Python——机器学习分类模型实例:从数据预处理到模型训练全流程
? ? ? ? ?本文旨在通过一份具体的数据,演示机器学习分类任务从数据预处理到模型训练的全流程。数据预处理过程主要包括缺失值、离群值处理,哑变量化和标准化。模型训练采用随机森林模型和LightGBM模型,同时进行了重要性变量提取和参数调优。文中也对一些细节和进阶的数据处理方法,进行了相应的文字提示。
1. 读取数据
? ? ? ?本文采用了5G用户预测数据集,该数据集为一个二分类数据集,标签为‘5y5g_flag’字段,取值 0 表示非5G用户,1 表示5G用户。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
data_dir='D:/ex/data/customer_5g/'
df_train=pd.read_csv(data_dir + 'train_data.csv')
df_test=pd.read_csv(data_dir + 'validation_data.csv')
# 查看数据集大小
print(df_train.shape)
print(df_test.shape)
#### 输出:
#### (23067, 46)
#### (15379, 46)
1.1 查看数据集是否平衡
df_train['5y5g_flag'].value_counts()
#### 输出:
#### 0 13660
#### 1 9407? ? ? ? 可以算平衡数据集。(不平衡数据集,可能需要通过过采样和欠采样方法来平衡,但该方法会破坏原数据集的数据分布,也可能使效果更差)
2. 数据预处理
2.1 缺失值
? ? ? ? 首先查看是否有空值。
df_train.info() #看出有空值
? ? ? ? 可以看出,性别、年龄等变量均存在缺失值。可以查看缺失的数量。
df_train.isnull().sum()[df_train.isnull().sum()>0]
? ? ? ? 此外,数据还可能出现缺失值用 0值、999值、'null' 字符串等形式表示,而非是空值。此时,可以用 df_train.describe() 方式,查看每个字段的统计量,通过查看最大值、最小值等的方式,判断是否有其它表示的缺失值。?
? ? ? ? 对测试集数据做相同查看。
2.1.1 缺失值处理方法一
? ? ? ? 如果只有训练集中存在缺失值,测试集中不存在,且缺失值比例很小,此时可以直接丢弃。
2.1.2 缺失值处理方法二
? ? ? ? 使用均值、中位数、众数等补全。
? ? ? ? 类别变量通常用众数补全 gender。
df_mode = df_train['gender'].mode()
print(df_mode)
## 输出: 0 男
df_train['gender']=df_train['gender'].fillna(df_mode[0])
# 查看补充后的情况
df_train.isnull().sum()[df_train.isnull().sum()>0]? ? ? ? ? 数值变量用中位数补全(用平均数的话最好先剔除异常值)?。
df_median = df_train.median()
#print(df_median)
df_train=df_train.fillna(df_median)2.1.3 缺失值处理方法三
? ? ? ? 可以将有缺失的变量视为响应变量,通过其它无缺失的变量来预测缺失值。
2.2 离群值
? ? ? ? 很多算法对离群值不敏感,可以不做处理。也有一些情况,离群值是真实存在的情况,需要保留,否则会降低模型准确性。所以该步骤要具体问题具体分析。可以通过可视化的方法,查看是否存在离群值。
? ? ? ? 首先,因为性别变量的取值为“男、女”,是 object格式,需要先做类别转换。用 0 表示男,1 表示女。
# 查看性别取值
df_train['gender'].unique()
#### 输出: array(['男', '女'], dtype=object)
# 替换
df_train['gender'][df_train['gender']=='男'] = 0
df_train['gender'][df_train['gender']=='女'] = 1
# 格式转换
df_train['gender'] = df_train['gender'].astype(int)
# 对测试集做相同处理
df_test['gender'][df_test['gender']=='男'] = 0
df_test['gender'][df_test['gender']=='女'] = 1
df_test['gender'] = df_test['gender'].astype(int)? ? ? ? 对每个变量画出箱型图。本文为简便批量画出,但因变量太多,视觉效果不算好。
## 提取变量名 和 变量数量
col_names = df_train.columns
col_num = len(col_names)
col_num
## 进行可视化, 10行5列
m = 10
n = 5
i=1
plt.figure(figsize=(15,20))
## 对每个变量,画出其箱型图
for name in col_names:
plt.subplot(m,n,i)
plt.boxplot(df_train[name])
plt.title(name)
i=i+1
? ? ? ? 可以看出,年龄中有一个超过150的离群值,且其明显为异常值。故可以直接剔除该条数据。
df_train = df_train[df_train.age <= 100].reset_index(drop=True)
# 验证一下是否已被删除
df_train[df_train.age > 100]
#### 输出为空2.3 哑变量化
? ? ? ? 因为性别已经手动处理为0、1数值型,故无需要哑变量化的特征。哑变量化的方法可参考我的文章:python——机器学习:sklearn数据预处理preprocessing连续特征离散化和类别特征编码_离散化数据怎么编码深度学习-CSDN博客
? ? ? ?或直接使用pandas中的get_dummies()。此处仅提供代码供参考。
# 将训练集和测试集合并进行特征编码
df_all = pd.get_dummies(pd.concat([df_train,df_test])).reset_index(drop=True)
# 再重新拆开
df_train_1 = df_all.iloc[0:23067]
df_test_1 = df_all.iloc[23067:]2.4 划分自变量和响应变量
? ? ? ? 因为本文用到的测试集数据中也包含了响应变量,故在此步划分。否则,可在哑变量化的前一步划分。
features=[]
for col in df_train.columns:
if col!='5y5g_flag' and col!='serv_id':
## 去除标签'5y5g_flag',和无意义的编码'serv_id'
features.append(col)
# 训练集
x_train=df_train[features]
y_train=df_train['5y5g_flag']
# 测试集
x_test=df_test[features]
y_test=df_test['5y5g_flag']2.5 标准化
? ? ? ? 本文采用?RobustScaler 方法进行标准化,详细介绍和其它方法可参考下面的文章。
python——机器学习:sklearn数据预处理preprocessing标准化、归一化和纠偏_python的preprocesing-CSDN博客
from sklearn.preprocessing import RobustScaler
rs = RobustScaler()
rs.fit(x_train)
# 对训练集和测试集进行转换
x_train_rs = rs.transform(x_train)
x_test_rs = rs.transform(x_test)
# 转回df格式
x_train=pd.DataFrame(x_train_rs,columns=features)
x_test=pd.DataFrame(x_test_rs,columns=features)? ? ? ? 至此,基本的数据预处理算是告一段落。更进一步的,可以对特征进行详细的相关性分析和新的特征构造等。
3. 模型训练
? ? ? ? 模型训练部分,通过随机森林和LightGBM两个模型进行演示。随机森林主要包括基础模型训练和重要性特征选择。LightGBM主要包括基础模型训练和参数网格搜索。
3.1 随机森林模型
3.1.1 基础模型训练
# 导入包
from sklearn.ensemble import RandomForestClassifier
# 定义一个随机森林分类器
rf = RandomForestClassifier(
min_samples_leaf=20, #每个节点的最小样本数
max_depth=10, #最大树深
n_estimators=150, #u弱分类器的个数
random_state=42 #随机种子固定
)
# 在训练集上进行训练
rf_model = rf.fit(x_train,y_train)
# 查看准确率
print("训练集准确率:",rf_model.score(x_train,y_train)) #训练集准确率
print("测试集准确率:",rf_model.score(x_test,y_test)) #测试集准确率
# 计算预测结果
rf_pred = rf.predict(x_test)输出结果:
训练集准确率: 0.7733026966097286 测试集准确率: 0.7609077313219325
3.1.2 重要性特征
将特征重要性排序
# 重要性特征和特征筛选
# 获取特征的重要性得分
importance = rf_model.feature_importances_ #特征重要性
# print(importance)
indices = np.argsort(importance) #返回每个得分按从小到大排列时,所在位置的索引
# print(indices)
# 从小到大对重要性进行排序
importance_sort = rf_model.feature_importances_[indices]
# print(importance_sort)
# 对特征名按重要性从小到大排序
feature_names_sort = np.array(x_train.columns)[indices] #特征名转化为array格式后排序
print(feature_names_sort)
获取重要性大于某一阈值的特征
importance_select = [] #特征重要性
feature_select = [] #特征名
#获取筛选后的特征名和特征重要性
for i,j in list(zip(importance_sort,feature_names_sort)):
#特征重要性是否大于0.01
if i>0.01:
importance_select.append(i) #添加到importance_select中
feature_select.append(j) #添加到feature_select中
else:
continue
# 打印特征及重要性值
print(importance_select)
print(feature_select)
print(len(feature_select))特征可视化
#特征可视化
y_pos = np.arange(len(feature_select)) #特征个数的排列
fig = plt.figure(figsize=(5,5)) #设置图像大小
plt.barh(y_pos, importance_select, align='center') #条形图
plt.yticks(y_pos, feature_select) #y轴刻度
plt.xlabel('特征') #x轴标签
plt.xlim(0,0.5) #x轴坐标范围
plt.title('特征重要性') #标题
plt.show()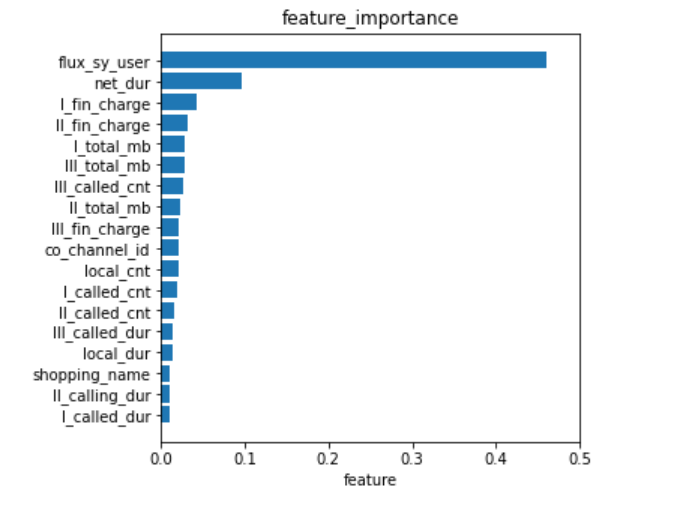
3.2 LightGBM
3.2.1 基础模型训练
? ? ? ? 基础模型训练和查看测试集上表现:
import lightgbm as lgb
# 定义一个LightGBM模型
gbm = lgb.LGBMClassifier(max_depth=6, num_leaves=50, subsample=0.8, learning_rate=0.1,
colsample_bytree = 0.8,
n_estimators=86, metrics='auc')
# 训练
gbm_model = gbm.fit(x_train, y_train)
# 预测
gbm_pred = gbm_model.predict(x_test)
# 计算准确率
print("训练集准确率:",gbm_model.score(x_train,y_train)) #训练集准确率
print("测试集准确率:",gbm_model.score(x_test,y_test)) #测试集准确率输出结果:
训练集准确率: 0.8102401803520333 测试集准确率: 0.7802197802197802
3.2.2 参数网格搜索
? ? ? ? 通过网格搜索的方法,确定模型的最优参数。详细内容可参考:
python——机器学习:sklearn模型选择model_selection模块函数说明和应用示例-CSDN博客
### 网格搜索确定最佳参数
from sklearn.model_selection import GridSearchCV
# 定义搜索范围
gbm_para={
'max_depth':[5,10,15],
'num_leaves':[29,31,40,60,80,90],
'reg_alpha':[0.5, 1, 2, 5, 10],
}
# 进行网格搜索
gbm_search = GridSearchCV(gbm, gbm_para, cv=5)
gbm_model2 = gbm_search.fit(x_train,y_train)? ? ? ? 获取最佳参数和最佳模型,并进行预测。
# 最佳参数
print(gbm_model2.best_params_)
#### 输出结果:
#### {'max_depth': 10, 'num_leaves': 80, 'reg_alpha': 0.5}
# 最佳模型
print(gbm_model2.best_estimator_)
#### 输出结果
LGBMClassifier(colsample_bytree=0.8, max_depth=10, metrics='auc',
n_estimators=86, num_leaves=80, reg_alpha=0.5, subsample=0.8)
# 最佳模型的预测结果
best_lgbm = gbm_model2.best_estimator_
print("训练集准确率:",best_lgbm.score(x_train,y_train)) #训练集准确率
print("测试集准确率:",best_lgbm.score(x_test,y_test)) #测试集准确率输出结果:
训练集准确率: 0.8630885285701899 测试集准确率: 0.7878275570583263
可以看出,在测试集上的准确率有所提高。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 远程服务器安装learn2learn
- (17)Linux的进程阻塞&&进程程序替换 && exec 函数簇
- 配置git服务器
- 【粉丝福利社】边缘计算系统设计与实践(文末送书-进行中)
- 【边缘计算的挑战和机遇】-未来可期
- NR cell配置带宽时,如何设置carrierBandwidth?
- 指标体系构建-03-交易型的数据指标体系
- 基于SpringBoot的教学辅助系统
- 【Sharding-Sphere 整合SpringBoot】
- flex布局(3)