爬取糖豆视频
爬虫案例积累,以爬取糖豆视频为例:
爬取视频类型的数据一般步骤:
1.点击media,刷新,播放一个视频,会刷新一个包,点击发现是播放视频的包,
2.复制这个包url中的关键字,在搜索框中进行搜索,看有哪些包有关键字。
3.搜索后找到有play_url的包
4.看这个包的url,观察有什么规律
5.以糖豆视频为例,发现这个包的url有参数vid
6.查找参数在哪个位置
7.在xhr?动态加载中找到包,发现其中json数据中有vid的数据。
8.访问xhr?中的包获取vid数据,利用获取到的vid数据拼凑含有play_url的包的链接,访问这个链接,获取play_url
9.多页爬取,观察xhr?包的链接有什么规律,发现参数为页数,即可多页爬取
注意:访问视频play_url时,必须headers中加上防盗链,否则只会爬取五秒中视频
总结:这一案例与爬取好看视频最大的区别在于,它的play_url并不在xhr下的包中,因此找到比较困难。我在爬三个视频后就被禁止访问了。
代码呈现: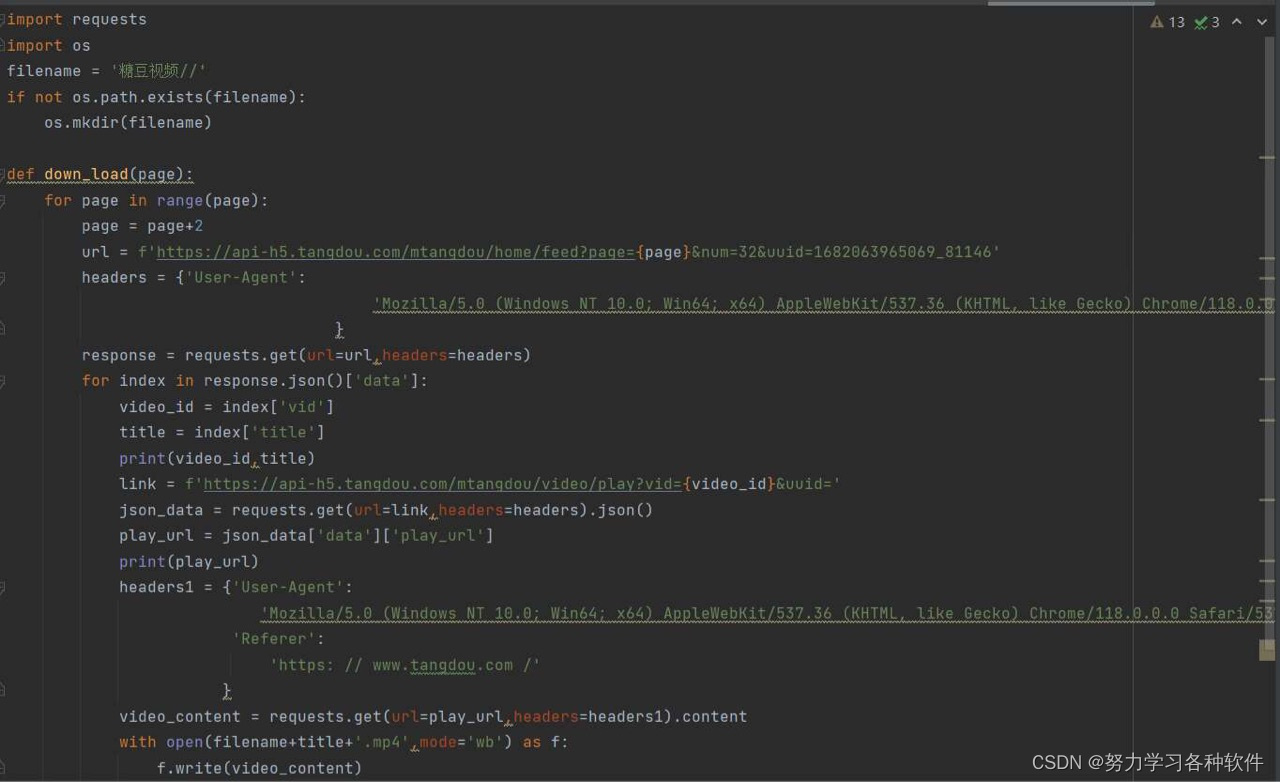
代码详情:
import requests
import os
filename = '糖豆视频//'
if not os.path.exists(filename):
? ? os.mkdir(filename)
def down_load(page):
? ? for page in range(page):
? ? ? ? page = page+2
? ? ? ? url = f'https://api-h5.tangdou.com/mtangdou/home/feed?page={page}&num=32&uuid=1682063965069_81146'
? ? ? ? headers = {'User-Agent':
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?}
? ? ? ? response = requests.get(url=url,headers=headers)
? ? ? ? for index in response.json()['data']:
? ? ? ? ? ? video_id = index['vid']
? ? ? ? ? ? title = index['title']
? ? ? ? ? ? print(video_id,title)
? ? ? ? ? ? link = f'https://api-h5.tangdou.com/mtangdou/video/play?vid={video_id}&uuid='
? ? ? ? ? ? json_data = requests.get(url=link,headers=headers).json()
? ? ? ? ? ? play_url = json_data['data']['play_url']
? ? ? ? ? ? print(play_url)
? ? ? ? ? ? headers1 = {'User-Agent':
? ? ? ? ? ? ? ? ? ? ? ? ? ?'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
? ? ? ? ? ? ? ? ? ? ? ? 'Referer':
? ? ? ? ? ? ? ? ? ? ? ? ? ? 'https: // www.tangdou.com /'
? ? ? ? ? ? ? ? ? ? ? ?}
? ? ? ? ? ? video_content = requests.get(url=play_url,headers=headers1).content
? ? ? ? ? ? with open(filename+title+'.mp4',mode='wb') as f:
? ? ? ? ? ? ? ? f.write(video_content)
结果展现:
被禁止访问了: ?
?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 时序预测 | Matlab实现SSA-CNN-GRU麻雀算法优化卷积门控循环单元时间序列预测
- 深度学习”和“多层神经网络”的区别
- C#销售管理系统源码
- 每日好题-A+B problem 高精度的加法和进位计算
- 新型招聘系统(JSP+java+springmvc+mysql+MyBatis)
- pytest自动化测试执行环境切换的两种解决方案
- 解析正交镜像滤波器组
- 研究生英语系列综合教程上
- File.mkdir与File.mkdirs区别&String.replace方法返回值
- java基于SSM框架的宿舍管理系统的设计与实现论文