机器学习入门
发布时间:2024年01月21日
让机器 去学习
让机器 去执行
最早的机器学习应用-垃圾邮件分辨
传统的计算机解决问题思路:
- 编写规则,定义“垃圾邮件”,让计算机执行
- 对于很多问题,规则很难定义
- 规则在不断变化
人类学习方式
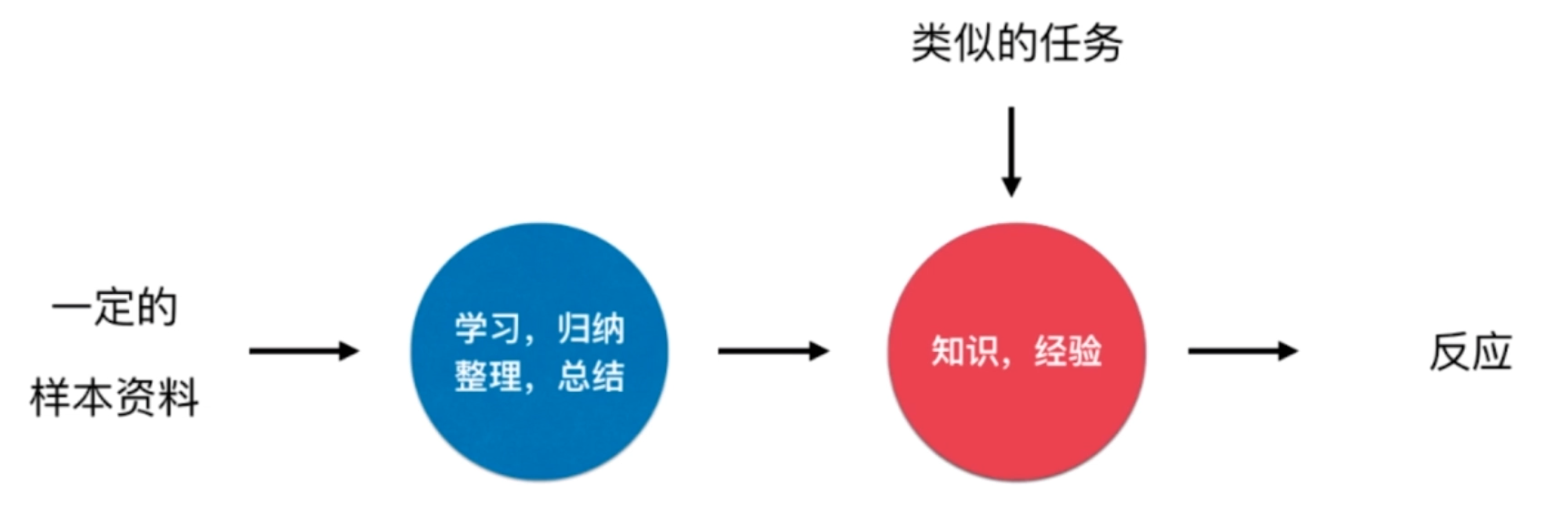
机器学习
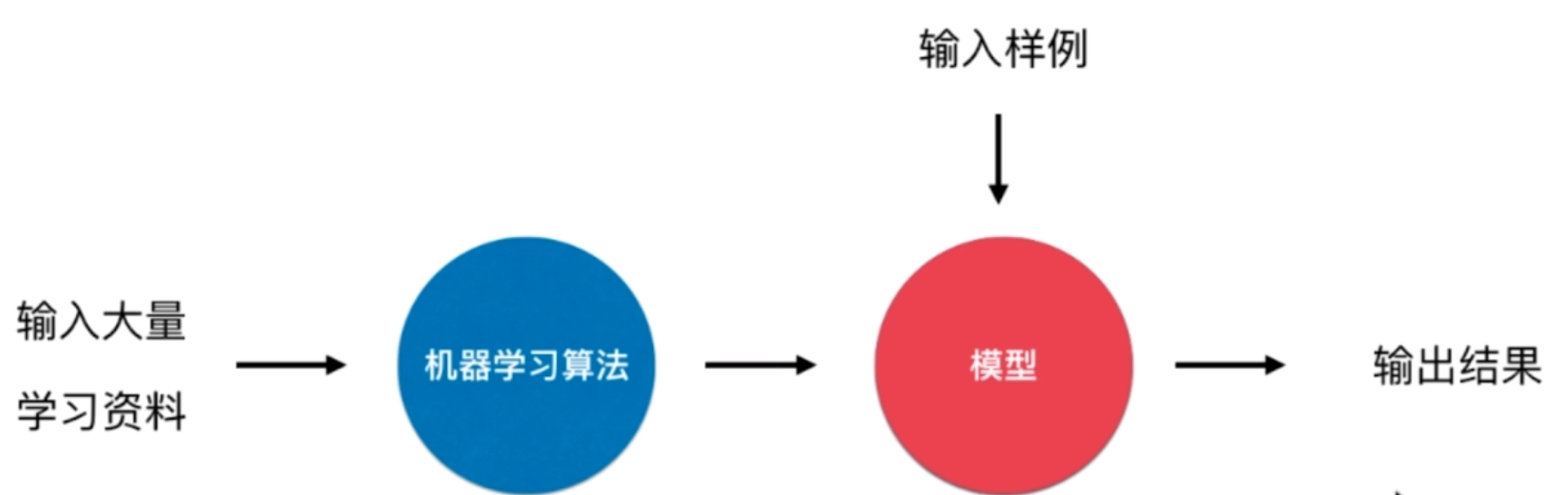
机器学习基础概念
数据
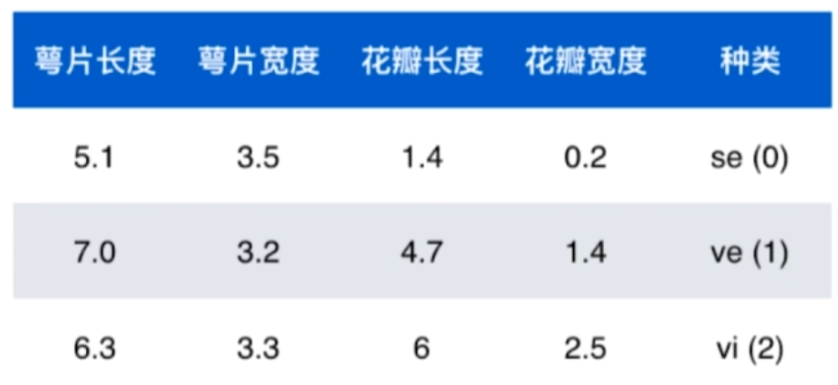
- 数据整体叫数据集(data set)
- 每一行数据称为一个样本(sample)
- 除最后一列,每一列表达样本的一个特征(feature)
- 最后一列,称为标记(label)



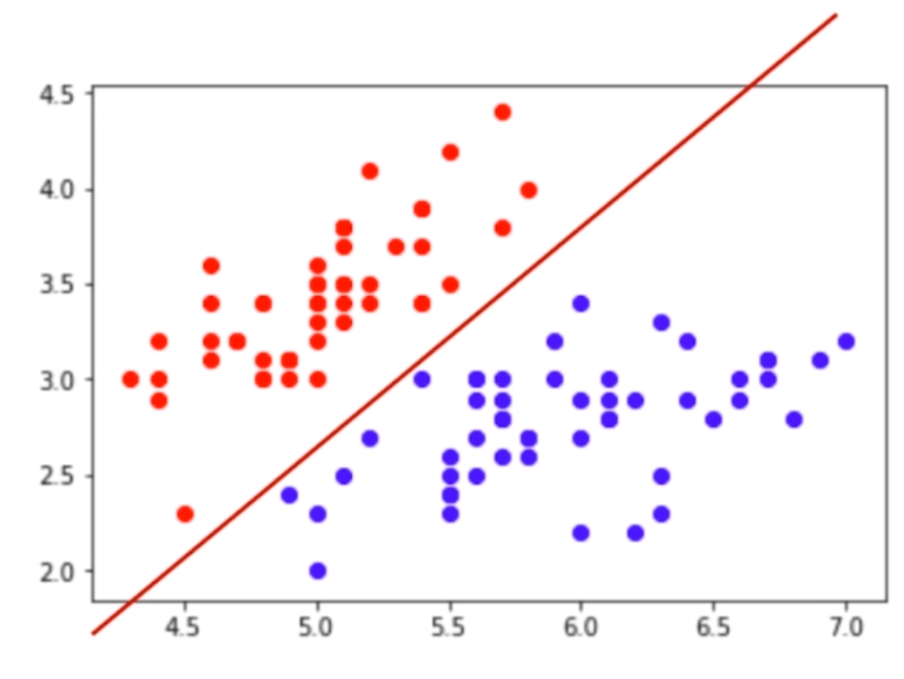
- 特征空间(feature space)
- 分类人物本质就是在特征空间切分
- 在高维空间同理
特征可以很抽象
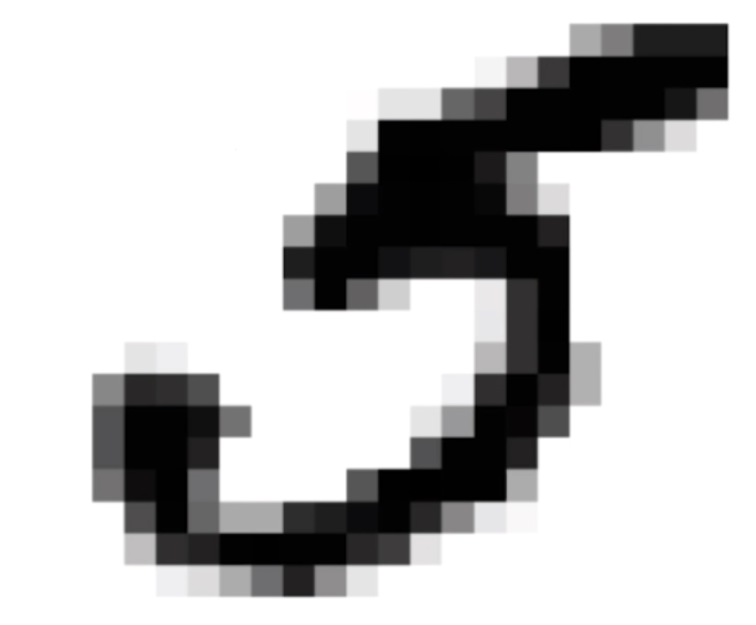
- 图像,每一个像素点都是特征
- 2828的图像有2828=784个特征
- 如果是彩色图像特征更多
机器学习的基本任务
分类任务
二分类:
- 判断邮件是不是垃圾邮件
- 判断发给客户信用卡有没有风险
- 判断股票跌涨
多分类:
- 数字识别
- 图像识别
- 判断发给客户的信用卡的风险评级
一些算法只支持完成二分类的任务
但是多分类的任务可以转换成二分类的任务
一些算法天然可以完成多分类任务‘’
多标签分类:

回归任务
结果是一个连续数字的值,而非一个类别
- 房屋价格
- 市场分析
- 学习成绩
- 股票价格
一些算法只能解决回归问题
一些算法只能解决分类问题
一些算法的思路既能解决回归问题,又能解决分类问题
一些情况下,回归任务可以简化成分类任务
监督学习
给机器的训练数据拥有“标记”或者“答案”
- 图像已经拥有了标定信息
- 银行已经积累了一定的客户信息和他们信用卡的信用情况
- 医院已经积累了一定的病人信息和他们最终确诊是否患病的情况
- 市场积累了房屋的基本信息和最终成交的金额
分类 回归
算法:
- k近邻
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
非监督学习
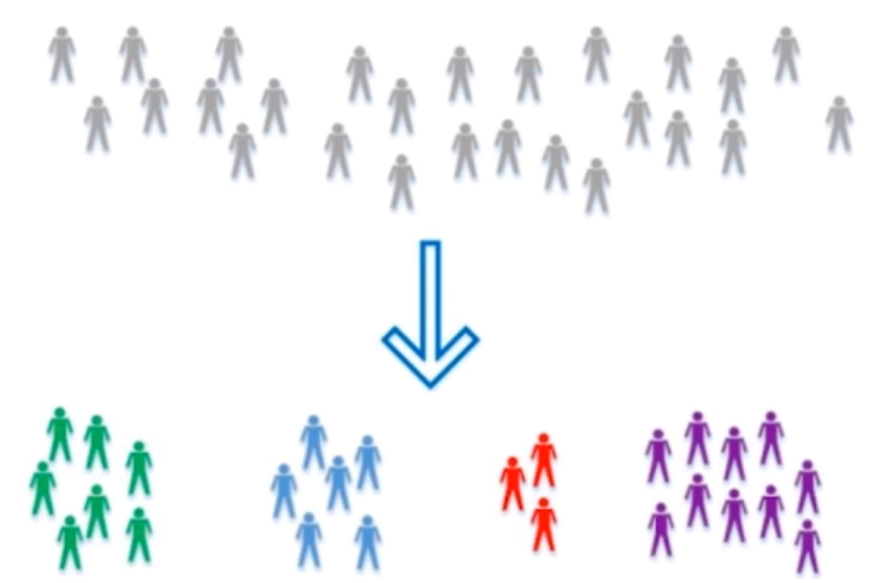
给机器的训练数据没有任何“标记”或者“答案”
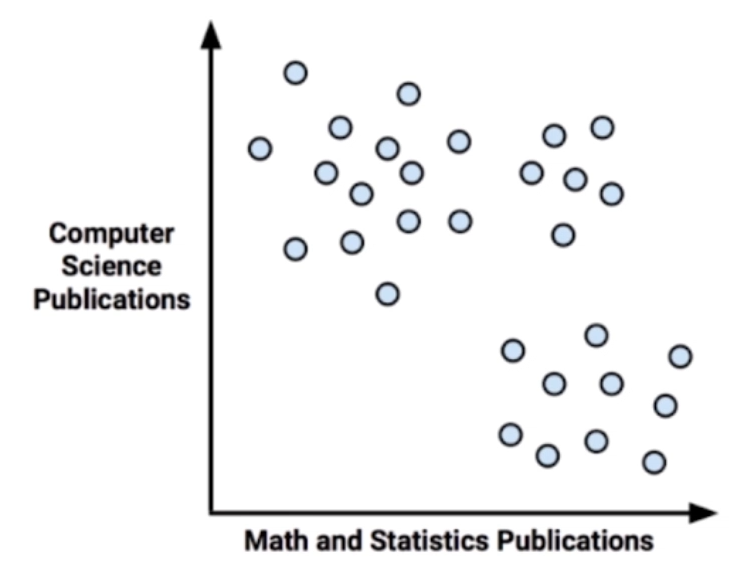
对没有“标记”的数据进行分类-聚类分析
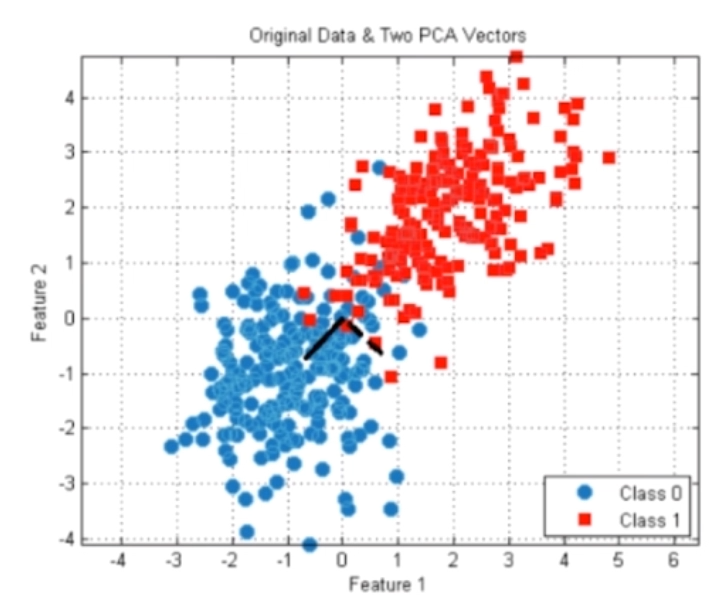
对数据进行降维处理
- 特征提取:信用卡的信用评级和人的胖瘦无关
- 特征压缩:PCA
降维处理的意义:方便可视化
异常检测
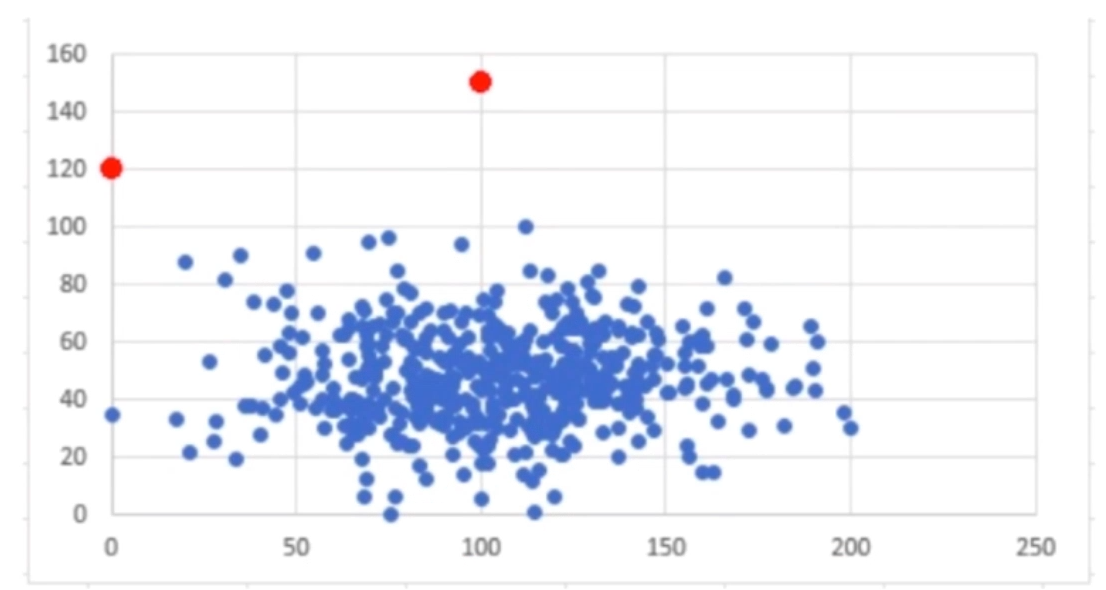
半监督学习
一部分数据有“标记”或者“答案”,另一部分数据没有
更常见:各种原因产生的标记缺失
通常都先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测
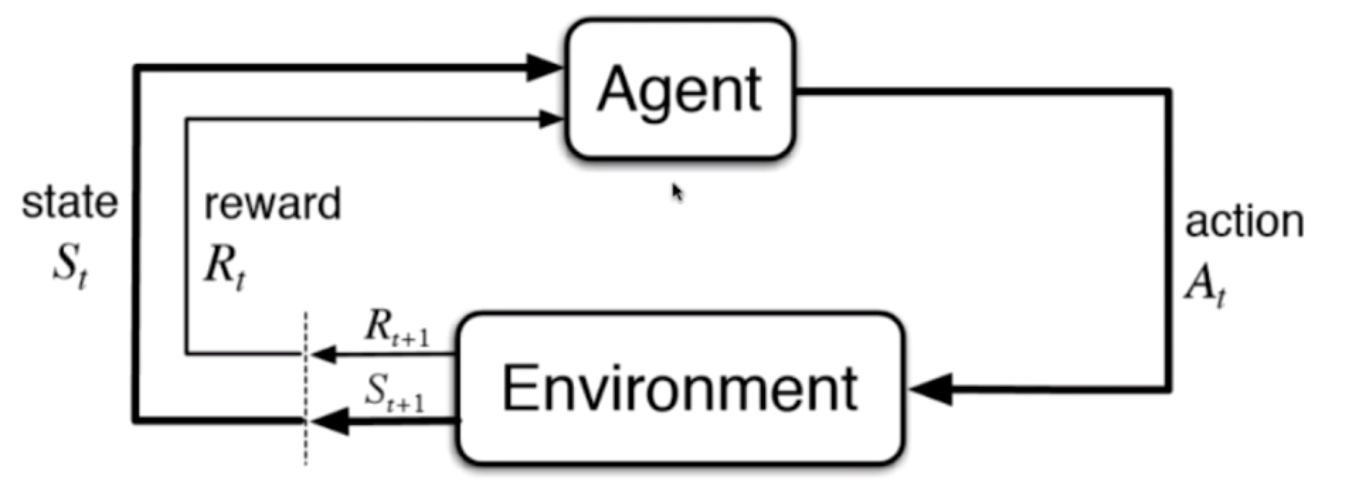
增强学习
根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式
批量学习和在线学习
批量学习 Batch Learning
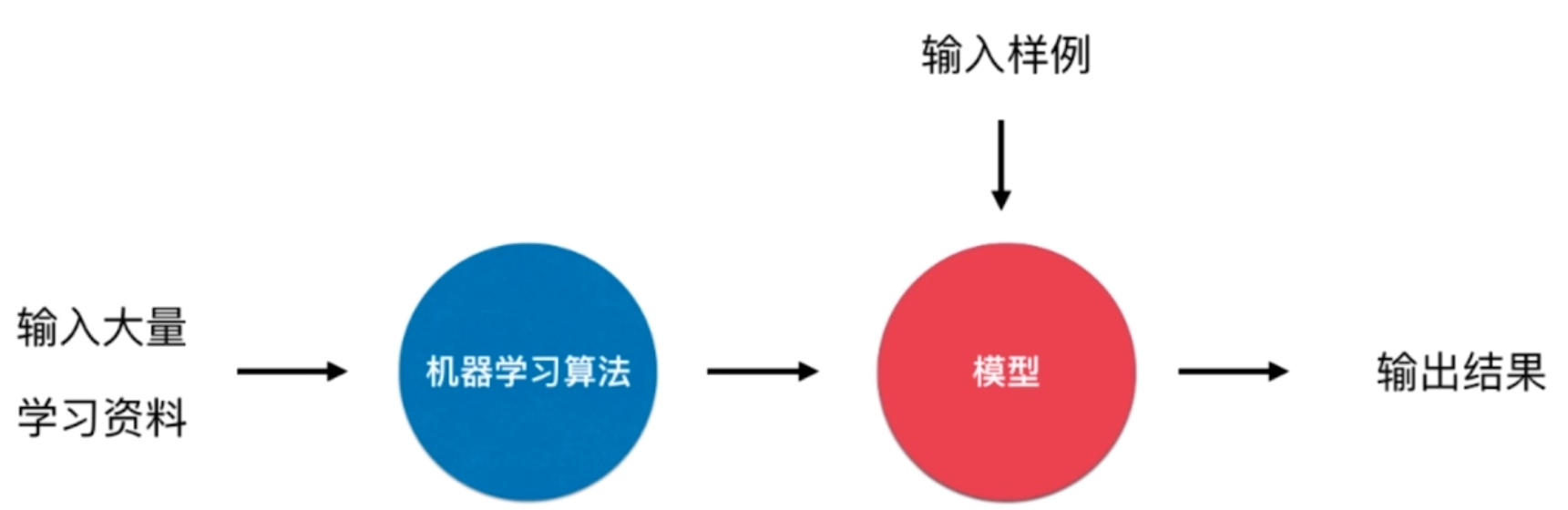
优点:简单
问题:如何适应环境变化?
解决方案:定时重新批量学习
缺点:每次重新批量学习,运算量巨大;在某些环境变化非常快的情况下,甚至不可能的
在线学习 Online Learning
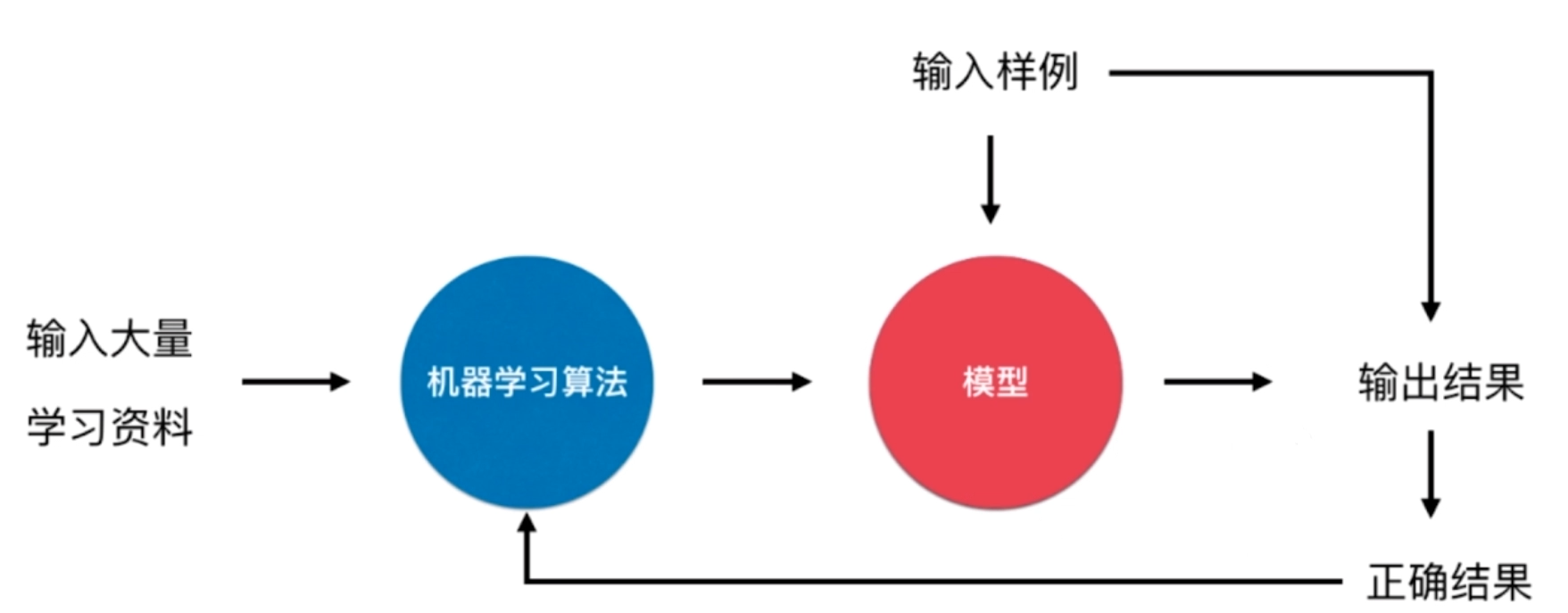
优点:及时反映新的环境变化
问题:新的数据带来不好的变化?
解决方案:需要加强对数据进行监控
其他:也适用与数据量巨大,完全无法批量学习的环境
参数学习和非参数学习
参数学习 Parametric Learning
一旦学到了参数,就不再需要原有的数据集
非参数学习 Nonparametric Learning
不对模型进行过多假设
非参数不等于没参数
文章来源:https://blog.csdn.net/weixin_42403632/article/details/135730547
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 鸿蒙OS:不止手机,是物联网应用开发
- AI技术已经发现了一种新材料,可以在电池制造中减少对锂的需求
- MLP(多层感知机) 虚战1
- 一创聚宽停止服务,散户可以选择它!
- 华为云云耀云服务器L实例评测|Ubuntu系统MySQL 8.1.0 Innovation压测
- Golang leetcode160相交链表 map 双指针迭代
- 工业相机相关概念词介绍:ISP算法、线阵相机、常用术语
- kubernetes 权限控制
- 【python mysql笔记】第一天
- WPS/Word插件-大珩助手免费功能更新-特殊字符