C++线程池的原理(画图)及简单实现+例子(加深理解)
1.为什么线程池会出现,解决什么问题?
C++线程池(ThreadPool)的出现主要是为了解决以下几个问题:
1.性能:创建和销毁线程都是相对昂贵的操作,特别是在高并发场景下,频繁地创建和销毁线程会极大地降低程序的性能。通过线程池预先创建一定数量的线程并保存在内存中,可以避免频繁地创建和销毁线程,从而提高程序的性能。
2.资源管理:线程是操作系统级别的资源,如果线程数量过多,可能会导致系统资源的过度消耗,甚至可能导致系统崩溃。通过线程池,可以控制同时运行的线程数量,避免资源过度消耗。
3.任务调度:线程池可以更方便地进行任务的调度。通过线程池,可以将任务分配给不同的线程执行,实现并行处理,提高程序的执行效率。
4.简化编程:使用线程池可以简化多线程编程的复杂性。程序员只需要将任务提交给线程池,而不需要关心线程的创建、管理和销毁等细节,降低了多线程编程的难度。
因此,C++线程池的出现是为了解决在高并发场景下创建和销毁线程的开销问题,提高程序的性能和并发处理能力,简化多线程编程的复杂性
................
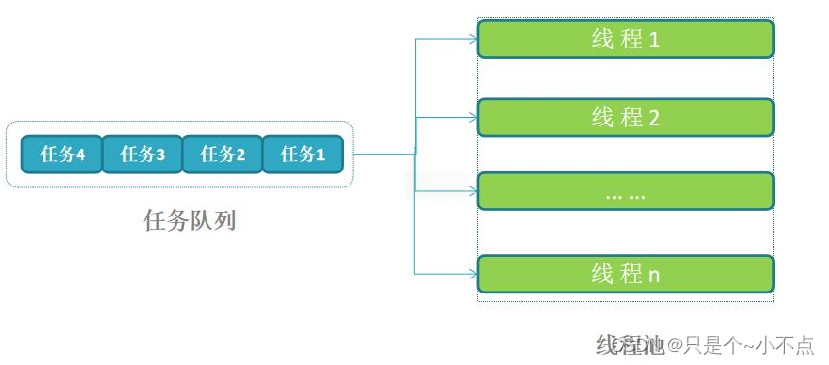
2.简单解释下原理
线程池初始化时,初始化线程,也可以生成一个管理线程,来管理工作线线程数量。
如果当前任务队列一直有很多任务时,说明线程繁忙,处理不过来,可以根据设置的最大工作线程数来新增线程,提高并发处理能力,提高工作效率。
如果当前任务队列一直为空,说明当前时间段,没有任务或者很少的任务要处理,可以销毁多余的空闲线程,避免资源浪费。
如下图所示:

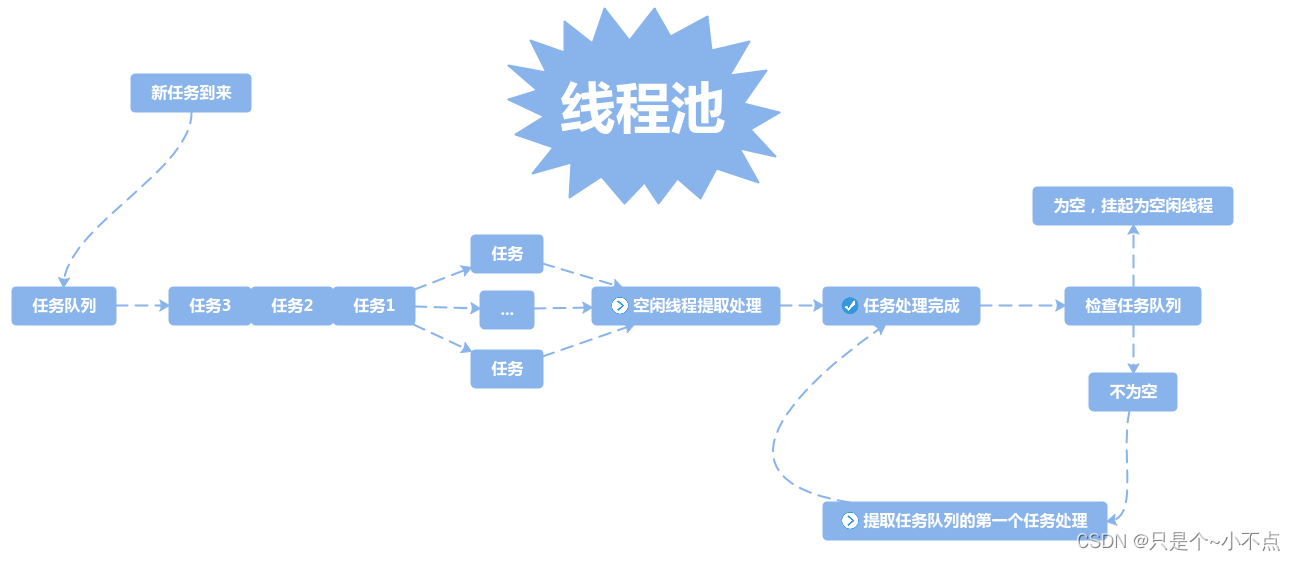
初始化线程池后,有新任务到来后,线程池处理流程为:
将新任务投递到线程队列中->发送信号通知线程处理->空闲线程处理->处理完成检查任务队列是否还有任务->有任务则提取任务处理,没有任务就挂起为空闲线程,避免占用系统资源
如下图所示:
3. 实现
用一个Task类表示任务,成员函数如下
void (*hander)(void* arg); // 要执行任务的函数指针
void *arg; //可执行任务的参数
std::string name; //任务名
static int taskNum; //任务数量
// task.h
class Task
{
public:
Task();
Task(std::string name);
Task(void *arg);
void createTask(void (*hander)(void* arg), void*arg);
~Task();
void (*hander)(void* arg);
void *arg;
//Task* next;
std::string name;
static int taskNum;
};
// task.cpp
int Task::taskNum = 0;
Task::Task()
{
next = nullptr;
this->arg = nullptr;
taskNum++;
}
Task::Task(std::string name)
{
this->name = name;
taskNum++;
}
Task::Task(void *arg)
{
next = nullptr;
this->arg = arg;
taskNum++;
}
void Task::createTask(void (*hander)(void *), void *arg)
{
this->hander = hander;
this->arg = arg;
}
Task::~Task()
{
if(--taskNum==0) {
qDebug()<<"所有任务执行完成, 完成时间:"<<QDateTime::currentDateTime().toString("yyyy-MM-dd hh:mm:ss:zzz");
free(this->arg);
}
}自定义线程池如下:
typedef struct {
Task* first; //任务队列头
Task** last; //任务队列尾部
}threadPool_Queue;
threadPool_Queue 这个结构提用来表示任务队列,对指针特性用的很巧妙,但是不好理解,我就不讲这个了,我在代码中注释掉了,感兴趣的可以把注释放开,理解下。现在用stl中的queue更好理解,用到如下成员函数,由于为了简便理解线程池,我就把管理线程去掉了
std::queue<Task*> taskQueue; // 任务队列
std::condition_variable cond; / /条件变量,用于唤醒线程和挂起线程
std::mutex mutexPool; ????????// 线程互斥锁,保护线程安全
unsigned long m_maxNum; ??????// 线程最大数量
unsigned long m_minNum; ??????// 线程最小数量
int busyNum; ????????????????// 线程是否繁忙,用于管理线程
int aliveNum; ??????????????// 活跃线程数,即繁忙线程数
std::vector<std::thread> m_threads;// 线程队列
用到两个函数:
void taskPost(Task* task); //投递任务到任务队列中 ? static void worker(void* arg);//工作线程函数,用来循环不断的处理任务
代码如下所示:
// threadpool.h
#include <thread>
#include <vector>
#include <condition_variable>
#include <mutex>
#include <queue>
#include "task.h"
typedef struct {
Task* first;
Task** last;
}threadPool_Queue;
class ThreadPool
{
public:
ThreadPool(unsigned long maxNum);
~ThreadPool();
void taskPost(Task* task);
static void worker(void* arg);
private:
//threadPool_Queue queue;
std::queue<Task*> taskQueue;
std::condition_variable cond;
std::mutex mutexPool;
unsigned long m_maxNum;
unsigned long m_minNum;
int busyNum;
int aliveNum;
std::vector<std::thread> m_threads;
};
// threadpool.cpp
#include "threadpool.h"
#include "task.h"
#include <QDebug>
#include <iostream>
#include <QDateTime>
ThreadPool::ThreadPool(unsigned long maxNum)
{
m_maxNum = maxNum;
m_minNum = 1;
busyNum = 0;
aliveNum = 0;
//queue.first = nullptr;
//queue.last = &queue.first;
m_threads.resize(maxNum);
for(unsigned long i=0; i<maxNum;i++) {
m_threads[i] = std::thread(worker, this);
}
}
ThreadPool::~ThreadPool()
{
//唤醒阻塞的工作线程
cond.notify_all();
for (unsigned long i = 0; i < m_maxNum; ++i)
{
if (m_threads[i].joinable()) {
m_threads[i].join();
}
}
}
void ThreadPool::taskPost(Task *task)
{
std::unique_lock<std::mutex> lk(mutexPool);
//task->next = nullptr;
//*queue.last = task;
//queue.last = &task->next;
taskQueue.push(task);
// 通知线程处理
cond.notify_one();
lk.unlock();
}
void ThreadPool::worker(void *arg)
{
ThreadPool* pool = static_cast<ThreadPool*>(arg);
while (1) {
// unique_lock在构造时或者构造后(std::defer_lock)获取锁
std::unique_lock<std::mutex> lk(pool->mutexPool);
//while (!pool->queue.first) { //没有任务时,线程挂起
while (pool->taskQueue.empty()) { //没有任务时,线程挂起
//挂起,直到收到主线程的事件通知
pool->cond.wait(lk);
}
/*Task* task = pool->queue.first;
pool->queue.first = task->next;
lk.unlock();
if(pool->queue.first==nullptr ) {
pool->queue.last=&pool->queue.first;
}*/
Task* task = pool->taskQueue.front();
pool->taskQueue.pop();//从队列中移除
// 当访问完线程池队列时,线程池解锁
lk.unlock();
qDebug()<<"执行任务任务开始时间:"<<QDateTime::currentDateTime().toString("yyyy-MM-dd hh:mm:ss:zzz");
task->hander(task->arg);
std::cout << task->name << " finish!" <<std::endl;
delete task;
}
}
4. 单线程与线程池的对比结果
然后在写个测试的例子,突出线程池的并发能力
先定义一个任务函数,用来计算累加值,计算1+2+3+...+value的值,相当于一个任务
void executeTask_1(void* size) {
int* s = static_cast<int*>(size);
int value = *s;
long sum=0;
for(int i=0; i<value; i++) {
sum+=i;
}
std::cout << "计算完成,sum= " <<sum << std::endl;
}然后在main函数中,执行四次这个任务,用一般流程下(即单线程)执行四次这个任务需要多长时间,和在线程池中的执行时间进行对比,我在线程池中初始化了四个线程,用于并发处理任务
int main()
{
long* n = new long;
*n = 1000000000;
// 获取当前时间
auto start = std::chrono::system_clock::now();
executeTask_1(n);
executeTask_1(n);
executeTask_1(n);
executeTask_1(n);
// 获取操作完成后的时间
auto end = std::chrono::system_clock::now();
// 计算时间差
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
// 输出时间差(以毫秒为单位)
std::cout << "一般流程执行所有任务所需时间: " << duration.count() << "毫秒" << std::endl;
ThreadPool pool(4);
Task* t1 = new Task("Task1");
t1->createTask(executeTask_1, n);
Task* t2 = new Task("Task2");
t2->createTask(executeTask_1, n);
Task* t3 = new Task("Task3");
t3->createTask(executeTask_1, n);
Task* t4 = new Task("Task4");
t4->createTask(executeTask_1, n);
// 获取当前时间
qDebug()<<"线程池执行任务开始时间:"<<QDateTime::currentDateTime().toString("yyyy-MM-dd hh:mm:ss:zzz");
pool.taskPost(t1);
pool.taskPost(t2);
pool.taskPost(t3);
pool.taskPost(t4);
return 0;
}结果如下所示:

可以看出,计算四次从1-十亿累加值的任务一般流程(即单线程)需要7.816秒,平均每一次:1.954秒
而用线程池执行的任务是同时开始的(在毫秒误差内),所有任务执行完成,用了41.131-39.117=2.014秒
数据对比可以看出,使用4个线程并发处理,和一个线程处理的时间差不多,说明线程池的并发处理是没有问题的
我把线程池线程数初始化为2,也符合预判

5. 总结
可以看出,在处理多个相同任务的时候,线程池(线程数量为4时)的速度几乎是单线程的4倍,当然,线程数不是越多越好,取决于CPU的核数(最好不要大于CPU的核数,因为太多的工作线程会竞争CPU的资源,带来不必要的上下文切换,小于CPU的核数则不能够充分利用CPU)。
对于某些场景,使用线程池是很有必要的,在需要高并发的服务器中线程池几乎是必备的,如文件传输的服务器,多用户下载或者上传文件时,几乎是同步的,在高并发场景下,如果每个请求都创建一个新线程,会导致线程数量过多,同时线程的创建和销毁也需要消耗大量的资源。为了解决这些问题,可以使用线程池技术。线程池预先创建一定数量的线程,并且可以在多个请求之间复用这些线程,从而提高服务器的处理能力和资源利用率。因此,在高并发的服务器中,使用线程池技术可以有效地降低资源消耗、提高系统性能和响应速度,是非常必要和常用的技术手段之一。
虽然现在有很多封装好的线程池供我们调用。但是,其原理也是值得我们推敲的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 自动化测试框架 —— pytest框架入门到入职篇
- jdk 线程池与 tomcat 线程池对比
- C#编程语言的从入门到深入学习大纲
- element中Table表格控件实现单选功能、多选功能、两种分页方式
- 【Filament】加载obj和fbx模型
- string_char把ascii数值转换成字符
- 配置IPv4静态路由与静态BFD联动
- HarmonyOS4.0系统性深入开发18公共事件简介
- 基于SpringBoot的人事管理系统(程序+数据库+文档)
- 安防视频监控EasyCVR平台HTTP-FMP4播放协议在分屏播放时的性能优化