automa插件使用的一些经验
发布时间:2024年01月10日
automa,我承认我写不出来这样的代码,早年的时候公司想过做一个爬虫的工具,那个时候RPA还没有火,虽然下载也没怎么火.RPA再牛,还是需要工程师,想一点经验都没有人来做,还是理解不了。能够简化数据采集,却不能替换工程师。
1 循环数据问题
如果我想采集的数据,告诉我每页有多少条记录,或者有多少分页,就很容易了。
它这个里面循环数据的选项,除了变量,其他的都无法实现非固定值的分页。
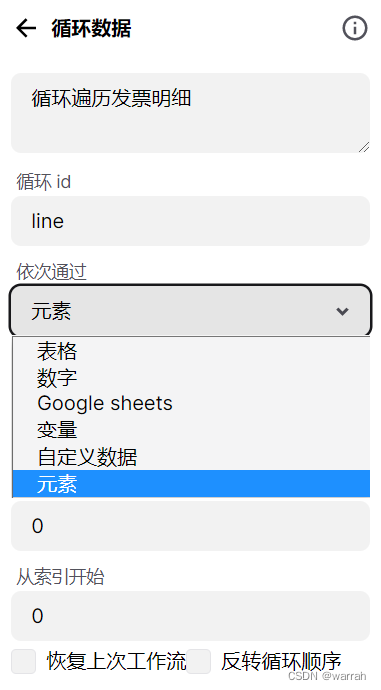
但实际并不是我所想的那样使用。取元素的数量好办,通过js就可以得到
// 得到目录数量
const dir_cn = document.querySelectorAll('.file-list-item').length
automaSetVariable('dir_cn', dir_cn)
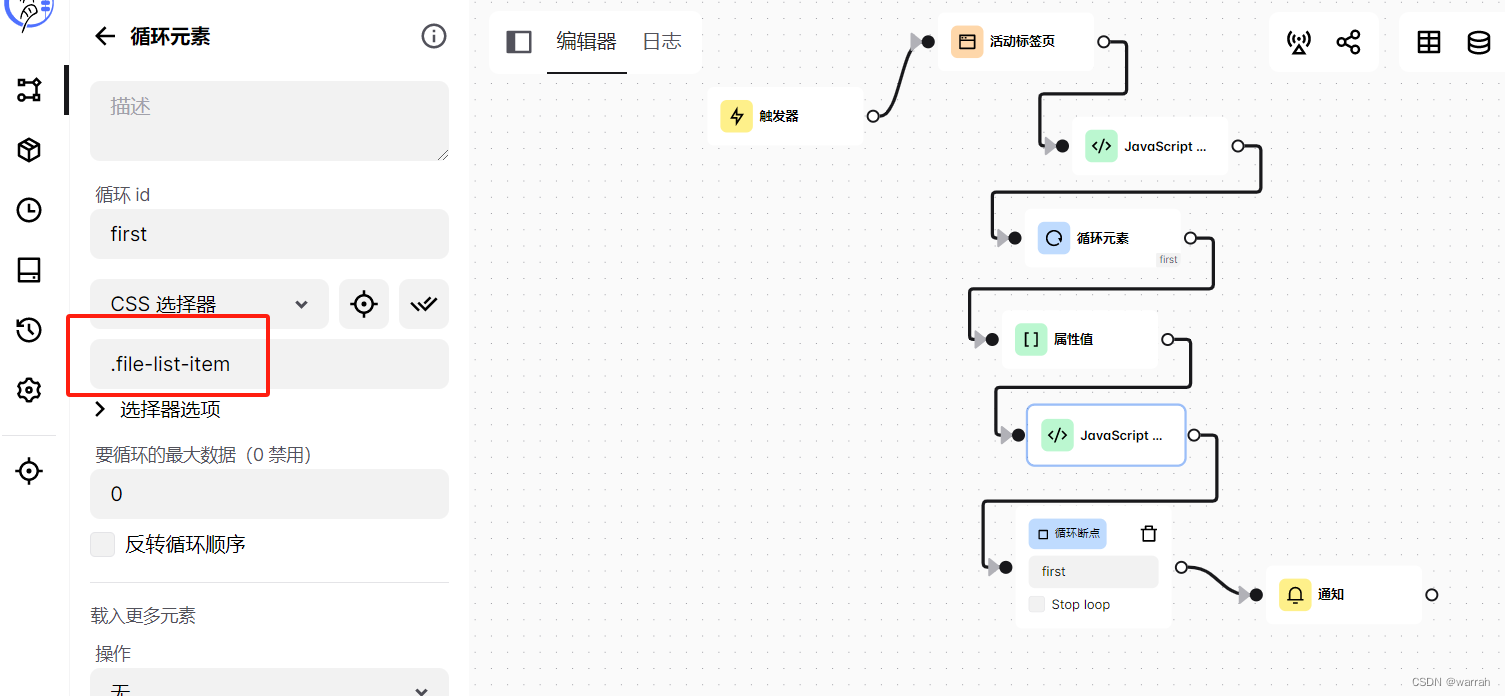
得到了数量如何循环呢?先调整思路,从循环元素着手,官方有个示例Extract All Instagram Profile Posts
指定要循环的元素,这里要循环的最大数据,就需要设置了,默认为0,这样循环就可以自动进行。
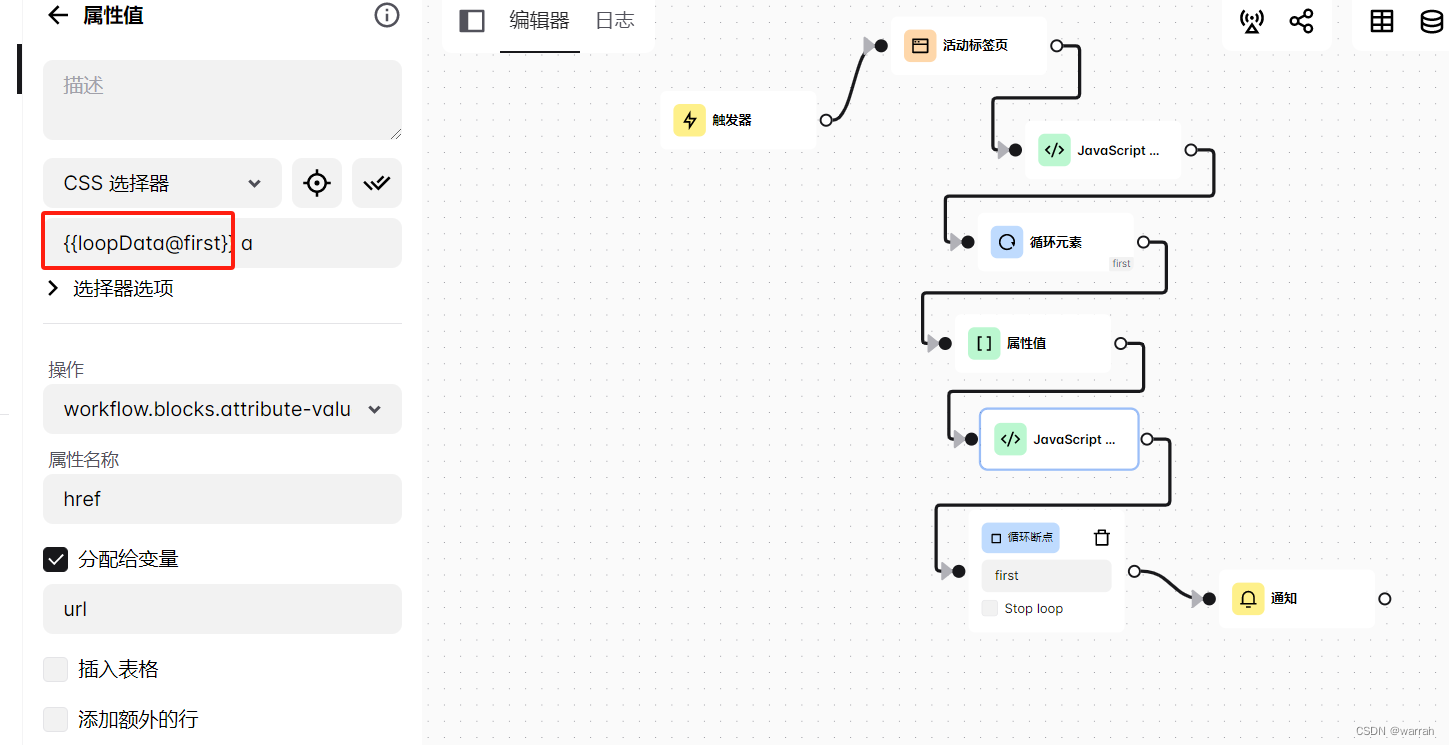
再取元素的属性值,获取超链接的href,可以看到这里的css选择器的使用规则,采用的是上面定义的first,得到值赋值给变量url
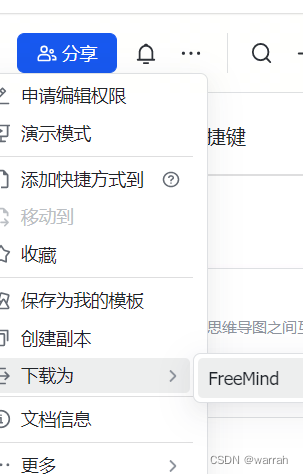
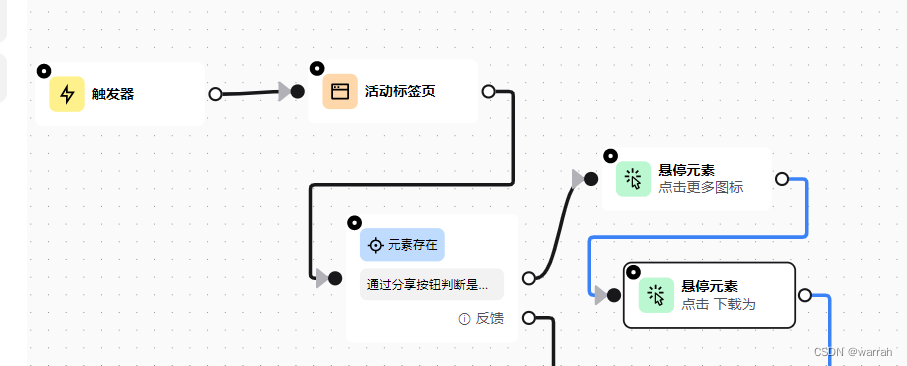
2 文件下载
飞书中文件有一个下载为“FreeMind”,这个用automa怎么操作呢?chrome浏览器 调试鼠标悬停后出现的元素样式,这里通过把鼠标放到对应元素,然后点击鼠标右键,同时按键盘上的N可以定位到悬浮窗口的dom节点,只是这种办法鼠标一挪走,就得反复这么操作,有些麻烦,多搞几次就好了。两个同时按,就不会隐藏掉,就容易定位到了。
前面两级菜单都好办,通过元素就可以找到,但是点击“FreeMind”,就有问题,因为它是文件下载。点击没有用
文章来源:https://blog.csdn.net/warrah/article/details/135478607
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 多维时序 | Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多变量时间序列预测
- c++学习笔记(9)-模板基础
- AI搜索引擎Perplexity来了,谷歌等老牌搜索引擎或许会有新的威胁?
- 实战案例:黑客如何全方面攻击手机app并绕过登录、权限获取、拒绝服务、恶意广播、sql注入、获取敏感信息?(附工具下载)
- 支付宝和微信支付对接流程
- Java版企业电子招投标系统源代码,支持二次开发,采用Spring cloud微服务架构
- 计算机网络概述(下)——“计算机网络”
- MySQL数据库-概括与常用图形管理工具
- 鸿蒙开发环境配置-Windows
- 未来的NAS:连接您的数字生活