ClickHouse 23.12 版本发布说明

本文字数:12700;估计阅读时间:32?分钟
作者:ClickHouse?Team
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发
欢迎来到2024年的第一篇新版本发布文章,实际上是与2023年底悄悄发布的那个版本相关!
发布概要:
新增21个新功能
实现了18项性能优化
修复了37处bug
在本文中,我们将介绍一小部分新功能,但这个新版本还包括:ORDER BY ALL按所有字段排序的功能,生成基于数字的短唯一标识符(SQID),使用新的傅立叶变换系列PeriodDetectFFT函数查找信号频率,支持SHA-512/256,ALIAS列上的索引,通过APPLY DELETED MASK在轻量删除操作后清除已删除的记录,哈希连接的内存使用率降低以及Merge表的更快计数。
在集成方面,我们还改进了ClickHouse的PowerBI、Metabase、dbt、Apache Beam和Kafka的连接器。
新的贡献者
一如既往,我们特别欢迎所有23.12版的新贡献者!ClickHouse的受欢迎程度在很大程度上归功于贡献社区的努力。看到这个社区不断壮大总是令人感到自豪。
以下是新贡献者的姓名:
Andrei Fedotov, Chen Lixiang, Gagan Goel, James Nock, Natalya Chizhonkova, Ryan Jacobs, Sergey Suvorov, Shani Elharrar, Zhuo Qiu, andrewzolotukhin, hdhoang, and skyoct.
如果你在这里看到你的名字,请与我们联系...当然,我们也会在 Twitter 等平台上找到你。
-
新版本发布视频见 YouTube:https://www.youtube.com/watch?v=7TLuT6gt0PQ
-
您还可以查看演示文稿(https://presentations.clickhouse.com/release_23.12)。
可刷新的物化视图
由Michael Kolupaev、Michael Guzov贡献
对ClickHouse不熟悉的用户,会发现经常要探索物化视图,以解决各种数据和查询问题,从加速聚合查询到在插入时进行数据转换任务。此时,这些用户经常会遇到一个常见的困惑——他们期望ClickHouse中所使用的物化视图,与他们在其他数据库中使用的物化视图类似,而实际上它们只是在插入新行时执行的查询触发器!更准确地说,当将行作为块(通常至少包含1000行)插入ClickHouse时,物化视图的查询在该块上执行,并将结果存储在不同的目标表中。我们的同事 Mark 在最近的一段视频中简洁地描述了这个过程。

这一功能非常强大,与ClickHouse中的大多数功能一样,都是经过了精心设计,以便在插入新数据时,以增量方式更新视图。然而,也存在着这样一些用例,这种增量过程是不必要的或不适用的。有些问题与增量方法不兼容,或者不需要实时更新,定期的重建会更为合适。例如,您可能希望定期对完整数据集执行视图的完全重新计算,因为它使用了复杂的JOIN,这与增量方法不兼容。
在23.12中,我们很高兴地宣布,作为实验性功能,我们发布了可刷新的物化视图,以解决这些问题!除了允许视图由定期执行的查询组成,并将结果集设置到目标表之外,此功能还可用于在ClickHouse中执行cron任务,例如,定期从外部数据源导出或导入数据。
关于本重大功能的详细信息值得一篇专门的博文(敬请关注!),特别是考虑到它可能会解决大量的问题。
举个例子,为了介绍语法,让我们考虑一个使用传统的增量物化视图或经典视图可能难以解决的问题。
考虑我们与dbt集成所使用的示例。这包括一个具有以下关系模式的小型IMDB数据集。此数据集源自关系数据集存储库。
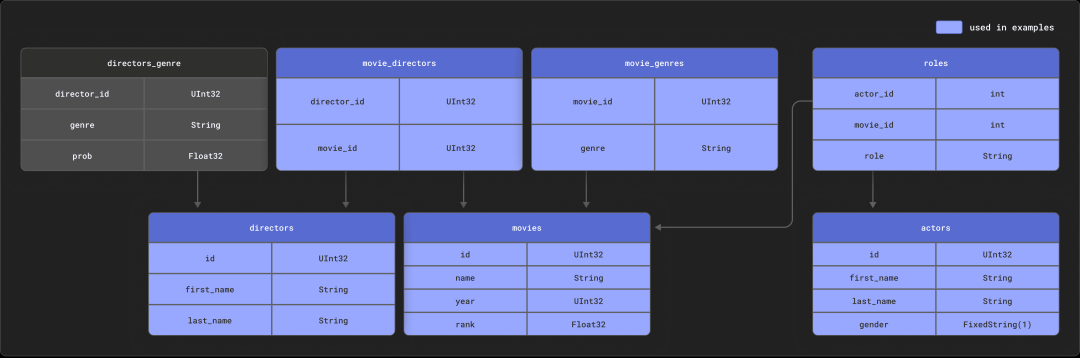
假设您已经按照文档在ClickHouse中创建和填充了这些表,可以使用以下查询,来计算每个演员的摘要,按电影出现次数倒排序。
SELECT
id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM
(
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 5
┌─────id─┬─name─────────┬─num_movies─┬───────────avg_rank─┬─unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 45332 │ Mel Blanc │ 909 │ 5.7884792542982515 │ 19 │ 148 │ 2024-01-08 15:44:31 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605094212635 │ 20 │ 301 │ 2024-01-08 15:44:31 │
│ 283127 │ Tom London │ 549 │ 2.8057034230202023 │ 18 │ 208 │ 2024-01-08 15:44:31 │
│ 41669 │ Adoor Bhasi │ 544 │ 0 │ 4 │ 121 │ 2024-01-08 15:44:31 │
│ 89951 │ Edmund Cobb │ 544 │ 2.72430730046193 │ 17 │ 203 │ 2024-01-08 15:44:31 │
└────────┴──────────────┴────────────┴────────────────────┴───────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 1.207 sec. Processed 5.49 million rows, 88.27 MB (4.55 million rows/s., 73.10 MB/s.)
Peak memory usage: 1.44 GiB.诚然,这不是最慢的查询,但让我们假设用户需要让这个查询更快且计算成本更低,以用于应用程序。假设此数据集还会经常的更新 - 电影的不断上映,新的演员和导演也不断的涌现。
在这种情况下,普通视图无法满足要求,将其转换为增量物化视图将会很有挑战性:只有左侧表的变改才会被反映,需要多个链接的视图和很大的复杂性。
有了23.12,我们可以创建一个可刷新的物化视图,定期运行上述查询,并以原子方式替换目标表中的结果。虽然这不会像增量视图一样实时更新,但对于不太可能频繁更新的数据集而言,这可能已经足够了。
让我们首先为结果创建目标表:
CREATE TABLE imdb.actor_summary
(
`id` UInt32,
`name` String,
`num_movies` UInt16,
`avg_rank` Float32,
`unique_genres` UInt16,
`uniq_directors` UInt16,
`updated_at` DateTime
)
ENGINE = MergeTree
ORDER BY num_movies创建可刷新的物化视图使用与增量相同的语法,只是我们引入了一个REFRESH子句,指定应执行查询的周期。请注意,我们取消了查询存储完整结果的限制。此视图类型对SELECT子句不施加任何限制。
//enable experimental feature
SET allow_experimental_refreshable_materialized_view = 1
CREATE MATERIALIZED VIEW imdb.actor_summary_mv
REFRESH EVERY 1 MINUTE TO imdb.actor_summary AS
SELECT
id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM
(
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC该视图将立即执行,并在之后的每一分钟按配置执行,以确保源表的更新得以反映。我们之前用于获取演员摘要的查询在语法上变得更简单,而且速度显著提升!
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5
┌─────id─┬─name─────────┬─num_movies─┬──avg_rank─┬─unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 45332 │ Mel Blanc │ 909 │ 5.7884793 │ 19 │ 148 │ 2024-01-09 10:12:57 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605 │ 20 │ 301 │ 2024-01-09 10:12:57 │
│ 283127 │ Tom London │ 549 │ 2.8057034 │ 18 │ 208 │ 2024-01-09 10:12:57 │
│ 356804 │ Bud Osborne │ 544 │ 1.9575342 │ 16 │ 157 │ 2024-01-09 10:12:57 │
│ 41669 │ Adoor Bhasi │ 544 │ 0 │ 4 │ 121 │ 2024-01-09 10:12:57 │
└────────┴──────────────┴────────────┴───────────┴───────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.003 sec. Processed 6.71 thousand rows, 275.62 KB (2.30 million rows/s., 94.35 MB/s.)
Peak memory usage: 1.19 MiB.假设我们向源数据添加了一位新演员,“Clicky McClickHouse”,他碰巧出演了很多电影!
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');INSERT INTO imdb.roles SELECT
845466 AS actor_id,
id AS movie_id,
'Himself' AS role,
now() AS created_at
FROM imdb.movies
LIMIT 10000, 910
0 rows in set. Elapsed: 0.006 sec. Processed 10.91 thousand rows, 43.64 KB (1.84 million rows/s., 7.36 MB/s.)
Peak memory usage: 231.79 KiB.不到60秒后,我们的目标表得到更新,反映了Clicky的多产演艺生涯:
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5
┌─────id─┬─name────────────────┬─num_movies─┬──avg_rank─┬unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 845466 │ Clicky McClickHouse │ 910 │ 1.4687939 │ 21 │ 662 │ 2024-01-09 10:45:04 │
│ 45332 │ Mel Blanc │ 909 │ 5.7884793 │ 19 │ 148 │ 2024-01-09 10:12:57 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605 │ 20 │ 301 │ 2024-01-09 10:12:57 │
│ 283127 │ Tom London │ 549 │ 2.8057034 │ 18 │ 208 │ 2024-01-09 10:12:57 │
│ 356804 │ Bud Osborne │ 544 │ 1.9575342 │ 16 │ 157 │ 2024-01-09 10:12:57 │
└────────┴─────────────────────┴────────────┴───────────┴──────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.003 sec. Processed 6.71 thousand rows, 275.66 KB (2.20 million rows/s., 90.31 MB/s.)
Peak memory usage: 1.19 MiB.这个例子演示了可刷新物化视图的简单应用。该功能可能具有更广泛的应用。查询执行的周期性意味着它可能被用于定期导入或导出到外部数据源。此外,这些视图可以使用DEPENDS子句链接,以在视图之间创建依赖关系,从而允许构建复杂的工作流程。有关更多详细信息,请参阅CREATE VIEW文档。
我们很想知道您如何利用这个功能以及它让您更有效地解决了哪些问题!
优化 FINAL
由Maksim Kita贡献
自动增量后台数据转换是ClickHouse中的一个重要概念,允许在后台合并数据part时持续应用特定于表引擎的数据修改,从而在大规模情况下维持高速率数据摄入。例如,当合并part时,ReplacingMergeTree引擎仅保留基于行的排序键列值和包含数据part的创建时间戳的最近插入版本的行。AggregatingMergeTree引擎在part合并期间,将具有相等排序键值的行合并为一个聚合行。
只要表存在多个part,表数据就处于中间状态,即对于ReplacingMergeTree表可能存在过时的行,对于AggregatingMergeTree表可能尚未对所有行进行聚合。在具有连续数据摄入的场景中(例如实时流场景),几乎总是存在多个part的情况。幸运的是,ClickHouse为您提供了解决方案:ClickHouse在SELECT查询的FROM子句上提供FINAL作为修饰符(例如SELECT ... FROM table FINAL),它在查询时动态应用缺失的数据转换。虽然这很方便,并且将查询结果与后台合并的进度解耦,但FINAL可能会减慢查询速度,并增加内存消耗。
在ClickHouse 20.5版本之前,带有FINAL的SELECT是以单线程方式执行的:所选数据按物理顺序(基于表的排序键)由单个线程读取,同时进行合并和转换。
自从ClickHouse 20.5引入了使用FINAL并行处理SELECT的功能:所有所选数据被拆分为带有不同排序键范围的组,并由多个线程同时处理(读取,合并和转换)。
ClickHouse 23.12迈出了一个重要的步伐,根据排序键值将与查询的WHERE子句匹配的表数据划分为不相交和相交范围。所有不相交的数据范围都被并行处理,就好像在查询中没有使用FINAL修饰符一样。这仅留下相交的数据范围,对于这些范围,应用了ClickHouse 20.5引入的并行处理方法的表引擎的合并逻辑。
此外,对于FINAL查询,如果表的分区键是表的排序键的前缀,ClickHouse将不再尝试在不同分区之间合并数据。
以下图表展示了带有FINAL的SELECT查询的新处理逻辑:
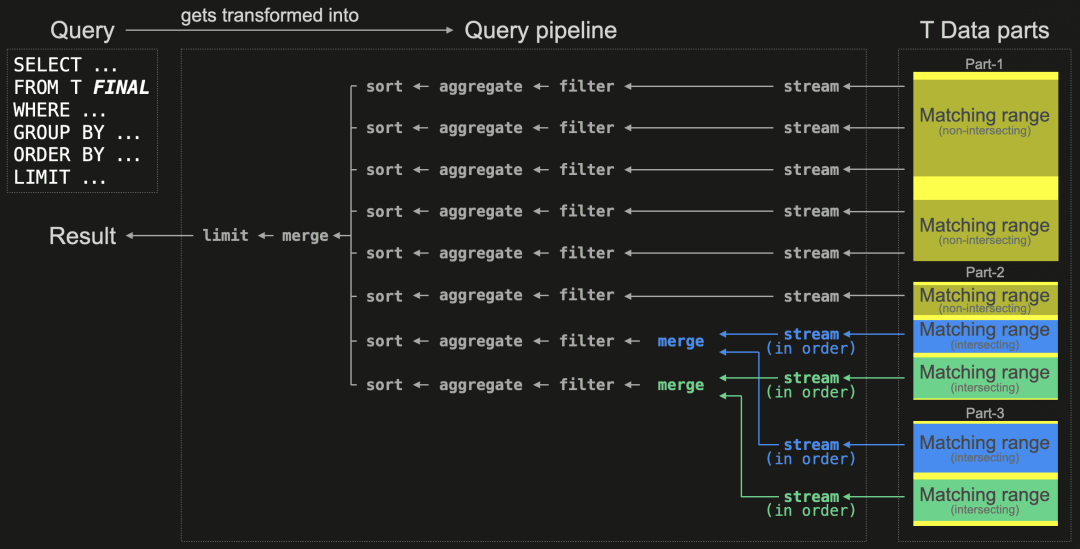
为了并行化数据处理,查询被转换为一个查询管道 - 查询的物理操作计划,包括多个独立执行通道,可以同时流式传输、过滤、聚合和排序所选表数据的不相交范围。独立执行通道的数量取决于max_threads设置,默认情况下设置为可用CPU核心的数量。在我们上面的示例中,运行查询的ClickHouse服务器有8个CPU核心。
由于查询使用了FINAL修饰符,ClickHouse在计划时,使用表数据part的主索引创建物理操作计划。
首先,识别并拆分与查询的WHERE子句匹配的part内的所有数据范围,基于表的排序键,将其划分为不相交和相交范围。不相交范围是:仅存在于单个部分的数据区域,无需转换。相反,相交范围中的行可能存在于多个part(基于排序键值),并且需要特殊处理。此外,在我们上面的示例中,查询规划器可以将所选的相交范围拆分为两组(在图表中以蓝色和绿色标记),每组具有一个不同的排序键范围。通过创建的查询管道,所有匹配的不相交数据范围(在图表中以黄色标记)通常会像没有FINAL子句的查询一样被并行处理,通过在一些可用的执行通道之间均匀分配它们的处理。所选相交数据范围的数据会按组顺序传送,并在数据像往常一样被处理之前,应用表引擎特定的合并逻辑。
请注意,当具有相同排序键列值的行数较少时,查询性能将大致与未使用FINAL时相同。我们通过一个具体的示例来演示这一点。为此,我们轻微修改了来自英国房地产价格示例数据集的表,并假设该表存储着当前房产报价,而不是以前出售的房产的数据。我们使用了ReplacingMergeTree表引擎,允许我们通过插入具有相同排序键值的新行,来更新提供的房产的价格和其他特征:
CREATE TABLE uk_property_offers
(
postcode1 LowCardinality(String),
postcode2 LowCardinality(String),
street LowCardinality(String),
addr1 String,
addr2 String,
price UInt32,
…
)
ENGINE = ReplacingMergeTree
ORDER BY (postcode1, postcode2, street, addr1, addr2);接下来,我们向表中插入约1500万行数据。
我们在ClickHouse版本23.11上运行一个典型的分析查询,选择三个最昂贵的主邮政编码:
SELECT
postcode1,
formatReadableQuantity(avg(price))
FROM uk_property_offers
GROUP BY postcode1
ORDER BY avg(price) DESC
LIMIT 3
┌─postcode1─┬─formatReadableQuantity(avg(price))─┐
│ W1A │ 163.58 million │
│ NG90 │ 68.59 million │
│ CF99 │ 47.00 million │
└───────────┴────────────────────────────────────┘
3 rows in set. Elapsed: 0.037 sec. Processed 15.52 million rows, 91.36 MB (418.58 million rows/s., 2.46 GB/s.)
Peak memory usage: 881.08 KiB.我们在带FINAL修饰符的ClickHouse版本23.11上运行相同的查询:
SELECT
postcode1,
formatReadableQuantity(avg(price))
FROM uk_property_offers FINAL
GROUP BY postcode1
ORDER BY avg(price) DESC
LIMIT 3;
┌─postcode1─┬─formatReadableQuantity(avg(price))─┐
│ W1A │ 163.58 million │
│ NG90 │ 68.59 million │
│ CF99 │ 47.00 million │
└───────────┴────────────────────────────────────┘
3 rows in set. Elapsed: 0.299 sec. Processed 15.59 million rows, 506.68 MB (57.19 million rows/s., 1.86 GB/s.)
Peak memory usage: 120.81 MiB.请注意,带FINAL修饰符的查询运行速度慢了约10倍,并且使用的主内存明显增加。
我们在ClickHouse 23.12上运行带FINAL修饰符的查询:
SELECT
postcode1,
formatReadableQuantity(avg(price))
FROM uk_property_offers FINAL
GROUP BY postcode1
ORDER BY avg(price) DESC
LIMIT 3;
┌─postcode1─┬─formatReadableQuantity(avg(price))─┐
│ W1A │ 163.58 million │
│ NG90 │ 68.59 million │
│ CF99 │ 47.00 million │
└───────────┴────────────────────────────────────┘
3 rows in set. Elapsed: 0.036 sec. Processed 15.52 million rows, 91.36 MB (434.42 million rows/s., 2.56 GB/s.)
Peak memory usage: 1.62 MiB.对于我们的示例数据,无论是否使用FINAL修饰符,23.12上的查询运行时间和内存使用情况都保持大致相同!:)
矢量化功能提升
在23.12中,通过使用SIMD指令增加矢量化,显著改进了几个常见查询。
更快的min/max
由Raúl Marín贡献
由于允许使用SIMD指令对这些函数进行矢量化,min和max函数现在变得更快。这些改变应该提高查询性能,当CPU受限而不受I/O或内存带宽限制时。尽管这些情况可能很少见,但改进可能是显著的。考虑以下相当人为的例子,在这个例子中,我们计算10亿个整数的最大数。以下是在支持Intel AVX指令的Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz上执行的。
在23.11:
SELECT max(number)
FROM
(
SELECT *
FROM system.numbers
LIMIT 1000000000
)
┌─max(number)─┐
│ 999999999 │
└─────────────┘
1 row in set. Elapsed: 1.102 sec. Processed 1.00 billion rows, 8.00 GB (907.50 million rows/s., 7.26 GB/s.)
Peak memory usage: 65.55 KiB.现在来看23.12版本:
┌─max(number)─┐
│ 999999999 │
└─────────────┘
1 row in set. Elapsed: 0.482 sec. Processed 1.00 billion rows, 8.00 GB (2.07 billion rows/s., 16.59 GB/s.)
Peak memory usage: 62.59 KiB.对于一个更为现实的例子,考虑以下包含超过10亿行数据的NOAA天气数据集。下面我们计算有史以来记录的最高温度。
在23.11:
SELECT max(tempMax) / 10
FROM noaa
┌─divide(max(tempMax), 10)─┐
│ 56.7 │
└──────────────────────────┘
1 row in set. Elapsed: 0.428 sec. Processed 1.08 billion rows, 3.96 GB (2.52 billion rows/s., 9.26 GB/s.)
Peak memory usage: 873.76 KiB.虽然在23.12中的改进不像我们之前的人为例子那样显著,但我们仍然获得了25%的加速!
┌─divide(max(tempMax), 10)─┐
│ 56.7 │
└──────────────────────────┘
1 row in set. Elapsed: 0.347 sec. Processed 1.08 billion rows, 3.96 GB (3.11 billion rows/s., 11.42 GB/s.)
Peak memory usage: 847.91 KiB.更快的聚合
由Anton Popov贡献
由于对跨足一个块的相同键情况进行了优化,聚合也变得更快了。ClickHouse以块为单位处理数据。在聚合处理期间,ClickHouse使用哈希表来存储新的聚合值,或者更新已存在的聚合值,用于处理每个已处理行块内的分组键值。分组键值用于确定哈希表内聚合值的位置。当已处理块中的所有行都具有相同的唯一分组键时,ClickHouse只需一次确定聚合值的位置,然后进行该位置的一批值更新,这可以很好地进行矢量化。
让我们在Apple M2 Max上尝试一下,看看我们的效果如何。
SELECT number DIV 100000 AS k,
avg(number) AS avg,
max(number) as max,
min(number) as min
FROM numbers_mt(1000000000)
GROUP BY k
ORDER BY k
LIMIT 10;在23.11中:
┌─k─┬──────avg─┬────max─┬────min─┐
│ 0 │ 49999.5 │ 99999 │ 0 │
│ 1 │ 149999.5 │ 199999 │ 100000 │
│ 2 │ 249999.5 │ 299999 │ 200000 │
│ 3 │ 349999.5 │ 399999 │ 300000 │
│ 4 │ 449999.5 │ 499999 │ 400000 │
│ 5 │ 549999.5 │ 599999 │ 500000 │
│ 6 │ 649999.5 │ 699999 │ 600000 │
│ 7 │ 749999.5 │ 799999 │ 700000 │
│ 8 │ 849999.5 │ 899999 │ 800000 │
│ 9 │ 949999.5 │ 999999 │ 900000 │
└───┴──────────┴────────┴────────┘
10 rows in set. Elapsed: 1.050 sec. Processed 908.92 million rows, 7.27 GB (865.66 million rows/s., 6.93 GB/s.)在23.12中:
┌─k─┬──────avg─┬────max─┬────min─┐
│ 0 │ 49999.5 │ 99999 │ 0 │
│ 1 │ 149999.5 │ 199999 │ 100000 │
│ 2 │ 249999.5 │ 299999 │ 200000 │
│ 3 │ 349999.5 │ 399999 │ 300000 │
│ 4 │ 449999.5 │ 499999 │ 400000 │
│ 5 │ 549999.5 │ 599999 │ 500000 │
│ 6 │ 649999.5 │ 699999 │ 600000 │
│ 7 │ 749999.5 │ 799999 │ 700000 │
│ 8 │ 849999.5 │ 899999 │ 800000 │
│ 9 │ 949999.5 │ 999999 │ 900000 │
└───┴──────────┴────────┴────────┘
10 rows in set. Elapsed: 0.649 sec. Processed 966.48 million rows, 7.73 GB (1.49 billion rows/s., 11.91 GB/s.)PASTE JOIN
由Yarik Briukhovetskyi贡献
PASTE JOIN对于连接多个数据集很有用,其中每个数据集中的等效行指的是相同的项目。也就是说,第一个数据集中的第n行应该与第二个数据集中的第n行连接。然后,我们可以通过行号而不是指定连接键来连接数据集。
让我们使用Hugging Face上GLUE基准测试中的Quora Question Pairs2数据集进行尝试。我们将训练Parquet文件分成两部分:
questions.parquet 包含question1、question2和idx labels.parquet 包含label和idx
然后,我们可以使用PASTE JOIN将这些列重新连接在一起。
INSERT INTO FUNCTION file('/tmp/qn_labels.parquet') SELECT *
FROM
(
SELECT *
FROM `questions.parquet`
ORDER BY idx ASC
) AS qn
PASTE JOIN
(
SELECT *
FROM `labels.parquet`
ORDER BY idx ASC
) AS lab
Ok.
0 rows in set. Elapsed: 0.221 sec. Processed 727.69 thousand rows, 34.89 MB (3.30 million rows/s., 158.15 MB/s.)
Peak memory usage: 140.47 MiB.
??联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue3新手必备:轻松掌握watch的使用技巧!
- initialDownlinkBWP-RedCap不包含pagingSearchSpace,Redcap ue应该怎么监听paging?
- logstack 日志技术栈-02-ELK 的缺点?loki 更轻量的解决方案?
- MySQL中约束是什么?
- 2024山东福祉展,中国残疾人用品展,济南失能护理与用品展会
- Netfilter 是如何工作的(六):连接跟踪信息的入口创建(in)和出口确认(confirm)
- VUE项目快速打包发布
- STM32 基础知识(探索者开发板)--135讲 ADC转换
- 输入两个时间,判断时间是否为非工作日,并且是日期否为同一天。是的话返回true,否返回false
- 智能优化算法应用:基于战争策略算法3D无线传感器网络(WSN)覆盖优化 - 附代码