最快速度与最简代码搭建卷积神经网络,并快速训练模型,每日坚持手撕默写代码
大家好,我是微学AI,今天给大家介绍一下最快速度与最简代码搭建卷积神经网络,并快速训练模型,每日坚持手撕默写代码。随着人工智能的快速发展,去年有强大的大模型ChatGPT横空出世,国内的大模型也紧追其后的发布,主要包括:文心一言、ChatGLM、通义千问、百川大模型等,他们可以帮助我们编写代码,但是在实际中,高度依赖于大模型则会缺乏思考的能力,缺乏编写代码的感觉,在别人问的时候,缺乏熟练度。坚持多写代码反复进行,可以提高熟练程度,提高开发效率,锻炼记忆力。本文尝试利用最短的代码实现数据集、卷积神经网络的搭建、模型的训练,模型的评估的整个流程代码,快速熟练手打出来。
一、坚持手撕默写代码的意义:
关于坚持手撕默写代码的意义,我总结一下几点:
1.提高熟练程度:
通过手撕默写代码,我能够更加深入地理解代码的逻辑和工作原理,加深对代码的理解,并提高对编程语言和算法的熟练程度。
2.培养思维逻辑与开发效率:
手撕默写代码需要你对算法和语法有较为全面的理解,同时需要你将思路转化为具体的代码实现。这种过程能够培养我的思维逻辑能力,提高问题解决能力,提高模型库包的快速调用与开发效率。
3.探索学习新知识:
通过手撕默写代码,你会遇到各种问题和挑战,需要不断查阅资料、学习和探索,从中获得新的知识和技能。
4.锻炼记忆力:
反复手写代码可以加强对语法和细节的记忆,提高记忆力和代码的熟悉程度。
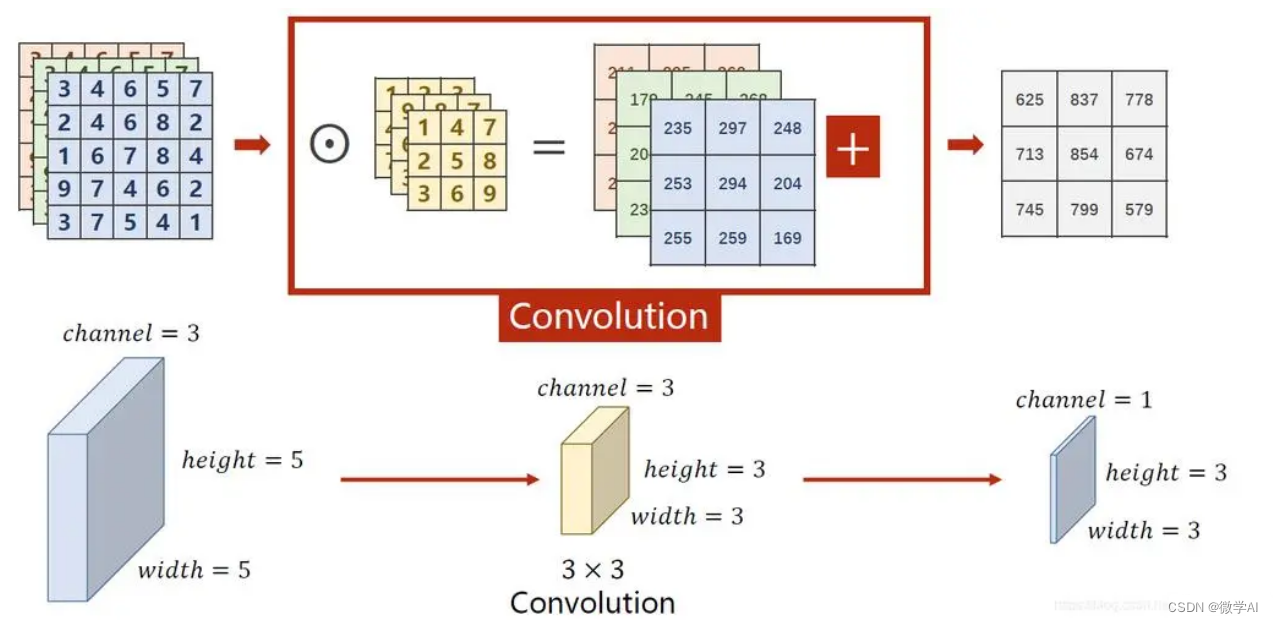
二、卷积神经网络的快速搭建
关于pytorch框架,我们经常用到的第三方库有torch,torch.nn,torchvision,这些我们要烂熟于心。
torch:torch是PyTorch的核心库,提供了张量操作、数学函数、自动求导等功能。它是一个多维数组的库,类似于NumPy,但具有GPU加速和用于深度学习的其他扩展功能。
torch.nn:torch.nn模块是PyTorch中用于构建神经网络模型的模块。它提供了各种层(如全连接层、卷积层、循环层等)和损失函数(如交叉熵损失、均方误差损失等),以及优化算法(如随机梯度下降等)的实现。
torchvision.transforms:torchvision.transforms模块提供了一系列用于图像预处理和数据增强的函数。通过该模块,可以对输入图像进行常见的操作,如裁剪、缩放、旋转、归一化等,以便更好地适应模型的输入要求。
torch.utils.data.DataLoader:torch.utils.data.DataLoader是PyTorch中用于加载和迭代数据集的工具。它可以将数据集封装成可迭代的数据加载器,支持批量加载、多线程加载和数据打乱等功能。
torchvision.datasets.FakeData:torchvision.datasets.FakeData是用于生成虚拟数据集的类。它可以根据指定的数据样式和大小生成虚拟的图像数据集,用于模型调试和测试。本文利用FakeData进行快速训练
第三方库的导入与卷积神经网络搭建:
import torch
import torch.nn as nn
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import FakeData
class CNNnet(nn.Module):
def __init__(self):
super(CNNnet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,32,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32,64,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2))
self.linear = nn.Linear(int((32/4)*(32/4)*64),2)
def forward(self, x):
x = self.conv1(x)
x =x.view(x.size(0),-1)
x = self.linear(x)
return x
在上述的CNNnet网络模型中,nn.Linear(int((32/4)*(32/4)64),2)中的int((32/4)(32/4)*64)是指线性层的输入特征数。在该模型中,线性层的输入来自于卷积层输出的特征图,经过reshape处理后得到的一维向量。具体地,假设输入图像的大小为 W x H,卷积核大小为 k x k,卷积层的输出通道数为 n,则经过两次最大池化后,卷积层的输出特征图的大小为 (W/4) x (H/4) x n。因此,线性层的输入特征数 num = (W/4) x (H/4) x n。
我们这里设置输入图像的大小为 32x32,卷积核大小为 3x3,卷积层的输出通道数为 64,则经过两次最大池化后,卷积层的输出特征图的大小为 (32/4)x(32/4)x64=8x8x64=4096。因此,线性层的输入特征数 num=4096。
三、模型训练代码快速编写
model = CNNnet() # 实例化模型
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 建立Adam优化器
dataset = FakeData(size=1000,image_size=(3,32,32),num_classes=2,transform=transforms.ToTensor())
train_loader=DataLoader(dataset,batch_size=32,shuffle=True)
for epoch in range(25):
running_loss = 0.0
correct = 0
total = 0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
if (i + 1) % 10 == 0:
print('[Epoch %d, Batch %5d] Loss: %.3f | Accuracy: %.3f%%' %
(epoch + 1, i + 1, running_loss / 5, 100 * correct / total))
running_loss = 0.0
correct = 0
total = 0
四、模型评估代码快速编写
# 模型评估
model.eval()
total = 0
correct = 0
with torch.no_grad():
for data in train_loader:
inputs, labels = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on the training dataset: %.3f%%' % (100 * correct / total))
上面的代码将模型设置为评估模式(model.eval()),然后使用torch.no_grad()上下文管理器来禁用梯度计算,以提高运行效率。在遍历训练集数据进行预测时,统计正确预测的样本数,并计算准确率。
该评估代码是在训练集上进行评估,如果需要在测试集上评估模型,需要使用测试集的数据进行评估。这里没有做扩展。
运行结果:
...
[Epoch 18, Batch 10] Loss: 0.292 | Accuracy: 99.062%
[Epoch 18, Batch 20] Loss: 0.264 | Accuracy: 100.000%
[Epoch 18, Batch 30] Loss: 0.245 | Accuracy: 100.000%
[Epoch 19, Batch 10] Loss: 0.208 | Accuracy: 100.000%
[Epoch 19, Batch 20] Loss: 0.218 | Accuracy: 100.000%
[Epoch 19, Batch 30] Loss: 0.215 | Accuracy: 99.688%
[Epoch 20, Batch 10] Loss: 0.201 | Accuracy: 100.000%
[Epoch 20, Batch 20] Loss: 0.183 | Accuracy: 100.000%
[Epoch 20, Batch 30] Loss: 0.165 | Accuracy: 100.000%
[Epoch 21, Batch 10] Loss: 0.136 | Accuracy: 100.000%
[Epoch 21, Batch 20] Loss: 0.137 | Accuracy: 100.000%
[Epoch 21, Batch 30] Loss: 0.119 | Accuracy: 100.000%
[Epoch 22, Batch 10] Loss: 0.108 | Accuracy: 100.000%
[Epoch 22, Batch 20] Loss: 0.102 | Accuracy: 100.000%
[Epoch 22, Batch 30] Loss: 0.098 | Accuracy: 100.000%
[Epoch 23, Batch 10] Loss: 0.087 | Accuracy: 100.000%
[Epoch 23, Batch 20] Loss: 0.083 | Accuracy: 100.000%
[Epoch 23, Batch 30] Loss: 0.086 | Accuracy: 100.000%
[Epoch 24, Batch 10] Loss: 0.072 | Accuracy: 100.000%
[Epoch 24, Batch 20] Loss: 0.075 | Accuracy: 100.000%
[Epoch 24, Batch 30] Loss: 0.075 | Accuracy: 100.000%
[Epoch 25, Batch 10] Loss: 0.068 | Accuracy: 100.000%
[Epoch 25, Batch 20] Loss: 0.060 | Accuracy: 100.000%
[Epoch 25, Batch 30] Loss: 0.065 | Accuracy: 100.000%
Accuracy on the training dataset: 100.000%
本文只是将模型训练的过程跑通,手打快速训练卷积神经网络网络的过程。实际应用场景中还需要将数据集分为训练集、验证集、测试集,详细的过程可以看我的往期文章。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux入门攻坚——9、Linux程序包管理-1
- golang协程goroutine教程
- Android studio 之 适配器
- 前端:html+css+js实现CSDN首页
- IntelliJ IDEA 常用快捷键一览表(通用型,提高编写速度,类结构、查找和查看源码,替换与关闭,调整格式)
- 深入了解鸿鹄工程项目管理系统源码:功能清单与项目模块的深度解析
- 【Web】forward 和 redirect 的区别
- mybatis.interceptor.exception.SqLValidateException:Ilegal SQL::......
- MybatisPlus快速入门
- js 中 复杂json 组装 实例通用模式