【Python 零基础入门】Pandas
【Python 零基础入门】第七课 Pandas
【Python 零基础入门】第七课 Pandas
Pandas 是一个开源的 Python 数据分析库, 由 Wes McKinney 在 2008 年创建, 而且在接下来的几年中, 它迅速成为 Python 数据分析社区中最受欢迎和最有影响力的工具之一. Pandas 的名字来源于 Panel Data 和 Python Data Analysis.

Pandas 是什么?
Pandas 是一个开源的 Python 数据分析库, 它提供了大量功能, 能够帮助我们轻松的处理结构化数据. 在数据清洗, 转换, 分析中 Pandas 都是我们的得力助手.

为什么 选择 Pandas
Pandas 的特征
对于我们开发者来说, Pandas 提供了一个强大的, 易于使用的数据结构和数据分析. Pandas 是数据清洗, 转换, 分析和可视化的首选.
列举一点 Pandas 的特点:
- 灵活的数据结构: Pandas 轻松的处理各种不同类型的数据, 如结构化数值表, 时间序列, 统计数据集等
- 功能强大的数据处理能力: 包括数据缺失, 插入, 删除, 聚合, 分析, 数据透视等操作
- 易于与其他 Python 库集成: 例如 Matplotlib, Numpy 等
Pandas 的应用场景
Pandas 的主要应用场景:
- 数据清洗: 如处理丢失的数据, 过滤数据等
- 数据转换: 如创建新的数据结构, 聚合数据等
- 数据分析: 如计算统计量, 对数据进行分组和汇总等
- 数据可视化: 与其他库 (Matplotlib, Seaborn) 结合, 绘制可视化图表
Pandas 底层
底层实现:
- Pandas 的底层是基于 Numpy 构建的, 这意味着 Pandas 的数据而机构, 如 “Series” 和 “DataFrame” 实际上都是在 Numpy 数组上进行操作的. 因为 Numpy 专门针对数值计算进行了优化, 所以 Pandas 在处理大量数据时性能很高
- C 语言扩展: 虽然 Pandas 本身是用 Python 编写的, 但 Pandas 使用 Cython 来编写关键代码部分, 从而进一步提高性能
安装 Pandas
在 cmd 中输入:
pip install pandas
在 conda 中安装:
conda install pandas
查看是否安装成功:
import pandas as pd
Series 数组
Pandas 有两个核心的数据结构. “Series” 和 “DataFrame”. 我们先来讲 Series.
什么是 Series?
Series 是一个一维的标签化数组, Series 它可以容纳任何数据类型 (整型, 字符串, 浮点数, Python 对象等). Series 与普通的 Python 列表相似, 但是具有更多的功能和灵活性.
Series 创建
格式:
pd.Series(data, index=None, dtype=None, name=None, copy=None, fastpath=False)
参数:
- data: 列表状数据
- index: 索引, 默认为 None
- drype: 返回的 Series 数组的类型, 默认为 None
- name: Series 数组的名字, 默认为 None
- copy: 复制输入的数据, 默认为 None
例子:
import pandas as pd
# 创建 Series 数组
list1 = [1, 2, 3] # 创建列表
series1 = pd.Series(list1) # 通过 list 创建 Series 数组
print(series1) # 调试输出
import pandas as pd
# 创建 Series 数组, 带 Index
student_name = ["张三", "李四", "我是小白呀"] # 创建学生名字列表, 用于索引学生id
student_id = [1, 2, 3] # 创建学生 id 列表
series2 = pd.Series(student_id, index=student_name) # 创建 Series 数组
print(series2) # 调试输出
# 通过字典创建 Series 数组
dict1 = {'a':1,'b':2, 'c':3} # 创建字典
series3 = pd.Series(dict1) # 通过字典创建 Series 数组
print(series3) # 调试输出
输出结果:
0 1
1 2
2 3
dtype: int64
张三 1
李四 2
我是小白呀 3
dtype: int64
a 1
b 2
c 3
dtype: int64
Series 数组操作
数据检索
Series 数组中, 我们可以通过索引来实现数据检索.
例子:
import pandas as pd
# 创建 Series 数组, 带 Index
student_name = ["张三", "李四", "我是小白呀"] # 创建学生名字列表, 用于索引学生id
student_id = [1, 2, 3] # 创建学生 id 列表
series1 = pd.Series(student_id, index=student_name) # 创建 Series 数组
print(series1) # 调试输出
# 数据检索
zhangsan_id = series1["张三"] # 通过索引提取张三对应的 id
lisi_id = series1["李四"] # 通过索引提取李四对应的 id
iamarookie_id = series1["我是小白呀"] # 通过索引提取小白对应的 id
print("张三的 id:", zhangsan_id)
print("李四的 id:", lisi_id)
print("张三的 id:", iamarookie_id)
# 多重检索
ids = series1[["张三", "李四"]] # 通过索引提取张三和李四的 id
print("张三 & 李四的 id: \n{}".format(ids)) # 调试输出
输出结果:
张三 1
李四 2
我是小白呀 3
dtype: int64
张三的 id: 1
李四的 id: 2
张三的 id: 3
张三 & 李四的 id:
张三 1
李四 2
dtype: int64
数据修改
Series 数组中, 可以用过索引来修改 Series 中的数据.
例子:
import pandas as pd
# 创建 Series 数组, 带 Index
student_name = ["张三", "李四", "我是小白呀"] # 创建学生名字列表, 用于索引学生id
student_id = [1, 2, 3] # 创建学生 id 列表
series1 = pd.Series(student_id, index=student_name) # 创建 Series 数组
print(series1) # 调试输出
# 数据修改
series1["张三"] = 123 # 将 Series 数组中, 索引张三对应的 id 修改为 123
print(series1) # 调试输出
输出结果:
张三 1
李四 2
我是小白呀 3
dtype: int64
张三 123
李四 2
我是小白呀 3
dtype: int64
过滤
Series 数组可以用过布尔索引来实现数据过滤.
例子:
import pandas as pd
# 创建关于学生成绩的 Series 数组
student_name = ["张三", "李四", "我是小白呀"] # 创建学生名字列表, 用于索引学生成绩
student_grade = [88, 90, 55] # 创建学生成绩列表
series1 = pd.Series(student_grade, index=student_name) # 创建 Series 数组
print(series1) # 调试输出
# 数据修改
result = series1[series1 < 60]
print("成绩不及格的同学: \n{}".format(result)) # 调试输出
输出结果:
张三 88
李四 90
我是小白呀 55
dtype: int64
成绩不及格的同学:
我是小白呀 55
dtype: int64
Series 数组运算
import pandas as pd
# 创建关于学生成绩的 Series 数组
student_name = ["张三", "李四", "我是小白呀"] # 创建学生名字列表, 用于索引学生成绩
student_grade = [88, 90, 55] # 创建学生成绩列表
series1 = pd.Series(student_grade, index=student_name) # 创建 Series 数组
print("加分前: \n{}".format(series1)) # 调试输出
# Series 数组运算
series1 = series1 + 5 # 鉴于小白同学不及格, 老师觉得给大家都加 5 分
print("加分后: \n{}".format(series1)) # 调试输出
输出结果:
加分前:
张三 88
李四 90
我是小白呀 55
dtype: int64
加分后:
张三 93
李四 95
我是小白呀 60
dtype: int64
总结
Pandas 中的 Series 提供了一种灵活且强大的方式来处理数据. 无论是数据分析, 数据清洗还是数据操作, Series 都是一个非常有用的工具.
DataFrame 数组
什么是 DataFrame?
DataFrame 是一个二维的标签化数据结构, 类似于一个 Excel 表格. DataFrame 中的值都是相同长度的 Series, DataFrame 是 Pandas 最常用和强大的数据结构.
DataFrame 创建
通过使用pd.DataFrame函数我们可以创建 DataFrame 数组, DataFrame 可以由多种数据穿点, 如字典, 列表, 或外部文件.
格式:
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
参数:
- data: 列表状数据
- index: 索引, 默认为 None
- columns: 列名, 默认为 None
- detype: 返回的 Series 数组的类型, 默认为 None
- copy: 复制输入的数据, 默认为 None
例子:
import pandas as pd
# 创建 DataFrame 数组
data = {"名字":["张三", "李四", "我是小白呀"], "年龄":[25, 32, 18]} # 创建字典
df = pd.DataFrame(data) # 由字典创建 DataFrame 数组
print(df) # 调试输出
输出结果:
名字 年龄
0 张三 25
1 李四 32
2 我是小白呀 18
数据操作
在 Pandas 中, 索引是一个非常强大的工具, 可以帮我我们更有效的访问, 查询和操作数据. 在了解数据结构后, 我们需要理解如何利用索引进行数组操作.
访问列数据
通过列名, 我们可以检索 DataFrame 中的数据.
数据:
名字 年龄
第一行 张三 25
第二行 李四 32
第三行 我是小白呀 18
例子:
import pandas as pd
# 创建 DataFrame 数组
data = {"名字":["张三", "李四", "我是小白呀"], "年龄":[25, 32, 18]} # 创建字典
df = pd.DataFrame(data, index=["第一行", "第二行", "第三行"]) # 由字典创建 DataFrame 数组
print(df) # 调试输出
# 检索名字列
name = df["名字"] # 提取名字列
print("提取名字列: \n{}".format(name)) # 调试输出
# 通过 iloc 实现切片
name = df.iloc[:,0] # 提取名字列 (所有行, 第一列)
print("提取名字列: \n{}".format(name)) # 调试输出
# 通过 loc 实现切片
name = df.loc[:,"名字"] # 提取名字列
print("提取名字列: \n{}".format(name)) # 调试输出
输出结果:
名字 年龄
第一行 张三 25
第二行 李四 32
第三行 我是小白呀 18
提取名字列:
第一行 张三
第二行 李四
第三行 我是小白呀
Name: 名字, dtype: object
提取名字列:
第一行 张三
第二行 李四
第三行 我是小白呀
Name: 名字, dtype: object
提取名字列:
第一行 张三
第二行 李四
第三行 我是小白呀
Name: 名字, dtype: object
访问行数据
例子:
import pandas as pd
# 创建 DataFrame 数组
data = {"名字":["张三", "李四", "我是小白呀"], "年龄":[25, 32, 18]} # 创建字典
df = pd.DataFrame(data, index=["第一行", "第二行", "第三行"]) # 由字典创建 DataFrame 数组
print(df) # 调试输出
# 检索第一行
row0 = df.iloc[0] # 提取第一行
print("提第一行: \n{}".format(row0)) # 调试输出
# 检索第一行
row0 = df.loc["第一行"] # 提取第一行
print("提第一行: \n{}".format(row0)) # 调试输出
输出结果:
名字 年龄
第一行 张三 25
第二行 李四 32
第三行 我是小白呀 18
提第一行:
名字 张三
年龄 25
Name: 第一行, dtype: object
提第一行:
名字 张三
年龄 25
Name: 第一行, dtype: object
loc vs iloc vs ix
在 Pandas 中, loc, iloc, ix都是用于选择数据的方法.
三者区别:
- loc[“行”,“列”]: 通过标签来选择数据
- 选择行: df.loc[“行标签名”]
- 选择列:df.loc[:,“列标签名”]
- iloc[行索引, 列索引]: 通过索引来选择数据
- 选择行: df.iloc[行索引]
- 选择列: df.iloc[列索引]
- ix: 既可以通过标签也可以通过索引, 约等于 loc 的功能 + iloc (了解即可)
- 为了代码的可读性, 建议使用 loc 或 iloc, ix 现已被废弃, 不建议使用
DataFrame 操作
筛选数据
例子:
import pandas as pd
# 创建 DataFrame 数组
data = {"名字":["张三", "李四", "我是小白呀"], "年龄":[25, 32, 18]} # 创建字典
df = pd.DataFrame(data) # 由字典创建 DataFrame 数组
print(df) # 调试输出
# 检索名字列
name = df["名字"] # 提取名字列
print("提取名字列: \n{}".format(name)) # 调试输出
输出结果:
名字 年龄
0 张三 25
1 李四 32
2 我是小白呀 18
提取名字列:
0 张三
1 李四
2 我是小白呀
Name: 名字, dtype: object
排序
格式:
pd.DataFrame.sort_values(by, *, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
参数:
- axis: 轴, 默认为纵向排序
- ascending: 从低到高
- inplace: 替换原本 DataFrame, 默认为 False
例子:
import pandas as pd
# 创建 DataFrame 数组
data = {"名字":["张三", "李四", "我是小白呀"], "年龄":[25, 32, 18]} # 创建字典
df = pd.DataFrame(data) # 由字典创建 DataFrame 数组
print(df) # 调试输出
# DataFrame 排序
df = df.sort_values(by="年龄") # 通过布尔条件筛选特定数据
df.reset_index(inplace=True) # 重新索引
print("排序: \n{}".format(df)) # 调试输出
注: 通过df.reset_index(inplace=True), DataFrame 数组会进行重新索引.
聚合
我们可以对 DataFrame 数字进行各种聚合操作.
例子:
import pandas as pd
# 创建 DataFrame 数组
data = {"名字":["张三", "李四", "我是小白呀"], "年龄":[25, 32, 18]} # 创建字典
df = pd.DataFrame(data) # 由字典创建 DataFrame 数组
print(df) # 调试输出
# DataFrame 聚合
mean = df["年龄"].mean() # 通过布尔条件筛选特定数据
print("平均年龄:", mean) # 调试输出
输出结果:
名字 年龄
0 张三 25
1 李四 32
2 我是小白呀 18
平均年龄: 25.0
增删
import pandas as pd
# 创建 DataFrame 数组
data = {"名字":["张三", "李四", "我是小白呀"], "年龄":[25, 32, 18]} # 创建字典
df = pd.DataFrame(data) # 由字典创建 DataFrame 数组
print(df) # 调试输出
# 添加列
data["成绩"] = [78, 82, 60] # 添加一个新的列, 成绩
print(df) # 调试输出
# 删除列
del data["年龄"] # 删除年龄列
print(df)
输出结果:
名字 年龄
0 张三 25
1 李四 32
2 我是小白呀 18
名字 年龄
0 张三 25
1 李四 32
2 我是小白呀 18
名字 年龄
0 张三 25
1 李四 32
2 我是小白呀 18
数据加载
我们经常会遇到需要从 csv 文件中加塞数据的情况. Pandas 中提供了read_csv方法, 使得我们从 csv 文件中加载数据变得非常简单.
CSV 文件加载
格式:
pandas.read_csv(filepath_or_buffer, *, sep=_NoDefault.no_default, delimiter=None, header='infer', names=_NoDefault.no_default, index_col=None, usecols=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=None, infer_datetime_format=_NoDefault.no_default, keep_date_col=False, date_parser=_NoDefault.no_default, date_format=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None, on_bad_lines='error', delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None, dtype_backend=_NoDefault.no_default)
参数:
- filepath_or_buffer: 文件路径
- header: 表头
- names: 列名
例子:
import pandas as pd
# 读取 txt/csv
data = pd.read_csv("test.txt", header=None, names=["链接"])
print(data) # 调试输出
输出结果:
链接
0 http://melanz.phorum.pl/viewtopic.php?f=7&t=64041
1 http://www.reo14.moe.go.th/phpBB3/viewtopic.ph...
2 https://www.xroxy.com/xorum/viewtopic.php?p=30...
3 http://armasow.forumbb.ru/viewtopic.php?id=840...
4 http://telecom.liveforums.ru/viewtopic.php?id=...
5 http://www.crpsc.org.br/forum/viewtopic.php?f=...
6 http://community.getvideostream.com/topic/4803...
7 http://www.shop.minecraftcommand.science/forum...
8 https://www.moddingway.com/forums/thread-31914...
9 https://webhitlist.com/forum/topics/main-featu...
Excel 文件加载
例子:
df = pd.read_excel('path_to_file.xlsx')
数据探索
在 DataFrame 中, 我们可以用过一些函数来查看 DataFrame 数据的基本结构和内容.
常用函数:
df.info(): 返回数据基本信息, 包括数据类型, 非空等df.head(): 显示前 5 行df.tail(): 显示最后 5 行df.describe(): 显示基本统计信息, 包括: 如平均值, 标准差, 最小值, 25th, 50th (中位数) 和 75th 百分位数, 最大值等
例子:
import pandas as pd
# 读取数据
data = pd.read_csv("students.txt", header=None)
print(data.info()) # 显示总览, 包括每列的数据类型和非空值的数量
print(data.head()) # 显示前 5 行
print(data.tail()) # 显示后 5 行
print(data.describe()) # 显示基本统计信息
调试输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 131 entries, 0 to 130
Data columns (total 2 columns):
0 131 non-null object
1 131 non-null object
dtypes: object(2)
memory usage: 2.1+ KB
None
0 1
0 c1235666 Fink-Nottle Augustus James
1 c3456765 O'Mahoney Geoffrey
2 c8732719 De Leo Victoria Margaret
3 c9676814 Thompson Sabrina
4 c4418710 Heck Kevin
0 1
126 c6060052 Long Marilyn
127 c2390980 Martz Perry Tony William
128 c5456142 Wilson Christine Mabel
129 c1036678 Bunch Richard Frank
130 c8306065 Hartley Marcel Jonathan Philip
0 1
count 131 131
unique 131 127
top c3827371 Bush Thomas
freq 1 2
Pandas 缺失值填充
大多情况下, 数据可能不总是完整的, 所以我们要处理数据丢失. Pandas 提供了多种处理缺失数据的方法.
识别缺失值
在 Pandas 中, 缺失值通常表示为 “NaN” (Not a Number). 我们可以使用isnull()函数或者isna()函数来列出数据中的缺失值.
以下数据就缺失 Fare 列中的几个值:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
例子:
import pandas as pd
# 读取数据
data = pd.read_csv("train.csv")
print(data)
# 调试输出每列的缺失值
print(data.isnull().sum())
输出结果:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
6 7 0 1 ... 51.8625 E46 S
7 8 0 3 ... 21.0750 NaN S
8 9 1 3 ... 11.1333 NaN S
9 10 1 2 ... 30.0708 NaN C
10 11 1 3 ... 16.7000 G6 S
11 12 1 1 ... 26.5500 C103 S
12 13 0 3 ... 8.0500 NaN S
13 14 0 3 ... 31.2750 NaN S
14 15 0 3 ... 7.8542 NaN S
15 16 1 2 ... 16.0000 NaN S
16 17 0 3 ... 29.1250 NaN Q
17 18 1 2 ... 13.0000 NaN S
18 19 0 3 ... 18.0000 NaN S
19 20 1 3 ... 7.2250 NaN C
20 21 0 2 ... 26.0000 NaN S
21 22 1 2 ... 13.0000 D56 S
22 23 1 3 ... 8.0292 NaN Q
23 24 1 1 ... 35.5000 A6 S
24 25 0 3 ... 21.0750 NaN S
25 26 1 3 ... 31.3875 NaN S
26 27 0 3 ... 7.2250 NaN C
27 28 0 1 ... 263.0000 C23 C25 C27 S
28 29 1 3 ... 7.8792 NaN Q
29 30 0 3 ... 7.8958 NaN S
.. ... ... ... ... ... ... ...
861 862 0 2 ... 11.5000 NaN S
862 863 1 1 ... 25.9292 D17 S
863 864 0 3 ... 69.5500 NaN S
864 865 0 2 ... 13.0000 NaN S
865 866 1 2 ... 13.0000 NaN S
866 867 1 2 ... 13.8583 NaN C
867 868 0 1 ... 50.4958 A24 S
868 869 0 3 ... 9.5000 NaN S
869 870 1 3 ... 11.1333 NaN S
870 871 0 3 ... 7.8958 NaN S
871 872 1 1 ... 52.5542 D35 S
872 873 0 1 ... 5.0000 B51 B53 B55 S
873 874 0 3 ... 9.0000 NaN S
874 875 1 2 ... 24.0000 NaN C
875 876 1 3 ... 7.2250 NaN C
876 877 0 3 ... 9.8458 NaN S
877 878 0 3 ... 7.8958 NaN S
878 879 0 3 ... 7.8958 NaN S
879 880 1 1 ... 83.1583 C50 C
880 881 1 2 ... 26.0000 NaN S
881 882 0 3 ... 7.8958 NaN S
882 883 0 3 ... 10.5167 NaN S
883 884 0 2 ... 10.5000 NaN S
884 885 0 3 ... 7.0500 NaN S
885 886 0 3 ... 29.1250 NaN Q
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
888 889 0 3 ... 23.4500 NaN S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[891 rows x 12 columns]
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
使用dropna()舍弃缺失值
df.dropna()可以帮助我们删除数据中所有缺失的行.
例子:
import pandas as pd
import numpy as np
# 创建一个模拟数据集
data = {
'Product': ['Apple', 'Banana', 'Cherry', 'Date', 'Fig', 'Grape', 'Mango', 'Watermelon'],
'Price': [1, 0.5, np.nan, 0.75, np.nan, 2.5, 1.2, np.nan],
'Date_sold': [np.nan, '2023-01-15', '2023-01-16', '2023-01-17', '2023-01-18', '2023-01-19', np.nan, '2023-01-21']
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
# 删除任何含有 NaN 的行
df_dropped = df.dropna()
print("\n删除含有 NaN 后的数据:")
print(df_dropped)
输出结果:
原始数据:
Product Price Date_sold
0 Apple 1.00 NaN
1 Banana 0.50 2023-01-15
2 Cherry NaN 2023-01-16
3 Date 0.75 2023-01-17
4 Fig NaN 2023-01-18
5 Grape 2.50 2023-01-19
6 Mango 1.20 NaN
7 Watermelon NaN 2023-01-21
删除含有 NaN 后的数据:
Product Price Date_sold
1 Banana 0.50 2023-01-15
3 Date 0.75 2023-01-17
5 Grape 2.50 2023-01-19
使用fillna()填充缺失值
df.fillna()帮助我们使用指定的值填充缺失数据.
例子:
import pandas as pd
import numpy as np
# 创建一个模拟数据集
data = {
'Product': ['Apple', 'Banana', 'Cherry', 'Date', 'Fig', 'Grape', 'Mango', 'Watermelon'],
'Price': [1, 0.5, np.nan, 0.75, np.nan, 2.5, 1.2, np.nan],
'Date_sold': [np.nan, '2023-01-15', '2023-01-16', '2023-01-17', '2023-01-18', '2023-01-19', np.nan, '2023-01-21']
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
# 使用固定值填充
df1 = df.copy()
df1['Price'].fillna("1", inplace=True)
print("\n使用固定值填充后的数据:")
print(df1)
# 使用前一个值填充
df2 = df.copy()
df2['Price'].fillna(method='ffill', inplace=True)
print("\n使用前一个值填充后的数据:")
print(df2)
# 使用平均值填充
df3 = df.copy()
df3['Price'].fillna(df3['Price'].mean(), inplace=True)
print("\n使用平均值填充后的数据:")
print(df3)
输出结果:
原始数据:
Product Price Date_sold
0 Apple 1.00 NaN
1 Banana 0.50 2023-01-15
2 Cherry NaN 2023-01-16
3 Date 0.75 2023-01-17
4 Fig NaN 2023-01-18
5 Grape 2.50 2023-01-19
6 Mango 1.20 NaN
7 Watermelon NaN 2023-01-21
使用固定值填充后的数据:
Product Price Date_sold
0 Apple 1 NaN
1 Banana 0.5 2023-01-15
2 Cherry 1 2023-01-16
3 Date 0.75 2023-01-17
4 Fig 1 2023-01-18
5 Grape 2.5 2023-01-19
6 Mango 1.2 NaN
7 Watermelon 1 2023-01-21
使用前一个值填充后的数据:
Product Price Date_sold
0 Apple 1.00 NaN
1 Banana 0.50 2023-01-15
2 Cherry 0.50 2023-01-16
3 Date 0.75 2023-01-17
4 Fig 0.75 2023-01-18
5 Grape 2.50 2023-01-19
6 Mango 1.20 NaN
7 Watermelon 1.20 2023-01-21
使用平均值填充后的数据:
Product Price Date_sold
0 Apple 1.00 NaN
1 Banana 0.50 2023-01-15
2 Cherry 1.19 2023-01-16
3 Date 0.75 2023-01-17
4 Fig 1.19 2023-01-18
5 Grape 2.50 2023-01-19
6 Mango 1.20 NaN
7 Watermelon 1.19 2023-01-21
去重
去重:
df.drop.duplicates()
数据转换:
df['column_name'] = df['column_name'].astype('new_type') # 转换数据类型
df['new_column'] = df['column1'] + df['column2']
inplace 参数
Pandas 中 inplace 参数在很多函数中都会有, 它的作用是: 是否在原对象基础上进行修改.
inplace 中 True 和 False 的意思:
- inplace = True: 不创建新的对象, 直接对原始对象进行修改
- inplace = False: 对数据进行修改, 创建并返回新的对象承载其修改结果
例子:
# 以下两行代码意思相同
df.dropna(inplace=True) # 直接对 df 对象进行修改
df_dropped = df.dropna(inplace=True) # 对 df 进行修改并返回对象
inplace 参数在函数中默认是 False,即创建新的对象进行修改, 原对象不变, 和深复制和浅复制有些类似.
数据合并, 连接与管理
合并
contact()函数可以帮助我们连接两个或者多个数据.
格式:
df.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
sort=None, copy=True)
参数:
- objs: 需要拼接的数字
- join: 拼接模式
- join_axes: 拼接轴
例子:
import pandas as pd
# 初始化 DataFrame 数组
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']})
df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],
'B': ['B3', 'B4', 'B5']})
# 调试输出
print(df1)
print(df2)
# 进行 concat 连接
result = pd.concat([df1, df2])
print(result)
调试输出:
A B
0 A0 B0
1 A1 B1
2 A2 B2
A B
0 A3 B3
1 A4 B4
2 A5 B5
A B
0 A0 B0
1 A1 B1
2 A2 B2
0 A3 B3
1 A4 B4
2 A5 B5
```merge()``函数也可以帮助我们进行合并操作, 类似于 SQL 的 JOIN.
例子:
import pandas as pd
# 初始化 DataFrame 数组
left = pd.DataFrame({'key': ['K0', 'K1', 'K2'],
'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2'],
'C': ['C0', 'C1', 'C2'],
'D': ['D0', 'D1', 'D2']})
# 调试输出
print(left)
print(right)
# 使用 merge 拼接
result = pd.merge(left, right, on='key')
print(result)
输出结果:
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
key C D
0 K0 C0 D0
1 K1 C1 D1
2 K2 C2 D2
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
分组与聚合
使用groupby()可以将数组框按列值分组, 然后对每个组应用聚合函数.
常见的聚合函数:
sum(): 求和mean(): 平均数median(): 求中位数min(): 求最小值max(): 求最大值
例 1:
import pandas as pd
# 初始化 DataFrame 数组
df = pd.DataFrame({'A': ['foo', 'bar', 'foo', 'bar'],
'B': [1, 2, 3, 4],
'C': [2.0, 3.0, 4.0, 5.0]})
print(df)
# 聚合求和
grouped = df.groupby('A').sum()
print(grouped)
调试输出:
A B C
0 foo 1 2.0
1 bar 2 3.0
2 foo 3 4.0
3 bar 4 5.0
B C
A
bar 6 8.0
foo 4 6.0
例 2, 关于全球员工薪水的数据集:
import pandas as pd
# 数据集
data = {
'Country': ['USA', 'India', 'UK', 'USA', 'India', 'UK', 'USA', 'India'],
'Employee': ['Sam', 'Amit', 'John', 'Alice', 'Alok', 'Bob', 'Charlie', 'Deepak'],
'Salary': [70000, 45000, 60000, 80000, 50000, 55000, 85000, 65000]
}
# 初始化 DataFrame
df = pd.DataFrame(data)
print(df)
# 使用 goupby() 根据国家计算平均薪水
salary_by_country = df.groupby("Country")["Salary"].mean()
print("平均薪水:", salary_by_country)
# 使用 groupby() 计算每个国家的员工数
employee_by_country = df.groupby("Country")["Employee"].count()
print("员工数量: \n{}",format(employee_by_country))
# 多重聚合
result = df.groupby("Country")['Salary'].agg(['mean', 'median', 'sum', 'max', 'min'])
print(result)
输出结果:
Country Employee Salary
0 USA Sam 70000
1 India Amit 45000
2 UK John 60000
3 USA Alice 80000
4 India Alok 50000
5 UK Bob 55000
6 USA Charlie 85000
7 India Deepak 65000
平均薪水: Country
India 53333.333333
UK 57500.000000
USA 78333.333333
Name: Salary, dtype: float64
员工数量:
{} Country
India 3
UK 2
USA 3
Name: Employee, dtype: int64
mean median sum max min
Country
India 53333.333333 50000 160000 65000 45000
UK 57500.000000 57500 115000 60000 55000
USA 78333.333333 80000 235000 85000 70000
时间序列分析
Pandas 提供了 “datatime” 和 “timedelta” 类型, 用于处理时间数据.
例子:
import pandas as pd
# 时间序列分析
data = pd.to_datetime(['2023-01-01', '2023-02-01'])
print(data) # 调试输出
输出结果:
DatetimeIndex(['2023-01-01', '2023-02-01'], dtype='datetime64[ns]', freq=None)
数据可视化
我们可以通过 Pandas 进行基本的数据可视化.
Pandas 除了能进行数据处理和分析的功能外, 还提供了简单直观的绘制方法:
- ````plot()```: 绘制线图, 通常用于时间序列数据
hist(): 绘制直方图, 有助于观察数据分布boxpolt(): 绘制箱线图, 可用于观察数据的中位数, 分位数等统计指标
使用plot绘制线图:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 生成示例数据
date_rng = pd.date_range(start='2020-01-01', end='2020-12-31', freq='D')
df = pd.DataFrame(date_rng, columns=['date'])
df['data'] = np.random.randint(0, 100, size=(len(date_rng)))
df.set_index('date', inplace=True)
df.plot(figsize=(10, 6))
plt.title('Time Series Data Visualization')
plt.ylabel('Random Data')
plt.show()
输出结果:
使用hist()绘制直方图:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 生成示例数据
date_rng = pd.date_range(start='2020-01-01', end='2020-12-31', freq='D')
df = pd.DataFrame(date_rng, columns=['date'])
df['data'] = np.random.randint(0, 100, size=(len(date_rng)))
# 绘制直方图
df['data'].hist(bins=30, figsize=(10, 6))
plt.title('Histogram Data Visualization')
plt.xlabel('Random Data')
plt.ylabel('Frequency')
plt.show()
输出结果:
使用boxplot()绘制箱线图:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 生成示例数据
date_rng = pd.date_range(start='2020-01-01', end='2020-12-31', freq='D')
df = pd.DataFrame(date_rng, columns=['date'])
df['data'] = np.random.randint(0, 100, size=(len(date_rng)))
# 绘制箱线图
df.boxplot(column='data', figsize=(6, 10))
plt.title('Boxplot Data Visualization')
plt.ylabel('Random Data')
plt.show()
输出结果:

总结
Pandas 在数据分析中的重要性. Pandas 是 Python 数据分析中的一个不可或缺的库. 通过 Pandas, 数据科学家和数据分析师能够轻松的读取, 处理, 分析和可视化数据.
首先,我们介绍了 Pandas 的核心数据结构——Series 和 DataFrame,它们分别为一维和二维数据提供了丰富的操作和功能。接着,我们详细讨论了如何对数据进行索引、选择和修改,使数据处理变得简单高效。
在数据清洗部分,我们学习了各种数据清洗技巧,如处理缺失值、重复数据和字符串操作。这些都是数据预处理过程中的关键步骤,对于后续的分析和模型建立至关重要。
之后,我们深入了解了数据的聚合、转换和过滤。通过对数据的分组和汇总,我们可以获得有关数据的有趣洞察和统计信息。
最后,我们探索了 Pandas 的高级特性,如数据的合并、重塑、透视以及如何处理大数据和性能优化。这些技巧可以帮助我们更好地组织和优化代码,使其更具可读性和效率。
总的来说,Pandas 是一个功能强大、灵活且高效的工具,无论你是数据初学者还是经验丰富的分析师,都应该深入学习和掌握它。希望本篇博客能为你的数据分析之旅提供有价值的参考和指导。继续探索、学习和实践,让数据的魅力助你走得更远!
练习
数据集介绍
泰坦尼克号数据集。这个数据集包含了泰坦尼克号上乘客的信息和他们是否在沉船事故中生还。
数据描述:
- PassengerId:乘客编号
- Survived:是否生还(0 = No, 1 = Yes)
- Pclass:票的类别(1 = 1st, 2 = 2nd, 3 = 3rd)
- Name:乘客姓名
- Sex:性别
- Age:年龄
- SibSp:在船上的兄弟姐妹和配偶的数量
- Parch:在船上的父母和子女的数量
- Ticket:票号
- Fare:票价
- Cabin:船舱号
- Embarked:登船港口(C = Cherbourg, Q = Queenstown, S = Southampton)
数据记载
下载泰坦尼克号数据集:点此下载
使用 Pandas 读取下载的 CSV 文件。
数据初步探索
数据初步探索:
- 描述数据集的大小、列的数据类型。
- 查看数据集中是否有缺失值,并决定如何处理它们。
数据筛选与操作
数据筛选与操作:
- 选择 Pclass, Sex, 和 Survived 列进行进一步分析。
- 找出所有在1等舱的女性乘客。
创建一个新列 IsChild,标记年龄小于18岁的乘客。
数据统计与聚合
数据统计与聚合:
- 计算女性乘客的平均生还率。
- 对 Pclass 使用 groupby(),并计算每个类别的平均生还率。
- 创建一个数据透视表,显示不同舱位和性别的生还率。
数据清洗
数据清洗:
- 处理 Age 列的缺失值,可以考虑填充平均年龄或使用其他方法。
- 根据姓名查找可能的重复乘客。
- 将 Sex 列转换为数值型,如:0为male,1为female。
数据可视化
数据可视化:
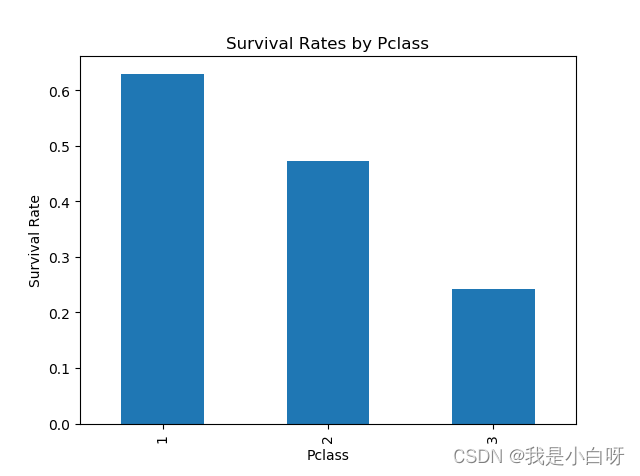
- 使用 Pandas 绘制不同 Pclass 的生还率条形图。
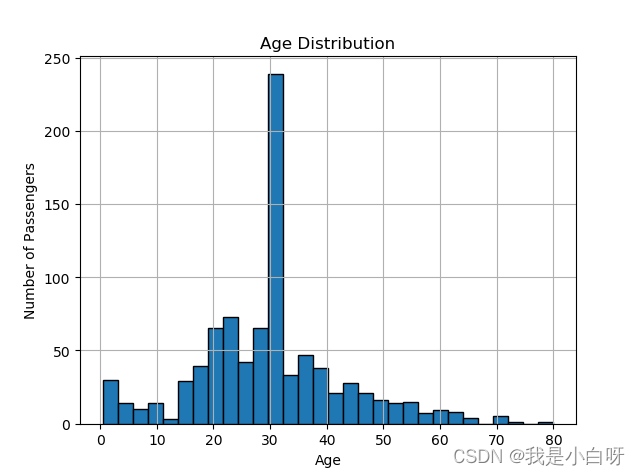
- 绘制 Age 列的直方图,观察乘客年龄分布。
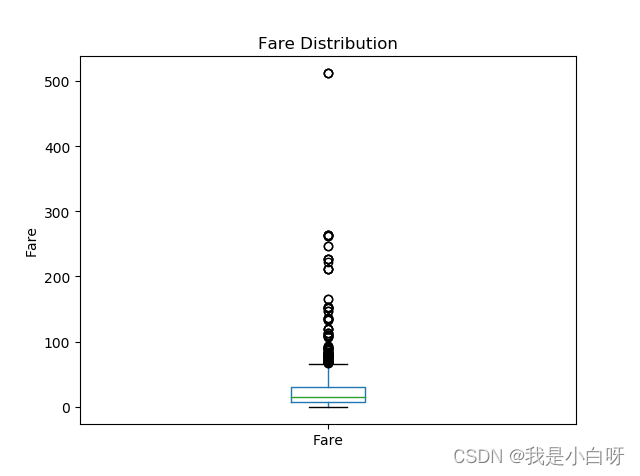
- 对 Fare 列绘制箱线图,观察票价的分布。
参考答案
import pandas as pd
from matplotlib import pyplot as plt
# 读取数据
data = pd.read_csv("train.csv")
print(data)
# 显示基本信息
print(data.info())
print(data.describe())
print(data.isnull().sum()) # 调试输出缺失值
# 填充缺失
data["Age"].fillna(data["Age"].mean(), inplace=True) # 填充平均值
data['Cabin'].fillna('Unknown', inplace=True)
print(data.isnull().sum()) # 调试输出缺失值
# 数据筛选与操作
selected_data = data[['Pclass', 'Sex', 'Survived']]
first_class_females = data[(data['Pclass'] == 1) & (data['Sex'] == 'female')]
# 标记18岁以下的乘客
data['IsChild'] = data['Age'].apply(lambda x: 1 if x < 18 else 0)
# 数据统计与聚合
female_survival_rate = data[data['Sex'] == 'female']['Survived'].mean()
print(f"Female Survival Rate: {female_survival_rate}")
class_survival_rates = data.groupby('Pclass')['Survived'].mean()
print(class_survival_rates)
pivot_table = data.pivot_table('Survived', index='Sex', columns='Pclass')
print(pivot_table)
# 数据清洗
data['Sex'] = data['Sex'].map({'male': 0, 'female': 1}) # 将 Sex 列转为数值型
# 数据可视化
class_survival_rates.plot(kind='bar', title='Survival Rates by Pclass')
plt.ylabel('Survival Rate')
plt.show()
data['Age'].hist(bins=30, edgecolor='black')
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Number of Passengers')
plt.show()
data['Fare'].plot(kind='box')
plt.title('Fare Distribution')
plt.ylabel('Fare')
plt.show()
输出结果:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
6 7 0 1 ... 51.8625 E46 S
7 8 0 3 ... 21.0750 NaN S
8 9 1 3 ... 11.1333 NaN S
9 10 1 2 ... 30.0708 NaN C
10 11 1 3 ... 16.7000 G6 S
11 12 1 1 ... 26.5500 C103 S
12 13 0 3 ... 8.0500 NaN S
13 14 0 3 ... 31.2750 NaN S
14 15 0 3 ... 7.8542 NaN S
15 16 1 2 ... 16.0000 NaN S
16 17 0 3 ... 29.1250 NaN Q
17 18 1 2 ... 13.0000 NaN S
18 19 0 3 ... 18.0000 NaN S
19 20 1 3 ... 7.2250 NaN C
20 21 0 2 ... 26.0000 NaN S
21 22 1 2 ... 13.0000 D56 S
22 23 1 3 ... 8.0292 NaN Q
23 24 1 1 ... 35.5000 A6 S
24 25 0 3 ... 21.0750 NaN S
25 26 1 3 ... 31.3875 NaN S
26 27 0 3 ... 7.2250 NaN C
27 28 0 1 ... 263.0000 C23 C25 C27 S
28 29 1 3 ... 7.8792 NaN Q
29 30 0 3 ... 7.8958 NaN S
.. ... ... ... ... ... ... ...
861 862 0 2 ... 11.5000 NaN S
862 863 1 1 ... 25.9292 D17 S
863 864 0 3 ... 69.5500 NaN S
864 865 0 2 ... 13.0000 NaN S
865 866 1 2 ... 13.0000 NaN S
866 867 1 2 ... 13.8583 NaN C
867 868 0 1 ... 50.4958 A24 S
868 869 0 3 ... 9.5000 NaN S
869 870 1 3 ... 11.1333 NaN S
870 871 0 3 ... 7.8958 NaN S
871 872 1 1 ... 52.5542 D35 S
872 873 0 1 ... 5.0000 B51 B53 B55 S
873 874 0 3 ... 9.0000 NaN S
874 875 1 2 ... 24.0000 NaN C
875 876 1 3 ... 7.2250 NaN C
876 877 0 3 ... 9.8458 NaN S
877 878 0 3 ... 7.8958 NaN S
878 879 0 3 ... 7.8958 NaN S
879 880 1 1 ... 83.1583 C50 C
880 881 1 2 ... 26.0000 NaN S
881 882 0 3 ... 7.8958 NaN S
882 883 0 3 ... 10.5167 NaN S
883 884 0 2 ... 10.5000 NaN S
884 885 0 3 ... 7.0500 NaN S
885 886 0 3 ... 29.1250 NaN Q
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
888 889 0 3 ... 23.4500 NaN S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[891 rows x 12 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
None
PassengerId Survived Pclass ... SibSp Parch Fare
count 891.000000 891.000000 891.000000 ... 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 ... 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 ... 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 ... 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 ... 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 ... 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 ... 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 ... 8.000000 6.000000 512.329200
[8 rows x 7 columns]
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 2
dtype: int64
Female Survival Rate: 0.7420382165605095
Pclass
1 0.629630
2 0.472826
3 0.242363
Name: Survived, dtype: float64
Pclass 1 2 3
Sex
female 0.968085 0.921053 0.500000
male 0.368852 0.157407 0.135447
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux文件系统与日志分析
- 【C#与Redis】--目录
- 无监督学习 - 关联规则学习(Association Rule Learning)
- 前端全栈基础之CSS中margin,padding
- Matlab:搜索文件和文件夹
- 拍立淘API:电商搜索引擎进入图像识别新时代
- <sa8650> sa8650基线代码编译
- 松下和米家、书客哪个牌子好?三款台灯全面测评谁更值得买!
- Linux --绘制地图投影出现报错:无法成功下载地图背景数据
- Hospital Laboratory