【BERT】详解
BERT 简介
-
BERT 是谷歌在 2018 年时提出的一种基于 Transformer 的双向编码器的表示学习模型,它在多个 NLP 任务上刷新了记录。它利用了大量的无标注文本进行预训练,预训练任务有掩码语言模型和下一句预测,掩码语言模型指的是随机地替换文本中的一些词为掩码符号,并让它通过上下文信息来预测原来的词是什么。而下一句预测则是给定两个句子,然后让它预测第二个句子是不是第一个句子的下一句。
-
由于 BERT 中编码器的强大学习能力,特别是上下文信息学习能力,使得它在预训练任务时学习到了大量通用的语言知识,而这些知识可以应用在下游任务中来提高性能。下游任务指的是句子对关系、文本分类、阅读理解、序列标注、语言翻译等任务。同时它也很容易适应不同的下游任务,只需在模型后面加上下游任务所需的输出层,然后使用少量的有标注文本数据来进行微调,这样可以节省大量的时间和资源,而且可以不用针对不同的任务重新设计模型结构,并从头开始训练模型。
-
BERT 的缺点在于需要大量的算力和无标注文本数据来进行预训练,从而使得下游任务只能在 BERT 的模型权重上进行微调。同时由于掩码符号的存在,使得预训练时的数据和微调、预测时的数据格式的不一致。
BERT 文本数据的 Mask 机制的规则如下
- 随机选择一个样本中 15% 的词,然后有 80% 的概率替换为 [MASK] 符号,10 % 的概率替换为任意一个词,10% 的概率不替换。
Token 和 Token 化
-
Token
将文本分割成一个个的最小单元,最小单元可以是字、词或者字符。Token 的目的是为了让模型能够理解和表示文本的语义和结构,同时也可以避免出现未登录词和新词无法识别的问题。
-
Token 化
将文本分割成 Token,然后还会添加一些特殊的符号,例如 [CLS]、[SEP]、[PAD]、[UNK] 等,用来表示文本的开始、结束、填充、未知等含义。最后给每个 Token 分配一个唯一的 ID ,方便通过 Embedding 层来进行向量化。它的好处是可以减小词表的大小和解决未登录词和新词无法识别的问题,从而提高模型的泛化能力。
一般不同的模型会有不同的 Token 化,而且同一个模型在面对不同语言时,也会有不同的 Token 化。
-
BERT 的 WordPiece Token 化
WordPiece Token 化是 BERT 用来对文本进行 Token 化的过程。WordPiece Token 化是一个基于统计的 Token 化方法,它的基本思想是基于一个预先构建的词表,从最长的子词开始,逐步将单词分割成更小的子词,直到所有的子词都在词表中,或者达到最小的字符为止。
BERT 模型的结构
-
结构图
-
结构详解
BERT 的网络结构主要是由 输入层、编码器(Encoder)层、输出层组成,其中:-
输入层是由 Token Embedding、句子 Embedding、位置 Embedding 组成的,一般是将它们的值进行相加来作为输入层的输出。
-
Token Embedding 会先将句子进行 Token 化,也就是将文本分割成一个个的最小单元 Token,然后再给它分配一个唯一的 ID,再经过 Embedding 层映射后得到一个对应的向量。
-
句子(Sentence) Embedding 会分别给第一个句子的所有 Token 都分配 0 作为 ID,用来标记它们属于第一个句子。给第二个句子的所有 Token 都分配 1 作为 ID,用来标记它们属于第二个句子。
-
位置(Position) Embedding :因为 BERT 的注意力层是并行化计算的,因此无法知道每个 Token 对应的位置是什么,所以需要输入一个位置信息给模型。BERT 会给每一个位置分配一个可学习的固定长度为 768 的向量,这些向量作为模型的参数,可以在训练的过程中进行更新。BERT 的最大的位置为 512,也就是最长可以输入的句子长度为 512.
-
维度变化过程:
输入: [512]
中间: [512]
Token Embedding -> [512, 768] Sentence Embedding -> [512] ->(相加)-> [512, 768] Position Embedding -> [512, 768]输出:[512, 768]
-
-
编码器层 :编码器层由多个 Transformer 中的编码器堆叠组成,而每个编码器又包括了两个子层,分别是多头自注意力层和前馈神经网络层。每个子层后面都有残差连接和归一化层。它可以对输入的文本序列进行编码,学习序列中 Token 之间的关系,从而提取序列的上下文信息。
-
多头自注意力层 :由多个自注意力组成,自注意力指的是计算注意力时的张量都是同一个输入经过乘以不同的矩阵得到的。每一个自注意力都可以独立地学习上下文信息,从而可以学习到不同的上下文信息,使得多头自注意力层可以捕捉到更丰富的上下文信息。计算自注意力的时候,使用的是缩放点乘注意力公式:
S o f t m a x ( Q K T d k ) Softmax(\frac{QK^T}{\sqrt{d_k}}) Softmax(dk??QKT?)
其中,张量 Q Q Q 和 K K K 分别是输入 X 分别乘以矩阵 W q W_q Wq? 和 W k W_k Wk? 得到的。而 K T K^T KT 则是张量 K K K 的转置。而 d k d_k dk? 则是 Embedding 的维度。 S o f t m a x Softmax Softmax 则是将计算结果转换为概率,其公式为:
S o f t m a x ( x i ) = exp ? x i ∑ j = 1 N exp ? x j Softmax(x_i) = \frac{\exp^{x_i}}{\sum_{j=1}^{N}\exp^{x_j}} Softmax(xi?)=∑j=1N?expxj?expxi??而 Q K T {QK^T} QKT 除以 d k {\sqrt{d_k}} dk?? 的作用是可以将 Q K T {QK^T} QKT 的结果缩放到一定的范围,避免计算出来的结果太大或太小,从而在使用 S o f t m a x Softmax Softmax 计算概率时,出现概率太大和太小的问题,使得模型更容易学习。具体解释可以参看:在计算注意力时为什么要除以词向量维度的开方?
-
前馈神经网络层 :由两个全连接层组成,作用是进一步提高网络的参数量,使得编码器具备更强大的学习能力。它的激活函数为 ReLU,也就是 m a x ( x , 0 ) max(x, 0) max(x,0)
-
-
残差连接 :残差连接是将输入加到输出上作为新的输出,它的作用是让模型学习目标变成了学习输入和输出之间的差值,同时也减小了输入和输出之间的变化幅度,同时也可以避免梯度爆炸和梯度消失,这些作用都可以降低模型的学习难度。进而加速模型的收敛速度和减少训练时间,还能使得设计和训练更多的网络层数变得可能。
-
层归一化 ( LayerNorm ) :层归一化可以对输入和输出进行缩放,使每一层的输入和输出服从相同的分布,降低模型的学习难度,提高模型的收敛速度。
-
层归一化是按照最后一个维度来算的,也就是特征维度。这是因为在 BERT 模型中,每个输入的单词都会被表示为一个高维的向量,这个向量包含了单词的语义、语法、上下文等信息。如果我们按照其他的维度来进行归一化,比如句子维度或者批次维度,那么就会导致不同的单词之间的差异被消除,从而损失了单词的重要特征。而如果我们按照特征维度来进行归一化,那么就可以保证每个单词的特征向量都有相同的分布,从而提高模型的稳定性和泛化能力。
-
层归一化的公式是:
LayerNorm ( x ) = γ x ? μ σ 2 + ? + β \text{LayerNorm}(x) = \gamma \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta LayerNorm(x)=γσ2+??x?μ?+β
-
参数说明: x x x 是输入张量, γ \gamma γ 和 β \beta β 是缩放因子和偏移因子, μ \mu μ 和 σ 2 \sigma^2 σ2 是沿着最后一个维度计算的均值和方差, ? \epsilon ? 是一个很小的正数,用于防止除以 0。
-
计算过程:
假设有张量 a ,它的维度为 [batch_size, sequence_len, embedding_dim],以下面的例子为例来计算。
a = [
[
[1, 2, 3],
[4, 5, 6]
]
]因此 a 的实际维度为 [1, 2, 3]。那么根据层归一化的计算规则,按照特征维度 embedding_dim 来计算均值和方差,以 [4, 5, 6] 来计算的过程如下:
均值 = (4 + 5 + 6) / 3 = 5 方差 = ((4-5)^2 + (5-5)^2 + (6-5)^2) / 3 = 2/3
-
-
维度变化 :
-
多头自注意力层:
输入: [512, 768]
输出:[512, 768] -
前馈神经网络层:
输入: [512, 768]
中间: [2048, 768]
输出:[512, 768]
输入: [512, 768]
中间: [512, 768]
多头自注意力 -> [512, 768] 残差连接 -> [512, 768] 层归一化 -> [512, 768] 前馈神经网络: 第一个全连接层: 输入: [512, 768] 输出: [2048, 768] 第二个全连接层: 输入: [2048, 768] 输出: [512, 768] 残差连接 -> [512, 768] 层归一化 -> [512, 768]输出:[512, 768]
-
-
输出层 :输出层一般是根据下游任务来决定的,例如文本分类则是一个全连接层。
-
在计算注意力时为什么要除以词向量维度的开方?
-
在计算注意力时,要除以词向量维度的开方,是为了避免注意力分数过大或过小,导致梯度爆炸或消失的问题。这个方法是基于以下的数学原理:
假设我们有两个词向量 q \mathbf{q} q 和 k \mathbf{k} k,它们的维度是 d d d,它们的点积是 q ? k \mathbf{q} \cdot \mathbf{k} q?k,它们的范数是 ∥ q ∥ \|\mathbf{q}\| ∥q∥ 和 ∥ k ∥ \|\mathbf{k}\| ∥k∥。那么,我们可以得到以下的关系:
q ? k = ∥ q ∥ ∥ k ∥ cos ? θ \mathbf{q} \cdot \mathbf{k} = \|\mathbf{q}\| \|\mathbf{k}\| \cos \theta q?k=∥q∥∥k∥cosθ
其中, θ \theta θ 是 q \mathbf{q} q 和 k \mathbf{k} k 之间的夹角。如果我们假设 q \mathbf{q} q 和 k \mathbf{k} k 的每个元素都是从一个均值为 0,方差为 1 的正态分布中采样的随机变量,那么,我们可以得到以下的期望和方差:
E [ q ? k ] = 0 \mathbb{E}[\mathbf{q} \cdot \mathbf{k}] = 0 E[q?k]=0
V [ q ? k ] = d \mathbb{V}[\mathbf{q} \cdot \mathbf{k}] = d V[q?k]=d
这意味着,当 d d d 很大时, q ? k \mathbf{q} \cdot \mathbf{k} q?k 的值也会很大,从而导致注意力分数的 softmax 函数的梯度接近于 0,这会影响模型的学习效率。为了解决这个问题,我们可以将 q ? k \mathbf{q} \cdot \mathbf{k} q?k 除以 d \sqrt{d} d?,这样就可以使得注意力分数的期望和方差都接近于 1,从而保持梯度的稳定性。这就是为什么要除以词向量维度的开方的原因。
BERT 的损失函数
-
损失函数 是由两部分组成的,分别是掩码语言模型(MLM)的损失和下一句预测(NSP)的损失。这两个损失都是使用交叉熵(Cross Entropy)来计算的,但是具体的计算方式有所不同。而交叉熵的作用是用来衡量两个分布的差异程度,所以可以用来衡量真实值和预测值之间的差异程度。下面我将详细介绍 BERT 的损失函数的计算过程。
-
掩码语言模型(MLM) 的损失是指模型在预测被掩码的词时产生的损失。具体来说,对于输入的每个词,模型会输出一个概率分布,表示该词是词表中每个词的可能性。然后,模型会根据真实的词和预测的概率分布来计算交叉熵损失。由于只有 15% 的词被掩码,所以只有这些词的损失会被计算,其他词的损失会被忽略。最后,模型会将所有被掩码的词的损失求平均,得到 MLM 的损失。MLM 的损失可以用下面的公式表示:
L MLM = ? 1 N ∑ i = 1 N log ? P ( w i ∣ C i ) L_{\text{MLM}} = -\frac{1}{N}\sum_{i=1}^{N} \log P(w_i|C_i) LMLM?=?N1?i=1∑N?logP(wi?∣Ci?)
其中, N N N 是被掩码的词的数量, w i w_i wi? 是第 i i i 个被掩码的词, C i C_i Ci? 是第 i i i 个被掩码的词的上下文, P ( w i ∣ C i ) P(w_i|C_i) P(wi?∣Ci?) 是模型预测的概率分布。
-
下一句预测(NSP) 的损失是指模型在判断两个句子是否连续时产生的损失。具体来说,对于输入的每个句子对,模型会输出一个二元概率分布,表示该句子对是连续的(IsNext)或者不连续的(NotNext)的可能性。然后,模型会根据真实的标签和预测的概率分布来计算交叉熵损失。最后,模型会将所有句子对的损失求平均,得到 NSP 的损失。NSP 的损失可以用下面的公式表示:
L NSP = ? 1 M ∑ j = 1 M log ? P ( y j ∣ S j ) L_{\text{NSP}} = -\frac{1}{M}\sum_{j=1}^{M} \log P(y_j|S_j) LNSP?=?M1?j=1∑M?logP(yj?∣Sj?)
其中, M M M 是句子对的数量, y j y_j yj? 是第 j j j 个句子对的真实标签(0 表示 NotNext,1 表示 IsNext), S j S_j Sj? 是第 j j j 个句子对, P ( y j ∣ S j ) P(y_j|S_j) P(yj?∣Sj?) 是模型预测的概率分布。
BERT 的总损失是 MLM 的损失和 NSP 的损失的加权和,可以用下面的公式表示:
L BERT = L MLM + λ L NSP L_{\text{BERT}} = L_{\text{MLM}} + \lambda L_{\text{NSP}} LBERT?=LMLM?+λLNSP?
其中, λ \lambda λ 是一个超参数,用来控制两个损失的相对重要性。在原始的 BERT 论文1中, λ \lambda λ 被设置为 1,表示两个损失的权重相同。
BERT 的激活函数
-
ReLU :是一个计算简单的非线性函数,但是它可能会导致神经节点死亡和梯度消失,也就是当神经节点的输出为 0 之后,它之后的输出都将会一直是 0,无法再更新参数。它的公式为:
m a x ( x , 0 ) max(x, 0) max(x,0)
它的图像只在第一象限,且是一条 y=x 的直线。 -
GeLU :是一个基于高斯误差函数的激活函数,它的公式较为复杂,计算量也较大,但是它可以避免出现神经节点死亡和梯度消失的问题,而且它的非线性也比 ReLU 更好。它的公式为:
GELU ( x ) = x Φ ( x ) = x 1 2 [ 1 + erf ( x 2 ) ] \text{GELU}(x) = x \Phi(x) = x \frac{1}{2} \left[ 1 + \text{erf} \left( \frac{x}{\sqrt{2}} \right) \right] GELU(x)=xΦ(x)=x21?[1+erf(2?x?)]
其中, erf ( x ) \text{erf}(x) erf(x) 是高斯误差函数,它的定义是:
erf ( x ) = 2 π ∫ 0 x e ? t 2 d t \text{erf}(x) = \frac{2}{\sqrt{\pi}} \int_{0}^{x} e^{-t^2} dt erf(x)=π?2?∫0x?e?t2dt
GELU 激活函数的特点是,当 x x x 趋近于正无穷时,它的输出趋近于 x x x,当 x x x 趋近于负无穷时,它的输出趋近于 0,当 x x x 等于 0 时,它的输出等于 0。GELU 激活函数的图像如下:
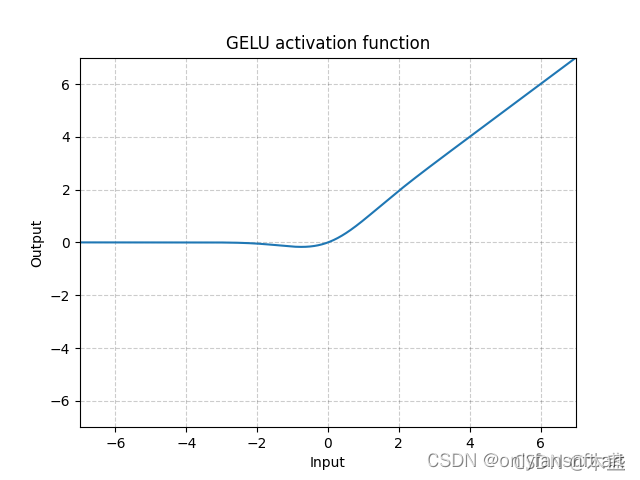
erf 函数的图像如下:
BERT 的激活函数的使用情况是:
- 在前馈神经网络中,BERT 使用了 GELU 激活函数,这是为了增加模型的非线性和复杂度,从而提高模型的表达能力。
- 在自注意力机制中,BERT 使用了 ReLU 激活函数,这是为了减少模型的计算量,从而提高模型的运行速度。
BERT 的优化器
-
Adam:Adam 是一个自适应的优化器,它可以利用参数的梯度的均值和方差来动态地调整每个参数的学习率,从而实现一个平滑和稳定的优化过程。
Adam 的公式是:
m t = β 1 m t ? 1 + ( 1 ? β 1 ) g t \mathbf{m}_t = \beta_1 \mathbf{m}_{t-1} + (1 - \beta_1) \mathbf{g}_t mt?=β1?mt?1?+(1?β1?)gt?
v t = β 2 v t ? 1 + ( 1 ? β 2 ) g t 2 \mathbf{v}_t = \beta_2 \mathbf{v}_{t-1} + (1 - \beta_2) \mathbf{g}_t^2 vt?=β2?vt?1?+(1?β2?)gt2?
m ^ t = m t 1 ? β 1 t \hat{\mathbf{m}}_t = \frac{\mathbf{m}_t}{1 - \beta_1^t} m^t?=1?β1t?mt??
v ^ t = v t 1 ? β 2 t \hat{\mathbf{v}}_t = \frac{\mathbf{v}_t}{1 - \beta_2^t} v^t?=1?β2t?vt??
θ t + 1 = θ t ? α m ^ t v ^ t + ? \mathbf{\theta}_{t+1} = \mathbf{\theta}_t - \alpha \frac{\hat{\mathbf{m}}_t}{\sqrt{\hat{\mathbf{v}}_t} + \epsilon} θt+1?=θt??αv^t??+?m^t??
其中, g t \mathbf{g}_t gt? 是第 t t t 步的梯度, m t \mathbf{m}_t mt? 和 v t \mathbf{v}_t vt? 是第 t t t 步的一阶矩和二阶矩的估计, m ^ t \hat{\mathbf{m}}_t m^t? 和 v ^ t \hat{\mathbf{v}}_t v^t? 是第 t t t 步的一阶矩和二阶矩的偏差修正, θ t \mathbf{\theta}_t θt? 是第 t t t 步的参数, α \alpha α 是学习率, β 1 \beta_1 β1? 和 β 2 \beta_2 β2? 是一阶矩和二阶矩的衰减率, ? \epsilon ? 是一个很小的常数,用于防止除以零的错误。
Adam 优化器的特点是,它可以自适应地调整每个参数的学习率,从而加速模型的收敛,同时也可以避免梯度的爆炸或消失的问题。Adam 优化器的优点是,它可以适用于各种类型的模型和数据,它也可以很容易地实现和使用。Adam 优化器的缺点是,它需要存储每个参数的一阶矩和二阶矩的估计,这会占用较多的内存空间,它也可能会导致一些参数的学习率过低,从而影响模型的性能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 拿出最少数目的魔法豆
- 数据库原理与应用——简答题练习(数据管理技术发展、数据库主要特征、数据模型、关系模型、实体性之间的关系、DBMS的功能、相关术语解释、数据库系统)
- 【VS】如何把wpf项目打包成exe文件
- QML —— CheckBox示例,嵌入TabView页中(附完整源码)
- 俄乌冲突波及,现代汽车被迫卖厂 | 百能云芯
- jmeter之循环遍历器:多参数组合遍历
- 华为HUAWEI笔记本MateBook 16s 2023款 i7 集显(CREFG-16)原装出厂Windows11系统22H2
- 第二章 操作系统用户界面【操作系统】
- ValueError: source code string cannot contain null bytes
- 博客的简介