (SOTA) 方法开发了新的预训练目标。
1.3本文贡献
在本研究中,我们提出了一个新的框架ESACL,Enhanced Seq2Seq Autoencoder via Contrastive Learning,通过微调来提高seq2seq模型的去噪能力并增加模型的灵活性,以达到我们的目标。与大多数在预训练中设计去噪目标的现有方法不同,ESACL 在微调阶段优化模型,需要更少的计算资源并显着节省训练时间。具体来说,ESACL 利用自监督对比学习 [18]、[19] 并将其集成到标准 seq2seq 自动编码器框架中。
总的来说,它涉及两个阶段:(1)句子级文档增强,(2)seq2seq自动编码器和对比学习的联合学习框架,总体目标基于微调损失和自监督对比损失。关于 seq2seq 自动编码器,ESACL 使用与 BART 类似的架构,BART 是一个基于标准 Transformer 的模型,具有多层双向编码器和从左到右的解码器。 ESACL 执行文档增强来创建两个实例,并设计了一个基于 seq2seq 模型的独特框架:它不仅使用解码器的输出进行微调,而且还尝试最大限度地提高编码器输出之间的一致性两个增强实例。对比学习的关键一步是数据增强。在单词级别的许多 NLP 任务中已经开发了各种增强策略,例如插入新单词或交换两个标记。为了捕获整个文档的高级语义和结构信息,我们在句子级别执行数据增强。
在本研究中,我们实现了数据增强的几种组合,我们的实验结果表明:(i)可以通过句子级增强来提高模型性能; (ii) 不同数据增强策略的摘要性能差别不大; (iii) 应避免大幅破坏文件结构的扩充。综上所述,ESACL 提出了一种通过抽象摘要微调对 seq2seq 模型进行去噪的新方法。它提出了一种新的摘要方案,将自监督对比学习纳入 seq2seq 框架,以提高模型的灵活性。
总之,我们的贡献如下:
? 我们提出ESACL,一种新的抽象文本摘要框架,通过微调联合训练具有对比学习的seq2seq 自动编码器。 ? 我们通过定量测量、稳健性检查和人工评估,使用两个汇总数据集来评估ESACL。 ESACL 实现了最先进的性能,并在对潜在不相关噪声进行建模方面表现出了更好的灵活性。 ? 我们引入了几种句子级文档增强策略并进行消融研究以了解它们对性能的影响。
二.相关工作
随着深度学习的快速发展,抽象文本摘要取得了可喜的成果。基于神经网络的模型[20]-[27]支持生成抽象摘要的框架。最近,随着注意力机制和基于 Transformer 的[8]语言模型的成功,基于预训练的方法[1]、[3]、[28]引起了越来越多的关注,并在许多领域取得了最先进的性能NLP 任务和预训练编码器-解码器 Transformers [5]-[7]、[17]、[29] 在总结方面取得了巨大成功。
对比学习最近在图像分析和语言理解领域重新兴起[14]、[18]、[30]、[31]。研究人员开发了许多基于对比学习的框架,包括自监督框架[14]和监督框架[31],并将它们应用于不同的语言理解任务,例如情感分析[32]和文档聚类[33]。他们主要利用对比学习来帮助模型深入探索数据的独特特征,同时忽略不相关的噪声,这也激发了当前的研究。
数据增强是对比学习的关键,并已广泛应用于图像分析中[34]。文本数据增强则不同,主要可分为词级转换[35]-[38]和神经文本生成[39]、[40]。在我们的论文中,为了保留全局语义,同时过滤文档的不相关噪声,我们设计了几种句子级增强策略并展示了它们在摘要中的有效性。根据实验结果,我们相信开发新的文本摘要替代增强方法具有很大的优点。
三.本文方法
在本节中,我们提出了我们提出的模型 ESACL,它利用自监督对比学习来增强 seq2seq 框架的去噪能力。图 1 展示了 ESACL 的整体架构。对于给定的输入文档 d,ESACL 首先创建一对增强文档,这些文档预计与相同的原始目标摘要相关联。然后,ESACL 使用基于 Transformer 的编码器生成增强文档的潜在表示,并执行自监督对比学习,以鼓励模型捕获文档 d 中的潜在噪声。最后,优化的潜在表示被发送到基于 Transformer 的解码器以生成摘要。在第 IV-B 节中,我们介绍了 ESACL 中对比学习的实现。在第 IV-A 节中,我们介绍了几种句子级文档增强策略,这是对比学习的关键。在第 IV-C 节中,我们描述了 ESACL 的详细 seq2seq 架构,特别是如何合并自监督对比学习以及如何通过微调联合训练它们。
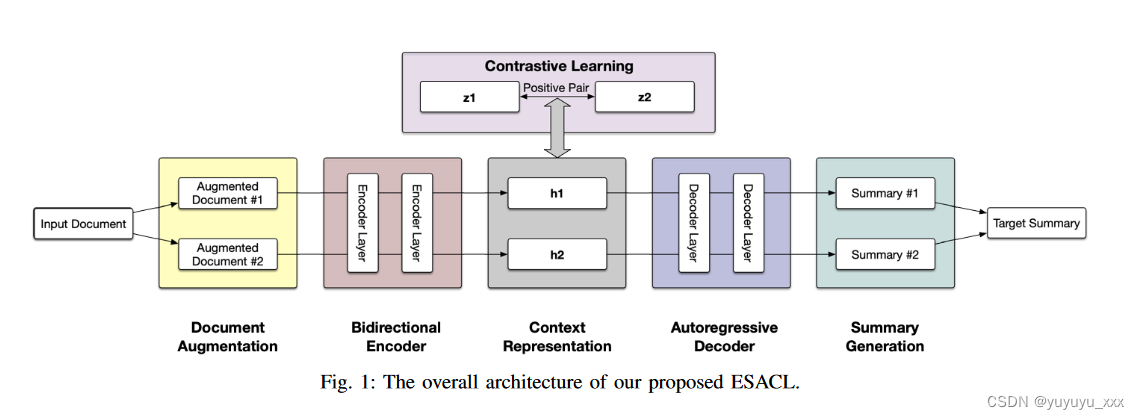
A 文档增强
数据增强已用于提高模型的去噪能力。在第二部分提到的现有文献中,NLP 中存在许多基于对比学习的模型和应用。然而,这些方法大多数都集中在单词级别的增强,这可能不适合文本摘要,因为全局语义甚至更高级别(例如句子或文档)的噪声很容易被忽略。在本研究中,我们在句子级别进行文档增强。具体来说,给定一个包含 k 个句子序列的输入文档 d,我们通过句子级别的各种转换来操作文档以增强文档。通过这样做,ESACL 可以生成另一个序列 ^ d,其中主要语义被保留,并带有一些额外的噪声。
与[38]类似,我们在句子级别设计了几种文档增强方法,如下所示: ? 随机插入(RI):随机选择一个现有句子并将其插入到输入文档中的随机位置。 ? 随机交换(RS):随机选择两个句子并交换它们的位置。 ? 随机删除(RD):从输入文档中随机删除一个句子。 ? 文档旋转(DR):随机选择一个句子,并使用该选定的句子作为枢轴旋转文档。
B.自我监督对比学习
我们在微调过程中将自监督对比学习引入 ESACL,以增强其噪声灵活性。 ESACL 对原始输入文档执行文档扩充以创建正训练对。与负对(两个不同的文档)一起,ESACL 能够鼓励自己识别从编码器学习的两个上下文向量是否表示相同的原始输入文档。通过这样做,ESACL 在微调期间提高了上下文向量 c 的质量,这有利于下游语言生成的性能。
为了在训练期间形成正对,我们执行文档增强,为一批 K 个训练实例 b = {d1, d2, …, dK } 中的每个文档创建两个增强实例。假设 di 是原始输入文档,我们生成增强文档 ? d2i?1 = A1(di) 和 ? d2i = A2(di),其中 A 指特定的增强策略。因此,我们一个批次总共有 2K 个增强实例,并且我们假设 ? d2i?1 和 ? d2i 是从相同的输入文档 di 增强的。当且仅当两个实例来自同一原始输入文档时,才定义正对。否则它们被视为负对。我们使用预训练的编码器 fencoder(·) 来获取每个增强文档 ? d 的潜在表示,即 h = fencoder(? d)。在我们的工作中,我们使用与第一个输入标记相对应的最终隐藏向量作为文档的聚合表示,就像之前的文献[1]一样。 ESACL还应用非线性投影头g来进一步理解潜在维度之间的深层语义。它将表示 h 投影到另一个潜在空间 z = g(h),用于计算正对的对比损失 l(i, j),如方程 1 所示。这里,当 k ? 时,1[k?=i] 为 1 = i,否则为 0。 τ 是温度参数。 sim(·,·) 是余弦相似度度量。
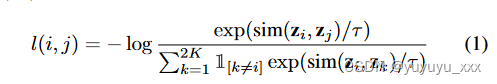
ESACL 中对比学习的损失是:
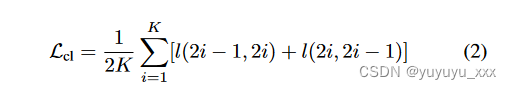
C. 序列到序列架构
对于抽象文本摘要,我们遵循文献并采用基于 Transformer 的 seq2seq 模型,该模型已被证明是有效的(参见第二节)。这里出现的一个自然问题是如何利用 seq2seq 框架中对比学习的去噪能力来改进摘要。为了回答这个问题,我们设计了一个组合损失来共同学习模型参数。对于每个实例 di,我们获得两个增强实例:^ d2i?1 和 ^ d2i1,被认为是自监督对比学习的正对。它们还用于生成摘要 ^y2i?1 和 ^y2i。将生成的摘要与原始输入文档的目标摘要进行比较,以计算微调损失 Lgenerate,从而衡量生成性能。在本研究中,我们将 Lgenerate 定义为交叉熵损失。正如我们所介绍的,我们还使用生成的正对来计算对比学习损失,这衡量了我们模型的噪声灵活性。公式 3 将 ESACL 的总体损失总结为两个损失的加权和。超参数 α ∈ [0, 1] 用于平衡对比学习和摘要生成的重要性。 ESACL 的总体流程如算法 1 所示。

四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
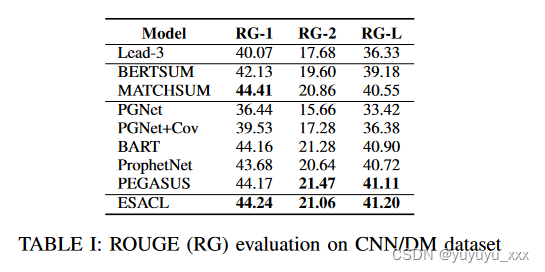
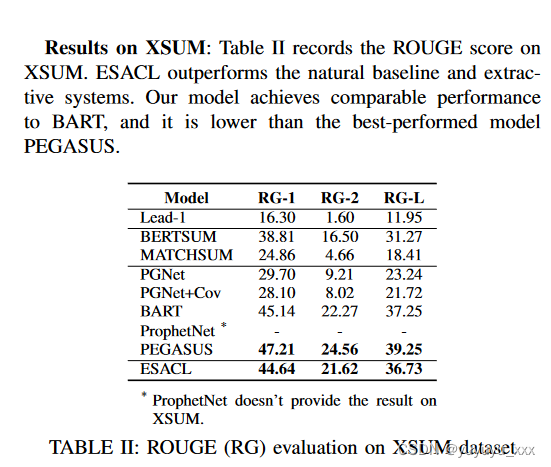
4.6 细粒度分析
五 总结
在本文中,我们提出了 ESACL,这是一种通过对比学习增强的序列到序列模型,旨在提高抽象文本摘要的性能,其中两个关键组件通过微调共同学习。通过几种提出的句子级文档增强,ESACL 可以通过微调构建具有去噪能力的自动编码器。我们在两个数据集上对 ESACL 进行了定量和定性的实证评估。结果表明,ESACL 的性能优于多个前沿基准。我们还研究了不同增强策略对性能的影响,并探讨了 ESACL 的稳健性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- APUE学习之守护进程
- EXness官方网站怎么辨别真假与安全访问指南
- LabVIEW在齿轮箱故障诊断中的应用
- 低代码是美味膳食还是垃圾食品?
- [electron]检测是否存在本地配置文件, 如果有则读取本地配置,主要是方便测试人员切换不同测试环境
- 峨眉山美食:罗鸭儿治愈挑剔味蕾
- 大数据机器学习与深度学习——过拟合、欠拟合及机器学习算法分类
- samba服务搭建,并将共享目录映射到windows
- CT检测中的CT是什么意思,可以用来哪些检测,如何成像的。
- Java进阶第九章——多线程:wait和notify以及生产者消费者模式