robots.txt
####什么是robots.txt?
? robots.txt是一个协议,我们可以把它理解为一个网站的"管家",它会告诉搜索引擎哪些页面可以访问,哪些页面不能访问。也可以规定哪些搜索引擎可以访问我们的网站而哪些搜索引擎不能爬取我们网站的信息等等,是网站管理者指定的"君子协议"。
当一个搜索机器人(有的叫搜索蜘蛛)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取。
另外,robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。
如何查看robots.txt?
在浏览器的网址搜索栏中,输入网站的根域名,然后再输入/robot.txt即可查看。比如,百度的robots.txt网址为 https://www.baidu.com/robots.txt
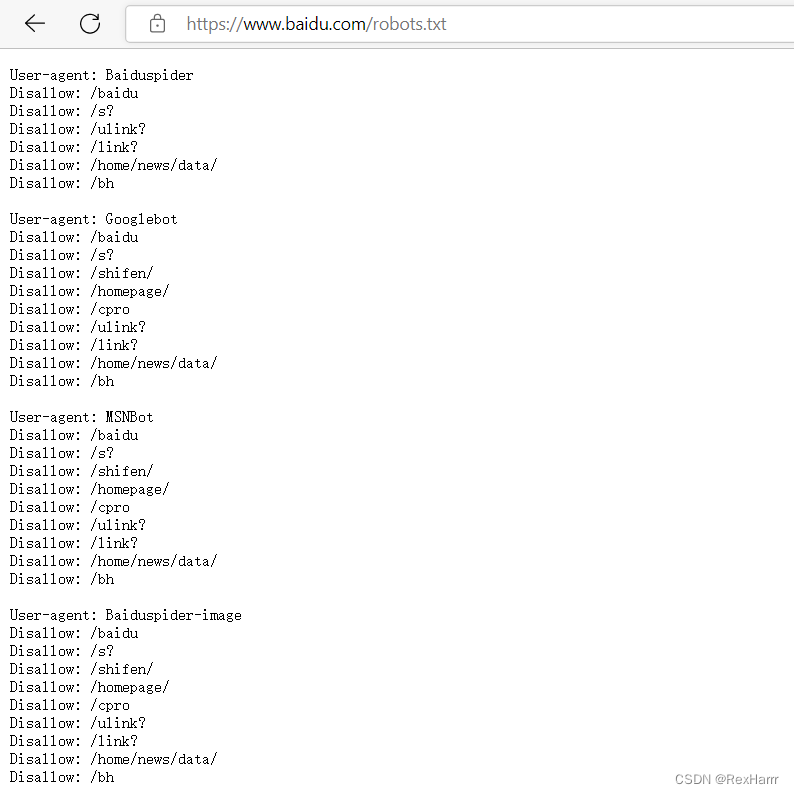
robots.txt的内容
User-agent: 搜索机器人的名称
Disallow: 不允许搜索机器人访问的地址
Allow: 允许搜索机器人访问的地址
若User-agent是*,则表示允许所有的搜索机器人访问该站点下的所有文件。在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。
Disallow和Allow后面跟的是地址,这个URL可以是一条完整的路径,也可以是部分的,地址的描述格式符合正则表达式(regex)的规则。因此可以在python中使用正则表达式来筛选出可以访问的地址。需要特别注意的是Disallow与Allow行的顺序是有意义的,robot会根据第一个匹配成功的Allow或Disallow行确定是否访问某个URL。
下列内容代表 禁止所有搜索引擎访问网站的任何部分
User-agent: *
Disallow: /
例如:

代表禁止Baidu spider访问根目录下/baidu 、/s?、/ulink?、/link?、/home/news/data/、/bh 这几个子目录
具体的写法可参考:robots.txt 文件详解_passport_daizi的博客-CSDN博客
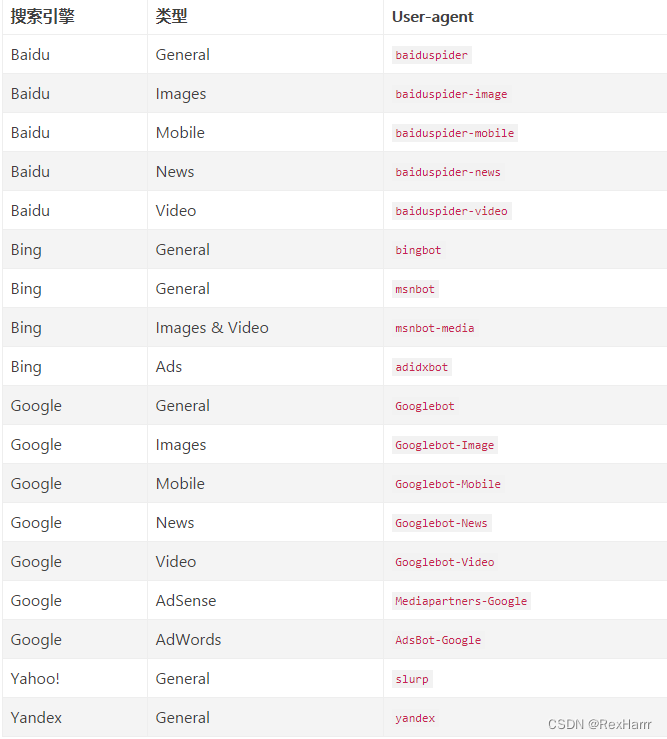
常见的搜索引擎的蜘蛛名称
如果创建并上传robots.txt文件?
(1) 用记事本或者其他文本型的软件(譬如Emeditor)创建一个名为robots.txt的文件,注意名字不能改,也不能大写,必须全小写。
(2) 用记事本编辑该文件,输入指令规则
例如:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~name/
(3) 上传文件至网站根目录。由于网站建站系统不同、服务器架构不同,上传文件的方法没有统一的,譬如可以借助主机的管理面板,又或是用FTP,在连通到网站所在的文件目录后,将robots.txt放在网站所在文件夹第一层中(也就是根目录,必须位于根目录中,否则无效)。当成功上传后,通常在浏览器中访问域名/robots.txt就可以查看到文件。
如果网站信息都需要被抓取,是不是可以不用robots.txt了?
每当用户试图访问某个不存在的URL时,服务器都会在日志中记录404错误(无法找到文件)。每当搜索蜘蛛来寻找并不存在的robots.txt文件时,服务器也将在日志中记录一条404错误,所以建议还是添加一个robots.txt。
为什么叫"君子协议 "
本身robots.txt就只是一个约定,一个协议,是道德约束,一般的搜索引擎爬虫都会遵守这个协议的,否则在这个行业还怎么混下去。而且robots.txt一般也是站点为了更好被搜索引擎收录所准备的。真正的封禁不可能靠user-agent来封禁。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用SpringCache缓存数据
- 2023 年全国职业院校技能大赛(高职组) “云计算应用” 评分标准
- C++ //练习 2.21 请解释下述定义。在这些定义中有非法的吗?如果有,为什么?
- 【Linux】修复 Linux 错误 - 没有可用的锁
- 大话 JavaScript(Speaking JavaScript):第十一章到第十五章
- java基础类型与输入输出
- 黑盒测试,软件测试中的军体拳
- 【javascript】npm ERR! cb() never called!
- 11.2 Linux串口驱动框架
- NLP深入学习(七):词向量