工具系列:时间序列预测工具Dart介绍_快速入门
快速入门
在这个笔记本中,我们将介绍库的主要功能:
我们只会展示一些最小的“入门”示例。如果需要更深入的信息,您可以参考我们的用户指南和示例笔记本。
安装Darts
我们建议使用一些虚拟环境。然后主要有两种方法。
使用pip:
pip install darts
使用conda:
conda install -c conda-forge -c pytorch u8darts-all
如果遇到问题或想安装不同的版本(避免某些依赖项),请参阅详细安装指南。
首先,让我们导入一些东西:
# 导入必要的库
%matplotlib inline # 在Jupyter Notebook中显示图形
import pandas as pd # 导入pandas库,用于数据处理和分析
import numpy as np # 导入numpy库,用于科学计算
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘图
from darts import TimeSeries # 导入darts库中的TimeSeries类,用于处理时间序列数据
from darts.datasets import AirPassengersDataset # 导入darts库中的AirPassengersDataset类,用于加载乘客数量数据集
构建和操作 TimeSeries
TimeSeries 是 Darts 中的主要数据类。TimeSeries 表示具有适当时间索引的单变量或多变量时间序列。时间索引可以是 pandas.DatetimeIndex 类型(包含日期时间),也可以是 pandas.RangeIndex 类型(包含整数;适用于表示没有特定时间戳的顺序数据)。在某些情况下,TimeSeries 甚至可以表示概率序列,以便例如获得置信区间。Darts 中的所有模型都使用 TimeSeries 并生成 TimeSeries。
读取数据并构建 TimeSeries
可以使用一些工厂方法轻松构建 TimeSeries:
- 从整个 Pandas
DataFrame,使用TimeSeries.from_dataframe()(文档)。 - 使用时间索引和相应值的数组,使用
TimeSeries.from_times_and_values()(文档)。 - 从 NumPy 值数组,使用
TimeSeries.from_values()(文档)。 - 从 Pandas
Series,使用TimeSeries.from_series()(文档)。 - 从
xarray.DataArray,使用TimeSeries.from_xarray()(文档)。 - 从 CSV 文件,使用
TimeSeries.from_csv()(文档)。
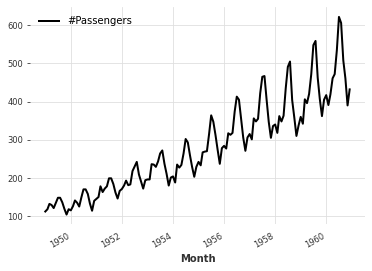
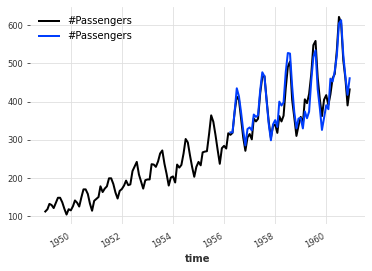
下面,我们通过直接从 Darts 中的数据集之一加载航空旅客系列来获取 TimeSeries:
# 加载数据集
series = AirPassengersDataset().load()
# 绘制数据集中的时间序列图
series.plot()
一些TimeSeries操作
TimeSeries支持不同种类的操作 - 这里有一些例子。
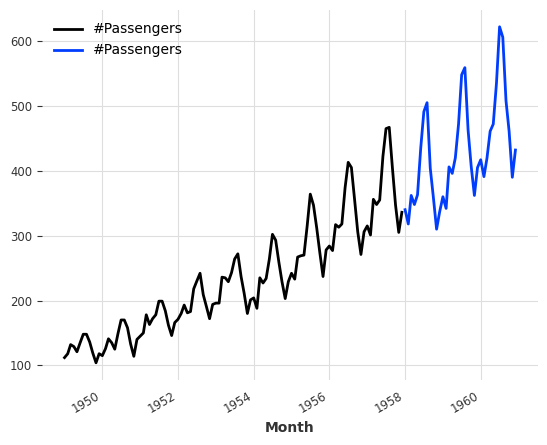
分割
我们也可以在系列的一部分、pandas的Timestamp或整数索引值处进行分割。
# 将序列按照0.75的比例分为两部分,分别赋值给series1和series2
series1, series2 = series.split_after(0.75)
# 绘制series1的图像
series1.plot()
# 绘制series2的图像
series2.plot()
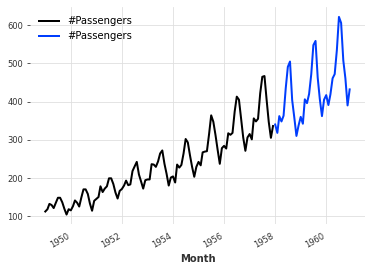
切片:
# 将series分为两部分,series1为除了最后36个元素之外的部分,series2为最后36个元素
series1, series2 = series[:-36], series[-36:]
# 绘制series1的折线图
series1.plot()
# 绘制series2的折线图
series2.plot()
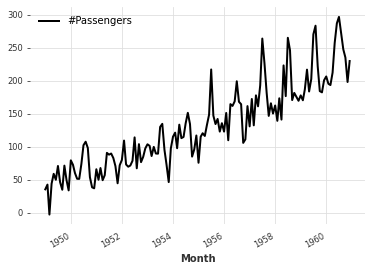
算术运算:
# 导入需要的库已经定义的TimeSeries类
# 不需要增加import语句
# series为一个TimeSeries类的实例
# series_noise为一个TimeSeries类的实例,其时间索引与series相同,值为随机生成的标准正态分布的值
series_noise = TimeSeries.from_times_and_values(
series.time_index, np.random.randn(len(series))
)
# 对series进行一系列数学运算,生成一个新的TimeSeries类的实例
# 首先将series除以2,然后加上20倍的series_noise,最后减去10
# 最终生成的TimeSeries类的实例的时间索引与series相同,值为上述运算的结果
# 调用plot()方法将生成的TimeSeries类的实例绘制出来
(series / 2 + 20 * series_noise - 10).plot()
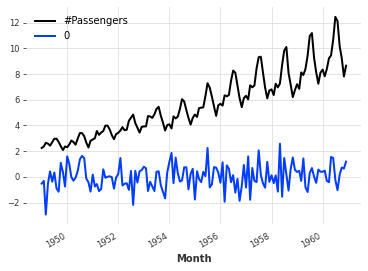
堆叠
将一个新的维度连接起来,生成一个新的单一的多元时间序列。
(series / 50).stack(series_noise).plot()
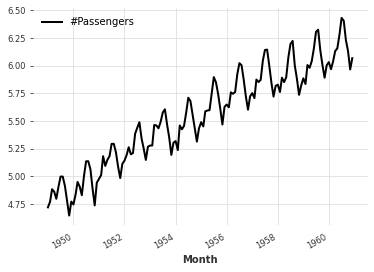
映射:
series.map(np.log).plot()
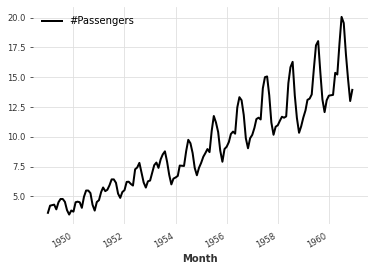
在时间戳和值上的映射:
# 使用map函数对Series对象进行操作,计算每个元素除以所在月份的天数
# lambda函数接受两个参数,ts表示时间戳,x表示元素的值
# ts.days_in_month表示获取时间戳所在月份的天数
series.map(lambda ts, x: x / ts.days_in_month).plot()
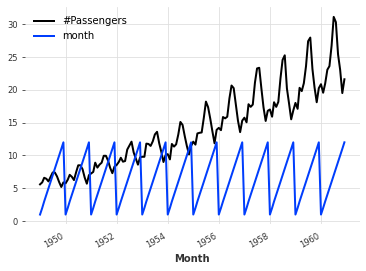
添加一些日期时间属性作为额外的维度(产生多变量序列)。
# 将series除以20,并添加日期时间属性"month"
(series / 20).add_datetime_attribute("month").plot()
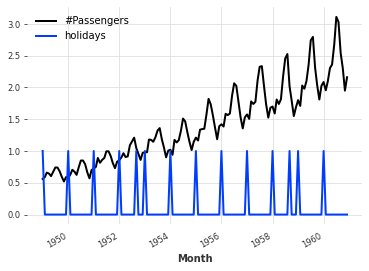
添加一些二进制假日组件。
(series / 200).add_holidays("US").plot()
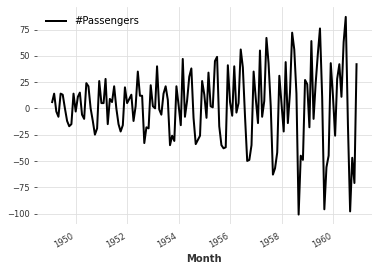
差分法
# 计算相邻元素的差值,并绘制差值的折线图
series.diff().plot()
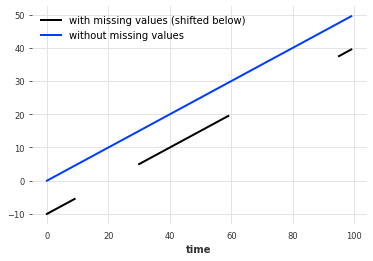
填充缺失值(使用utils函数)。
缺失值用np.nan表示。
# 创建一个包含50个数值的数组,步长为0.5
values = np.arange(50, step=0.5)
# 将数组中索引为10到29的元素设置为NaN(缺失值)
values[10:30] = np.nan
# 将数组中索引为60到94的元素设置为NaN(缺失值)
values[60:95] = np.nan
# 使用values创建一个时间序列对象
series_ = TimeSeries.from_values(values)
# 将时间序列中的每个值减去10,并绘制图表(带有缺失值的时间序列,向下偏移)
(series_ - 10).plot(label="带缺失值的时间序列(向下偏移)")
# 使用fill_missing_values函数填充缺失值,并绘制图表(没有缺失值的时间序列)
fill_missing_values(series_).plot(label="没有缺失值的时间序列")
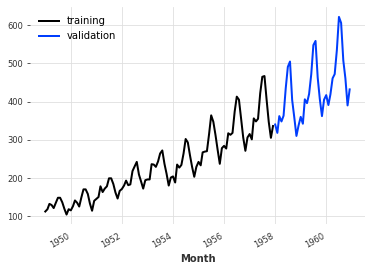
创建训练和验证序列
接下来,我们将把我们的TimeSeries分成训练和验证序列。注意:通常,将测试序列保留并在整个过程中不进行任何操作也是一个好的实践。在这里,我们只是为了简单起见构建了一个训练和一个验证序列。
训练序列将是一个包含值的TimeSeries,直到1958年1月(不包括),验证序列将是包含其余值的TimeSeries。
# 将时间序列数据按照指定时间点进行分割,分割点为1958年1月1日
train, val = series.split_before(pd.Timestamp("19580101"))
# 绘制训练集数据的折线图,并给图例命名为“training”
train.plot(label="training")
# 绘制验证集数据的折线图,并给图例命名为“validation”
val.plot(label="validation")
训练预测模型和做出预测
玩具模型
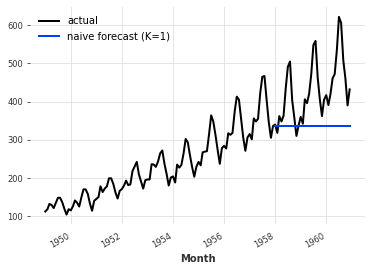
Darts中有一系列“天真”的基准模型,它们非常有用,可以让人们了解可以期望的最低准确度。例如,NaiveSeasonal(K)模型始终“重复”K个时间步骤之前发生的值。
在其最天真的形式下,当K=1时,该模型只是简单地重复训练序列的最后一个值:
# 导入NaiveSeasonal模型
from darts.models import NaiveSeasonal
# 初始化NaiveSeasonal模型,设置季节性参数K为1
naive_model = NaiveSeasonal(K=1)
# 使用训练数据拟合模型
naive_model.fit(train)
# 对未来36个时间步进行预测
naive_forecast = naive_model.predict(36)
# 绘制实际数据的曲线
series.plot(label="actual")
# 绘制NaiveSeasonal模型的预测曲线,设置K值为1
naive_forecast.plot(label="naive forecast (K=1)")
检查季节性
我们上面的模型可能有点太简单了。我们可以通过利用数据中的季节性来改进模型。很明显,数据具有年度季节性,我们可以通过查看自相关函数(ACF)并突出显示滞后m=12来确认这一点。
# 导入plot_acf和check_seasonality函数
from darts.utils.statistics import plot_acf, check_seasonality
# 使用plot_acf函数绘制训练数据的自相关图
# train为训练数据,m为季节周期,alpha为显著性水平
plot_acf(train, m=12, alpha=0.05)
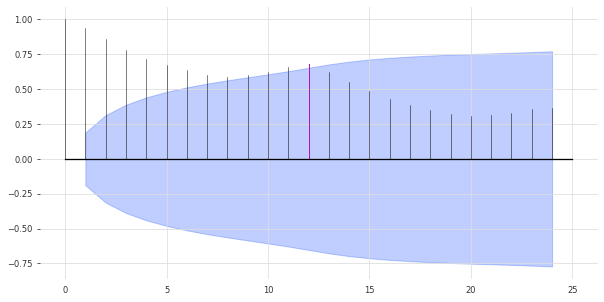
ACF在x = 12处呈现出一个尖峰,这表明存在年度季节性趋势(用红色标出)。蓝色区域确定了统计学上的显著性,置信水平为
α
=
5
%
\alpha = 5\%
α=5%。我们还可以对每个候选周期m进行季节性的统计检验。
# 循环遍历2到24的整数
for m in range(2, 25):
# 调用check_seasonality函数,传入训练数据train、m值和置信水平alpha
is_seasonal, period = check_seasonality(train, m=m, alpha=0.05)
# 如果存在季节性
if is_seasonal:
# 输出季节性的周期
print("There is seasonality of order {}.".format(period))
There is seasonality of order 12.
一个不那么天真的模型
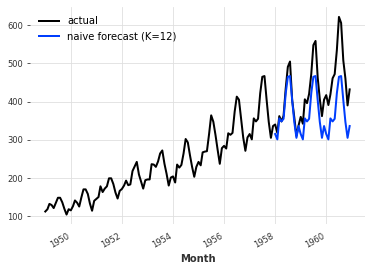
让我们再次尝试使用季节性为12的NaiveSeasonal模型:
# 创建一个NaiveSeasonal对象,K=12表示季节性的周期为12个月
seasonal_model = NaiveSeasonal(K=12)
# 使用训练数据来拟合(训练)季节性模型
seasonal_model.fit(train)
# 使用季节性模型来预测未来36个时间点的值
seasonal_forecast = seasonal_model.predict(36)
# 绘制实际数据的曲线
series.plot(label="实际数据")
# 绘制使用季节性模型预测的曲线,标签为"naive forecast (K=12)"
seasonal_forecast.plot(label="季节性预测 (K=12)")
这个更好了,但我们仍然缺少趋势。幸运的是,还有另一个天真的基准模型捕捉趋势,它被称为“NaiveDrift”。这个模型简单地产生线性预测,其斜率由训练集的第一个和最后一个值确定:
# 导入NaiveDrift模型类
from darts.models import NaiveDrift
# 创建NaiveDrift模型对象
drift_model = NaiveDrift()
# 使用训练数据拟合模型
drift_model.fit(train)
# 使用拟合好的模型进行36个时间步的预测
drift_forecast = drift_model.predict(36)
# 将季节性预测与趋势性预测相结合,并减去训练数据的最后一个值,得到综合预测结果
combined_forecast = drift_forecast + seasonal_forecast - train.last_value()
# 绘制原始时间序列图
series.plot()
# 绘制综合预测结果图,并添加标签
combined_forecast.plot(label="combined")
# 绘制趋势性预测结果图,并添加标签
drift_forecast.plot(label="drift")
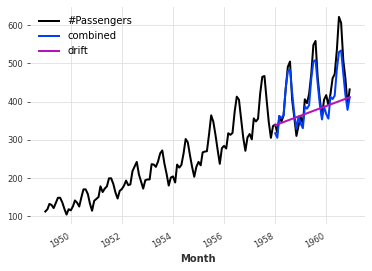
发生了什么?我们只是简单地拟合了一个天真的漂移模型,并将其预测添加到之前的季节性预测中。我们还从结果中减去了训练集的最后一个值,以便得到的组合预测具有正确的偏移量。
计算误差指标
这看起来已经是一个相当不错的预测了,而且我们还没有使用任何非朴素模型。实际上,任何模型都应该能够打败它。
那么我们需要打败的误差是多少呢?我们将使用平均绝对百分比误差(MAPE)(请注意,在实践中通常有很好的理由不使用MAPE - 我们在这里使用它是因为它非常方便和独立于规模)。在Darts中,这是一个简单的函数调用:
# 导入mape函数
from darts.metrics import mape
# 打印输出结果,使用format函数将mape函数计算得到的结果插入到字符串中
print(
"Mean absolute percentage error for the combined naive drift + seasonal: {:.2f}%.".format(
mape(series, combined_forecast)
)
)
Mean absolute percentage error for the combined naive drift + seasonal: 5.66%.
darts.metrics 包含许多用于比较时间序列的指标。当两个序列不对齐时,这些指标将仅比较共同的序列切片,并在大量序列对上并行计算 - 但让我们不要过于超前。
快速尝试几个模型
Darts旨在以统一的方式轻松训练和验证多个模型。让我们训练几个模型并计算它们在验证集上的MAPE。
# 导入需要的模块
from darts.models import ExponentialSmoothing, TBATS, AutoARIMA, Theta
# 定义一个评估模型的函数,接收一个模型作为参数
def eval_model(model):
# 使用训练数据拟合模型
model.fit(train)
# 使用模型预测验证集的长度
forecast = model.predict(len(val))
# 打印模型的MAPE评估结果
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
# 使用ExponentialSmoothing模型评估
eval_model(ExponentialSmoothing())
# 使用TBATS模型评估
eval_model(TBATS())
# 使用AutoARIMA模型评估
eval_model(AutoARIMA())
# 使用Theta模型评估
eval_model(Theta())
model ExponentialSmoothing(trend=ModelMode.ADDITIVE, damped=False, seasonal=SeasonalityMode.ADDITIVE, seasonal_periods=12 obtains MAPE: 5.11%
model (T)BATS obtains MAPE: 5.87%
model Auto-ARIMA obtains MAPE: 11.65%
model Theta(2) obtains MAPE: 8.15%
在这里,我们只是使用它们的默认参数构建了这些模型。如果我们对我们的问题进行微调,我们可能可以做得更好。让我们尝试使用Theta方法。
寻找使用Theta方法的超参数。
模型Theta包含了Assimakopoulos和Nikolopoulos的Theta方法的实现。这种方法在M3竞赛中取得了一些成功。
尽管在应用中Theta参数的值通常设置为0,但我们的实现支持参数调优的可变值。让我们尝试找到一个合适的Theta值:
# 寻找最佳的theta参数,尝试50个不同的值
thetas = 2 - np.linspace(-10, 10, 50) # 生成50个从-10到10的等差数列,再用2减去每个数,得到50个theta值
best_mape = float("inf") # 初始化最小平均绝对百分比误差为正无穷
best_theta = 0 # 初始化最佳theta值为0
# 遍历每个theta值
for theta in thetas:
model = Theta(theta) # 创建Theta模型对象,传入当前的theta值
model.fit(train) # 使用训练数据拟合模型
pred_theta = model.predict(len(val)) # 使用模型预测验证集的结果
res = mape(val, pred_theta) # 计算预测结果与真实结果的平均绝对百分比误差
# 如果当前的平均绝对百分比误差比之前的最小值更小,更新最小值和最佳theta值
if res < best_mape:
best_mape = res
best_theta = theta
# 创建一个Theta模型,使用最佳的theta值
best_theta_model = Theta(best_theta)
# 使用训练集对模型进行拟合
best_theta_model.fit(train)
# 使用验证集进行预测
pred_best_theta = best_theta_model.predict(len(val))
# 输出MAPE值和最佳theta值
print(
"The MAPE is: {:.2f}, with theta = {}.".format(
mape(val, pred_best_theta), best_theta
)
)
The MAPE is: 4.40, with theta = -3.5102040816326543.
# 给训练集的数据绘制图像,并标记为"train"
train.plot(label="train")
# 给验证集的数据绘制图像,并标记为"true"
val.plot(label="true")
# 给最佳theta预测的数据绘制图像,并标记为"prediction"
pred_best_theta.plot(label="prediction")
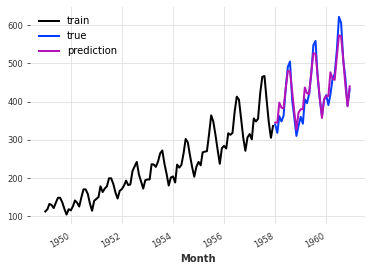
我们可以观察到,就MAPE而言,具有best_theta的模型到目前为止是我们最好的模型。
回测:模拟历史预测
所以在这一点上,我们有一个在验证集上表现良好的模型,这是好的。但是,我们如何知道如果我们在历史上一直使用这个模型,我们将获得的性能呢?
回测使用给定的模型模拟历史上可能获得的预测。由于模型(默认情况下)在每次模拟预测时间推进时都会重新训练,因此可能需要一些时间来生成。
这样的模拟预测总是与预测时间和预测时间之间的时间步数有关。在下面的示例中,我们模拟了未来3个月的预测(与预测时间相比)。调用historical_forecasts()的结果(默认情况下)是一个包含这些3个月预测的TimeSeries:
# 使用best_theta_model对series进行历史预测,预测起始时间为0.6,预测时间跨度为3个时间点,同时打印详细信息
historical_fcast_theta = best_theta_model.historical_forecasts(
series, start=0.6, forecast_horizon=3, verbose=True
)
# 绘制原始数据的图像
series.plot(label="data")
# 绘制历史预测结果的图像
historical_fcast_theta.plot(label="backtest 3-months ahead forecast (Theta)")
# 计算并打印MAPE指标
print("MAPE = {:.2f}%".format(mape(historical_fcast_theta, series)))
0%| | 0/57 [00:00<?, ?it/s]
MAPE = 7.70%
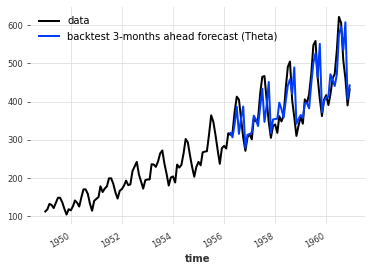
所以看起来我们在验证集上表现最好的模型在回测时并不那么出色(我听到过拟合了吗 😄)
为了更仔细地查看错误,我们还可以使用backtest()方法来获取模型可能得到的所有原始错误(比如MAPE错误):
# 创建Theta模型的实例,传入最佳参数best_theta
best_theta_model = Theta(best_theta)
# 对模型进行回测,传入时间序列数据series,起始时间start为0.6,预测时间horizon为3,评估指标为mape,不进行降维处理,打印详细信息
raw_errors = best_theta_model.backtest(
series, start=0.6, forecast_horizon=3, metric=mape, reduction=None, verbose=True
)
# 导入plot_hist函数,绘制raw_errors的直方图,设置bins为0到raw_errors的最大值,标题为"Individual backtest error scores (histogram)"
from darts.utils.statistics import plot_hist
plot_hist(
raw_errors,
bins=np.arange(0, max(raw_errors), 1),
title="Individual backtest error scores (histogram)",
)
0%| | 0/57 [00:00<?, ?it/s]
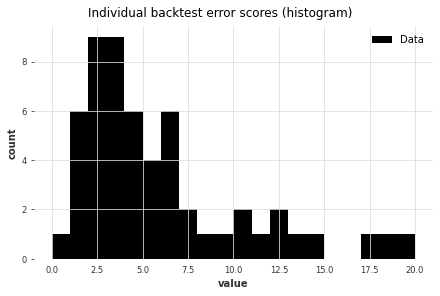
最后,使用backtest()函数,我们还可以更简单地查看历史预测的平均误差。
# 计算平均误差
average_error = best_theta_model.backtest(
series, # 输入时间序列数据
start=0.6, # 设置开始时间的比例,这里是从时间序列的60%处开始
forecast_horizon=3, # 设置预测的时间范围,这里是预测未来3个时间点
metric=mape, # 使用MAPE作为评估指标
reduction=np.mean, # 设置误差的计算方法为取平均值,这实际上是默认设置
verbose=True, # 打印详细信息
)
# 打印平均误差(MAPE)在所有历史预测中的结果
print("Average error (MAPE) over all historical forecasts: %.2f" % average_error)
0%| | 0/57 [00:00<?, ?it/s]
Average error (MAPE) over all historical forecasts: 6.36
我们还可以指定参数reduction=np.median来获得中位数MAPE。
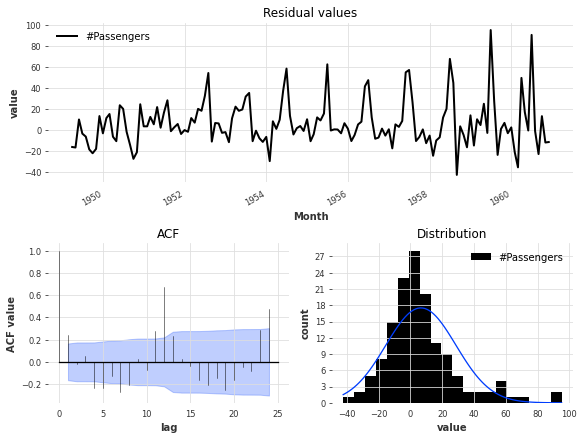
查看残差
让我们来看看当前Theta模型的拟合值残差,即在所有先前时间点上拟合模型并获得每个时间点的1步预测与实际观测值之间的差异:
# 导入plot_residuals_analysis函数
# 该函数用于绘制时间序列模型的残差分析图
from darts.utils.statistics import plot_residuals_analysis
# 调用best_theta_model.residuals()函数获取时间序列模型的残差
# best_theta_model是一个时间序列模型对象,residuals()函数用于获取该模型的残差
# series是一个时间序列对象,作为best_theta_model.residuals()函数的参数,用于计算该模型的残差
residuals = best_theta_model.residuals(series)
# 调用plot_residuals_analysis()函数,传入残差数据作为参数
# 该函数会绘制出残差分析图,用于评估时间序列模型的拟合效果
plot_residuals_analysis(residuals)
更好的模型
我们可以看到分布不是以0为中心,这意味着我们的Theta模型存在偏差。我们还可以看出在滞后等于12时有一个很大的ACF值,这表明残差包含了模型未使用的信息。
也许我们可以用一个简单的ExponentialSmoothing模型做得更好吗?
# 定义了一个 ExponentialSmoothing 类的实例,其中 seasonal_periods=12 表示季节周期为 12 个月
model_es = ExponentialSmoothing(seasonal_periods=12)
# 使用 historical_forecasts() 方法进行历史预测,其中 series 为时间序列数据,start=0.6 表示从数据的 60% 开始预测,forecast_horizon=3 表示预测未来 3 个月,verbose=True 表示打印详细信息
historical_fcast_es = model_es.historical_forecasts(
series, start=0.6, forecast_horizon=3, verbose=True
)
# 绘制原始数据的折线图
series.plot(label="data")
# 绘制指数平滑模型的历史预测结果的折线图
historical_fcast_es.plot(label="backtest 3-months ahead forecast (Exp. Smoothing)")
# 打印 MAPE 值,其中 mape() 函数用于计算预测值和真实值之间的平均绝对百分比误差
print("MAPE = {:.2f}%".format(mape(historical_fcast_es, series)))
0%| | 0/57 [00:00<?, ?it/s]
MAPE = 4.45%
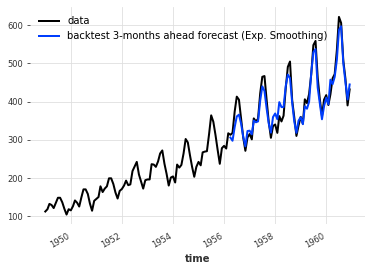
这好多了!在这种情况下,我们进行三个月预测时的平均绝对百分比误差约为4-5%。
# 对模型的残差进行可视化分析
# 使用model_es.residuals()函数获取模型的残差,并传入series参数
# 将获取到的残差数据作为参数传入plot_residuals_analysis()函数中进行可视化分析
plot_residuals_analysis(model_es.residuals(series))
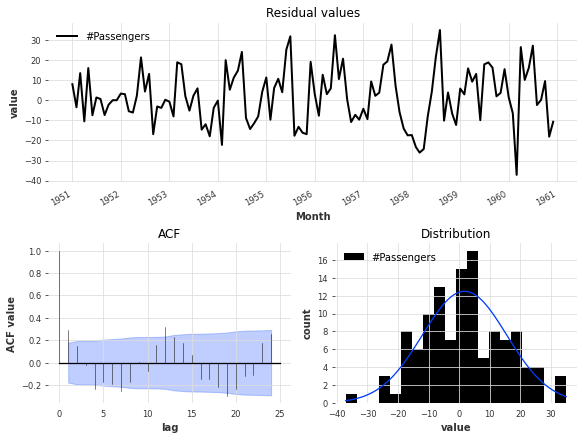
残差分析也反映了改进的表现,因为我们现在有一个以值0为中心的残差分布,尽管ACF值并不显著,但幅度较低。
机器学习和全局模型
Darts对机器学习和深度学习预测模型有很好的支持,例如:
- RegressionModel可以包装任何与sklearn兼容的回归模型以产生预测结果(它有自己的下面的部分)。
- RNNModel是一个灵活的RNN实现,可以像DeepAR一样使用。
- NBEATSModel实现了N-BEATS模型。
- TFTModel实现了时间融合变压器模型。
- TCNModel实现了时间卷积网络。
- …
除了支持其他模型相同的基本fit()/predict()接口外,这些模型还是全局模型,因为它们支持在多个时间序列上进行训练(有时称为元学习)。
这是使用基于ML的模型进行预测的关键点:往往情况下,ML模型(尤其是深度学习模型)需要在大量数据上进行训练,这通常意味着大量独立但相关的时间序列。
在Darts中,指定多个TimeSeries的基本方法是使用TimeSeries的Sequence(例如,一个简单的TimeSeries列表)。
一个包含两个序列的玩具示例
这些模型可以在成千上万个序列上进行训练。在这里,为了说明的目的,我们将加载两个不同的序列 - 航空客流量和每月每头奶牛产奶量的序列。我们还将将我们的序列转换为np.float32,因为这将稍微加快训练速度:
# 导入AirPassengersDataset和MonthlyMilkDataset数据集
from darts.datasets import AirPassengersDataset, MonthlyMilkDataset
# 加载AirPassengersDataset数据集并将其转换为float32类型
series_air = AirPassengersDataset().load().astype(np.float32)
# 加载MonthlyMilkDataset数据集并将其转换为float32类型
series_milk = MonthlyMilkDataset().load().astype(np.float32)
# 将每个序列的最后36个月作为验证集,其余作为训练集
train_air, val_air = series_air[:-36], series_air[-36:]
train_milk, val_milk = series_milk[:-36], series_milk[-36:]
# 绘制AirPassengersDataset数据集的训练集和验证集
train_air.plot()
val_air.plot()
# 绘制MonthlyMilkDataset数据集的训练集和验证集
train_milk.plot()
val_milk.plot()
首先,让我们将这两个序列缩放到0到1之间,因为这将有利于大多数ML模型。我们将使用Scaler进行此操作。
# 导入Scaler类
from darts.dataprocessing.transformers import Scaler
# 创建一个Scaler对象
scaler = Scaler()
# 使用fit_transform方法对train_air和train_milk进行缩放处理,并将结果保存在train_air_scaled和train_milk_scaled中
train_air_scaled, train_milk_scaled = scaler.fit_transform([train_air, train_milk])
# 绘制train_air_scaled的图形
train_air_scaled.plot()
# 绘制train_milk_scaled的图形
train_milk_scaled.plot()
请注意,我们可以一次性缩放多个系列。我们还可以通过指定“n_jobs”来将这种操作并行化到多个处理器上。
使用深度学习:N-BEATS的示例
接下来,我们将构建一个N-BEATS模型。该模型可以通过许多超参数进行调整(例如堆叠数量、层数等)。在这里,为了简单起见,我们将使用默认的超参数。我们只需要提供两个超参数:
input_chunk_length:这是模型的“回溯窗口”,即神经网络在前向传递中将多少个时间步的历史作为输入来生成输出。output_chunk_length:这是模型的“前向窗口”,即神经网络在前向传递中输出多少个时间步的未来值。
random_state参数只是为了获得可重复的结果。
Darts中的大多数神经网络都需要这两个参数。在这里,我们将使用季节性的倍数。现在,我们准备好将我们的模型拟合到我们的两个序列上(通过将包含这两个序列的列表传递给fit()函数)。
# 导入NBEATS模型类
from darts.models import NBEATSModel
# 创建一个NBEATS模型对象
# input_chunk_length表示输入序列的长度为24
# output_chunk_length表示输出序列的长度为12
# random_state表示随机种子,用于重现实验结果
model = NBEATSModel(input_chunk_length=24, output_chunk_length=12, random_state=42)
# 使用训练数据对模型进行训练
# train_air_scaled和train_milk_scaled是训练数据,需要是Darts库中的TimeSeries类型
# epochs表示训练的轮数为50
# verbose=True表示训练过程中输出详细信息
model.fit([train_air_scaled, train_milk_scaled], epochs=50, verbose=True);
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
---------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | stacks | ModuleList | 6.2 M
---------------------------------------------------
6.2 M Trainable params
1.4 K Non-trainable params
6.2 M Total params
24.787 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=50` reached.
让我们现在对我们的两个系列进行36个月的预测。我们可以使用fit()函数的series参数告诉模型要预测哪个系列。重要的是,output_chunk_length并不直接限制可以与predict()一起使用的预测范围n。在这里,我们使用output_chunk_length=12训练了模型,并为n=36个月的预测生成了预测;这只是在幕后以自回归方式完成的(其中网络递归地消耗其先前的输出)。
# 预测空气数据和牛奶数据
# 使用模型对空气数据进行预测,预测36个时间步
pred_air = model.predict(series=train_air_scaled, n=36)
# 使用模型对牛奶数据进行预测,预测36个时间步
pred_milk = model.predict(series=train_milk_scaled, n=36)
# 将预测结果进行反向缩放,得到原始数据的预测结果
pred_air, pred_milk = scaler.inverse_transform([pred_air, pred_milk])
# 绘制图表
plt.figure(figsize=(10, 6))
series_air.plot(label="实际数据 (空气)")
series_milk.plot(label="实际数据 (牛奶)")
pred_air.plot(label="预测数据 (空气)")
pred_milk.plot(label="预测数据 (牛奶)")
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: 0it [00:00, ?it/s]
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: 0it [00:00, ?it/s]
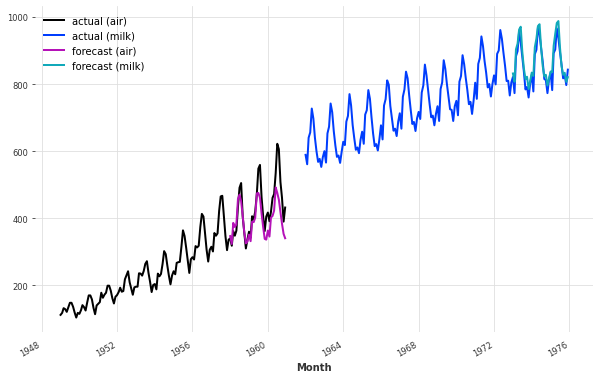
我们的预测实际上并不那么糟糕,考虑到我们使用一个模型和默认的超参数来捕捉空中乘客和牛奶生产的情况!
该模型在捕捉年度季节性方面似乎还不错,但在空中系列的趋势方面却有所遗漏。在下一节中,我们将尝试使用外部数据(协变量)来解决这个问题。
协变量:使用外部数据
除了目标系列(我们感兴趣的预测系列)之外,Darts中的许多模型还接受输入的协变量系列。协变量是我们不想预测的系列,但可以为模型提供有用的附加信息。目标和协变量都可以是多变量或单变量。
Darts中有两种类型的协变量时间序列:
past_covariates是在预测时间之前不一定已知的系列。这些可以代表需要测量但事先不知道的事物。模型在进行预测时不使用past_covariates的未来值。future_covariates是预先已知的系列,直到预测的时间范围。这可以代表诸如日历信息、假期、天气预报等事物。接受future_covariates的模型在进行预测时会查看未来值(直到预测的时间范围)。

每个协变量理论上可以是多变量的。如果您有多个协变量系列(例如月份和年份值),您应该使用stack()或concatenate()将它们合并成一个多变量系列。
您提供的协变量可以比所需的时间长。Darts会尝试聪明地根据不同系列的时间索引将它们切片以预测目标。但是,如果您的协变量时间跨度不足,您将收到错误提示。
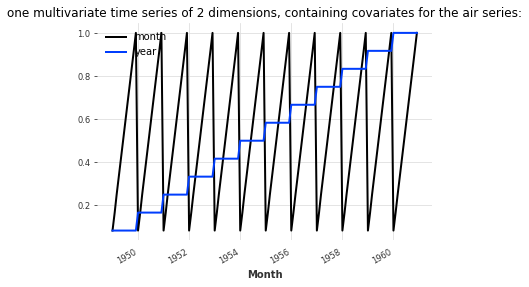
现在让我们构建一些包含空气和牛奶系列的外部协变量,其中包含月度和年度值。
在下面的单元格中,我们使用darts.utils.timeseries_generation.datetime_attribute_timeseries()函数生成包含月份和年份值的系列,并使用concatenate()函数沿着“component”轴将这些系列连接起来,以获得一个具有两个组成部分(月份和年份)的协变量系列,每个目标系列一个。为简单起见,我们直接将月份和年份值缩放到(大约)0到1之间:
# 导入concatenate函数和datetime_attribute_timeseries函数
from darts import concatenate
from darts.utils.timeseries_generation import datetime_attribute_timeseries as dt_attr
# 生成空气时间序列的协变量
# 将月份转换为浮点数并除以12,将年份转换为浮点数并减去1948再除以12
air_covs = concatenate(
[
dt_attr(series_air.time_index, "month", dtype=np.float32) / 12,
(dt_attr(series_air.time_index, "year", dtype=np.float32) - 1948) / 12,
],
axis="component",
)
# 生成牛奶时间序列的协变量
# 将月份转换为浮点数并除以12,将年份转换为浮点数并减去1962再除以13
milk_covs = concatenate(
[
dt_attr(series_milk.time_index, "month", dtype=np.float32) / 12,
(dt_attr(series_milk.time_index, "year", dtype=np.float32) - 1962) / 13,
],
axis="component",
)
# 绘制空气时间序列的协变量
air_covs.plot()
# 设置图表标题
plt.title(
"one multivariate time series of 2 dimensions, containing covariates for the air series:"
);
并非所有模型都支持所有类型的协变量。NBEATSModel仅支持past_covariates。因此,即使我们的协变量代表日历信息并且是预先知道的,我们也会将它们作为past_covariates与N-BEATS一起使用。要进行训练,我们只需将它们按照与目标相同的顺序作为past_covariates传递给fit()函数。
# 创建一个NBEATS模型对象,设置输入序列长度为24,输出序列长度为12,随机种子为42
model = NBEATSModel(input_chunk_length=24, output_chunk_length=12, random_state=42)
# 使用训练数据和对应的过去协变量进行模型训练
# train_air_scaled为训练数据的空气数据部分,train_milk_scaled为训练数据的牛奶数据部分
# air_covs为空气数据的过去协变量,milk_covs为牛奶数据的过去协变量
# 这里使用了多个输入序列和对应的过去协变量进行训练
model.fit(
[train_air_scaled, train_milk_scaled],
past_covariates=[air_covs, milk_covs],
epochs=50, # 训练轮数为50轮
verbose=True, # 输出训练过程中的详细信息
)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
---------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | stacks | ModuleList | 6.6 M
---------------------------------------------------
6.6 M Trainable params
1.7 K Non-trainable params
6.6 M Total params
26.314 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=50` reached.
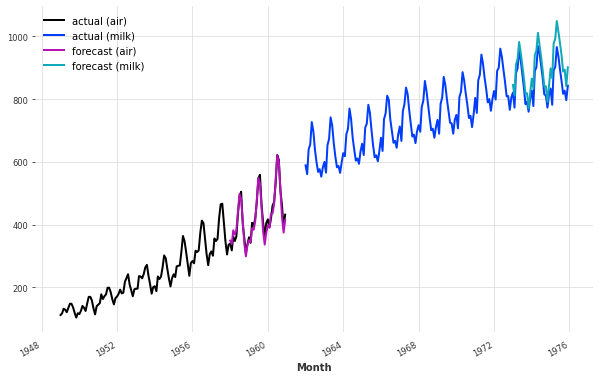
然后,为了生成预测,我们需要再次将我们的协变量作为past_covariates提供给predict()函数。尽管协变量时间序列也包含了预测时段的"未来"协变量值,但模型不会使用这些未来值,因为它将它们作为过去的协变量(而不是未来的协变量)。
# 导入模型后,使用模型对空气和牛奶的时间序列数据进行预测
pred_air = model.predict(series=train_air_scaled, past_covariates=air_covs, n=36)
pred_milk = model.predict(series=train_milk_scaled, past_covariates=milk_covs, n=36)
# 将预测结果进行反向缩放,得到真实的预测值
pred_air, pred_milk = scaler.inverse_transform([pred_air, pred_milk])
# 绘制预测结果图像,包括空气和牛奶的实际值和预测值
plt.figure(figsize=(10, 6))
series_air.plot(label="actual (air)")
series_milk.plot(label="actual (milk)")
pred_air.plot(label="forecast (air)")
pred_milk.plot(label="forecast (milk)")
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: 0it [00:00, ?it/s]
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: 0it [00:00, ?it/s]
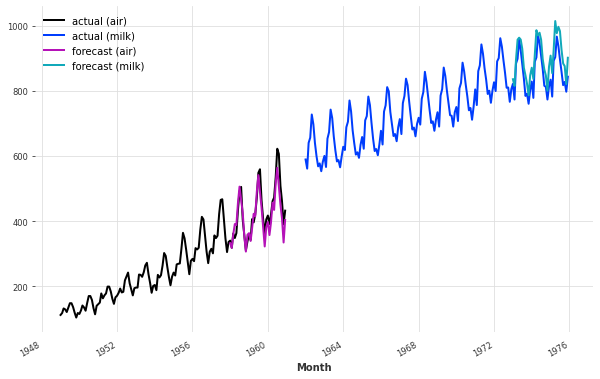
现在模型似乎更好地捕捉到了空气系列的趋势(这也稍微扰动了牛奶系列的预测)。
编码器:免费使用协变量
在Darts中,与日历或时间轴相关的协变量(如上面的示例中的月份和年份)是如此频繁,以至于深度学习模型具有内置功能,可以直接使用这些协变量。
要将这些协变量轻松集成到您的模型中,您只需在模型创建时指定add_encoders参数。该参数必须是一个包含有关应将其编码为额外协变量的信息的字典。以下是一个这样的字典的示例,用于支持过去和未来协变量的模型:
# 定义一个函数,用于提取时间索引中的年份并进行归一化处理
def extract_year(idx):
"""提取时间索引中的年份并进行归一化处理"""
return (idx.year - 1950) / 50
# 定义一个字典,用于存储不同类型的编码器及其参数
encoders = {
# 循环编码器,用于处理未来的月份特征
"cyclic": {"future": ["month"]},
# 日期时间属性编码器,用于处理未来的小时和星期几特征
"datetime_attribute": {"future": ["hour", "dayofweek"]},
# 位置编码器,用于处理过去的绝对位置和未来的相对位置特征
"position": {"past": ["absolute"], "future": ["relative"]},
# 自定义编码器,用于处理过去的自定义特征
"custom": {"past": [extract_year]},
# 转换器编码器,用于对特征进行缩放处理
"transformer": Scaler(),
}
在上述字典中,指定了以下内容:
- 月份应作为未来协变量使用,使用循环(sin/cos)编码。
- 小时和星期几应作为未来协变量使用。
- 绝对位置(时间序列中的时间步骤)应作为过去协变量使用。
- 相对位置(相对于预测时间)应作为未来协变量使用。
- 年份的另一个自定义函数应作为过去协变量使用。
- 所有上述协变量应使用“Scaler”进行缩放,该缩放器将在调用模型“fit()”函数时进行拟合,并在之后用于转换协变量。
有关如何使用编码器的更多信息,请参见API文档。请注意,无法使用lambda函数,因为它们无法被pickable。
要使用月份和年份作为过去协变量来复制我们的示例,并使用N-BEATS,我们可以使用以下一些编码器:
# 定义了一个字典encoders,其中包含两个键值对
# 第一个键值对的键为"datetime_attribute",值为一个字典
# 第一个键值对的值字典中包含一个键值对
# 第二个键值对的键为"past",值为一个包含两个字符串元素的列表,分别为"month"和"year"
# 第二个键值对的键为"transformer",值为一个名为Scaler的对象
encoders = {"datetime_attribute": {"past": ["month", "year"]}, "transformer": Scaler()}
现在,使用这些协变量进行N-BEATS模型的整个训练如下:
# 创建一个NBEATS模型对象
# input_chunk_length=24表示输入序列的长度为24
# output_chunk_length=12表示输出序列的长度为12
# add_encoders=encoders表示使用指定的编码器
# random_state=42表示设置随机种子为42
model = NBEATSModel(
input_chunk_length=24,
output_chunk_length=12,
add_encoders=encoders,
random_state=42,
)
# 使用训练数据对模型进行训练
# [train_air_scaled, train_milk_scaled]表示训练数据,包括空气质量和牛奶销量的数据
# epochs=50表示训练的轮数为50
# verbose=True表示打印训练过程中的详细信息
model.fit([train_air_scaled, train_milk_scaled], epochs=50, verbose=True);
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
---------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | stacks | ModuleList | 6.6 M
---------------------------------------------------
6.6 M Trainable params
1.7 K Non-trainable params
6.6 M Total params
26.314 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=50` reached.
并获取一些航空旅客系列的预测。
# 预测空气数据
# 使用模型对训练集的空气数据进行预测,预测结果存储在pred_air中
pred_air = model.predict(series=train_air_scaled, n=36)
# 将预测结果还原为原始数据的尺度
pred_air = scaler.inverse_transform(pred_air)
# 创建一个图表,设置图表大小为10x6
plt.figure(figsize=(10, 6))
# 绘制实际的空气数据曲线,设置标签为"actual (air)"
series_air.plot(label="actual (air)")
# 绘制预测的空气数据曲线,设置标签为"forecast (air)"
pred_air.plot(label="forecast (air)")
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: 0it [00:00, ?it/s]
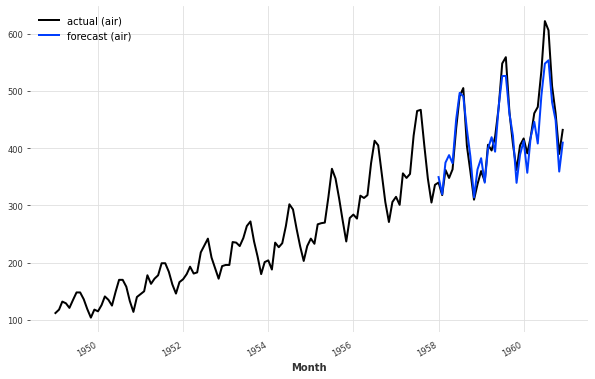
回归预测模型
RegressionModel是封装在sklearn兼容的回归模型周围的预测模型。内部回归模型用于根据目标序列的某些滞后值、过去和未来的协变量来预测目标序列的未来值。在幕后,时间序列被制表化以构建正确格式的训练数据集。
默认情况下,RegressionModel将进行线性回归。通过指定model参数,可以很容易地使用任何所需的sklearn兼容的回归模型,但为了方便起见,Darts还提供了一些现成的模型:
- RandomForest封装了
sklearn.ensemble.RandomForestRegressor。 - LightGBMModel封装了
lightbm。 - LinearRegressionModel封装了
sklearn.linear_model.LinearRegression(接受相同的kwargs)。
例如,将贝叶斯岭回归拟合到我们的玩具两个序列问题的示例代码如下:
# 导入RegressionModel类和BayesianRidge类
from darts.models import RegressionModel
from sklearn.linear_model import BayesianRidge
# 创建一个RegressionModel对象,设置lags为72,表示使用前72个时间步作为输入特征,lags_future_covariates为[-6, 0],表示使用前6个和当前时间步作为未来协变量
# model使用BayesianRidge模型
model = RegressionModel(lags=72, lags_future_covariates=[-6, 0], model=BayesianRidge())
# 使用fit方法拟合模型,传入训练数据train_air_scaled和train_milk_scaled,同时传入未来协变量air_covs和milk_covs
model.fit(
[train_air_scaled, train_milk_scaled], future_covariates=[air_covs, milk_covs]
);
以下是发生的几件事情:
lags=72告诉RegressionModel要查看目标的过去 72 个滞后。- 此外,
lags_future_covariates=[-6, 0]意味着模型还将查看我们提供的future_covariates的滞后。在这里,我们列举了我们希望模型考虑的具体滞后;“-6th” 和 “0th” 滞后。 “0th” 滞后表示 “当前” 滞后(即在进行预测的时间步骤上);显然,了解此滞后需要提前了解数据(因此我们使用future_covariates)。类似地,“-6” 意味着我们还要查看预测时间步骤之前 6 个月的协变量值(如果我们预测的时间范围超过 6 个步骤,则还需要提前了解协变量)。 model=BayesianRidge()提供了实际的内部回归模型。
现在让我们进行一些预测:
# 预测
pred_air, pred_milk = model.predict(
series=[train_air_scaled, train_milk_scaled], # 使用训练集的空气质量和牛奶销量数据进行预测
future_covariates=[air_covs, milk_covs], # 使用未来的空气质量和牛奶销量的协变量数据进行预测
n=36, # 预测未来36个时间步长的数据
)
# 还原缩放
pred_air, pred_milk = scaler.inverse_transform([pred_air, pred_milk]) # 将预测结果还原为原始数据的范围
# 绘制图表
plt.figure(figsize=(10, 6))
series_air.plot(label="actual (air)") # 绘制实际空气质量数据的曲线
series_milk.plot(label="actual (milk)") # 绘制实际牛奶销量数据的曲线
pred_air.plot(label="forecast (air)") # 绘制预测的空气质量数据的曲线
pred_milk.plot(label="forecast (milk)") # 绘制预测的牛奶销量数据的曲线
请注意我们如何同时获取上述两个时间序列的预测。同样地,我们也可以对序列进行一些指标计算。
mape([series_air, series_milk], [pred_air, pred_milk])
[3.41736301779747, 5.282935127615929]
或者对于“所有”系列的平均度量。
# 调用mape函数,计算两个时间序列的MAPE值
mape([series_air, series_milk], [pred_air, pred_milk], inter_reduction=np.mean)
4.350149072706699
顺便提一下:与Scaler等转换器类似,通过指定n_jobs=N,在执行许多时间序列对的计算度量时,可以在N个处理器上并行化。
这个模型在航空交通系列上表现良好,但在我们对这个系列进行回测时,它的表现如何?
# 导入RegressionModel类
# 该类用于构建回归模型,包括时间滞后项、未来协变量等参数
# 导入BayesianRidge类
# 该类用于构建贝叶斯岭回归模型
bayes_ridge_model = RegressionModel(
lags=72, lags_future_covariates=[0], model=BayesianRidge()
)
# 使用historical_forecasts方法进行回测
# series_air为时间序列数据
# future_covariates为未来协变量
# start为开始时间
# forecast_horizon为预测时间
# verbose为是否打印详细信息
backtest = bayes_ridge_model.historical_forecasts(
series_air, future_covariates=air_covs, start=0.6, forecast_horizon=3, verbose=True
)
# 计算MAPE指标
# mape为自定义函数,用于计算MAPE指标
print("MAPE = %.2f" % (mape(backtest, series_air)))
# 绘制原始数据和回测数据的图像
series_air.plot()
backtest.plot()
0%| | 0/57 [00:00<?, ?it/s]
MAPE = 3.66
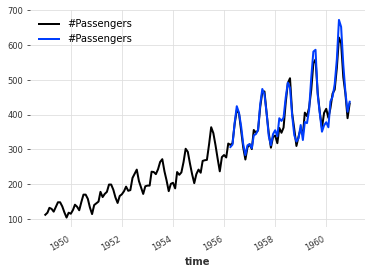
我们迄今为止最好的模型!
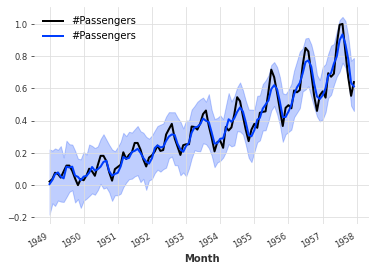
概率预测
一些模型可以生成概率预测。这适用于所有深度学习模型(如RNNModel,NBEATSModel等),以及ARIMA和ExponentialSmoothing。完整列表可在Darts README页面上找到。
对于ARIMA和ExponentialSmoothing,可以简单地在predict()函数中指定一个num_samples参数。返回的TimeSeries将由num_samples个蒙特卡洛样本组成,描述时间序列值的分布。依赖蒙特卡洛样本(与显式置信区间相比)的优势在于,它们可以用于描述任何参数化或非参数化的组件联合分布,并计算任意分位数。
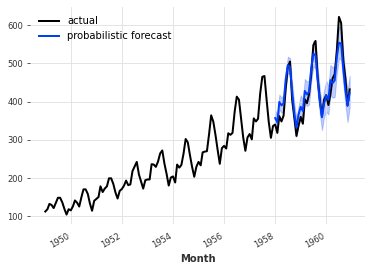
# 创建指数平滑模型
model_es = ExponentialSmoothing()
# 使用训练数据拟合模型
model_es.fit(train)
# 使用模型预测未来一段时间的数据,num_samples表示使用多少个样本进行预测
probabilistic_forecast = model_es.predict(len(val), num_samples=500)
# 绘制实际数据的图像
series.plot(label="actual")
# 绘制预测数据的图像
probabilistic_forecast.plot(label="probabilistic forecast")
# 添加图例
plt.legend()
# 显示图像
plt.show()
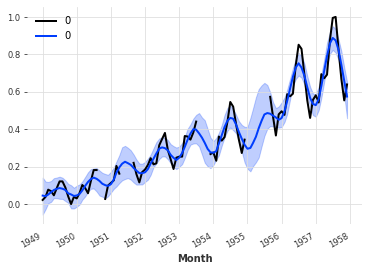
使用神经网络
使用神经网络时,必须向模型提供一个Likelihood对象。这些似然函数指定模型将尝试拟合的分布,以及分布参数的潜在先验值。可用似然函数的完整列表在文档中可用。
使用似然函数很简单。例如,下面是训练一个NBEATSModel以适应拉普拉斯似然函数的示例:
# 导入所需的模块和类
from darts.models import TCNModel
from darts.utils.likelihood_models import LaplaceLikelihood
# 创建一个TCNModel对象
# 设置输入时间序列的长度为24,输出时间序列的长度为12
# 设置随机种子为42
# 设置似然函数为LaplaceLikelihood
model = TCNModel(
input_chunk_length=24,
output_chunk_length=12,
random_state=42,
likelihood=LaplaceLikelihood(),
)
# 使用训练数据对模型进行训练
# 设置训练轮数为400
# 设置显示训练过程中的详细信息
model.fit(train_air_scaled, epochs=400, verbose=True);
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
----------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | dropout | MonteCarloDropout | 0
4 | res_blocks | ModuleList | 166
----------------------------------------------------
166 Trainable params
0 Non-trainable params
166 Total params
0.001 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=400` reached.
然后,要获得概率预测,我们只需要指定一些“num_samples >> 1”即可:
# 预测模型
pred = model.predict(n=36, num_samples=500)
# 使用模型对未来36个时间步进行预测,生成500个样本
# 反向缩放
pred = scaler.inverse_transform(pred)
# 将预测结果反向缩放,还原为原始数据的范围
# 绘制原始数据
series_air.plot()
# 绘制原始数据的折线图
# 绘制预测结果
pred.plot()
# 绘制预测结果的折线图
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: 0it [00:00, ?it/s]
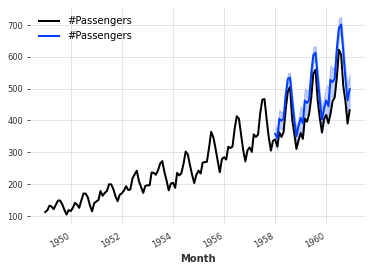
此外,我们还可以例如指定我们对分布的尺度有一些先验信念,大约为
0.1
0.1
0.1(在转换域中),同时仍然捕捉到分布的一些时间依赖性,通过指定prior_b=.1。
在幕后,这将使用Kullback-Leibler散度项对训练损失进行正则化。
# 导入TCNModel模型
# input_chunk_length表示输入数据的时间步长
# output_chunk_length表示输出数据的时间步长
# random_state表示随机数种子,保证每次运行结果一致
# likelihood表示概率分布函数,这里使用LaplaceLikelihood,prior_b表示Laplace分布的尺度参数
model = TCNModel(
input_chunk_length=24,
output_chunk_length=12,
random_state=42,
likelihood=LaplaceLikelihood(prior_b=0.1),
)
# 使用训练数据train_air_scaled进行模型训练
# epochs表示训练轮数
# verbose表示是否打印训练过程中的详细信息
model.fit(train_air_scaled, epochs=400, verbose=True);
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
----------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | dropout | MonteCarloDropout | 0
4 | res_blocks | ModuleList | 166
----------------------------------------------------
166 Trainable params
0 Non-trainable params
166 Total params
0.001 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=400` reached.
# 预测
pred = model.predict(n=36, num_samples=500)
# 反向缩放
pred = scaler.inverse_transform(pred)
# 绘制原始数据
series_air.plot()
# 绘制预测数据
pred.plot()
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: 0it [00:00, ?it/s]
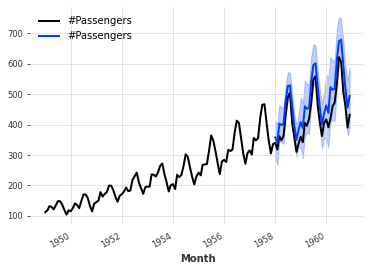
默认情况下,TimeSeries.plot()会显示中位数以及第5和第95百分位数(如果TimeSeries是多变量的话,会显示边际分布)。可以对此进行控制。
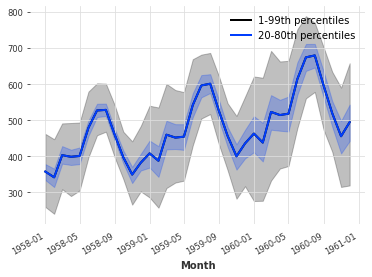
# 绘制pred的1-99分位数的图像,low_quantile=0.01表示下分位数为1%,high_quantile=0.99表示上分位数为99%
# label="1-99th percentiles"表示图像的标签为“1-99分位数”
pred.plot(low_quantile=0.01, high_quantile=0.99, label="1-99th percentiles")
# 绘制pred的20-80分位数的图像,low_quantile=0.2表示下分位数为20%,high_quantile=0.8表示上分位数为80%
# label="20-80th percentiles"表示图像的标签为“20-80分位数”
pred.plot(low_quantile=0.2, high_quantile=0.8, label="20-80th percentiles")
分布类型
似然函数必须与时间序列值的域兼容。例如,PoissonLikelihood 可以用于离散正值,ExponentialLikelihood 可以用于实数正值,而BetaLikelihood 可以用于 ( 0 , 1 ) (0,1) (0,1)范围内的实数值。
还可以使用QuantileRegression 应用分位数损失并直接拟合所需的分位数。
评估概率预测
我们如何评估概率预测的质量?默认情况下,大多数度量函数(如mape())仍然有效,但只考虑中位数预测。还可以使用
ρ
\rho
ρ-risk度量(或分位数损失),该度量量化了每个预测分位数的误差:
# 导入rho_risk函数
from darts.metrics import rho_risk
# 输出median forecast的MAPE
print("MAPE of median forecast: %.2f" % mape(series_air, pred))
# 遍历rho列表,计算rho-risk
for rho in [0.05, 0.1, 0.5, 0.9, 0.95]:
# 调用rho_risk函数,计算rho-risk
rr = rho_risk(series_air, pred, rho=rho)
# 输出rho-risk结果
print("rho-risk at quantile %.2f: %.2f" % (rho, rr))
MAPE of median forecast: 11.80
rho-risk at quantile 0.05: 0.14
rho-risk at quantile 0.10: 0.15
rho-risk at quantile 0.50: 0.11
rho-risk at quantile 0.90: 0.03
rho-risk at quantile 0.95: 0.02
使用分位数损失
我们能否通过直接拟合这些分位数来取得更好的效果?我们可以使用QuantileRegression似然函数:
# 导入QuantileRegression模型
from darts.utils.likelihood_models import QuantileRegression
# 初始化TCNModel模型,设置输入序列长度为24,输出序列长度为12,随机种子为42,使用QuantileRegression模型进行预测
model = TCNModel(
input_chunk_length=24,
output_chunk_length=12,
random_state=42,
likelihood=QuantileRegression([0.05, 0.1, 0.5, 0.9, 0.95]),
)
# 使用训练数据train_air_scaled进行训练,迭代400次,输出训练过程信息
model.fit(train_air_scaled, epochs=400, verbose=True);
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
----------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | dropout | MonteCarloDropout | 0
4 | res_blocks | ModuleList | 208
----------------------------------------------------
208 Trainable params
0 Non-trainable params
208 Total params
0.001 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=400` reached.
# 预测模型
pred = model.predict(n=36, num_samples=500)
# 反向缩放
pred = scaler.inverse_transform(pred)
# 绘制原始数据
series_air.plot()
# 绘制预测数据
pred.plot()
# 计算并打印预测值与真实值之间的平均绝对百分比误差(MAPE)
print("MAPE of median forecast: %.2f" % mape(series_air, pred))
# 计算并打印在不同分位数下的rho-risk
for rho in [0.05, 0.1, 0.5, 0.9, 0.95]:
rr = rho_risk(series_air, pred, rho=rho)
print("rho-risk at quantile %.2f: %.2f" % (rho, rr))
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: 0it [00:00, ?it/s]
MAPE of median forecast: 4.96
rho-risk at quantile 0.05: 0.00
rho-risk at quantile 0.10: 0.00
rho-risk at quantile 0.50: 0.03
rho-risk at quantile 0.90: 0.01
rho-risk at quantile 0.95: 0.01
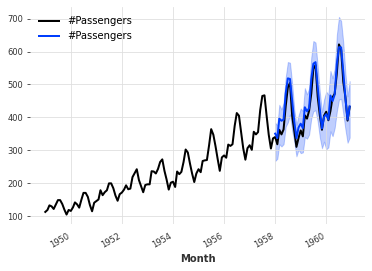
模型集成
模型集成是指将多个模型产生的预测组合起来,以获得最终的 - 且希望更好的预测结果。
例如,在我们上面的不那么天真的模型的示例中,我们手动将一个天真的季节模型与一个天真的漂移模型组合起来。在这里,我们将展示如何自动组合模型预测,使用NaiveEnsembleModel进行天真组合,或使用RegressionEnsembleModel进行学习。
当然,也可以在集成模型中使用past和/或future_covariates,但只有在调用fit()和predict()时支持它们的模型才会传递它们。
Naive Ensembling
Naive ensembling(天真集成)只是将几个模型的预测结果取平均值。Darts提供了NaiveEnsembleModel,可以在仅操作一个预测模型的情况下实现这一点(例如,可以更容易地进行回测):
# 导入需要的模块
from darts.models import NaiveEnsembleModel
# 创建两个预测模型对象,分别为NaiveDrift和NaiveSeasonal
models = [NaiveDrift(), NaiveSeasonal(12)]
# 创建一个NaiveEnsembleModel对象,将上述两个预测模型作为参数传入
ensemble_model = NaiveEnsembleModel(forecasting_models=models)
# 使用ensemble_model进行历史预测,将结果保存在backtest中
# series_air为待预测的时间序列数据,start为预测起始位置,forecast_horizon为预测的时间范围,verbose为是否显示详细信息
backtest = ensemble_model.historical_forecasts(
series_air, start=0.6, forecast_horizon=3, verbose=True
)
# 计算预测结果backtest与原始数据series_air之间的MAPE,并打印结果
print("MAPE = %.2f" % (mape(backtest, series_air)))
# 绘制原始数据series_air的折线图
series_air.plot()
# 绘制预测结果backtest的折线图
backtest.plot()
0%| | 0/57 [00:00<?, ?it/s]
MAPE = 11.88
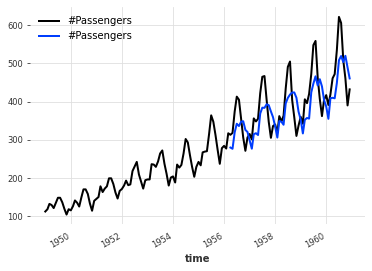
学习集成
正如预期的那样,在这种情况下,天真的集成并不能给出很好的结果(尽管在某些情况下可能会有!)
如果我们将集成视为一个监督回归问题,有时我们可以做得更好:给定一组预测(特征),找到一个模型来组合它们,以便在目标上最小化误差。
这就是RegressionEnsembleModel所做的。它接受三个参数:
forecasting_models是我们想要集成预测的一组预测模型。regression_train_n_points是用于拟合“集成回归”模型(即组合预测的内部模型)的时间步数。regression_model是一个可选的sklearn兼容回归模型或DartsRegressionModel,用于集成回归。如果未指定,将使用线性回归。使用sklearn模型很容易,但使用RegressionModel允许将个别预测的任意滞后作为回归模型的输入。
一旦这些元素就位,RegressionEnsembleModel可以像常规预测模型一样使用:
# 导入RegressionEnsembleModel模块
from darts.models import RegressionEnsembleModel
# 定义两个预测模型:NaiveDrift和NaiveSeasonal(12)
models = [NaiveDrift(), NaiveSeasonal(12)]
# 创建一个RegressionEnsembleModel对象,传入预测模型列表和回归训练点数
ensemble_model = RegressionEnsembleModel(
forecasting_models=models, regression_train_n_points=12
)
# 使用ensemble_model进行历史预测,传入时间序列数据series_air,起始点为0.6,预测时间范围为3,verbose参数为True表示打印详细信息
backtest = ensemble_model.historical_forecasts(
series_air, start=0.6, forecast_horizon=3, verbose=True
)
# 计算预测结果backtest与原始数据series_air的MAPE值,并打印结果
print("MAPE = %.2f" % (mape(backtest, series_air)))
# 绘制原始数据series_air的图像
series_air.plot()
# 绘制预测结果backtest的图像
backtest.plot()
0%| | 0/57 [00:00<?, ?it/s]
MAPE = 4.85
我们还可以检查用于加权线性组合中的两个内部模型的系数。
# Fit the ensemble model to the series_air data
ensemble_model.fit(series_air)
# Get the coefficients of the regression model used in the ensemble model
coefficients = ensemble_model.regression_model.model.coef_
array([0.01368849, 1.0980105 ], dtype=float32)
通过使用概率回归模型,RegressionEnsembleModel 还可以生成概率预测:
# 导入LinearRegressionModel模块
from darts.models import LinearRegressionModel
# 定义quantiles列表,用于指定分位数
quantiles = [0.25, 0.5, 0.75]
# 定义models列表,包含两个模型:NaiveDrift和NaiveSeasonal
models = [NaiveDrift(), NaiveSeasonal(12)]
# 创建LinearRegressionModel对象,用于线性回归
# 参数包括:quantiles(分位数)、lags_future_covariates(未来协变量的滞后值)、likelihood(似然函数类型)、fit_intercept(是否拟合截距)
regression_model = LinearRegressionModel(
quantiles=quantiles,
lags_future_covariates=[0],
likelihood="quantile",
fit_intercept=False,
)
# 创建RegressionEnsembleModel对象,用于回归集成模型
# 参数包括:forecasting_models(预测模型列表)、regression_train_n_points(回归训练数据点数)、regression_model(回归模型)
ensemble_model = RegressionEnsembleModel(
forecasting_models=models,
regression_train_n_points=12,
regression_model=regression_model,
)
# 使用ensemble_model进行历史预测
# 参数包括:series_air(时间序列数据)、start(开始时间索引)、forecast_horizon(预测时间范围)、num_samples(采样次数)、verbose(是否显示详细信息)
backtest = ensemble_model.historical_forecasts(
series_air, start=0.6, forecast_horizon=3, num_samples=500, verbose=True
)
# 打印MAPE(平均绝对百分比误差)
print("MAPE = %.2f" % (mape(backtest, series_air)))
# 绘制原始时间序列数据
series_air.plot()
# 绘制预测结果
backtest.plot()
0%| | 0/57 [00:00<?, ?it/s]
MAPE = 4.81

RegressionEnsembleModel使用stacking技术来训练和组合forecasting_models:每个模型都是独立训练的,然后使用它们的预测结果作为future_covariates来训练regression_model。
过滤模型
除了能够预测时间序列未来值的预测模型之外,Darts还包含了一些有用的过滤模型,可以对“样本内”时间序列的值分布进行建模。
拟合卡尔曼滤波器
KalmanFilter实现了卡尔曼滤波器。该实现依赖于nfoursid,因此可以提供一个包含转移矩阵、过程噪声协方差、观测噪声协方差等的nfoursid.kalman.Kalman对象。
还可以通过调用fit()使用N4SID系统辨识算法对卡尔曼滤波器进行系统辨识。
# 导入KalmanFilter模型类
from darts.models import KalmanFilter
# 创建一个KalmanFilter对象,设置状态向量的维度为3
kf = KalmanFilter(dim_x=3)
# 使用训练数据train_air_scaled对KalmanFilter模型进行训练
kf.fit(train_air_scaled)
# 使用训练好的KalmanFilter模型对训练数据train_air_scaled进行滤波,得到滤波后的时间序列数据
filtered_series = kf.filter(train_air_scaled, num_samples=100)
# 绘制原始训练数据的折线图
train_air_scaled.plot()
# 绘制滤波后的时间序列数据的折线图
filtered_series.plot()
用高斯过程推断缺失值
Darts还包含一个GaussianProcessFilter,可用于对序列进行概率建模:
# 导入所需的模块
from darts.models import GaussianProcessFilter
from sklearn.gaussian_process.kernels import RBF
# 创建一个带有空缺的时间序列
values = train_air_scaled.values() # 获取训练数据的值
values[20:22] = np.nan # 在索引20到22之间创建空缺
values[28:32] = np.nan # 在索引28到32之间创建空缺
values[55:59] = np.nan # 在索引55到59之间创建空缺
values[72:80] = np.nan # 在索引72到80之间创建空缺
series_holes = TimeSeries.from_times_and_values(train_air_scaled.time_index, values) # 创建带有空缺的时间序列
series_holes.plot() # 绘制带有空缺的时间序列
# 创建RBF核函数
kernel = RBF()
# 创建高斯过程滤波器对象
gpf = GaussianProcessFilter(kernel=kernel, alpha=0.1, normalize_y=True)
# 使用高斯过程滤波器对带有空缺的时间序列进行滤波
filtered_series = gpf.filter(series_holes, num_samples=100)
filtered_series.plot() # 绘制滤波后的时间序列
警告
那么,对于预测未来航空旅客数量,N-BEATS、指数平滑或基于牛奶产量训练的贝叶斯岭回归哪种方法最好呢?嗯,目前很难确切地说哪种方法最好。我们的时间序列很小,验证集甚至更小。在这种情况下,很容易将整个预测过程过度拟合到这么小的验证集上。特别是如果可用模型的数量及其自由度很高(例如深度学习模型),或者如果我们在单个测试集上尝试了许多模型(如在本笔记本中所做的那样),这一点尤为真实。
作为数据科学家,我们有责任了解我们的模型可以信任的程度。因此,在小数据集上,始终要以谨慎的态度看待结果,并在进行任何预测之前应用科学方法 😃 快乐建模!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!