DETR 【目标检测里程碑的任务】
标题
End-to-End Object Detection with Transformers
- end-to-end 意味着去掉了NMS的操作(生成很多的预测框,nms 去掉冗余的预测框)。因为有了NMS ,所以调参,训练都会多了一道工序,都会比较复杂和麻烦,不是所有硬件都支持的。
所以一个【端到端 detr】 解决了上述的问题,把目标检测转化成了集合预测的问题。
DETR 不再出很多冗余的框,一下就让模型训练和部署变得很简单。
【全新的架构】

摘要
补一嘴。目标检测 任务 天然的就不适合 自回归的架构(GPT系列)。理解一下:检测大物体,不需要依赖检测小物体, 检测右边的物体也不需要先检测左边的物体。且自回归是顺序推理,目标检测想要的一定是并行的一起出框。

引言

之前的一些工作都是不是直接预测目标框,而是设计了一些回归任务 来生成了很多接近重复的框。
- proposal Faster rcnn Cascade R-CNN 通过使用一系列逐级训练IoU阈值逐渐增加的检测器来解决高质量检测的问题
- anchor RetinaNet 提出新的损失函数 focal loss
- window centers object as points 新的物体检测方法,即将物体表示为一个点,通过关键点估计来找到物体中心点
再用nms来去除重复的框。所以需要很多的先验知识来设计NMS,如何可以好的去除这些冗余的框。DETR的目标就是消除这个鸿沟。
模型架构
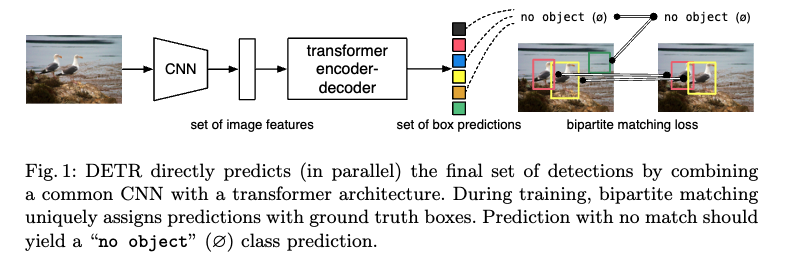
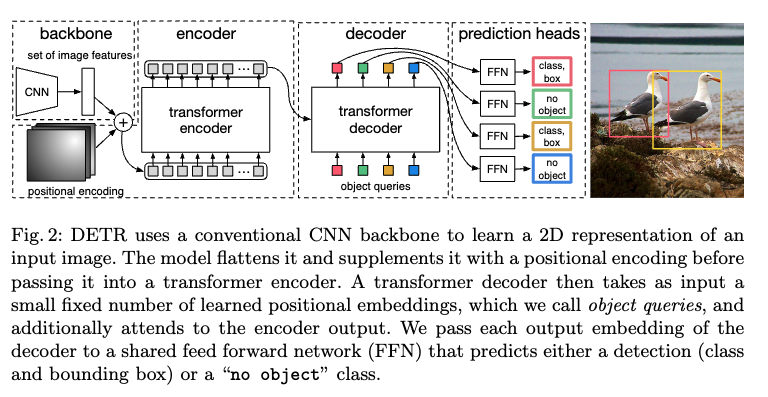
训练整个流程分为以下四步:
- 用cnn去抽特征 。把特征拉直 送给transformer
- encoder的作用就是学习这些全局的信息,使用encoder的好处是:每一个像素点或者说每一个特征都和其他的特征有交互了,那么就大概可以知道哪块是哪个物体,对于同一个物体就应该只出一个框。
- decoder的作用生成框的输出。object query 。 query 限定了要出多少个框。query和self-attention做交互,从而得出了最后的框。默认是100。那么问题来了,这100个框 怎么得到最后的ground truth呢?
使用了二分图匹配算法。
- 预测的框和ground truth的框做匹配,再匹配的框里面去算目标检测的loss。
(补充知识)DETR的二分图匹配损失函数是如何工作的?
DETR的全局损失函数采用了一个称为二分图匹配的方法,通过这种方法可以实现预测与实际目标的唯一匹配。在训练过程中,DETR会推断出一个固定大小的N个预测对象集合,然后通过最优的二分图匹配算法将这些预测对象与实际目标进行匹配。在匹配完成后,会对每个对象的特定损失(如边界框损失)进行优化。这个匹配的过程类似于用于将提议框或锚点与实际目标进行匹配的启发式分配规则。不同之处在于,DETR需要在直接集预测的情况下找到一对一的匹配,而不会出现重复的匹配。实际上,在匹配成本中,对于对象和空集之间的匹配成本并不依赖于预测结果,这意味着在这种情况下,成本是一个常数。DETR的全局损失函数还考虑了类别预测项,通过使用概率而不是对数概率,使得类别预测项与边界框损失项具有可比性,并且在实验中观察到了更好的性能表现。
推理的流程
- 和训练的逻辑一致,除了不再需要做训练的loss,直接在最后的输出上,用一个阈值去卡一个置信度。
结论

- 检测大物体的性能好,因为对大物体有全局建模的能力了,不再受限于anchor的设置
- 小物体就性能差了些。
- 对于未来的展望,后续的工作来改进。
- Deformable DETR 通过多尺度的特征来解决了小物体的问题。
 ?
? 训练太慢。
训练太慢。
- Deformable DETR 通过多尺度的特征来解决了小物体的问题。
相关工作
- 集合预测
- transformer 并行解码
- 目标检测的相关工作 . 性能比较低,往往用手工设计的人工干预。

-
- set based loss Learning non-maximum suppression
- relation network Relation Networks for Object Detection cvpr 2018?

RNN系列 对比transformer 并行推理。
DETR 最终能够work的主要原因!!!还是用了transformer
主要算法
- 基于集合的目标函数

再说 二分图匹配,抽象点来说,举个例子,如何分配一些工人,去干一些活,让最后的支出最小。
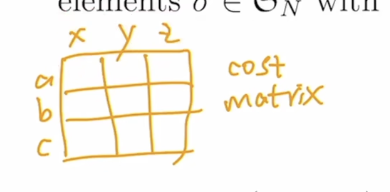
最优二分图匹配,最后能给一个唯一解,能够给到每个人都去做最擅长的工作,让总支出最小。典型:匈牙利算法 工程实现:scipy linear-sum-assignment

- 分类loss
- box loss l1 loss 和generalized iou loss
- 模型结构框架
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 云工作流 CloudFlow 重磅发布,流程式开发让云上应用构建更简单
- 1118. 分成互质组(DFS之搜索顺序)
- 初识人工智能,一文读懂贝叶斯优化和其他算法的知识文集(8)
- Ubuntu安装和配置Nextcloud并结合内网穿透实现远程访问
- Tomcat (Linux系统)详解全集
- 【rar密码】RAR文件打开密码的3种设置方法
- 对象转成json,由于数据量过大压缩成.json.zip格式
- 论文阅读 1| 从仿真域到实验域无监督轴承故障诊断的新型联合传输网络
- 数字式温度计的设计
- ArcMap实现多行标注