SAP HANA性能优化(4)——过滤相关优化
SELECT……WHERE
-
尽可能早地进行过滤,这里的过滤可以是where条件限制也可以是参数,但是要避免在计算列上使用过滤器
作为查询简化的一部分,优化器将所有投影列拉升到树的顶部,应用简化措施,包括删除不必要的列,然后尽可能地向下推送过滤器,大多数情况下推送到表层。
开发模型的时候,会有许多过滤条件,也就是大家理解WHERE条件的内容,大家要尽量下沉过滤条件,能在底表过滤的都在底表过滤,减少上层运算的数据量。
另外在各种其他优化方式不生效的情况下,使用参数也是一个优化的方法。如下图,增加了开始时间和结束时间,使用的时候加上时间参数限制,不再是全部数据取出来,可以显著地提升效率。
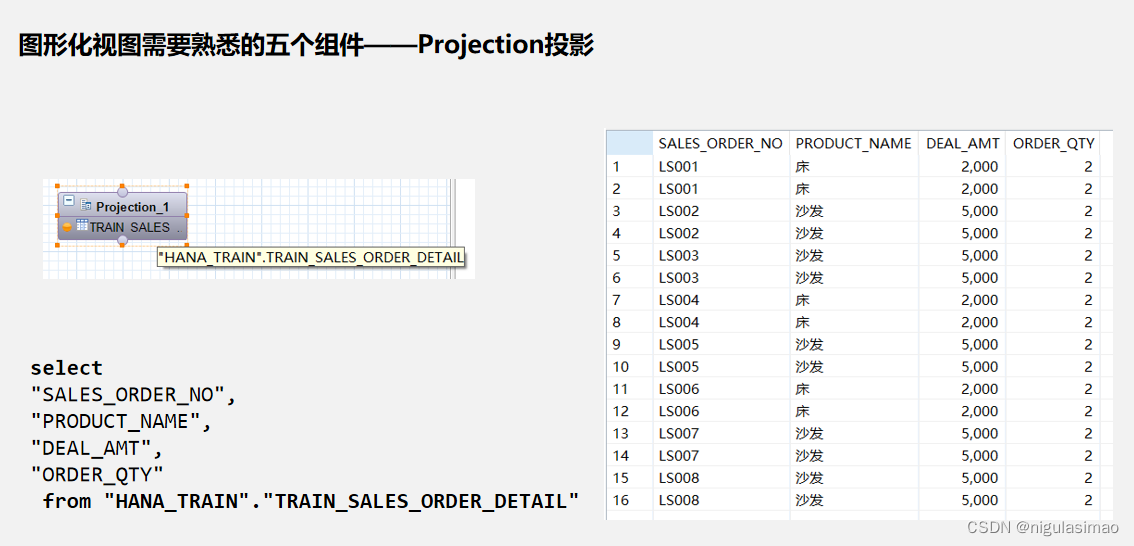
在搜素的时候,应选择特定的字段,避免使用SELECT *
这个与HANA三大特性之一,列式存储息息相关。
列式存储,顾名思义,只需要访问必需的列,极大减少不必要的数据访问。因此我们在进行数据开发的时候,SELECT 后边的字段要非常明确,避免整表查询造成性能消耗。
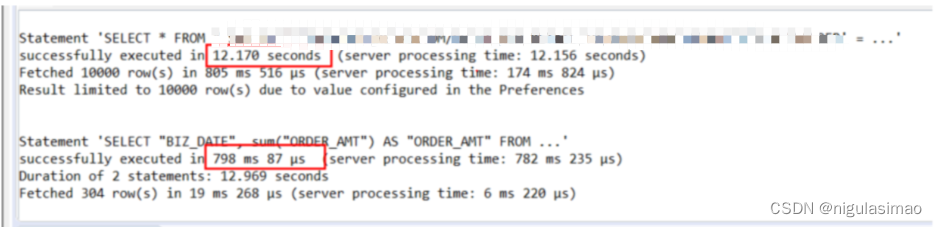
从跑的结果可以看出,同样是跑同一个模型的1-10月份数据,SELECT * ?和SELECT 特定字段时间上是相差很大的。
- 避免查询中的隐式转换
即使你没有显式编写类型转换操作,系统也可以隐式地生成类型转换。例如,如果在VARCHAR值和DATE值之间进行比较,系统将生成一个将VARCHAR值转换为DATE值的隐式类型转换操作。隐式类型转换是从较低优先级类型到较高优先级类型的转换。如果经常通过查询比较两个列,则最好确保它们从一开始就具有相同的数据类型。
避免隐式类型转换的一种方法是在查询的连接部分使用显式类型转换。
例如,如果一个VARCHAR列与一个DATE值进行比较,并且你知道将DATE值转换为VARCHAR值会得到你想要的结果,建议将DATE值转换为VARCHAR值。如果VARCHAR列只包含形式为'YYYYMMDD'的日期值,则可以与从形式为'YYYYMMDD'的DATE值生成的字符串进行比较。
| 原始代码: SELECT * FROM T WHERE date_string < CURRENT_DATE; | 推荐代码: SELECT * FROM T WHERE date_string < TO_VARCHAR(CURRENT_DATE, 'YYYYMMDD'); |
在HANA中,如果可能,请使用BINARY(<n>)或NVARCHAR(<n<)数据类型,而不是BLOB或NCLOB(即,当最大<n>5000足够大时,可以存储在列或值中的任何数据)。与BLOB或NCLOB值相比,SAP HANA数据库可以更有效地处理BINARY(<n>)或NVARCHAR(<n<)值。
- 重排连接条件
引用条件中的某些情况(例如,"A1" - "B1" = 1)可能无法高效处理,并且可能导致在生成的查询计划中CROSS PRODUCT上方出现低效的后连接筛选操作符。
通过将条件重新排列,可以避免潜在的运行时错误,并改进查询性能。但请记住,在重新排列时要小心潜在的运行时错误,并根据实际情况进行测试和验证。
| 原始代码: SELECT * FROM TA, TB WHERE a1 - b1 = 1; | 推荐代码: SELECT * FROM TA, TB WHERE a1 = b1 + 1; |
| 原始代码: SELECT * FROM TA, TB WHERE DAYS_BETWEEN(a1, b1) = -1; | 推荐代码: |
- 使用 exists代替in
与NOT EXISTS相比,NOT IN的处理成本要高得多。如果可能的话,建议使用NOT EXISTS代替NOT IN。
一般来说,NOT IN需要先处理整个子查询,然后在根据提供的条件匹配条目之前再处理整体查询。然而,使用NOT EXISTS时,在检查提供的条件时会返回true或false,因此除非子查询结果非常小,否则使用NOT EXISTS比使用NOT IN要快得多(EXISTS/IN也是如此)。
请注意,在转换为NOT EXISTS时,需要将子查询中的列与外部查询中的列进行正确的比较。这样,可以避免NOT EXISTS中的任何列可能为空值时引发的错误结果。
总之,如果可能的话,请尽量使用NOT EXISTS来替代NOT IN,以提高查询性能。
| 原始代码: SELECT * FROM T WHERE a NOT IN (SELECT b FROM S); | 推荐代码: SELECT * FROM T WHERE NOT EXISTS (SELECT * FROM S WHERE S.b = T.a); |
- 避免分开使用exists
当一个EXISTS或NOT EXISTS通过OR连接时,它在内部被映射为左外连接。由于左外连接的处理通常比内连接性能更差,建议在可能的情况下避免使用这些分离的EXISTS条件,下边的两种方法,其中第二种方法是在嵌套查询中使用UNION ALL。如果嵌套查询结果非常小,则可以提高查询执行效率。
这里的例子是exists,in也同理。
| 原始代码: SELECT * FROM T WHERE EXISTS (SELECT * FROM S WHERE S.a = T.a AND S.b = 1) OR EXISTS (SELECT * FROM S WHERE S.a = T.a AND S.b = 2); | 推荐代码1: SELECT * FROM T WHERE EXISTS (SELECT * FROM S WHERE S.a = T.a AND (S.b = 1 OR S.b = 2)); 推荐代码2: SELECT * FROM T WHERE EXISTS ((SELECT * FROM S WHERE S.a = T.a AND S.b = 1) UNION ALL (SELECT * FROM S WHERE S.a = T.a AND S.b = 2)); |
- 忽略SQL优化器的显示指定
SQL优化器通常根据成本(基于成本的优化器)来确定访问路径(例如,索引搜索与表扫描)。
如果你在评估之后,发现这并不是最优的方案,可以通过在查询中显式指定提示来覆盖SQL优化器的选择,以强制执行特定的访问路径。
SELECT EXTRACT(MONTH FROM CURRENT_DATE) FROM DUMMY
WITH HINT(NO_USE_OLAP_PLAN) -- 指导优化器优先选择使用OLAP引擎。
HANA中有非常多的强制指定类型,详见官方文档:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 洛谷刷题的第....n+1天
- 基于TI TPSXX系列 Buck电路应用计算-外围器件详细计算过程
- 最新Redis7哨兵模式(保姆级教学)
- Matrix 使用
- 视频转换成文字,原来转换的方法这么简单!
- C#进行Web API开发时,遇到的常见问题
- linux系统安全及应用
- 【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
- Proxy可以监听基本数据类型吗?
- Linux基础第一章:基础知识和基础命令(2)